Karpathy 200行纯Python实现GPT2直观理解大语言模型核心原理
- 2026-07-04 08:15:59
相关阅读
Karpathy200行纯Python实现GPT直观理解语言模型核心原理
Andrej Karpathy实现的最小化GPT模型,仅用不到200行纯Python代码完成字符级语言模型(名字生成)的训练与推理,核心覆盖自动微分、GPT核心架构、Adam优化、自回归生成全流程(推理)。
“@Karpathy: 仅需 243 行纯 Python 代码(无依赖),即可完成 GPT 的训练和推理。这就是所需的全部算法内容。其他代码只是为了提高效率。我无法再进一步简化了。 其工作原理是将完整的 LLM 架构和损失函数完全简化为构成它的最基本的单个数学运算(+、*、 ** 、log、exp),然后使用一个微型的标量值自动微分引擎(micrograd)计算梯度。Adam 用于优化。
我花更多时间进行测试计算,发现我的微梯度模型还可以进一步大幅简化。你只需要返回每个操作的局部梯度,然后获取反向传播()来与损失函数的全局梯度进行乘法(链式运算)。因此,每个操作只表达了它所需的最基本要素:前向传播的计算及其对应的反向传播梯度。 代码量从 243 行大幅减少到仅 200 行(~18 %) 。 此外,代码现在更适合三列布局,而且恰好能正确地换行: 第一列:数据集、分词器、自动分级 第 2 列:GPT 模型 第 3 列:训练、推理
1. 核心目标
实现了一个最小化代码、纯python代码实现字符级GPT模型。用作理解GPT底层原理的极简范例。
以人名数据集(names.txt)为训练数据 通过最小化“下一个字符预测的负对数似然损失”训练模型 最终实现自回归生成新的、符合语言规律的人名。 全程无第三方依赖(仅Python内置库)
2. 模块拆解与深度解读
2.1 数据集与分词器
ifnot os.path.exists('input.txt'):import urllib.request names_url = 'https://raw.githubusercontent.com/karpathy/makemore/refs/heads/master/names.txt' urllib.request.urlretrieve(names_url, 'input.txt')docs = [l.strip() for l in open('input.txt').read().strip().split('\n') if l.strip()]random.shuffle(docs)uchars = sorted(set(''.join(docs))) # 所有唯一字符(如a,b,c...)BOS = len(uchars) # BOS标记的token ID(特殊标记,标识序列开始/结束)vocab_size = len(uchars) + 1# 总词汇量=普通字符数+BOS2.1.1 数据集准备
docs = [l.strip() for l in open('input.txt').read().strip().split('\n') if l.strip()]random.shuffle(docs)功能:下载Karpathy的 names.txt人名数据集,清洗后转为文档列表并打乱,用于训练。作用:提供字符级的训练语料,模型学习“字符序列的概率分布”(比如“ab”后接“y”的概率)。
2.1.2 字符级分词器(极简版)
uchars = sorted(set(''.join(docs))) # 唯一字符列表(如['a','b',...])BOS = len(uchars) # 序列开始标记(Begin of Sequence)vocab_size = len(uchars) + 1# 词汇表大小=唯一字符数+1(BOS)核心设计:字符级分词(无BPE/WordPiece等复杂分词),是最简单的token映射方式: 字符→ID: uchars.index(ch)(如'a'→0,'b'→1)ID→字符: uchars[token_id](如0→'a')特殊token:BOS(值为唯一字符数),用于标记序列开始/结束。
2.2 自动微分引擎(micrograd)
GPT训练依赖梯度下降,而自动微分是计算“损失对参数梯度”的核心。代码中的Value类实现了标量自动微分,是整个模型的数学基础。
classValue: __slots__ = ('data', 'grad', '_children', '_local_grads') # 内存优化def__init__(self, data, children=(), local_grads=()): self.data = data # 节点标量值(前向传播结果) self.grad = 0# 损失对该节点的梯度(反向传播计算) self._children = children # 计算图中的父节点 self._local_grads = local_grads # 节点对父节点的局部梯度# 运算符重载:实现基础运算并记录局部梯度def__add__(self, other): other = other if isinstance(other, Value) else Value(other)return Value(self.data + other.data, (self, other), (1, 1))def__mul__(self, other): other = other if isinstance(other, Value) else Value(other)return Value(self.data * other.data, (self, other), (other.data, self.data))def__pow__(self, other):return Value(self.data**other, (self,), (other * self.data**(other-1),))deflog(self):return Value(math.log(self.data), (self,), (1/self.data,))defexp(self):return Value(math.exp(self.data), (self,), (math.exp(self.data),))defrelu(self):return Value(max(0, self.data), (self,), (float(self.data > 0),))# 反向传播:拓扑排序 + 梯度累积defbackward(self): topo = [] visited = set()defbuild_topo(v):# 构建计算图的拓扑序(确保反向传播顺序)if v notin visited: visited.add(v)for child in v._children: build_topo(child) topo.append(v) build_topo(self) self.grad = 1# 损失节点梯度初始化为1for v in reversed(topo): # 逆序遍历,按链式法则累积梯度for child, local_grad in zip(v._children, v._local_grads): child.grad += local_grad * v.grad2.2.1 Value类核心设计
data | 2.5) |
grad | |
_children | x+y的子节点是x和y) |
_local_grads |
2.2.2 核心操作的数学原理(前向+局部梯度)
x + y | __add__ | ||
x * y | __mul__ | ||
x**k | __pow__ | ||
log(x) | log() | ||
exp(x) | exp() | ||
max(0,x) | relu() |
2.2.3 反向传播(backward()):链式法则
反向传播的核心是拓扑排序+链式法则,数学公式:
其中:
:损失函数(最终要最小化的目标) :父节点的梯度(已计算) :局部梯度( _local_grads存储)
代码中backward()步骤:
拓扑排序:确保反向传播时先计算父节点梯度,再计算子节点(避免依赖顺序错误); 初始化根节点(损失)梯度为1(); 逆序遍历拓扑序列,累加子节点梯度: child.grad += local_grad * parent.grad。
2.3 GPT模型架构
模型遵循GPT-2的核心设计(简化版),核心是“多头注意力块 + MLP块”的堆叠,带残差连接和RMSNorm(替代LayerNorm),高斯初始化。
n_embd = 16# 嵌入维度n_head = 4# 注意力头数n_layer = 1# Transformer层数block_size = 16# 最大序列长度head_dim = n_embd // n_head # 单头维度(4)# 生成高斯分布的权重矩阵(nout行×nin列)matrix = lambda nout, nin, std=0.08: [[Value(random.gauss(0, std)) for _ in range(nin)] for _ in range(nout)]# 定义GPT所有参数state_dict = {'wte': matrix(vocab_size, n_embd), # Token嵌入(字符→向量)'wpe': matrix(block_size, n_embd), # 位置嵌入(位置→向量)'lm_head': matrix(vocab_size, n_embd) # 语言模型头(向量→字符概率)}# 为每个Transformer层添加注意力/MLP参数for i in range(n_layer): state_dict[f'layer{i}.attn_wq'] = matrix(n_embd, n_embd) # Q投影 state_dict[f'layer{i}.attn_wk'] = matrix(n_embd, n_embd) # K投影 state_dict[f'layer{i}.attn_wv'] = matrix(n_embd, n_embd) # V投影 state_dict[f'layer{i}.attn_wo'] = matrix(n_embd, n_embd) # 注意力输出投影 state_dict[f'layer{i}.mlp_fc1'] = matrix(4 * n_embd, n_embd) # MLP扩张层 state_dict[f'layer{i}.mlp_fc2'] = matrix(n_embd, 4 * n_embd) # MLP压缩层# 扁平化参数列表(方便优化器更新)params = [p for mat in state_dict.values() for row in mat for p in row]核心设计:
每个运算(+/*/log 等)都记录局部梯度(如加法的局部梯度为 (1,1)); backward()先通过拓扑排序确定反向传播顺序,再按链式法则累积梯度。
2.3.1 超参数与参数初始化
n_embd = 16# 嵌入维度n_head = 4# 注意力头数n_layer = 1# 模型层数block_size = 16# 最大序列长度head_dim = n_embd // n_head # 每个注意力头的维度(4)参数初始化函数matrix(nout, nin):生成正态分布(均值0,标准差0.08)的权重矩阵,每个元素是Value对象(支持自动微分)。
模型参数清单(state_dict):
wte | ||
wpe | ||
layer{i}.attn_wq/wk/wv | ||
layer{i}.attn_wo | ||
layer{i}.mlp_fc1/fc2 | ||
lm_head |
2.3.2 核心组件的数学原理
(1) 线性层(linear函数)
数学公式:,其中:
:权重矩阵(nout × nin) :输入向量(nin × 1) (第i个输出元素)
代码实现:[sum(wi * xi for wi, xi in zip(wo, x)) for wo in w],每个元素都是Value对象的运算,自动构建计算图。
deflinear(x, w):return [sum(wi * xi for wi, xi in zip(wo, x)) for wo in w](2) RMSNorm(均方根归一化)
替代LayerNorm的简化归一化(去掉均值中心化),数学公式:
其中:
(向量的均方值) (防止除零)
代码实现:
defrmsnorm(x): ms = sum(xi * xi for xi in x) / len(x) # 均方值 scale = (ms + 1e-5) ** -0.5# 缩放因子return [xi * scale for xi in x](3) Softmax函数(logits→概率)
将模型输出的logits转换为概率分布,数学公式:
:数值稳定项(防止exp溢出) :词汇表大小
defsoftmax(logits): max_val = max(val.data for val in logits) exps = [(val - max_val).exp() for val in logits] total = sum(exps)return [e / total for e in exps](4) 多头自注意力(核心)
GPT的核心是因果自注意力(仅关注当前位置之前的字符),数学原理如下:
单头缩放点积注意力
其中:
(查询):(输入向量×查询权重) (键): (值): :每个头的维度(head_dim),缩放因子防止内积过大导致softmax饱和。
多头注意力步骤(代码实现)
拆分Q/K/V到每个头( q_h = q[hs:hs+head_dim]);计算注意力logits:; softmax转换为注意力权重; 加权求和V得到单头输出: ; 拼接所有头输出,通过 attn_wo投影,加残差连接()。
defgpt(token_id, pos_id, keys, values):# 1. 嵌入层:Token Embedding + Position Embedding tok_emb = state_dict['wte'][token_id] pos_emb = state_dict['wpe'][pos_id] x = [t + p for t, p in zip(tok_emb, pos_emb)] # 拼接字符+位置向量 x = rmsnorm(x)# 2. Transformer层(n_layer层)for li in range(n_layer):# 2.1 多头注意力块(带残差连接) x_residual = x # 残差备份 x = rmsnorm(x)# Q/K/V投影 q = linear(x, state_dict[f'layer{li}.attn_wq']) k = linear(x, state_dict[f'layer{li}.attn_wk']) v = linear(x, state_dict[f'layer{li}.attn_wv']) keys[li].append(k) values[li].append(v) x_attn = []for h in range(n_head): # 遍历每个注意力头 hs = h * head_dim q_h = q[hs:hs+head_dim] # 单头Q k_h = [ki[hs:hs+head_dim] for ki in keys[li]] # 单头K(历史序列) v_h = [vi[hs:hs+head_dim] for vi in values[li]] # 单头V(历史序列)# 计算注意力分数(缩放点积) attn_logits = [sum(q_h[j] * k_h[t][j] for j in range(head_dim)) / head_dim**0.5for t in range(len(k_h))] attn_weights = softmax(attn_logits) # 注意力权重# 计算单头输出 head_out = [sum(attn_weights[t] * v_h[t][j] for t in range(len(v_h))) for j in range(head_dim)] x_attn.extend(head_out) # 拼接所有头的输出 x = linear(x_attn, state_dict[f'layer{li}.attn_wo']) # 注意力输出投影 x = [a + b for a, b in zip(x, x_residual)] # 残差连接# 2.2 MLP块(带残差连接) x_residual = x x = rmsnorm(x) x = linear(x, state_dict[f'layer{li}.mlp_fc1']) # 扩张到4×n_embd x = [xi.relu() for xi in x] # ReLU激活 x = linear(x, state_dict[f'layer{li}.mlp_fc2']) # 压缩回n_embd x = [a + b for a, b in zip(x, x_residual)] # 残差连接# 3. 语言模型头:输出字符的logits logits = linear(x, state_dict['lm_head'])return logits(5) MLP块
GPT的MLP是两层线性层+ReLU激活(简化GPT-2的GeLU),公式:
fc1输出维度:(GPT经典设置); fc2投影回,加残差连接。
(6)完整GPT前向流程
graph TD A[token_id/pos_id] --> B[token嵌入+位置嵌入] B --> C[RMSNorm] C --> D[注意力块:残差+RMSNorm+多头注意力] D --> E[MLP块:残差+RMSNorm+MLP] E --> F[lm_head线性层] F --> G[logits(词汇表得分)]2.4 训练过程
训练的核心是最小化负对数似然损失,结合Adam优化器更新参数。
2.4.1 损失函数(负对数似然,NLL)
语言模型的核心目标是最大化“序列的联合概率”,等价于最小化负对数似然,数学公式:
其中:
:序列长度; :模型预测第t个位置目标字符的概率(softmax输出); 代码实现: loss = (1 / n) * sum(-probs[target_id].log() for ...)。
2.4.2 Adam优化器(参数更新)
Adam是结合“动量”和“自适应学习率”的优化器,数学公式如下(第t步,):
累积一阶矩(动量): 累积二阶矩(平方梯度): 偏差修正(初始m/v为0,修正早期值): 参数更新(线性学习率衰减):其中(学习率线性衰减),防止除零。
learning_rate, beta1, beta2, eps_adam = 0.01, 0.85, 0.99, 1e-8m = [0.0] * len(params) # 一阶动量缓存v = [0.0] * len(params) # 二阶动量缓存# 训练循环num_steps = 1000for step in range(num_steps):# 采样一个人名,转换为token序列(首尾加BOS) doc = docs[step % len(docs)] tokens = [BOS] + [uchars.index(ch) for ch in doc] + [BOS] n = min(block_size, len(tokens) - 1)# 前向传播:计算损失(负对数似然) keys, values = [[] for _ in range(n_layer)], [[] for _ in range(n_layer)] losses = []for pos_id in range(n): token_id, target_id = tokens[pos_id], tokens[pos_id + 1] logits = gpt(token_id, pos_id, keys, values) probs = softmax(logits) loss_t = -probs[target_id].log() # 单个位置的损失 losses.append(loss_t) loss = (1 / n) * sum(losses) # 序列平均损失# 反向传播:计算所有参数的梯度 loss.backward()# Adam更新参数 lr_t = learning_rate * (1 - step / num_steps) # 线性学习率衰减for i, p in enumerate(params): m[i] = beta1 * m[i] + (1 - beta1) * p.grad v[i] = beta2 * v[i] + (1 - beta2) * p.grad ** 2 m_hat = m[i] / (1 - beta1 ** (step + 1)) v_hat = v[i] / (1 - beta2 ** (step + 1)) p.data -= lr_t * m_hat / (v_hat ** 0.5 + eps_adam) p.grad = 0# 梯度清零 print(f"step {step+1:4d} / {num_steps:4d} | loss {loss.data:.4f}")2.5 推理过程
推理是自回归生成:从BOS token开始,逐个预测下一个字符,直到遇到BOS或达到最大长度。
temperature = 0.5# 温度越低,生成越保守;越高越随机print("\n--- inference (new, hallucinated names) ---")for sample_idx in range(20): keys, values = [[] for _ in range(n_layer)], [[] for _ in range(n_layer)] token_id = BOS # 初始token为BOS sample = []for pos_id in range(block_size): logits = gpt(token_id, pos_id, keys, values) probs = softmax([l / temperature for l in logits]) # 温度调节 token_id = random.choices(range(vocab_size), weights=[p.data for p in probs])[0]if token_id == BOS: break# 遇到BOS停止生成 sample.append(uchars[token_id]) print(f"sample {sample_idx+1:2d}: {''.join(sample)}")2.5.1 温度系数(Temperature)
控制生成的“随机性”,公式:(为温度);
越小:概率分布越集中(生成越确定,比如只生成常见名字); 越大:概率分布越均匀(生成越随机,甚至无意义)。
2.5.2 生成步骤
初始化token_id为BOS; 遍历位置(直到block_size或BOS): 前向传播得到logits; 温度调整后softmax得到概率; 按概率采样下一个token_id; 若采样到BOS,停止生成;否则转换为字符并继续。
3. 核心数学公式汇总
4. 总结
关键点回顾
极简设计:代码无第三方依赖,用标量自动微分替代复杂框架,核心是“计算图+链式法则”; GPT核心:模型架构遵循GPT-2的“注意力+MLP+残差+归一化”,仅做了简化(ReLU替代GeLU、RMSNorm替代LayerNorm); 训练逻辑:通过最小化负对数似然损失,结合Adam优化器更新参数,推理采用自回归+温度调整生成文本; 简化点:字符级分词(无复杂分词)、单层数、标量自动微分(效率低但易理解),是学习GPT底层原理的最佳范例。
这段代码的价值不在于效率,而在于剥离所有工程优化,暴露GPT的数学本质——所有复杂的LLM,最终都可拆解为“基础算术运算+链式法则+注意力机制+梯度下降”。
来源
https://gist.github.com/karpathy/8627fe009c40f57531cb18360106ce95
代码解释
可直接运行调试
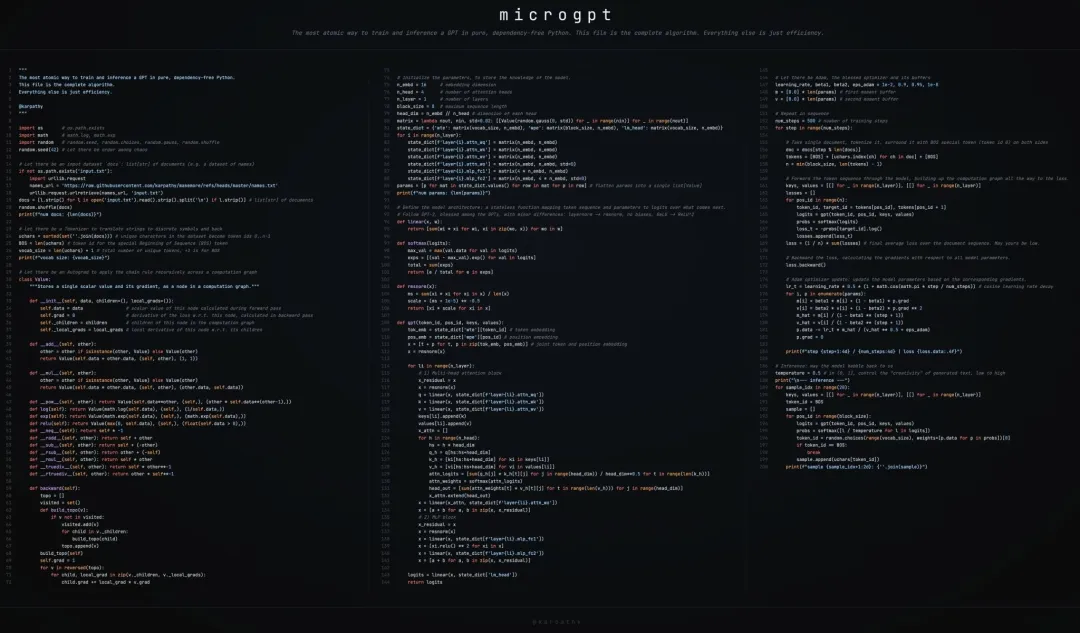
"""The most atomic way to train and inference a GPT in pure, dependency-free Python.This file is the complete algorithm.Everything else is just efficiency.@karpathy"""import os # 用于文件路径检查(os.path.exists)import math # 用于数学运算(对数、指数)import random # 用于随机数生成(种子、采样、高斯分布、洗牌)random.seed(42) # 设置随机种子,保证实验可复现("Let there be order among chaos" 是趣味注释)# ===================== 1. 数据集加载与预处理 =====================# 目标:加载人名数据集(若本地无则从网络下载),最终得到docs列表(每个元素是一个人名字符串)ifnot os.path.exists('input.txt'): # 检查本地是否有数据集文件import urllib.request # 导入网络请求模块(仅在文件不存在时导入)# 数据集地址:Karpathy的makemore项目中的人名数据集 names_url = 'https://raw.githubusercontent.com/karpathy/makemore/refs/heads/master/names.txt' urllib.request.urlretrieve(names_url, 'input.txt') # 下载数据集到本地# 读取文件并预处理:# 1. 读取所有内容 → 按换行分割 → 去除每行首尾空白 → 过滤空行 → 得到干净的人名列表docs = [l.strip() for l in open('input.txt').read().strip().split('\n') if l.strip()]random.shuffle(docs) # 打乱数据集顺序,避免训练时的顺序偏差print(f"num docs: {len(docs)}") # 打印数据集大小(总人数名数量)# ===================== 2. 字符级Tokenizer构建 =====================# 目标:构建字符到token ID的映射,定义特殊标记(BOS)# 提取数据集中所有唯一字符并排序,作为基础词汇表(每个字符对应一个唯一ID:0,1,2...)uchars = sorted(set(''.join(docs)))BOS = len(uchars) # 定义BOS(Beginning of Sequence)特殊标记的ID(值为普通字符数)# BOS用于标识序列的开始/结束,是GPT必需的特殊标记vocab_size = len(uchars) + 1# 总词汇量 = 普通字符数 + BOS标记print(f"vocab size: {vocab_size}") # 打印词汇表大小# ===================== 3. 自动微分引擎(Autograd)实现 =====================# 目标:手动实现计算图和反向传播,替代PyTorch/TensorFlow的Autograd# 核心原理:链式法则(复合函数求导),通过记录计算依赖和局部梯度实现梯度回传classValue:# __slots__:限定实例属性,减少内存占用(Python内存优化技巧) __slots__ = ('data', 'grad', '_children', '_local_grads')def__init__(self, data, children=(), local_grads=()): self.data = data # 当前节点的标量值(前向传播计算结果) self.grad = 0# 损失函数对当前节点的梯度(反向传播后更新) self._children = children # 当前节点的父节点(计算依赖,用于构建计算图) self._local_grads = local_grads # 当前节点对每个父节点的局部梯度(链式法则的"链节")# 重载加法运算符:a + b → 记录依赖和局部梯度(加法的局部梯度为(1,1))def__add__(self, other): other = other if isinstance(other, Value) else Value(other) # 兼容普通数值(转为Value对象)return Value(self.data + other.data, (self, other), (1, 1))# 重载乘法运算符:a * b → 记录依赖和局部梯度(乘法的局部梯度为(b.data, a.data))def__mul__(self, other): other = other if isinstance(other, Value) else Value(other)return Value(self.data * other.data, (self, other), (other.data, self.data))# 重载幂运算符:a ** b(b为常数)→ 局部梯度为b*a^(b-1)def__pow__(self, other):return Value(self.data**other, (self,), (other * self.data**(other-1),))# 对数运算:log(a) → 局部梯度为1/adeflog(self):return Value(math.log(self.data), (self,), (1/self.data,))# 指数运算:exp(a) → 局部梯度为exp(a)defexp(self):return Value(math.exp(self.data), (self,), (math.exp(self.data),))# ReLU激活:max(0,a) → 局部梯度为1(a>0)或0(a≤0)defrelu(self):return Value(max(0, self.data), (self,), (float(self.data > 0),))# 重载负号:-a → 等价于a * -1def__neg__(self):return self * -1# 反向加法(处理 普通数 + Value 对象的情况,如 3 + Value(2))def__radd__(self, other):return self + other# 减法:a - b → 等价于a + (-b)def__sub__(self, other):return self + (-other)# 反向减法(处理 普通数 - Value 对象的情况)def__rsub__(self, other):return other + (-self)# 反向乘法(处理 普通数 * Value 对象的情况)def__rmul__(self, other):return self * other# 除法:a / b → 等价于a * b^(-1)def__truediv__(self, other):return self * other**-1# 反向除法(处理 普通数 / Value 对象的情况)def__rtruediv__(self, other):return other * self**-1# 反向传播核心方法:计算当前节点到所有父节点的梯度defbackward(self): topo = [] # 存储计算图的拓扑排序结果(确保梯度回传顺序) visited = set() # 标记已访问节点,避免重复处理# 递归构建拓扑序:先处理所有子节点,再处理当前节点(后序遍历)defbuild_topo(v):if v notin visited: visited.add(v)for child in v._children: # 遍历所有父节点 build_topo(child) topo.append(v) # 后序添加,保证父节点在子节点之后 build_topo(self) # 从当前节点(损失节点)开始构建拓扑序 self.grad = 1# 损失节点的梯度初始化为1(dL/dL=1)# 逆序遍历拓扑序,按链式法则累积梯度for v in reversed(topo):# 遍历当前节点的每个父节点和对应的局部梯度for child, local_grad in zip(v._children, v._local_grads):# 梯度累积:父节点梯度 += 局部梯度 * 当前节点梯度(链式法则) child.grad += local_grad * v.grad# ===================== 4. 模型参数初始化 =====================# 目标:初始化GPT的所有可训练参数(权重矩阵),定义超参数n_embd = 16# 嵌入维度(每个token/位置的向量长度)n_head = 4# 多头注意力的头数(拆分嵌入维度为多个头,捕捉不同特征)n_layer = 1# Transformer解码器层数(这里仅1层,简化版)block_size = 16# 最大序列长度(模型能处理的最长字符序列)head_dim = n_embd // n_head # 单个注意力头的维度(必须整除,16/4=4)# 定义权重矩阵生成函数:生成n_out行×n_in列的矩阵,元素服从高斯分布(均值0,标准差std)# 每个元素是Value对象(支持自动微分)matrix = lambda nout, nin, std=0.08: [[Value(random.gauss(0, std)) for _ in range(nin)] for _ in range(nout)]# 初始化核心权重矩阵:state_dict = {'wte': matrix(vocab_size, n_embd), # Token嵌入矩阵(vocab_size×n_embd:字符→向量)'wpe': matrix(block_size, n_embd), # 位置嵌入矩阵(block_size×n_embd:位置→向量)'lm_head': matrix(vocab_size, n_embd) # 语言模型头(n_embd→vocab_size:向量→字符概率)}# 为每个Transformer层初始化注意力/MLP权重for i in range(n_layer): state_dict[f'layer{i}.attn_wq'] = matrix(n_embd, n_embd) # Q(查询)投影矩阵 state_dict[f'layer{i}.attn_wk'] = matrix(n_embd, n_embd) # K(键)投影矩阵 state_dict[f'layer{i}.attn_wv'] = matrix(n_embd, n_embd) # V(值)投影矩阵 state_dict[f'layer{i}.attn_wo'] = matrix(n_embd, n_embd) # 注意力输出拼接投影矩阵 state_dict[f'layer{i}.mlp_fc1'] = matrix(4 * n_embd, n_embd) # MLP第一层(扩张维度到4×n_embd) state_dict[f'layer{i}.mlp_fc2'] = matrix(n_embd, 4 * n_embd) # MLP第二层(压缩回n_embd)# 扁平化所有参数到一维列表:方便后续优化器遍历更新(所有Value对象)params = [p for mat in state_dict.values() for row in mat for p in row]print(f"num params: {len(params)}") # 打印总参数数量# ===================== 5. GPT模型核心架构 =====================# 目标:实现GPT的前向传播(无偏置、用RMSNorm替代LayerNorm、ReLU替代GeLU,简化GPT-2)# 线性层(无偏置):输入x(一维列表)× 权重w(二维列表)→ 输出(一维列表)# 数学原理:y = W · x(矩阵乘法,无偏置项)deflinear(x, w):return [sum(wi * xi for wi, xi in zip(wo, x)) for wo in w]# Softmax函数:将logits转为概率分布(保证和为1),做数值稳定处理(减最大值避免溢出)# 数学公式:softmax(z_i) = exp(z_i - max(z)) / sum(exp(z_j - max(z)))defsoftmax(logits): max_val = max(val.data for val in logits) # 取logits的最大值(数值稳定) exps = [(val - max_val).exp() for val in logits] # 每个logit减最大值后指数化 total = sum(exps) # 计算指数和return [e / total for e in exps] # 归一化得到概率# RMSNorm:替代LayerNorm的归一化方法(无均值中心化,仅归一化方差)# 数学公式:RMSNorm(x) = x / sqrt(mean(x²) + ε),ε=1e-5避免除0defrmsnorm(x): ms = sum(xi * xi for xi in x) / len(x) # 计算均方值(mean of square) scale = (ms + 1e-5) ** -0.5# 计算缩放因子(1/根号(均方值+ε))return [xi * scale for xi in x] # 归一化# GPT前向传播函数:输入token ID和位置ID,输出下一个token的logits# keys/values:存储历史序列的K/V,用于自注意力计算defgpt(token_id, pos_id, keys, values):# 步骤1:Token嵌入 + 位置嵌入(GPT的核心嵌入方式) tok_emb = state_dict['wte'][token_id] # 取当前token的嵌入向量 pos_emb = state_dict['wpe'][pos_id] # 取当前位置的嵌入向量 x = [t + p for t, p in zip(tok_emb, pos_emb)] # 向量逐元素相加(融合token+位置信息) x = rmsnorm(x) # 嵌入层后归一化# 步骤2:遍历所有Transformer层(这里仅1层)for li in range(n_layer):# 子步骤1:多头自注意力块(带残差连接) x_residual = x # 保存残差(注意力块的输入,用于后续残差连接) x = rmsnorm(x) # 注意力层前归一化(Pre-Norm架构)# 生成Q/K/V向量(通过线性层投影) q = linear(x, state_dict[f'layer{li}.attn_wq']) k = linear(x, state_dict[f'layer{li}.attn_wk']) v = linear(x, state_dict[f'layer{li}.attn_wv']) keys[li].append(k) # 保存当前K到历史列表(自注意力需要历史K) values[li].append(v)# 保存当前V到历史列表(自注意力需要历史V) x_attn = [] # 存储所有注意力头的输出拼接结果# 遍历每个注意力头(拆分Q/K/V为多个头)for h in range(n_head): hs = h * head_dim # 当前头的起始索引(如第0头:0-3,第1头:4-7...) q_h = q[hs:hs+head_dim] # 提取当前头的Q向量(长度=head_dim) k_h = [ki[hs:hs+head_dim] for ki in keys[li]] # 提取历史序列的K(当前头) v_h = [vi[hs:hs+head_dim] for vi in values[li]]# 提取历史序列的V(当前头)# 计算注意力分数(缩放点积注意力):Q·K^T / sqrt(head_dim)# 避免分数过大导致softmax饱和 attn_logits = [sum(q_h[j] * k_h[t][j] for j in range(head_dim)) / head_dim**0.5for t in range(len(k_h))] attn_weights = softmax(attn_logits) # 注意力分数转权重(和为1)# 计算当前头的输出:加权求和V(权重为注意力权重) head_out = [sum(attn_weights[t] * v_h[t][j] for t in range(len(v_h))) for j in range(head_dim)] x_attn.extend(head_out) # 拼接当前头的输出到总注意力输出# 注意力输出投影 + 残差连接 x = linear(x_attn, state_dict[f'layer{li}.attn_wo']) # 注意力输出线性投影 x = [a + b for a, b in zip(x, x_residual)] # 残差连接(注意力输入+注意力输出)# 子步骤2:MLP块(带残差连接) x_residual = x # 保存残差(MLP块的输入) x = rmsnorm(x) # MLP层前归一化 x = linear(x, state_dict[f'layer{li}.mlp_fc1']) # MLP第一层(扩张维度) x = [xi.relu() for xi in x] # ReLU激活(简化版,GPT-2用GeLU) x = linear(x, state_dict[f'layer{li}.mlp_fc2']) # MLP第二层(压缩维度) x = [a + b for a, b in zip(x, x_residual)] # 残差连接(MLP输入+MLP输出)# 步骤3:语言模型头 → 输出所有token的logits logits = linear(x, state_dict['lm_head'])return logits# ===================== 6. Adam优化器初始化 =====================# 目标:实现Adam优化器(结合动量和RMSProp,自适应学习率)learning_rate, beta1, beta2, eps_adam = 0.01, 0.85, 0.99, 1e-8# Adam的一阶动量缓存(m):记录梯度的指数移动平均(动量)m = [0.0] * len(params)# Adam的二阶动量缓存(v):记录梯度平方的指数移动平均(自适应学习率)v = [0.0] * len(params)# ===================== 7. 训练循环 =====================# 目标:迭代训练模型,更新参数num_steps = 1000# 训练步数(简化版,仅1000步)for step in range(num_steps):# 子步骤1:采样并预处理单个训练样本(人名) doc = docs[step % len(docs)] # 循环采样数据集(step超过数据集大小时取模)# Tokenize:将人名转为token ID序列,首尾添加BOS标记(如"abc"→[BOS, a_id, b_id, c_id, BOS]) tokens = [BOS] + [uchars.index(ch) for ch in doc] + [BOS] n = min(block_size, len(tokens) - 1) # 取有效序列长度(不超过block_size)# 子步骤2:前向传播 → 计算损失(负对数似然,衡量预测误差) keys, values = [[] for _ in range(n_layer)], [[] for _ in range(n_layer)] # 初始化K/V缓存 losses = [] # 存储每个位置的损失for pos_id in range(n): # 遍历序列每个位置,预测下一个token token_id, target_id = tokens[pos_id], tokens[pos_id + 1] # 当前token ID + 目标token ID logits = gpt(token_id, pos_id, keys, values) # 前向传播得到logits probs = softmax(logits) # logits转概率分布 loss_t = -probs[target_id].log() # 单个位置损失:-log(目标token的概率) losses.append(loss_t)# 序列平均损失:所有位置损失的平均值(最终优化目标) loss = (1 / n) * sum(losses)# 子步骤3:反向传播 → 计算所有参数的梯度 loss.backward()# 子步骤4:Adam优化器更新参数 lr_t = learning_rate * (1 - step / num_steps) # 线性学习率衰减(后期减小学习率)for i, p in enumerate(params): # 遍历所有参数# 一阶动量更新:m = β1*m + (1-β1)*grad m[i] = beta1 * m[i] + (1 - beta1) * p.grad# 二阶动量更新:v = β2*v + (1-β2)*grad² v[i] = beta2 * v[i] + (1 - beta2) * p.grad ** 2# 动量偏差修正(初始阶段动量偏小,修正后更准确) m_hat = m[i] / (1 - beta1 ** (step + 1)) v_hat = v[i] / (1 - beta2 ** (step + 1))# 参数更新:p = p - lr * m_hat / (sqrt(v_hat) + ε) p.data -= lr_t * m_hat / (v_hat ** 0.5 + eps_adam) p.grad = 0# 梯度清零(避免下一轮反向传播累积)# 打印当前步数和损失(损失越低,模型预测越准) print(f"step {step+1:4d} / {num_steps:4d} | loss {loss.data:.4f}")# ===================== 8. 推理(生成新名字) =====================# 目标:基于训练好的模型,自回归生成新的人名temperature = 0.5# 温度系数(0,1]:越低生成越保守(接近训练数据),越高越随机print("\n--- inference (new, hallucinated names) ---")for sample_idx in range(20): # 生成20个样本 keys, values = [[] for _ in range(n_layer)], [[] for _ in range(n_layer)] # 初始化K/V缓存 token_id = BOS # 生成起始token(BOS) sample = [] # 存储生成的字符for pos_id in range(block_size): # 最多生成block_size个字符 logits = gpt(token_id, pos_id, keys, values) # 前向传播得到logits# 温度调节:logits / temperature → 改变概率分布的熵(越高越随机) probs = softmax([l / temperature for l in logits])# 按概率采样下一个token ID(加权随机选择) token_id = random.choices(range(vocab_size), weights=[p.data for p in probs])[0]if token_id == BOS: # 遇到BOS停止生成(序列结束)break sample.append(uchars[token_id]) # 将token ID转回字符# 打印生成的名字 print(f"sample {sample_idx+1:2d}: {''.join(sample)}")附Karpathy的源码
"""The most atomic way to train and inference a GPT in pure, dependency-free Python.This file is the complete algorithm.Everything else is just efficiency.@karpathy"""import os # os.path.existsimport math # math.log, math.expimport random # random.seed, random.choices, random.gauss, random.shufflerandom.seed(42) # Let there be order among chaos# Let there be an input dataset `docs`: list[str] of documents (e.g. a dataset of names)ifnot os.path.exists('input.txt'):import urllib.request names_url = 'https://raw.githubusercontent.com/karpathy/makemore/refs/heads/master/names.txt' urllib.request.urlretrieve(names_url, 'input.txt')docs = [l.strip() for l in open('input.txt').read().strip().split('\n') if l.strip()] # list[str] of documentsrandom.shuffle(docs)print(f"num docs: {len(docs)}")# Let there be a Tokenizer to translate strings to discrete symbols and backuchars = sorted(set(''.join(docs))) # unique characters in the dataset become token ids 0..n-1BOS = len(uchars) # token id for the special Beginning of Sequence (BOS) tokenvocab_size = len(uchars) + 1# total number of unique tokens, +1 is for BOSprint(f"vocab size: {vocab_size}")# Let there be Autograd, to recursively apply the chain rule through a computation graphclassValue: __slots__ = ('data', 'grad', '_children', '_local_grads') # Python optimization for memory usagedef__init__(self, data, children=(), local_grads=()): self.data = data # scalar value of this node calculated during forward pass self.grad = 0# derivative of the loss w.r.t. this node, calculated in backward pass self._children = children # children of this node in the computation graph self._local_grads = local_grads # local derivative of this node w.r.t. its childrendef__add__(self, other): other = other if isinstance(other, Value) else Value(other)return Value(self.data + other.data, (self, other), (1, 1))def__mul__(self, other): other = other if isinstance(other, Value) else Value(other)return Value(self.data * other.data, (self, other), (other.data, self.data))def__pow__(self, other):return Value(self.data**other, (self,), (other * self.data**(other-1),))deflog(self):return Value(math.log(self.data), (self,), (1/self.data,))defexp(self):return Value(math.exp(self.data), (self,), (math.exp(self.data),))defrelu(self):return Value(max(0, self.data), (self,), (float(self.data > 0),))def__neg__(self):return self * -1def__radd__(self, other):return self + otherdef__sub__(self, other):return self + (-other)def__rsub__(self, other):return other + (-self)def__rmul__(self, other):return self * otherdef__truediv__(self, other):return self * other**-1def__rtruediv__(self, other):return other * self**-1defbackward(self): topo = [] visited = set()defbuild_topo(v):if v notin visited: visited.add(v)for child in v._children: build_topo(child) topo.append(v) build_topo(self) self.grad = 1for v in reversed(topo):for child, local_grad in zip(v._children, v._local_grads): child.grad += local_grad * v.grad# Initialize the parameters, to store the knowledge of the model.n_embd = 16# embedding dimensionn_head = 4# number of attention headsn_layer = 1# number of layersblock_size = 16# maximum sequence lengthhead_dim = n_embd // n_head # dimension of each headmatrix = lambda nout, nin, std=0.08: [[Value(random.gauss(0, std)) for _ in range(nin)] for _ in range(nout)]state_dict = {'wte': matrix(vocab_size, n_embd), 'wpe': matrix(block_size, n_embd), 'lm_head': matrix(vocab_size, n_embd)}for i in range(n_layer): state_dict[f'layer{i}.attn_wq'] = matrix(n_embd, n_embd) state_dict[f'layer{i}.attn_wk'] = matrix(n_embd, n_embd) state_dict[f'layer{i}.attn_wv'] = matrix(n_embd, n_embd) state_dict[f'layer{i}.attn_wo'] = matrix(n_embd, n_embd) state_dict[f'layer{i}.mlp_fc1'] = matrix(4 * n_embd, n_embd) state_dict[f'layer{i}.mlp_fc2'] = matrix(n_embd, 4 * n_embd)params = [p for mat in state_dict.values() for row in mat for p in row] # flatten params into a single list[Value]print(f"num params: {len(params)}")# Define the model architecture: a stateless function mapping token sequence and parameters to logits over what comes next.# Follow GPT-2, blessed among the GPTs, with minor differences: layernorm -> rmsnorm, no biases, GeLU -> ReLUdeflinear(x, w):return [sum(wi * xi for wi, xi in zip(wo, x)) for wo in w]defsoftmax(logits): max_val = max(val.data for val in logits) exps = [(val - max_val).exp() for val in logits] total = sum(exps)return [e / total for e in exps]defrmsnorm(x): ms = sum(xi * xi for xi in x) / len(x) scale = (ms + 1e-5) ** -0.5return [xi * scale for xi in x]defgpt(token_id, pos_id, keys, values): tok_emb = state_dict['wte'][token_id] # token embedding pos_emb = state_dict['wpe'][pos_id] # position embedding x = [t + p for t, p in zip(tok_emb, pos_emb)] # joint token and position embedding x = rmsnorm(x)for li in range(n_layer):# 1) Multi-head attention block x_residual = x x = rmsnorm(x) q = linear(x, state_dict[f'layer{li}.attn_wq']) k = linear(x, state_dict[f'layer{li}.attn_wk']) v = linear(x, state_dict[f'layer{li}.attn_wv']) keys[li].append(k) values[li].append(v) x_attn = []for h in range(n_head): hs = h * head_dim q_h = q[hs:hs+head_dim] k_h = [ki[hs:hs+head_dim] for ki in keys[li]] v_h = [vi[hs:hs+head_dim] for vi in values[li]] attn_logits = [sum(q_h[j] * k_h[t][j] for j in range(head_dim)) / head_dim**0.5for t in range(len(k_h))] attn_weights = softmax(attn_logits) head_out = [sum(attn_weights[t] * v_h[t][j] for t in range(len(v_h))) for j in range(head_dim)] x_attn.extend(head_out) x = linear(x_attn, state_dict[f'layer{li}.attn_wo']) x = [a + b for a, b in zip(x, x_residual)]# 2) MLP block x_residual = x x = rmsnorm(x) x = linear(x, state_dict[f'layer{li}.mlp_fc1']) x = [xi.relu() for xi in x] x = linear(x, state_dict[f'layer{li}.mlp_fc2']) x = [a + b for a, b in zip(x, x_residual)] logits = linear(x, state_dict['lm_head'])return logits# Let there be Adam, the blessed optimizer and its bufferslearning_rate, beta1, beta2, eps_adam = 0.01, 0.85, 0.99, 1e-8m = [0.0] * len(params) # first moment bufferv = [0.0] * len(params) # second moment buffer# Repeat in sequencenum_steps = 1000# number of training stepsfor step in range(num_steps):# Take single document, tokenize it, surround it with BOS special token on both sides doc = docs[step % len(docs)] tokens = [BOS] + [uchars.index(ch) for ch in doc] + [BOS] n = min(block_size, len(tokens) - 1)# Forward the token sequence through the model, building up the computation graph all the way to the loss. keys, values = [[] for _ in range(n_layer)], [[] for _ in range(n_layer)] losses = []for pos_id in range(n): token_id, target_id = tokens[pos_id], tokens[pos_id + 1] logits = gpt(token_id, pos_id, keys, values) probs = softmax(logits) loss_t = -probs[target_id].log() losses.append(loss_t) loss = (1 / n) * sum(losses) # final average loss over the document sequence. May yours be low.# Backward the loss, calculating the gradients with respect to all model parameters. loss.backward()# Adam optimizer update: update the model parameters based on the corresponding gradients. lr_t = learning_rate * (1 - step / num_steps) # linear learning rate decayfor i, p in enumerate(params): m[i] = beta1 * m[i] + (1 - beta1) * p.grad v[i] = beta2 * v[i] + (1 - beta2) * p.grad ** 2 m_hat = m[i] / (1 - beta1 ** (step + 1)) v_hat = v[i] / (1 - beta2 ** (step + 1)) p.data -= lr_t * m_hat / (v_hat ** 0.5 + eps_adam) p.grad = 0 print(f"step {step+1:4d} / {num_steps:4d} | loss {loss.data:.4f}")# Inference: may the model babble back to ustemperature = 0.5# in (0, 1], control the "creativity" of generated text, low to highprint("\n--- inference (new, hallucinated names) ---")for sample_idx in range(20): keys, values = [[] for _ in range(n_layer)], [[] for _ in range(n_layer)] token_id = BOS sample = []for pos_id in range(block_size): logits = gpt(token_id, pos_id, keys, values) probs = softmax([l / temperature for l in logits]) token_id = random.choices(range(vocab_size), weights=[p.data for p in probs])[0]if token_id == BOS:break sample.append(uchars[token_id]) print(f"sample {sample_idx+1:2d}: {''.join(sample)}")推荐阅读
避免AI瞎写代码Claude Code核心编程准则
Reasoning LLMs解析
腾讯ShunyuYao新作CL-BENCH用于评估语言模型上下文学习能力的真实世界基准
Kimi K2.5 开源多模态智能体基模
各种AI产品爆火浪潮下的一点思考
DeepSeek-OCR 2探索统一全模态编码的可能性
DeepseekV4预热:mHC 大幅提高预训练模型稳定性
Gemini 3 Prompt:通用使用的最佳实践
20260125关于AICoding引发技术栈划分取消的思考
为什么使用Jinja2构建LLM工具调用Prompt
DeepseekV4预热Engram代码解析:静态Memory与动态计算分离
DeepseekV4预热:Engram实现静态Memory与动态计算分离
Qwen3 Embedding系列模型
Anthropic Multi-Agent Research System构建方法与经验
Anthropic 高效的AI agents上下文工程设计理念和实践经验
Anthropic通过MCP实现高效的Agent
Anthropic Agentic coding最佳实践
Anthropic think tool设计理念与实践经验
Anthropic 评估LLM实现软件工程能力实践经验
Anthropic:高效构建Agents设计理念
Anthropic RAG 上下文检索设计理念
2025,于AI浪潮中锚定自我
关于选择:理解贝叶斯主义,拥抱变化做好当下
致敬2025:一些前沿的超越标准大语言模型的探索
致敬2025:从DeepSeek V3到Mistral 3 Large现代LLM架构设计解析
Google极长上下文解决方案:Titans + MIRAS
MCP: Function Calling原理
一人公司AI技术栈:极简思维,拉满独立开发效率
FalkorDB开源Graph数据库
MemOS以LLMmemory为中心实现高效的存储和检索
一项连通心理学、神经科学与机器学习的研究Key-value memory in the brain
Ilya关于Scaling到Research转变的探讨
Claude Agent Skills:从第一性原理深入剖析
SQL原生LLM记忆引擎Memori
CUDA Toolkit安装多版本管理
多模态新方向:Cambrain-S空间超感知多模态
HunyuanOCR 1B商用级开源VLM模型技术报告解读
百度飞桨0.9B文档解析模型PaddleOCR-VL
ClaudeCode导入其他AI模型的方法
LLM多轮对话数据集构建高级攻略
Karpathy提出多LLM协作委员会项目解析
Document AI: 智能文档处理的下一次进化
Meta 提出SAM 3D Body: 单图像全身3D人体Mesh重建可提示模型
极简生活指南49条
多模态高效架构:Deeply Stacking Visual Tokens
高效生活:五大时间管理工具用法对比分析
如何保证Agent的上下文Memory清晰
突破textual content限制:RAG-Anything
Mate超级实验室推出低成本RL: Scaling Agent Learning
Alibaba提出 Logics-Parsing 端到端文档解析模型
SimpleVLA-RL为解决VLA模型数据稀缺与泛化能力弱的高效RL框架
Microsoft提出Agent Lightning突破性的解耦思维打破了RL与Agent训练的适配壁垒
OpenAI指出语言模型幻觉的核心原因:训练和评估机制的统计必然
K2-Think低成本高可用的高效推理系统
腾讯小模型:R-4B专为通用auto-thinking设计的MLLM
Qwen3-VL:从 “看见” 到 “理解”,从 “认知” 到 “行动”
如何创造财富?《黑客与画家》
LLM-JEPA:跨领域创新打破 NLP 与视觉表征学习的壁垒
常用10+多模态检索Benchmark
Less is More:递归小模型
Context Engineering系统研究:Context Engineering 2.0
新方向:DeepSeek-OCR
字节新作多模态小模型:SAIL-VL2