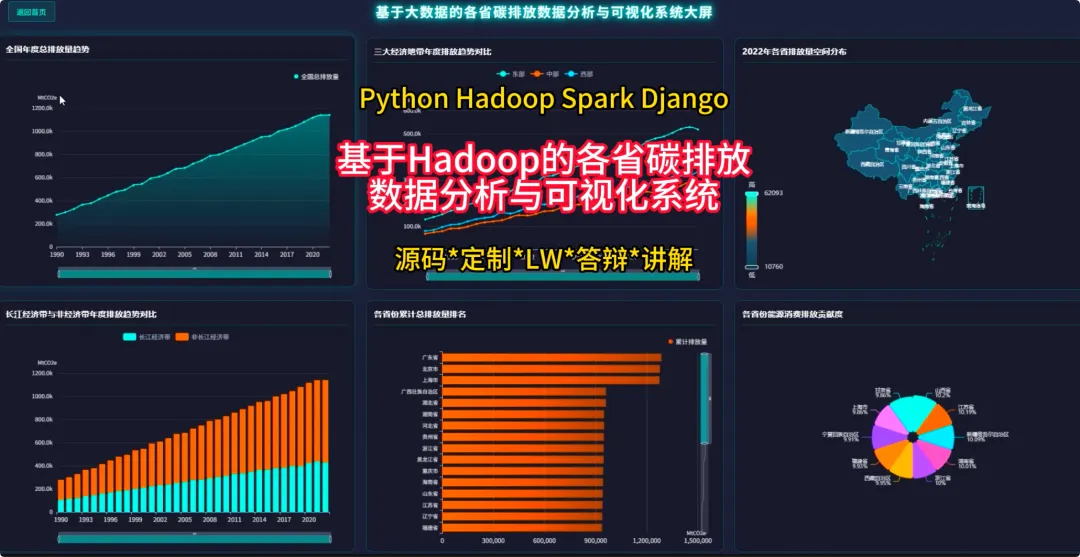
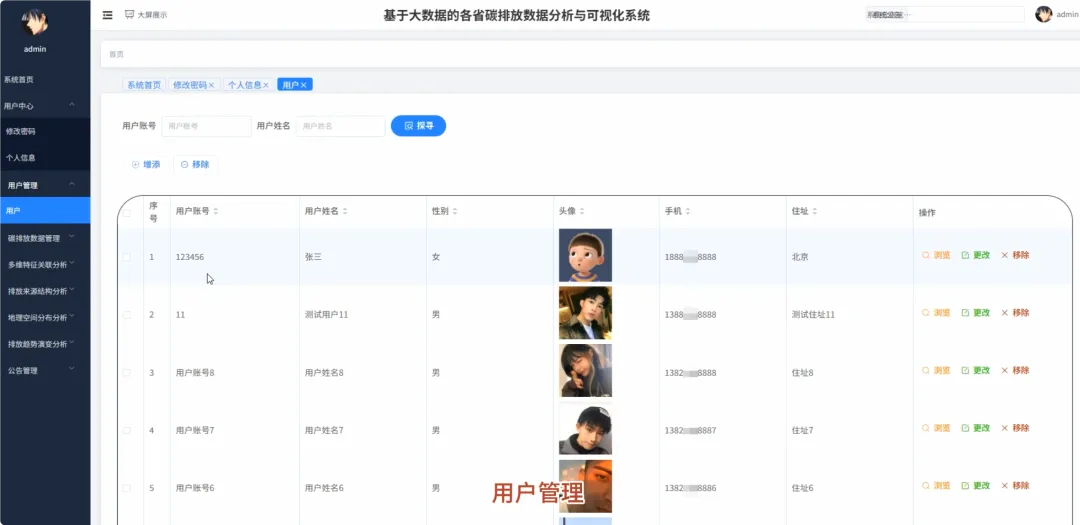
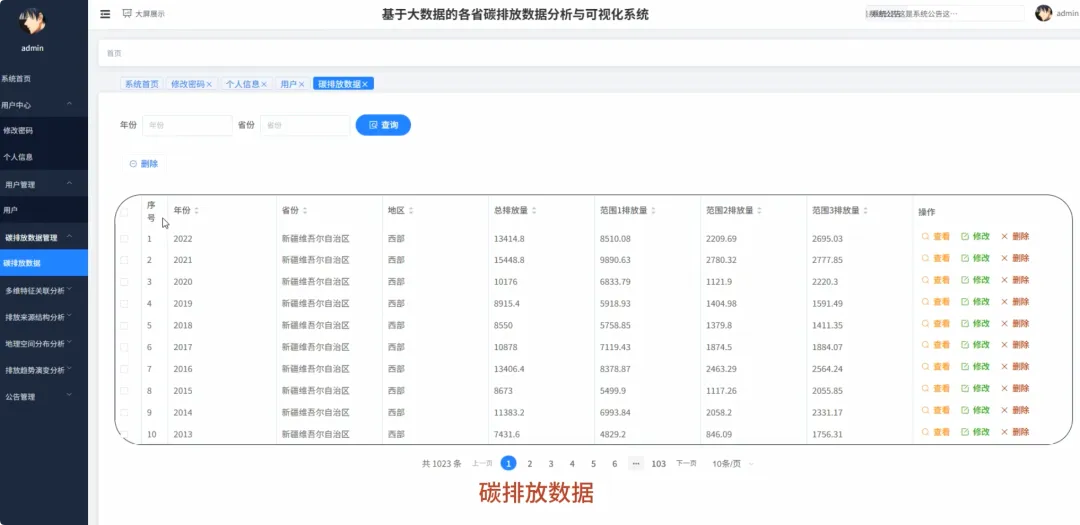
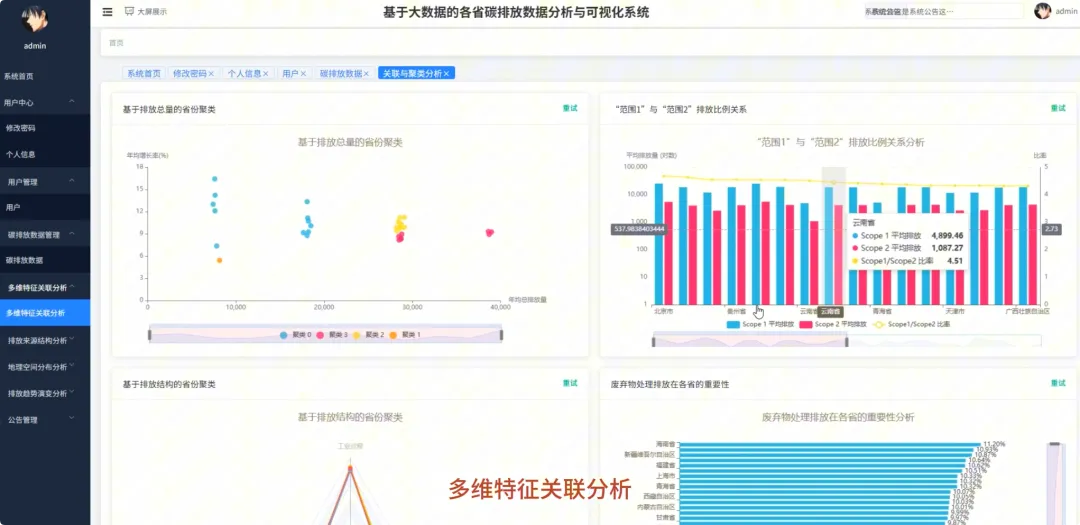
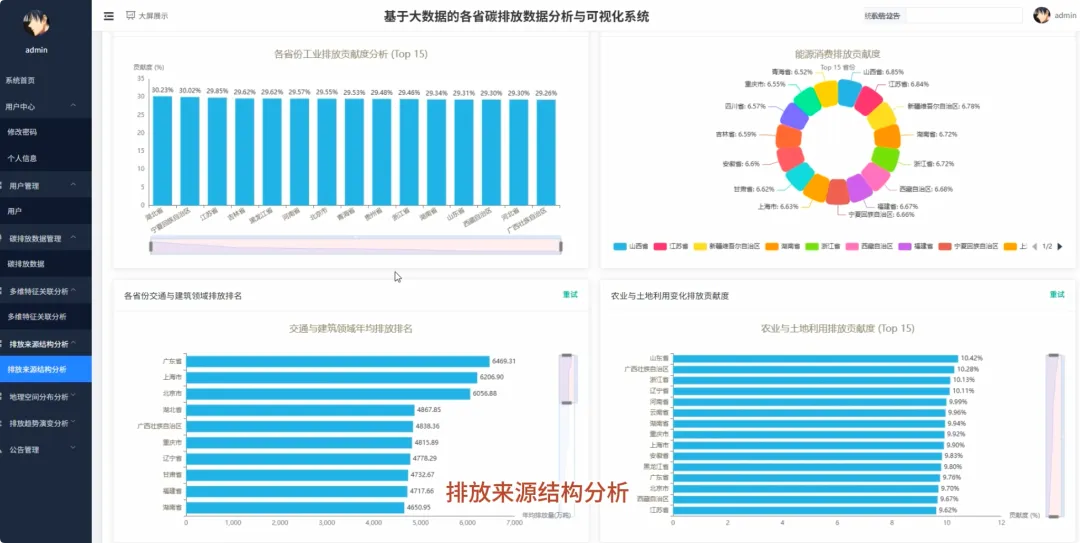
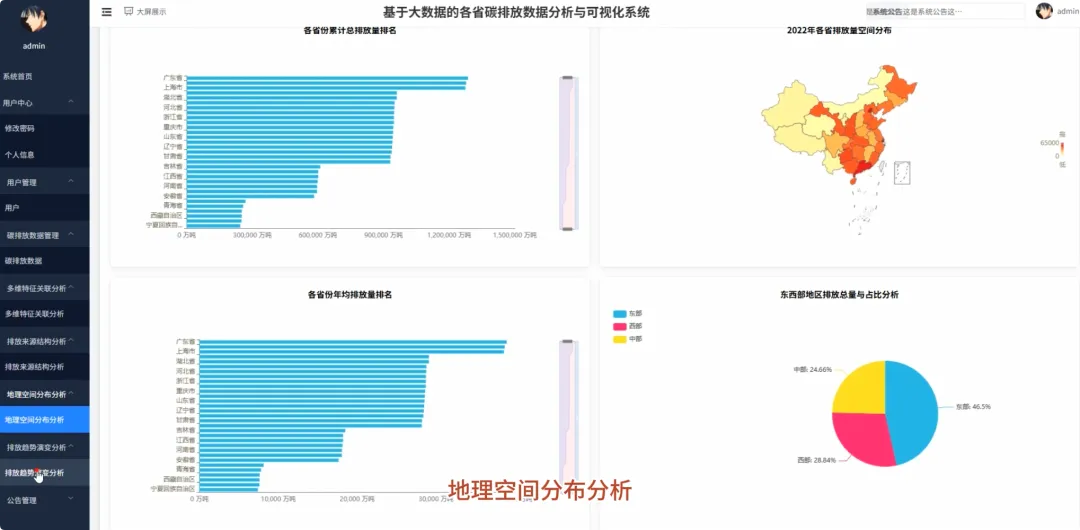
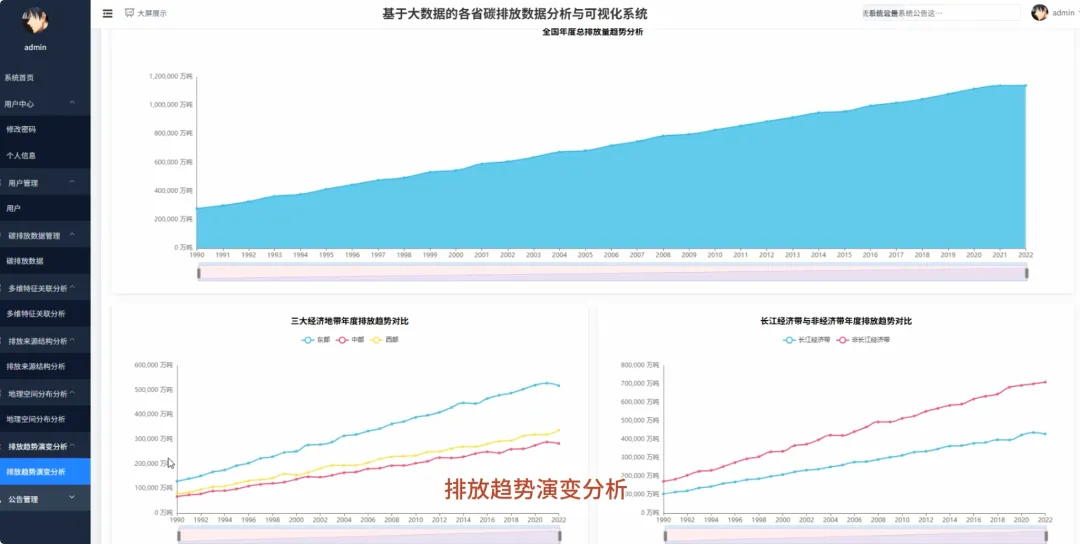
from pyspark.sql import SparkSessionfrom pyspark.sql.functions import col, sum, avg, count, when, litfrom pyspark.ml.feature import VectorAssemblerfrom pyspark.ml.clustering import KMeansspark = SparkSession.builder.appName("CarbonAnalysis").getOrCreate()df = spark.read.csv("hdfs://namenode:9000/carbon_data.csv", header=True, inferSchema=True)def get_national_yearly_trend(): yearly_emissions = df.groupBy("year").agg(sum("total_emissions").alias("yearly_total")).orderBy("year") pandas_df = yearly_emissions.toPandas() return pandas_df.to_dict('records')def get_province_ranking_for_year(target_year): specific_year_df = df.filter(df.year == target_year) province_ranking = specific_year_df.groupBy("province").agg(sum("total_emissions").alias("province_total")).orderBy(col("province_total").desc()) pandas_df = province_ranking.toPandas() return pandas_df.to_dict('records')def cluster_provinces_by_structure(k=3): structure_df = df.groupBy("province").agg( sum("industrial_process_emissions").alias("industrial_sum"), sum("purchased_electricity_emissions").alias("energy_sum"), sum("transport_construction_emissions").alias("transport_sum") ) total_emissions_per_province = structure_df.select( col("province"), (col("industrial_sum") + col("energy_sum") + col("transport_sum")).alias("total_sum") ) structure_with_ratios = structure_df.join(total_emissions_per_province, "province").withColumn("industrial_ratio", col("industrial_sum") / col("total_sum")).withColumn("energy_ratio", col("energy_sum") / col("total_sum")).fillna(0) assembler = VectorAssembler(inputCols=["industrial_ratio", "energy_ratio"], outputCol="features") final_data = assembler.transform(structure_with_ratios) kmeans = KMeans(featuresCol="features", k=k) model = kmeans.fit(final_data) clustered_data = model.transform(final_data).select("province", "prediction") return clustered_data.toPandas().to_dict('records')