Python学习
一、学前花絮
我们一直在说,学习python要面对生活和工作的实际,也就是要学以致用。最近一位朋友是做榴莲生意的,问我能否从网上爬取一些关于猫山王榴莲的信息。我在此尝试一下。
想用 Python 了解猫山王榴莲的市场行情和用户评价,这其实是个很典型的电商数据分析场景。不过在动手写代码前,得先明确一点:直接爬取大型电商平台(如淘宝、京东)的动态数据难度较大,因为它们有复杂的反爬虫机制(验证码、登录、动态加载)。那么还是从简单做起,爬取公开的社交媒体/内容平台等相对开放数据。
二、python爬取有关猫山王榴莲销售情况等方面的信息
用豆瓣(Douban)来练手python爬取就非常合适。它的页面结构清晰,反爬虫相对宽松,特别适合初学者练手。而且豆瓣书影音区经常有对“猫山王”的测评,数据质量很高。
2.1 环境准备
pip install requests lxml pandas |
2.2 示例代码
这个脚本会去“吃货”相关的小组,搜索“猫山王”关键词,抓取标题、作者和链接。
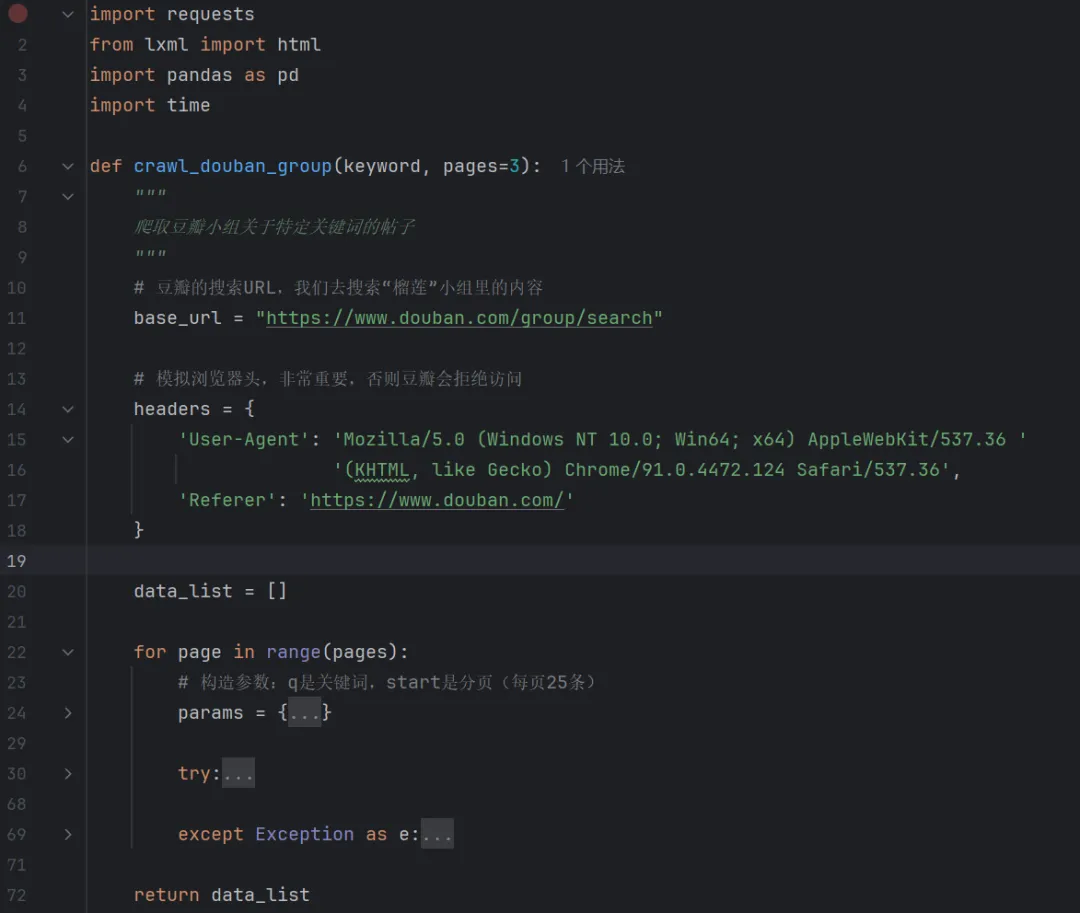
代码解析:
使用 params 构造URL:
我们没有直接拼接URL字符串,而是用 requests 的 params 参数。这样代码更清晰,也能自动处理中文编码。
XPath 定位:
豆瓣的搜索结果列表是用 标签做的,每行是一个 。我们通过 .//td[1]/a/text() 来获取第一列(标题)的文本。
设置延时:
time.sleep(2) 是爬虫的“礼貌”,避免太快被封IP。
编码处理:
response.encoding = 'utf-8' 很重要,否则保存的CSV文件中文可能会变成乱码。
2.3 运行效果
运行这个脚本,能看到控制台打印出爬取进度,并生成一个“猫山王_豆瓣小组讨论.csv ”文件。打开文件,你就能看到大家关于猫山王的评价了,比如:
“猫山王到底是不是智商税?”
“哪里能买到正宗的平价猫山王?”
“猫山王和金枕哪个好吃?”

从终端查看csv文件内容:
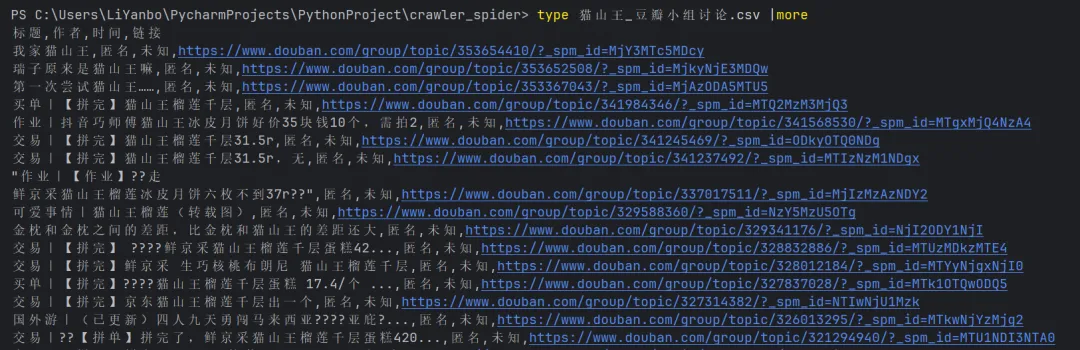
我们看到,确实爬取了相关网页,并有http链接。点击链接可以进入对应的网页。说明爬取成功了!
三、小结
对于python的爬虫技术,我们在学习中只是当做一个技能去练习。而在实际工作中,要遵从相关的规定,比如Robots 协议 (robots.txt)。这是网站根目录下的一个文本文件,用来告诉爬虫哪些目录可以爬,哪些禁止爬取。
让我们保持学习热情,多做练习。我们下期再见!


