在 Mac、Linux 与 Windows 上使用 Unsloth 运行 Qwen3-Coder-Next
一份关于高效配置与部署的完整实践指南(含代码)
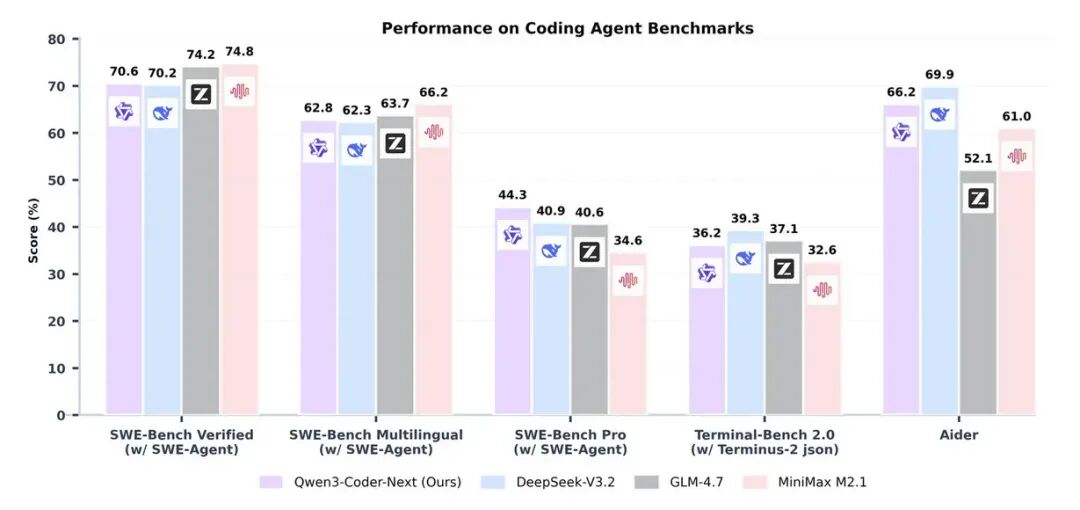
阿里巴巴近期推出的 Qwen3-Coder-Next 模型,凭借其 800 亿参数的混合专家架构 (Mixture-of-Experts, MoE),在推理时仅激活约 30 亿参数。这种高效设计使其性能远超其参数量级,在 SWE-Bench Verified 基准测试中取得了 74.8% 的分数,足以挑战参数量为其 10 至 20 倍的模型。
这意味着开发者可以实现更快的迭代周期、更强的数据隐私保护以及显著的成本节约,而无需依赖云端 API。借助 Unsloth 的优化技术,该模型得以在消费级硬件上部署,使得先进的智能编码代理变得触手可及。本文将全面阐述其配置流程,特别针对 Mac 桌面设备及其他平台进行适配,并分享相关洞见,以助力开发者构建更稳健的 AI 集成方案。
Qwen3-Coder-Next 何以成为变革者
Qwen3-Coder-Next 专为编码代理与本地开发场景设计。与通用模型不同,它在代理任务 (Agentic Tasks) 方面表现卓越,能够熟练处理复杂的工具调用、长程推理以及执行错误的恢复。其 256K 的上下文长度足以支撑复杂的代码库,使其能够管理多步骤流程,例如网页开发、浏览器交互,乃至与 OpenClaw、Claude Code 等工具的集成。
 Image
Image该模型的 MoE 架构是其效率的关键。每个令牌仅激活部分专家网络,从而在保持高性能的同时显著降低了计算需求。无论是生成 HTML 版的 Flappy Bird 游戏,还是通过集成工具执行 shell 命令,它都能轻松胜任,且无需承受远程服务器的延迟。
Unsloth 通过提供动态的 GGUF 量化 (GGUF Quantizations) 进一步增强了这一优势。该技术能在不明显损失模型质量的前提下压缩模型体积,使其能够在统一内存低至 46GB 的硬件上部署,从而为 Mac 桌面设备或中端 PC 提供了可行性。
硬件与软件需求:启程前的准备
在深入配置之前,有必要明确基本要求。Qwen3-Coder-Next 的资源需求随量化级别而变化,但 Unsloth 的优化使其保持在可控范围内。
硬件规格
- • 4 位量化的最低要求(推荐起点):46GB 统一内存(RAM + VRAM)。这适用于 UD-Q4_K_XL 量化级别,能在速度与质量间取得良好平衡。对于采用 Apple Silicon(M1 Max 或更新)的 Mac,这意味着需要 Mac Studio 或配备 64GB+ 统一内存的 MacBook Pro。对于 PC,则需要配备 24GB VRAM 的 NVIDIA GPU(如 RTX 4090)并搭配 32GB 系统内存。
- • 较低量化级别(2-3 位):30-40GB,适合入门级配置,如 32GB 内存的 MacBook Air 或配备 RTX 3060 的笔记本电脑。
- • 较高量化级别(8 位或 FP8):85GB+,适用于高端设备,如配备多 GPU 的服务器或拥有 128GB 统一内存的 Mac。
- • 性能说明:若希望达到每秒 20+ 个令牌的生成速度,应确保整个模型能完全载入内存。若需将部分模型卸载至 CPU 或磁盘,则速度会降至每秒 10-15 个令牌。在 Mac 上,统一内存机制表现良好,它将 RAM 和 VRAM 视为一个统一的内存池。
- • 其他平台:Linux/Windows PC 可利用 NVIDIA GPU 的 CUDA 加速获得性能提升。AMD GPU(如 Instinct MI300X)通过 ROCm 获得了首日支持,但若追求最广泛的兼容性,建议仍使用 NVIDIA 硬件。
软件前提
- • Python 3.10+:脚本编写与 API 交互的必备环境。
- • Git 与 CMake:用于构建运行 GGUF 模型的核心引擎
llama.cpp。 - • Hugging Face CLI:通过
pip install -U huggingface_hub 安装,用于下载模型。 - • OpenAI 库:通过
pip install openai 安装,用于进行兼容 OpenAI API 的推理。 - • llama.cpp:Unsloth 依赖此工具进行高效推理。需根据操作系统从源码构建。
- • 高级使用(可选):对于多 GPU 设置下的高吞吐量服务,可考虑使用
vLLM 或 SGLang。
建议在开始前先对硬件进行基准测试,在 PC 上使用 nvidia-smi,在 Mac 上使用 Activity Monitor 来监控初始运行时的内存使用情况。这有助于避免程序崩溃,并帮助您尽早选择合适的量化级别。
在 Mac 桌面上的逐步配置指南
配备 Apple Silicon 的 Mac 因其统一内存和 llama.cpp 中的 Metal 加速支持,非常适合本地 AI 部署。以下是运行 Qwen3-Coder-Next 的步骤。
步骤 1:安装依赖项
打开终端并运行:
brew install git cmake make
pip install -U huggingface_hub openai
Homebrew 将处理大部分工具的安装;若尚未安装 Homebrew,请从 brew.sh 获取。
步骤 2:构建支持 Metal 的 llama.cpp
克隆并构建代码库:
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
mkdir build && cd build
cmake .. -DGGML_METAL=ON
cmake --build . --config Release
此命令启用 Metal 以实现 GPU 加速。复制生成的二进制文件:cp bin/llama-* ../。
步骤 3:下载模型
使用 Hugging Face CLI 获取量化后的 GGUF 模型:
huggingface-cli download unsloth/Qwen3-Coder-Next-GGUF --include "*UD-Q4_K_XL*" --local-dir ./models
对于 46GB 内存配置,选择 UD-Q4_K_XL。对于 64GB 内存的 Mac,可尝试 Q5_K_M 以获得更好的质量。
步骤 4:运行基础推理测试
使用命令行界面进行测试:
../llama-cli --model ./models/Qwen3-Coder-Next-UD-Q4_K_XL.gguf --ctx-size 32768 --temp 1.0 --top-p 0.95 --min-p 0.01 --top-k 40 --jinja
输入提示词,如“编写一个 Python 快速排序函数”。在 64GB 内存的 M2 Max 芯片上,预期速度约为每秒 30-50 个令牌。
步骤 5:设置 API 服务器
为了与其他工具集成,启动 API 服务器:
../llama-server --model ./models/Qwen3-Coder-Next-UD-Q4_K_XL.gguf --port 8001 --ctx-size 262144 --temp 1.0 --top-p 0.95 --min-p 0.01 --top-k 40 --jinja
现在,可以使用 Python 进行查询:
from openai import OpenAI
client = OpenAI(base_url="http://127.0.0.1:8001/v1", api_key="sk-no-key-required")
response = client.chat.completions.create(
model="Qwen3-Coder-Next",
messages=[{"role": "user", "content": "生成一个 Flask API 骨架。"}]
)
print(response.choices[0].message.content)
此设置模拟了 OpenAI 的 API,便于集成到 VS Code 扩展(如 Continue.dev)中。
在 Mac 上运行时,需注意散热问题,保持设备凉爽以获得持续稳定的性能。
在其他设备上的配置:Linux 与 Windows
对于 Linux 或 Windows 系统,配置过程主要利用 NVIDIA GPU 的 CUDA 加速,为 PC 提供了更大的灵活性。
Linux 配置
安装依赖项:
sudo apt-get update && sudo apt-get install pciutils build-essential cmake curl libcurl4-openssl-dev -y
构建支持 CUDA 的 llama.cpp:
git clone https://github.com/ggml-org/llama.cpp
cmake llama.cpp -B llama.cpp/build -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON
cmake --build llama.cpp/build --config Release -j
cp llama.cpp/build/bin/llama-* llama.cpp/
下载模型并运行的方式与 Mac 类似,但需添加 --gpu-layers 999 参数以实现完整的 GPU 卸载。
Windows 配置
可使用 WSL2 获得类似 Linux 的环境,或使用 Visual Studio 进行原生构建。首先安装 CUDA 工具包(访问 developer.nvidia.com/cuda-downloads)。在 WSL 中遵循上述 Linux 步骤即可。
对于多 GPU 配置,可在 vLLM 中使用 --tensor-parallel-size 2 参数:
vllm serve unsloth/Qwen3-Coder-Next-FP8-Dynamic --tensor-parallel-size 2 --port 8001 --enable-auto-tool-choice --tool-call-parser qwen3_coder
在双 RTX 4090 配置下,此设置可将吞吐量提升至每秒 50+ 个令牌。
跨平台提示:使用 Docker 进行容器化以实现环境可复现性。一个包含 llama.cpp 的简单 Dockerfile 在团队协作扩展时能节省大量时间。
推理与工具调用实践示例
配置完成后,即可充分利用 Qwen3-Coder-Next 的优势。
基础推理
对于快速测试,可使用 CLI;若需集成到脚本中,则可调用 API。对于长上下文场景,可启用 KV 缓存量化:--cache-type-k q4_1 --cache-type-v q4_1。这可将 256K 令牌的内存占用减半。
工具调用
Qwen 原生支持函数调用。在 API 调用中定义工具:
tools = [
{"type": "function", "function": {"name": "add_numbers", "parameters": {"type": "object", "properties": {"a": {"type": "number"}, "b": {"type": "number"}}}}}
]
response = client.chat.completions.create(
model="Qwen3-Coder-Next",
messages=[{"role": "user", "content": "5 加 3 等于多少?"}],
tools=tools,
tool_choice="auto"
)
解析并执行工具调用。对于高级代理,可以添加带有安全包装的“terminal”或“python”工具,以防止有害命令的执行。这使得构建能够本地编辑文件或运行测试的编码代理成为可能。
开发洞见:务必验证工具的输出结果,AI 可能产生参数幻觉,因此应在编排层添加错误处理逻辑。
实现峰值性能的优化技巧
为最大化效率,可考虑以下建议:
- • 量化选择:从 4 位量化(Q4_K_M)开始以取得平衡。在支持的硬件上,使用 FP8 Dynamic 量化可获得 25% 的速度提升。
- • 卸载策略:在内存有限的情况下,可将 MoE 层卸载至 CPU:
--ot ".ffn_.*_exps.=CPU"。 - • 基准测试:使用
--log-disable 参数运行以测量纯推理速度。将 min_p 调整为 0.01 可在不产生重复的情况下获得更多样化的输出。 - • 扩展上下文:对于 256K 上下文,使用
--fit on 参数让其自动调整。 - • 集成:与 VS Code 的
llama.cpp 扩展配对,可实现中间填充编码 (Fill-in-Middle, FIM)。
常见陷阱:忽视 KV 缓存大小可能导致内存溢出错误。可使用 llama-print-timings 进行监控。
面向未来的开发经验:构建可持续的 AI 工作流
效率优先于规模,Qwen3-Coder-Next 等 MoE 模型正凸显出针对性架构如何超越更大规模的模型,这一趋势将在边缘 AI 领域愈发明显。这使得本地部署能够促进隐私保护和定制化,并通过设计可轻松切换模型的模块化代理来避免供应商锁定。
展望未来,可以预见混合本地-云管道的兴起:
- • 在本地运行轻量级推理,将复杂任务升级至云端处理。
- • 随着工具调用功能的普及,需实施防护措施以防止滥用。## 总结
依托 Unsloth 框架,在本地运行 Qwen3-Coder-Next 模型变得极为便捷。无论是在 Mac 桌面环境进行个人开发,还是在 Linux 生产服务器上部署,该方案都能助力实现更快速、更私密的编码体验。希望您能享受这款全新的本地化人工智能助手带来的便利。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
