1. 创始时间与作者
2. 官方资源
3. 核心功能
4. 应用场景
1. 数据持久化存储
import pickle
import os
# 定义复杂数据结构
data = {
'name': '张三',
'age': 30,
'skills': ['Python', '机器学习', '数据分析'],
'projects': {
'current': '智能推荐系统',
'completed': ['电商平台', '财务系统']
}
}
# 序列化到文件
with open('user_data.pkl', 'wb') as f:
pickle.dump(data, f)
print(f"文件大小: {os.path.getsize('user_data.pkl')} 字节")
# 从文件反序列化
with open('user_data.pkl', 'rb') as f:
loaded_data = pickle.load(f)
print(f"恢复的数据: {loaded_data}")
2. 机器学习模型保存
import pickle
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
# 生成示例数据
X, y = make_classification(n_samples=1000, n_features=20, random_state=42)
# 训练模型
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X, y)
# 保存模型
with open('model.pkl', 'wb') as f:
pickle.dump(model, f)
# 加载并预测
with open('model.pkl', 'rb') as f:
loaded_model = pickle.load(f)
# 创建新数据进行预测
new_data = np.random.randn(1, 20)
prediction = loaded_model.predict(new_data)
print(f"预测结果: {prediction}")
3. 分布式计算任务传递
import pickle
import multiprocessing as mp
def process_task(task_data):
"""处理任务的函数"""
# 这里模拟一些处理逻辑
result = sum(task_data) *2
return result
def worker(task_pickle):
"""工作进程函数"""
# 反序列化任务
task_data = pickle.loads(task_pickle)
result = process_task(task_data)
# 序列化结果
return pickle.dumps(result)
# 主进程
if __name__ == '__main__':
# 创建任务数据
tasks = [
[1, 2, 3, 4, 5],
[10, 20, 30],
[100, 200, 300, 400]
]
# 创建进程池
with mp.Pool(processes=3) as pool:
# 序列化任务并提交
pickled_tasks = [pickle.dumps(task) for task in tasks]
results = pool.map(worker, pickled_tasks)
# 反序列化结果
decoded_results = [pickle.loads(result) for result in results]
print(f"处理结果: {decoded_results}")
4. 缓存计算结果
import pickle
import hashlib
import time
import os
class PickleCache:
"""基于pickle的缓存系统"""
def __init__(self, cache_dir='.cache'):
self.cache_dir = cache_dir
os.makedirs(cache_dir, exist_ok=True)
def _get_cache_path(self, key):
"""获取缓存文件路径"""
# 使用MD5哈希作为文件名
key_hash = hashlib.md5(key.encode()).hexdigest()
return os.path.join(self.cache_dir, f"{key_hash}.pkl")
def get(self, key, func=None, *args, **kwargs):
"""获取缓存或计算结果"""
cache_path = self._get_cache_path(key)
# 检查缓存是否存在
if os.path.exists(cache_path):
try:
with open(cache_path, 'rb') as f:
print(f"从缓存加载: {key}")
return pickle.load(f)
except (pickle.UnpicklingError, EOFError):
print(f"缓存损坏,重新计算: {key}")
# 计算并缓存结果
if func is None:
raise ValueError("需要提供计算函数")
result = func(*args, **kwargs)
# 保存到缓存
with open(cache_path, 'wb') as f:
pickle.dump(result, f)
print(f"计算并缓存: {key}")
return result
# 使用示例
def expensive_computation(n):
"""模拟耗时计算"""
time.sleep(2) # 模拟耗时
return sum(range(n))
cache = PickleCache()
# 第一次计算(耗时)
start = time.time()
result1 = cache.get("sum_1000000", expensive_computation, 1000000)
print(f"结果1: {result1}, 耗时: {time.time() - start:.2f}秒")
# 第二次相同计算(快速从缓存加载)
start = time.time()
result2 = cache.get("sum_1000000", expensive_computation, 1000000)
print(f"结果2: {result2}, 耗时: {time.time() - start:.2f}秒")
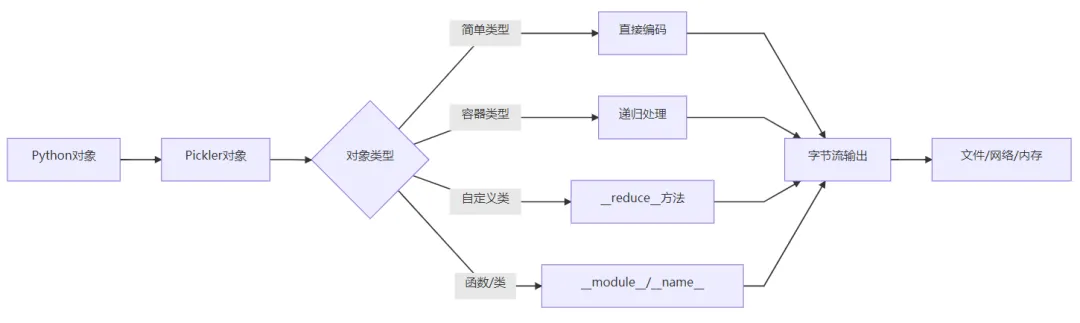
5. 底层逻辑与技术原理
序列化过程架构
关键技术实现
协议设计:
对象序列化过程:
# 简化版序列化流程
def pickle_object(obj):
# 1. 检查对象类型
obj_type = type(obj)
# 2. 查找对应的序列化器
if hasattr(obj, '__reduce_ex__'):
# 使用对象的自定义序列化方法
return obj.__reduce_ex__(protocol)
elif obj_type in _dispatch_table:
# 使用注册的序列化函数
return _dispatch_table[obj_type](obj)
else:
# 默认序列化逻辑
return default_serialize(obj)
递归处理机制:
反序列化过程:
字节码解释执行重建对象
__setstate__方法恢复对象状态
安全验证和类型检查
6. 安装与配置
基础说明
pickle是Python标准库的一部分,无需单独安装
# 验证pickle模块
python -c "import pickle; print(f'pickle版本: {pickle.__version__}')"
Python版本对应关系
| Python版本 | pickle默认协议 | 支持协议 | 重要特性 |
|---|
| Python 2.3-2.7 | 协议0 | 0,1,2 | 支持cPickle加速 |
| Python 3.0-3.3 | 协议3 | 0,1,2,3 | 默认协议3,Unicode支持 |
| Python 3.4-3.7 | 协议3 | 0,1,2,3,4 | 协议4支持大对象 |
| Python 3.8+ | 协议4 | 0,1,2,3,4,5 | 协议5带外数据 |
性能优化安装
# Python 2中可使用cPickle获得更好性能
# Python 3中pickle模块已用C实现,无需额外安装
# 安装pickle5以在旧版本中使用协议5
pip install pickle5
验证安装与版本
import pickle
import sys
print(f"Python版本: {sys.version}")
print(f"pickle模块: {pickle.__name__}")
print(f"最高支持协议: {pickle.HIGHEST_PROTOCOL}")
print(f"默认协议: {pickle.DEFAULT_PROTOCOL}")
# 测试序列化
test_obj = {"name": "test", "value": 123}
pickled = pickle.dumps(test_obj)
print(f"序列化大小: {len(pickled)} 字节")
# 测试反序列化
unpickled = pickle.loads(pickled)
print(f"反序列化验证: {unpickled == test_obj}")
7. 性能特点与优化
协议性能对比
import pickle
import time
import sys
def benchmark_protocol(obj, protocol):
"""测试不同协议的序列化性能"""
start = time.time()
data = pickle.dumps(obj, protocol=protocol)
dump_time = time.time() -start
start = time.time()
pickle.loads(data)
load_time = time.time() -start
return len(data), dump_time, load_time
# 测试数据
test_data = {
'list': list(range(10000)),
'dict': {str(i): i for i in range(1000)},
'nested': [[[i for i in range(10)] for _ in range(10)] for _ in range(10)]
}
print("协议性能对比:")
print("="*60)
print(f"{'协议':<10} {'大小(字节)':<15} {'序列化时间(s)':<15} {'反序列化时间(s)':<15}")
print("-"*60)
for protocol in range(pickle.HIGHEST_PROTOCOL+1):
size, dump_t, load_t = benchmark_protocol(test_data, protocol)
print(f"{protocol:<10} {size:<15} {dump_t:<15.6f} {load_t:<15.6f}")
内存优化技巧
import pickle
import io
class OptimizedPickler:
"""优化版Pickler,减少内存使用"""
@staticmethod
def dump_to_bytes(obj, protocol=None):
"""直接序列化到字节,避免中间字符串"""
file = io.BytesIO()
pickler = pickle.Pickler(file, protocol=protocol)
# 优化:禁用备忘录以减少内存(适用于无循环引用的对象)
pickler.fast = True
pickler.dump(obj)
return file.getvalue()
@staticmethod
def dump_compressed(obj, protocol=None):
"""压缩序列化数据"""
import zlib
data = pickle.dumps(obj, protocol=protocol)
compressed = zlib.compress(data)
print(f"压缩率: {len(compressed)/len(data)*100:.1f}%")
return compressed
@staticmethod
def load_compressed(compressed_data):
"""加载压缩的数据"""
import zlib
data = zlib.decompress(compressed_data)
return pickle.loads(data)
# 使用示例
data = {"key": "value"*1000}
optimized = OptimizedPickler()
# 普通序列化
normal = pickle.dumps(data)
print(f"普通序列化大小: {len(normal)} 字节")
# 优化序列化
optimized_bytes = optimized.dump_to_bytes(data)
print(f"优化序列化大小: {len(optimized_bytes)} 字节")
# 压缩序列化
compressed = optimized.dump_compressed(data)
print(f"压缩后大小: {len(compressed)} 字节")
8. 安全注意事项
反序列化安全风险
import pickle
# 危险的反序列化示例(不要在生产环境使用)
class MaliciousClass:
def __reduce__(self):
# 反序列化时会执行系统命令
import os
return (os.system, ('echo "恶意代码执行"',))
# 创建恶意对象
malicious = MaliciousClass()
malicious_data = pickle.dumps(malicious)
# 反序列化会执行命令(危险!)
# pickle.loads(malicious_data) # 不要执行!
安全反序列化方案
import pickle
import builtins
class SafeUnpickler(pickle.Unpickler):
"""安全的Unpickler,限制可加载的类"""
# 白名单:只允许这些模块中的类
SAFE_MODULES = {
'__builtin__': ['list', 'dict', 'tuple', 'str', 'int', 'float'],
'builtins': ['list', 'dict', 'tuple', 'str', 'int', 'float', 'bool'],
'collections': ['OrderedDict', 'defaultdict'],
'datetime': ['datetime', 'date', 'time'],
'decimal': ['Decimal'],
'fractions': ['Fraction'],
'types': ['MappingProxyType'],
}
def find_class(self, module, name):
# 检查模块是否在白名单中
if module in self.SAFE_MODULES:
if name in self.SAFE_MODULES[module]:
# 安全导入
return getattr(__import__(module), name)
# 拒绝不安全的类
raise pickle.UnpicklingError(
f"禁止加载类: {module}.{name}"
)
def safe_loads(data):
"""安全地加载pickle数据"""
import io
file = io.BytesIO(data)
return SafeUnpickler(file).load()
# 使用示例
safe_data = {'name': '安全数据', 'value': 123}
pickled = pickle.dumps(safe_data)
try:
result = safe_loads(pickled)
print(f"安全加载成功: {result}")
except pickle.UnpicklingError as e:
print(f"安全加载失败: {e}")
生产环境最佳实践
import pickle
import hmac
import hashlib
class SignedPickle:
"""签名验证的pickle序列化"""
def __init__(self, secret_key):
self.secret_key = secret_key.encode()
def dumps(self, obj):
"""序列化并签名"""
data = pickle.dumps(obj)
signature = hmac.new(self.secret_key, data, hashlib.sha256).digest()
return signature+data
def loads(self, signed_data):
"""验证签名并反序列化"""
signature = signed_data[:32] # SHA256签名长度
data = signed_data[32:]
# 验证签名
expected_signature = hmac.new(
self.secret_key, data, hashlib.sha256
).digest()
if not hmac.compare_digest(signature, expected_signature):
raise ValueError("签名验证失败")
return pickle.loads(data)
# 使用示例
secret = "my-secret-key"
sp = SignedPickle(secret)
data = {"user": "alice", "balance": 1000}
signed = sp.dumps(data)
print(f"签名数据长度: {len(signed)}")
# 验证并加载
loaded = sp.loads(signed)
print(f"加载的数据: {loaded}")
# 尝试篡改数据
tampered = signed[:-10] +b'xxx'+signed[-7:]
try:
sp.loads(tampered)
except ValueError as e:
print(f"篡改检测: {e}")
9. 高级功能与技巧
自定义序列化
import pickle
class CustomObject:
"""支持自定义序列化的对象"""
def __init__(self, name, data):
self.name = name
self.data = data
self._cache = {} # 不序列化的属性
def __getstate__(self):
"""控制序列化的状态"""
state = self.__dict__.copy()
# 删除不需要序列化的属性
del state['_cache']
# 可以添加额外信息
state['_version'] = '1.0'
return state
def __setstate__(self, state):
"""控制反序列化的状态"""
version = state.pop('_version', '1.0')
self.__dict__.update(state)
# 恢复默认值
self._cache = {}
# 版本迁移逻辑
if version == '1.0':
self._migrate_from_v1()
def _migrate_from_v1(self):
"""从版本1迁移数据"""
if hasattr(self, 'old_field'):
self.data = self.old_field*2
delattr(self, 'old_field')
def __reduce__(self):
"""更底层的序列化控制"""
# 返回 (构造函数, 参数, 状态)
return (
self.__class__, # 可调用对象
(self.name, self.data), # 参数
self.__getstate__() # 状态
)
# 测试自定义序列化
obj = CustomObject("测试对象", [1, 2, 3])
obj._cache['temp'] = '不保存的数据'
# 序列化
data = pickle.dumps(obj)
print(f"序列化大小: {len(data)} 字节")
# 反序列化
new_obj = pickle.loads(data)
print(f"恢复的对象: {new_obj.name}")
print(f"数据: {new_obj.data}")
print(f"缓存是否恢复: {hasattr(new_obj, '_cache')}")
协议5带外数据
import pickle
# 协议5支持带外数据传输,适合大数据处理
def use_protocol5():
"""使用协议5的带外数据功能"""
import numpy as np
# 创建大数据
large_array = np.random.randn(10000, 10000) # 800MB数据
# 使用协议5序列化
buffers = []
data = pickle.dumps(
{
'metadata': {'shape': large_array.shape, 'dtype': str(large_array.dtype)},
'array': large_array
},
protocol=5,
buffer_callback=buffers.append# 缓冲区回调
)
print(f"元数据大小: {len(data)} 字节")
print(f"缓冲区数量: {len(buffers)}")
print(f"第一个缓冲区大小: {buffers[0].nbytes if buffers else 0} 字节")
# 可以分别传输元数据和缓冲区
return data, buffers
# 注意:协议5需要Python 3.8+
if pickle.HIGHEST_PROTOCOL>= 5:
print("支持协议5")
# use_protocol5() # 需要大量内存,谨慎运行
else:
print("不支持协议5")
10. 替代方案与比较
序列化方案对比
| 特性 | pickle | json | msgpack | protobuf | yaml |
|---|
| Python对象支持 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ | ⭐ | ⭐⭐⭐⭐ |
| 跨语言支持 | ⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 性能 | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐ |
| 数据大小 | ⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐ |
| 可读性 | ⭐ | ⭐⭐⭐⭐⭐ | ⭐ | ⭐ | ⭐⭐⭐⭐⭐ |
| 安全性 | ⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| 模式演进 | ⭐⭐ | ⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
pickle适用场景总结
使用pickle的场景:
Python内部数据交换
机器学习模型持久化
临时缓存存储
进程间通信(相同Python版本)
复杂对象图的保存
避免使用pickle的场景:
跨语言数据交换
不可信数据源的反序列化
长期数据存储(格式可能变化)
需要人类可读的数据存储
需要严格模式演进的数据
11. 企业级应用案例
1. 机器学习平台
2. 分布式计算框架
Celery:任务序列化传递
Dask:分布式任务调度
Ray:Actor和任务序列化
3. Web框架
Django:会话数据存储
Flask:缓存后端支持
FastAPI:依赖项缓存
4. 数据分析平台
Pandas:DataFrame序列化选项
Jupyter:Notebook内核通信
Apache Airflow:任务状态序列化
总结
pickle是Python生态中不可或缺的对象序列化工具,核心价值在于:
原生Python支持:无需第三方库,开箱即用
完整对象序列化:支持几乎所有Python对象类型
协议演进:6个协议版本适应不同需求
生态系统集成:广泛用于机器学习、Web开发、科学计算
技术特色:
递归对象图序列化
循环引用处理
自定义序列化控制
协议版本向后兼容
安全警告:
永远不要反序列化不受信任的数据
使用白名单机制限制可加载的类
考虑使用签名验证数据完整性
最佳实践:
生产环境使用最高协议版本
大对象使用协议5带外数据传输
长期存储数据考虑兼容性问题
跨Python版本使用注意协议差异
替代方案建议:
学习资源:
官方文档:https://docs.python.org/3/library/pickle.html
Python源码:Lib/pickle.py(优秀的学习材料)
《Python Cookbook》第5章:文件与IO
pickle作为Python标准库的一部分,其代码质量、文档完整性和社区支持都是最高水平的。虽然存在安全风险,但在正确的使用场景下,它是Python开发者最强大的工具之一。