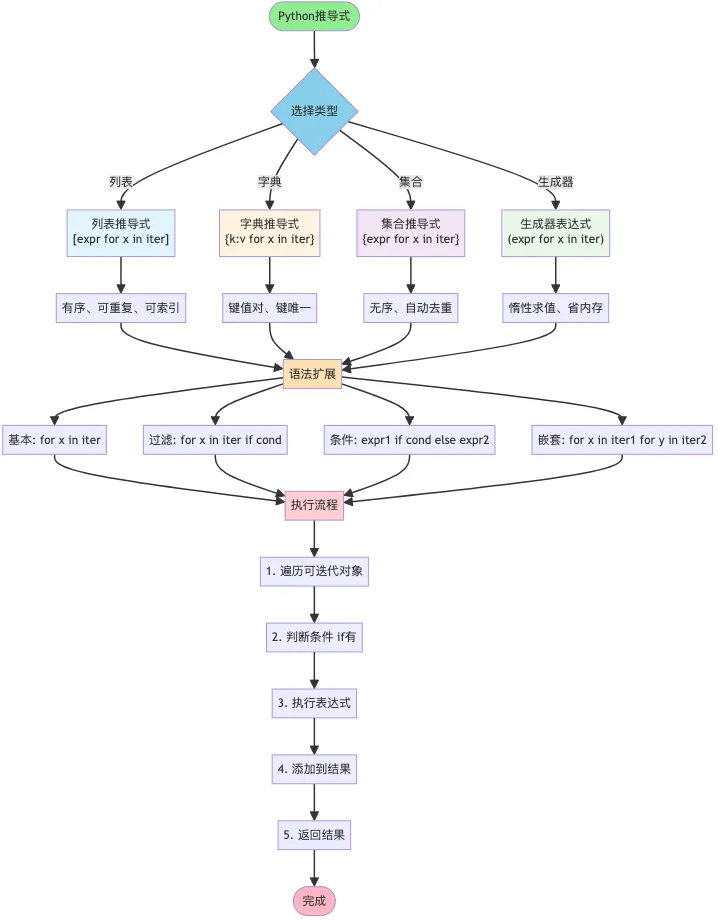
推导式(Comprehensions)是 Python 中一种简洁、高效的创建序列的方式。它可以用一行代码替代多行循环,使代码更加 Pythonic。推导式的优势:
- 列表推导式
[expression for item in iterable] - 字典推导式
{key: value for item in iterable} - 集合推导式
{expression for item in iterable} - 生成器表达式
(expression for item in iterable)
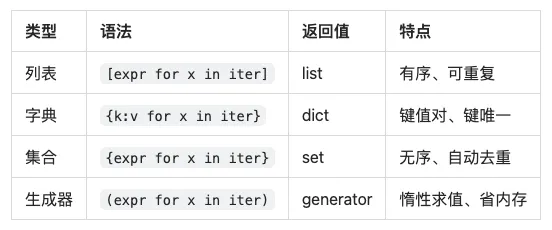
📌 四种推导式对比
1️⃣ 列表推导式
# 基本语法[表达式 for 变量 in 可迭代对象 if 条件]# 示例squares = [x**2 for x in range(10)] # 平方数evens = [x for x in range(20) if x % 2 == 0] # 偶数result = ["偶" if x % 2 == 0 else "奇" for x in range(5)] # if-else
2️⃣ 字典推导式
# 基本语法{键表达式: 值表达式 for 变量 in 可迭代对象 if 条件}# 示例squares = {x: x**2 for x in range(5)} # {0:0, 1:1, 2:4, 3:9, 4:16}swapped = {v: k for k, v in {'a':1, 'b':2}.items()} # 交换键值filtered = {k: v for k, v in scores.items() if v >= 90} # 过滤
4️⃣ 生成器表达式
# 基本语法(表达式 for 变量 in 可迭代对象 if 条件)# 示例gen = (x**2 for x in range(1000000)) # 不占内存total = sum(x**2 for x in range(100)) # 直接使用
5️⃣ 嵌套推导式
# 二维列表matrix = [[i*j for j in range(3)] for i in range(3)]# [[0,0,0], [0,1,2], [0,2,4]]# 展开嵌套列表nested = [[1,2], [3,4], [5]]flat = [x for sublist in nested for x in sublist] # [1,2,3,4,5]# 笛卡尔积pairs = [(x,y) for x in [1,2,3] for y in ['a','b']]# [(1,'a'), (1,'b'), (2,'a'), (2,'b'), (3,'a'), (3,'b')]
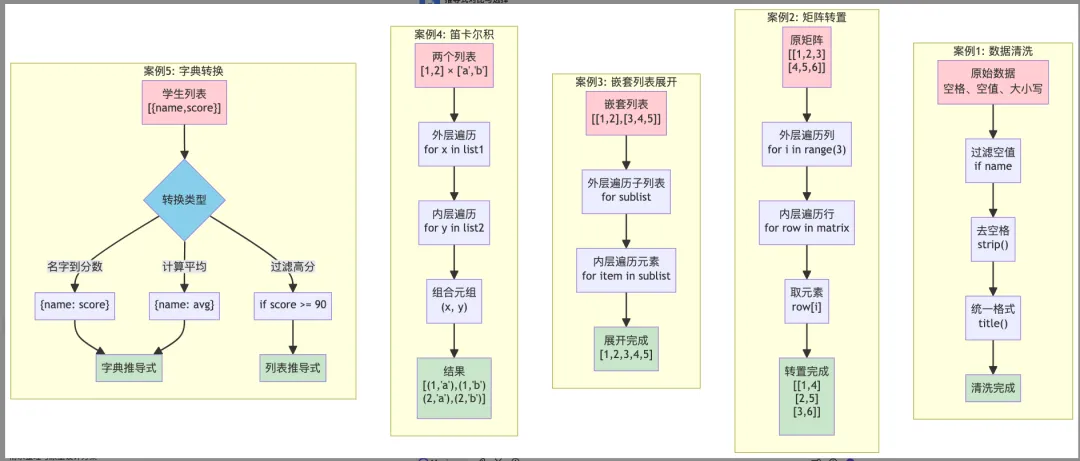
6️⃣ 实战案例
# 案例1:数据清洗data = [" Alice ", "BOB", "", " charlie "]clean = [name.strip().title() for name in data if name and name.strip()]# ['Alice', 'Bob', 'Charlie']# 案例2:成绩统计students = [ {'name': 'Alice', 'score': 85}, {'name': 'Bob', 'score': 92}]high = [s['name'] for s in students if s['score'] >= 90] # ['Bob']# 案例3:矩阵转置matrix = [[1,2,3], [4,5,6]]transposed = [[row[i] for row in matrix] for i in range(3)]# [[1,4], [2,5], [3,6]]# 案例4:文本分析text = "Python is great Python is easy"words = text.lower().split()freq = {w: words.count(w) for w in set(words)}# {'python': 2, 'is': 2, 'great': 1, 'easy': 1}
实战案例
案例 1:数据清洗
# 原始数据data = [ " Alice ", "BOB", " charlie ", "", "DAVID ", None, "eve"]# 清洗数据:去空格、统一大小写、过滤空值cleaned = [ name.strip().title() for name in data if name and name.strip()]print(cleaned) # ['Alice', 'Bob', 'Charlie', 'David', 'Eve']
案例 2:成绩统计
# 学生成绩数据students = [ {'name': 'Alice', 'math': 85, 'english': 90}, {'name': 'Bob', 'math': 92, 'english': 88}, {'name': 'Charlie', 'math': 78, 'english': 85}, {'name': 'David', 'math': 95, 'english': 92}]# 计算总分total_scores = { student['name']: student['math'] + student['english'] for student in students}print(total_scores)# {'Alice': 175, 'Bob': 180, 'Charlie': 163, 'David': 187}# 找出优秀学生(总分>=180)excellent = [ student['name'] for student in students if student['math'] + student['english'] >= 180]print(excellent) # ['Bob', 'David']# 计算平均分averages = { student['name']: (student['math'] + student['english']) / 2 for student in students}print(averages)# {'Alice': 87.5, 'Bob': 90.0, 'Charlie': 81.5, 'David': 93.5}
案例 3:文本分析
# 文本数据text = """Python is a high-level programming language.Python is easy to learn and powerful.Many developers love Python."""# 提取所有单词words = [ word.lower().strip('.,!?') for line in text.split('\n') for word in line.split() if word]print(words[:10])# 统计单词频率from collections import Counterword_freq = { word: words.count(word) for word in set(words)}print(sorted(word_freq.items(), key=lambda x: x[1], reverse=True)[:5])# 找出长单词(长度>5)long_words = {word for word in words if len(word) > 5}print(long_words)
案例 4:矩阵运算
# 矩阵加法matrix_a = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]matrix_b = [[9, 8, 7], [6, 5, 4], [3, 2, 1]]result = [ [matrix_a[i][j] + matrix_b[i][j] for j in range(len(matrix_a[0]))] for i in range(len(matrix_a))]print(result)# [[10, 10, 10], [10, 10, 10], [10, 10, 10]]# 矩阵数乘scalar = 2result = [[num * scalar for num in row] for row in matrix_a]print(result)# [[2, 4, 6], [8, 10, 12], [14, 16, 18]]# 对角线元素diagonal = [matrix_a[i][i] for i in range(len(matrix_a))]print(diagonal) # [1, 5, 9]
案例 5:数据转换
# CSV 数据解析csv_data = """name,age,cityAlice,25,BeijingBob,30,ShanghaiCharlie,28,Guangzhou"""lines = csv_data.strip().split('\n')headers = lines[0].split(',')# 转换为字典列表data = [ {headers[i]: value for i, value in enumerate(line.split(','))} for line in lines[1:]]print(data)# [{'name': 'Alice', 'age': '25', 'city': 'Beijing'},# {'name': 'Bob', 'age': '30', 'city': 'Shanghai'},# {'name': 'Charlie', 'age': '28', 'city': 'Guangzhou'}]# 按城市分组cities = {item['city'] for item in data}grouped = { city: [item['name'] for item in data if item['city'] == city] for city in cities}print(grouped)# {'Beijing': ['Alice'], 'Shanghai': ['Bob'], 'Guangzhou': ['Charlie']}
案例 6:质数筛选
# 埃拉托斯特尼筛法def sieve_of_eratosthenes(n): # 创建布尔列表 is_prime = [True] * (n + 1) is_prime[0] = is_prime[1] = False for i in range(2, int(n**0.5) + 1): if is_prime[i]: # 标记倍数为非质数 for j in range(i*i, n + 1, i): is_prime[j] = False # 提取质数 primes = [num for num, prime in enumerate(is_prime) if prime] return primesprint(sieve_of_eratosthenes(50))# [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47]# 简化版本primes = [ n for n in range(2, 100) if all(n % i != 0 for i in range(2, int(n**0.5) + 1))]print(primes[:10])
案例 7:文件路径处理
# 文件列表files = [ "/home/user/document.txt", "/home/user/image.png", "/home/user/script.py", "/home/user/data.csv", "/home/user/photo.jpg"]# 提取文件名filenames = [path.split('/')[-1] for path in files]print(filenames)# 按扩展名分类extensions = {file.split('.')[-1] for file in filenames}categorized = { ext: [file for file in filenames if file.endswith(f'.{ext}')] for ext in extensions}print(categorized)# {'txt': ['document.txt'], 'png': ['image.png'], # 'py': ['script.py'], 'csv': ['data.csv'], 'jpg': ['photo.jpg']}# 过滤图片文件image_extensions = {'png', 'jpg', 'jpeg', 'gif'}images = [ file for file in filenames if file.split('.')[-1] in image_extensions]print(images) # ['image.png', 'photo.jpg']
✅ 推荐做法
# 1. 简洁清晰squares = [x**2 for x in range(10)]# 2. 合理使用过滤even_squares = [x**2 for x in range(10) if x % 2 == 0]# 3. 生成器处理大数据large_data = (x**2 for x in range(1000000))
❌ 不推荐做法
# 1. 过度嵌套(可读性差)result = [[[x+y+z for z in range(3)] for y in range(3)] for x in range(3)]# 2. 复杂逻辑(应该用函数)result = [x if x > 0 else -x if x < -10 else 0 for x in numbers]# 3. 副作用操作(应该用循环)[print(x) for x in numbers] # 不要这样做!