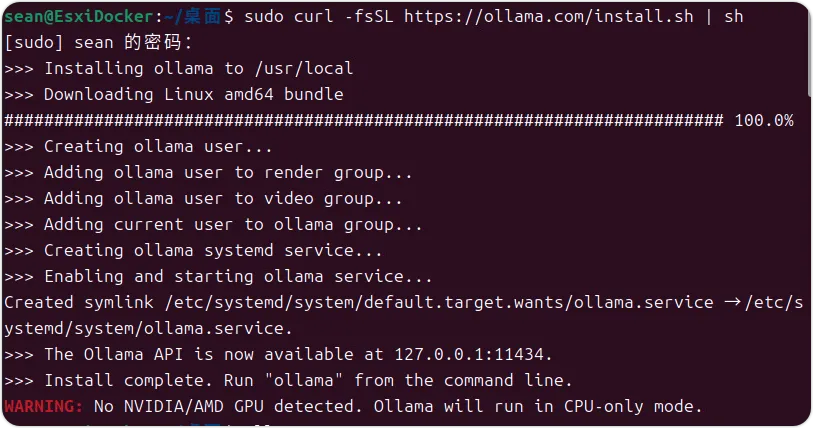
本文以ubuntu24.04为例,使用ubuntu是因为其第三方显卡的驱动。安装的先决条件:因ollama的安装是直接使用在线安装脚本进行安装,故首先需要可以访问到github。web界面使用docker容器运行,也确保可以从公共仓库中拉取open-webui的镜像。以下是 Ollama 和 DeepSeek 的部署方法:Ollama 部署
curl -fsSL https://ollama.com/install.sh | sh。
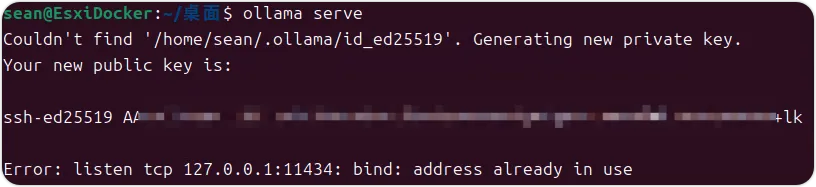
因为我是在esxi里面的虚拟机中做的这个文章的演示,且我没有开启显卡直通,所以这里安装完成后会有告警信息,说没有找到GPU,将使用CPU模式运行。启动 Ollama:在终端运行命令 ollama serve 启动 Ollama 服务。启动过程中会创建一个公钥和私钥并监听本地的11434端口。DeepSeek 部署
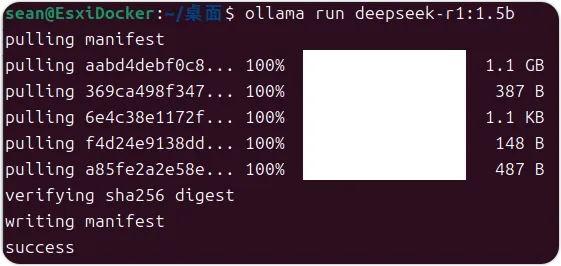
通过 Ollama 部署:上面的ollama已经部署完成,下面通过命令运行deepseek模型即可,命令如果是首次运行,会下面对应的模型。所以先根据自己的磁盘空间等情况选择合适的模型版本。根据硬件选择合适的模型版本,例如运行 1.5B 模型,可执行命令 ollama run deepseek-r1:1.5b;因为是虚机的演示,这里我就仅使用了1.1G大小的1.5B模型。若要运行更大规模的模型,如 70B 模型或者671B 模型,可执行命令 ollama run deepseek-r1:70b或ollama run deepseek-r1:671b。
通过 API 交互:启动 Ollama 服务后,可通过 HTTP 请求与模型交互。例如,向 http://localhost:11434/api/generate 发送 POST 请求,请求体中包含模型名称、是否流式传输以及提示内容。使用 Open WebUI
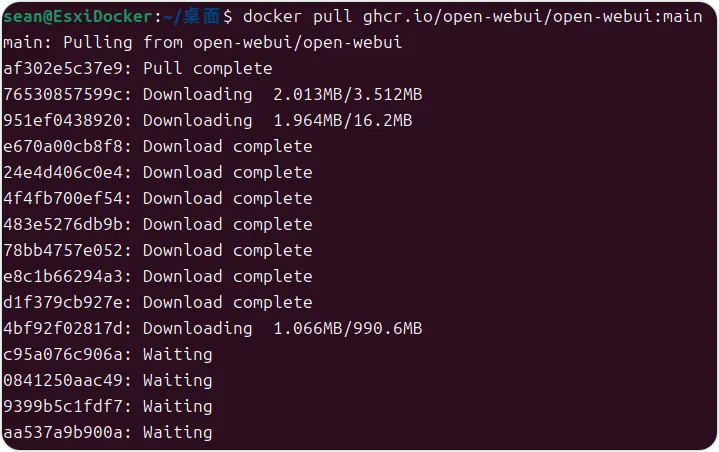
docker pull ghcr.io/open-webui/open-webui:main
docker run -d-p3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
访问 WebUI: 打开浏览器,输入 http://localhost:3000/,进入 WebUI 界面。


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
