# pip install pandas numpy scikit-learn matplotlib seaborn joblib scipyimport osimport pandas as pdimport numpy as npfrom sklearn.svm import SVRfrom sklearn.model_selection import RandomizedSearchCVfrom sklearn.preprocessing import StandardScalerfrom sklearn.metrics import mean_squared_error, mean_absolute_error, r2_scorefrom sklearn.ensemble import RandomForestRegressorimport matplotlib.pyplot as pltimport seaborn as snsfrom datetime import datetimeimport warningsimport joblibfrom scipy.stats import loguniform, uniformwarnings.filterwarnings('ignore')# 设置中文字体plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'DejaVu Sans']plt.rcParams['axes.unicode_minus'] = Falsedef main():# 获取桌面路径并创建结果文件夹 desktop_path = os.path.join(os.path.expanduser("~"), "Desktop") data_path = os.path.join(desktop_path, "Results时间", "combined_weather_disease_data.csv") results_path = os.path.join(desktop_path, "Results时间SVM")# 创建子文件夹 subfolders = ["Models", "Predictions", "Plots", "Feature_Importance","Partial_Dependence", "SVM_Analysis"]for folder in subfolders: folder_path = os.path.join(results_path, folder)if not os.path.exists(folder_path): os.makedirs(folder_path)print("开始SVM疾病预测建模...")# 检查数据文件是否存在if not os.path.exists(data_path):print(f"错误: 数据文件不存在于 {data_path}")print("请确保桌面上的 'Results时间XGB' 文件夹中包含 'combined_weather_disease_data.csv' 文件")return# 读取数据 try:print(f"从 {data_path} 读取数据...") combined_data = pd.read_csv(data_path) combined_data['timestamp'] = pd.to_datetime(combined_data['timestamp'])print("数据读取成功!")print(f"数据形状: {combined_data.shape}")print(f"数据列名: {list(combined_data.columns)}") except Exception as e:print(f"读取数据时出错: {e}")return# 选择要建模的疾病 target_diseases = ["influenza", "common_cold", "pneumonia","bacillary_dysentery", "hand_foot_mouth","hemorrhagic_fever"]# 检查目标疾病列是否存在 available_diseases = [disease for disease in target_diseases if disease in combined_data.columns]if not available_diseases:print("错误: 数据中未找到任何目标疾病列")print(f"数据中的列: {list(combined_data.columns)}")returnprint("目标疾病:", ", ".join(available_diseases)) def create_features(data):"""优化的特征工程函数""" df = data.copy()# 时间特征 df['year'] = df['timestamp'].dt.year df['month'] = df['timestamp'].dt.month df['day'] = df['timestamp'].dt.day df['week'] = df['timestamp'].dt.isocalendar().week df['day_of_week'] = df['timestamp'].dt.dayofweek + 1 df['quarter'] = df['timestamp'].dt.quarter df['day_of_year'] = df['timestamp'].dt.dayofyear df['is_weekend'] = (df['day_of_week'].isin([6, 7])).astype(int)# 季节特征 - 使用更高效的方法 season_map = { 12: 'Winter', 1: 'Winter', 2: 'Winter', 3: 'Spring', 4: 'Spring', 5: 'Spring', 6: 'Summer', 7: 'Summer', 8: 'Summer', 9: 'Fall', 10: 'Fall', 11: 'Fall' } df['season'] = df['month'].map(season_map)# 只创建最重要的滞后特征 weather_cols = ['temp_mean', 'humidity_mean']for col in weather_cols:if col in df.columns:# 只保留最重要的滞后值 df[f'{col}_lag7'] = df[col].shift(7) df[f'{col}_lag30'] = df[col].shift(30)# 滑动窗口特征 - 使用更快的计算方法for col in ['temp_mean', 'humidity_mean']:if col in df.columns: df[f'{col}_rollmean7'] = df[col].rolling(7, min_periods=1).mean()# 季节性特征 df['sin_day'] = np.sin(2 * np.pi * df['day_of_year'] / 365) df['cos_day'] = np.cos(2 * np.pi * df['day_of_year'] / 365)# 为每种疾病创建滞后特征 - 只保留最重要的for disease in available_diseases:if disease in df.columns: df[f'{disease}_lag7'] = df[disease].shift(7) df[f'{disease}_rollmean7'] = df[disease].rolling(7, min_periods=1).mean()# 移除由于滞后产生的NA df = df.dropna()return df# 应用特征工程print("正在进行特征工程...") featured_data = create_features(combined_data)print(f"特征工程后数据形状: {featured_data.shape}")# 定义基础特征 - 精简特征集 base_features = [# 气象特征"temp_max", "temp_min", "temp_mean","humidity_max", "humidity_min", "humidity_mean","wind_mean", "pressure_mean", "precipitation_total", "sunshine_hours",# 时间特征"year", "month", "week", "day_of_week", "day_of_year","is_weekend", "quarter",# 气象滞后特征"temp_mean_lag7", "temp_mean_lag30","humidity_mean_lag7", "humidity_mean_lag30",# 滑动窗口特征"temp_mean_rollmean7", "humidity_mean_rollmean7",# 季节性特征"sin_day", "cos_day" ]# 只保留实际存在的特征 base_features = [f for f in base_features if f in featured_data.columns]print(f"可用基础特征数量: {len(base_features)}")# 存储结果 results_summary = [] predictions_list = {} models_list = {} feature_importance_list = {}# 对每种疾病进行建模for disease in available_diseases:if disease not in featured_data.columns:print(f"跳过疾病 {disease},数据中不存在该列")continueprint(f"\n正在处理疾病: {disease}")# 添加该疾病的滞后特征 disease_specific_features = base_features + [ f"{disease}_lag7", f"{disease}_rollmean7" ]# 只保留存在的特征 available_features = [f for f in disease_specific_features if f in featured_data.columns] available_features.append(disease)# 创建完整数据集 model_data = featured_data[available_features].copy() model_data = model_data.dropna()if len(model_data) == 0:print(f" 数据不足,跳过疾病 {disease}")continue# 划分训练集和测试集 train_data = model_data[model_data['year'] < 2016] test_data = model_data[model_data['year'] >= 2016]print(f" 训练集大小: {len(train_data)}, 测试集大小: {len(test_data)}")if len(train_data) == 0 or len(test_data) == 0:print(f" 数据不足,跳过疾病 {disease}")continue# 准备特征矩阵和目标向量 X_train = train_data.drop(columns=[disease]) y_train = train_data[disease] X_test = test_data.drop(columns=[disease]) y_test = test_data[disease]# 数据标准化(SVM对特征尺度敏感) scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test)
# 使用最佳参数训练最终模型 best_svr = random_search.best_estimator_# 预测 train_pred = best_svr.predict(X_train_scaled) test_pred = best_svr.predict(X_test_scaled)# 计算评估指标 train_rmse = np.sqrt(mean_squared_error(y_train, train_pred)) test_rmse = np.sqrt(mean_squared_error(y_test, test_pred)) train_mae = mean_absolute_error(y_train, train_pred) test_mae = mean_absolute_error(y_test, test_pred) train_r2 = r2_score(y_train, train_pred) test_r2 = r2_score(y_test, test_pred)# 存储结果 disease_results = {'Disease': disease,'Train_Size': len(train_data),'Test_Size': len(test_data),'Train_RMSE': train_rmse,'Test_RMSE': test_rmse,'Train_MAE': train_mae,'Test_MAE': test_mae,'Train_R2': train_r2,'Test_R2': test_r2,'SVM_Cost': random_search.best_params_['C'],'SVM_Gamma': random_search.best_params_['gamma'],'SVM_Epsilon': random_search.best_params_['epsilon'] } results_summary.append(disease_results)# 存储预测结果 test_dates = featured_data.loc[ test_data.index, 'timestamp'] if'timestamp'in featured_data.columns else test_data.index pred_df = pd.DataFrame({'Date': test_dates,'Actual': y_test.values,'Predicted': test_pred,'Disease': disease }) predictions_list[disease] = pred_df# 存储模型 models_list[disease] = {'model': best_svr,'scaler': scaler,'features': X_train.columns.tolist(),'best_params': random_search.best_params_ }# 使用更快的特征重要性计算方法print(" 计算特征重要性...")# 使用更少的树和并行计算 rf_model = RandomForestRegressor( n_estimators=50, # 减少树的数量 random_state=42, n_jobs=-1, # 使用所有CPU核心 max_features='sqrt'# 减少特征考虑数量 ) rf_model.fit(X_train, y_train) importance_df = pd.DataFrame({'Feature': X_train.columns,'Importance': rf_model.feature_importances_ }).sort_values('Importance', ascending=False) feature_importance_list[disease] = importance_df# 并行保存特征重要性数据 importance_df.to_csv(os.path.join(results_path, f'Feature_Importance/{disease}_Feature_Importance.csv'), index=False)# 只生成最重要的可视化图表 try:
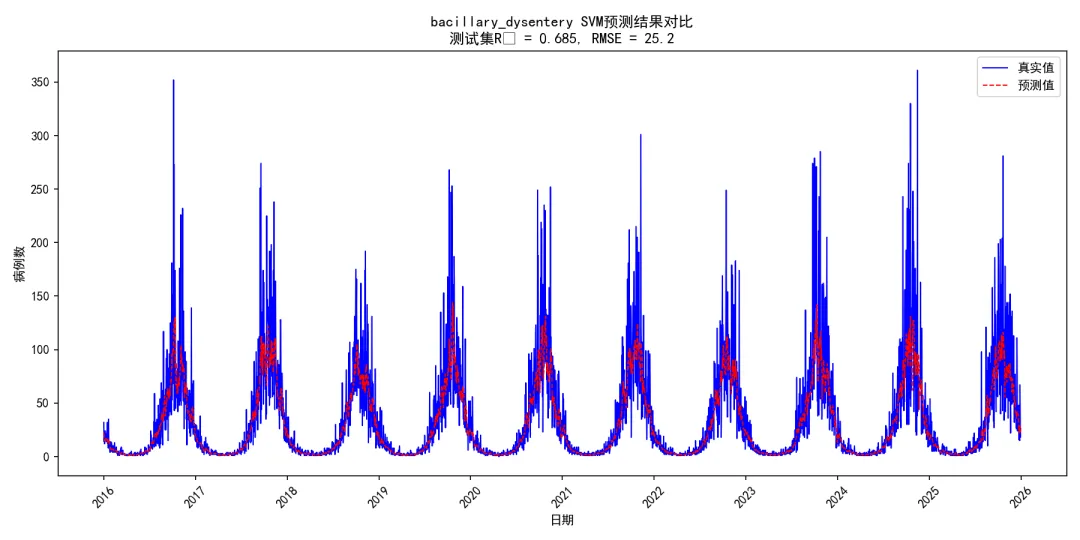
# 1. 预测结果对比图 plt.figure(figsize=(12, 6)) plt.plot(pred_df['Date'], pred_df['Actual'], label='真实值', linewidth=1, color='blue') plt.plot(pred_df['Date'], pred_df['Predicted'], label='预测值', linewidth=1, linestyle='--', color='red') plt.title(f'{disease} SVM预测结果对比\n测试集R² = {test_r2:.3f}, RMSE = {test_rmse:.1f}') plt.xlabel('日期') plt.ylabel('病例数') plt.legend() plt.xticks(rotation=45) plt.tight_layout() plt.savefig(os.path.join(results_path, f'Plots/{disease}_SVM_Results_Comparison.png'), dpi=150) # 降低DPI plt.close()
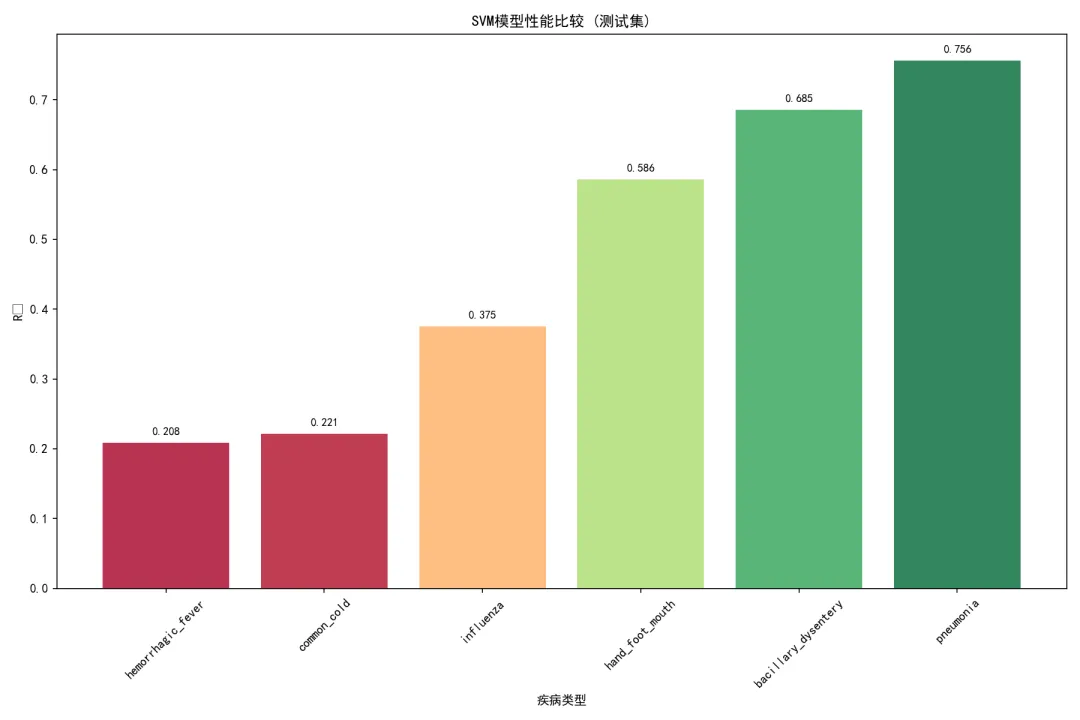
# 2. 特征重要性图 (只显示前10个) plt.figure(figsize=(10, 6)) top_features = importance_df.head(10) # 只显示前10个 plt.barh(top_features['Feature'], top_features['Importance']) plt.title(f'{disease} 特征重要性 (前10)') plt.xlabel('重要性') plt.tight_layout() plt.savefig(os.path.join(results_path, f'Plots/{disease}_Feature_Importance.png'), dpi=150) plt.close() except Exception as e:print(f" 可视化图表生成失败: {e}")print(f" {disease} 建模完成")# 保存总体结果if results_summary: results_df = pd.DataFrame(results_summary) results_df.to_csv(os.path.join(results_path, "Model_Performance_Summary.csv"), index=False)# 保存预测结果 all_predictions = pd.concat(predictions_list.values(), ignore_index=True) all_predictions.to_csv(os.path.join(results_path, "Predictions/All_Disease_Predictions.csv"), index=False)# 只生成关键的可视化图表# 模型性能比较图 plt.figure(figsize=(12, 8)) results_sorted = results_df.sort_values('Test_R2') colors = plt.cm.RdYlGn((results_sorted['Test_R2'] - results_sorted['Test_R2'].min()) / (results_sorted['Test_R2'].max() - results_sorted['Test_R2'].min())) bars = plt.bar(range(len(results_sorted)), results_sorted['Test_R2'], color=colors, alpha=0.8) plt.title('SVM模型性能比较 (测试集)') plt.xlabel('疾病类型') plt.ylabel('R²') plt.xticks(range(len(results_sorted)), results_sorted['Disease'], rotation=45)# 添加数值标签for i, bar in enumerate(bars): height = bar.get_height() plt.text(bar.get_x() + bar.get_width() / 2., height + 0.01, f'{height:.3f}', # 只显示R²值 ha='center', va='bottom', fontsize=9) plt.tight_layout() plt.savefig(os.path.join(results_path, "Plots/Model_Performance_Comparison.png"), dpi=150) plt.close()# 批量保存模型for disease, model_info in models_list.items(): joblib.dump(model_info, os.path.join(results_path, f'Models/{disease}_svm_model.pkl'))# 生成最终报告print("\n=== SVM建模完成 ===")print(f"建模疾病数量: {len(models_list)}")print("训练集时间范围: 1981-2015")print("测试集时间范围: 2016-2025")print(f"总特征数量: {len(base_features) + len(available_diseases) * 2}\n") # 更新特征数量if results_summary: results_df = pd.DataFrame(results_summary)print("模型性能总结:")print(results_df.to_string(index=False)) best_model = results_df.loc[results_df['Test_R2'].idxmax()] worst_model = results_df.loc[results_df['Test_R2'].idxmin()]print(f"\n最佳性能模型:")print(f"疾病: {best_model['Disease']}, 测试集R²: {best_model['Test_R2']:.3f}, " f"RMSE: {best_model['Test_RMSE']:.1f}")print(f"\n最差性能模型:")print(f"疾病: {worst_model['Disease']}, 测试集R²: {worst_model['Test_R2']:.3f}, " f"RMSE: {worst_model['Test_RMSE']:.1f}")# 计算平均性能 avg_r2 = results_df['Test_R2'].mean() avg_rmse = results_df['Test_RMSE'].mean()print(f"\n平均性能:")print(f"平均测试集R²: {avg_r2:.3f}")print(f"平均测试集RMSE: {avg_rmse:.1f}")print("\n文件输出:")print(f"1. {results_path}/Model_Performance_Summary.csv - 模型性能汇总")print(f"2. {results_path}/Predictions/All_Disease_Predictions.csv - 所有预测结果")print(f"3. {results_path}/Models/ - 所有训练好的SVM模型")print(f"4. {results_path}/Plots/ - 各种可视化图表")print(f"5. {results_path}/Feature_Importance/ - 特征重要性数据")print(f"\n结果文件夹位置: {results_path}")# 公共卫生意义分析print("\n=== 公共卫生意义分析 ===")print("基于特征工程的SVM模型在疾病预测中的优势:")print("1. 多源数据整合: 能够整合气象数据、时间特征和疾病历史数据")print("2. 非线性关系建模: SVM能够捕捉疾病与影响因素之间的复杂非线性关系")print("3. 泛化能力强: 通过核技巧在高维特征空间中寻找最优分离超平面")print("\n关键发现:")for disease in available_diseases:if disease in feature_importance_list: top_features = feature_importance_list[disease]['Feature'].head(3).tolist()print(f"- {disease}: 最重要的特征包括 {', '.join(top_features)}")if __name__ == "__main__": main()









 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
