Linux深度解析自旋锁
- 2026-07-03 14:16:14
在Linux内核同步机制中,自旋锁是最基础、最高效的临界资源保护手段之一,尤其适用于多核SMP架构和内核可抢占场景。随着Armv8架构在服务器、嵌入式设备中的广泛应用,理解Linux 6.6内核中Armv8架构下自旋锁的实现原理、源码细节与正确用法,对内核开发者和驱动工程师而言至关重要。本文将结合Linux 6.6内核源码(重点基于Armv8架构),从原理到实操,全方位拆解自旋锁的核心逻辑,同时补充读写自旋锁、顺序锁的相关内容,完善内核同步机制的学习体系,形成“原理-源码-实操-避坑”的完整学习链路。
一、自旋锁核心原理回顾
自旋锁的核心设计思路是“忙等不阻塞”:当执行单元试图获取已被占用的锁时,不会进入睡眠状态,而是在一个循环中反复尝试获取锁(即“自旋”),直到锁被释放。这种机制避免了进程上下文切换的开销,因此特别适合临界区执行时间极短的场景。
从本质上看,自旋锁可以看作一个状态标记变量,用于标识临界区的占用状态:
锁空闲时:执行单元通过原子操作获取锁,标记为“占用”后进入临界区;
锁占用时:执行单元循环执行“测试并设置”(Test-And-Set)原子操作,直至锁释放。
关键前提:自旋锁的高效性依赖于“临界区极短”——若临界区执行时间过长,自旋等待会浪费CPU资源,此时应使用互斥锁(mutex)而非自旋锁。这一前提也是后续Armv8架构下自旋锁实现与优化的核心出发点。
自旋锁的核心适用场景是:SMP多核架构、单CPU但内核可抢占的系统;对于单CPU且内核不可抢占的系统,自旋锁会退化为空操作,无需实际自旋。而Armv8架构多应用于多核设备,因此自旋锁的高效实现对Armv8平台的内核性能至关重要。
二、Linux 6.6 + Armv8架构:自旋锁的底层实现
基于前文所述的自旋锁核心原理,Armv8架构提供了专属的原子指令和内存屏障指令,Linux 6.6内核正是基于这些指令,实现了适配Armv8的自旋锁,既保证了多核环境下的排他性,又处理好了内存可见性问题,完美契合Armv8多核平台的应用需求。核心依赖的Armv8指令如下:
ldrex:加载-独占指令,用于原子读取锁变量,并标记该内存地址为“独占访问”;
strex:存储-独占指令,用于原子更新锁变量,仅当地址仍为“独占访问”时更新成功;
dmb/dsb:内存屏障指令,保证指令执行顺序,避免CPU乱序执行导致的锁状态错乱;
wfe/sev:等待/唤醒指令,优化自旋效率,减少CPU空转消耗。
2.1 核心源码路径(Linux 6.6)
Armv8架构下自旋锁的核心源码集中在以下路径,这些源码文件完整实现了前文所述指令的封装与自旋锁的核心逻辑:
// 自旋锁核心实现kernel/locking/spinlock.c// Armv8架构专属实现(汇编+宏定义)arch/arm64/include/asm/spinlock.harch/arm64/kernel/locking.c其中,spinlock.h定义了自旋锁的结构体、原子操作宏,locking.c则实现了适配Armv8的自旋锁核心逻辑,是理解Armv8自旋锁底层实现的关键入口。
2.2 关键结构体与核心宏(Linux 6.6 Armv8)
(1)自旋锁结构体spinlock_t
Linux 6.6中,Armv8架构下的spinlock_t结构体定义简化且高效,本质是一个32位整数(用于标记锁状态),源码如下,其设计充分适配Armv8的32位/64位混合操作特性:
// arch/arm64/include/asm/spinlock.htypedefstructspinlock {union { u32 slock; // 锁状态标记:0=空闲,非0=占用struct { u16 owner; // 持有锁的CPU核心ID(优化调试) u16 next; // 等待队列索引(可选,用于优先级调度) }; };} spinlock_t;Linux 6.6通过union复用内存,兼顾锁状态标记与调试信息,适配Armv8的32位/64位混合操作,在保证功能的同时最大限度降低了内存开销。
(2)核心原子操作宏(ldrex + strex实现)
Armv8架构下,自旋锁的“测试并设置”原子操作,通过ldrex和strex指令封装为宏,这是自旋锁实现的核心,也是保证多核环境下锁原子性的关键,源码简化如下:
// arch/arm64/include/asm/spinlock.h// 尝试获取自旋锁staticinlineintarch_spin_trylock(arch_spinlock_t *lock){ u32 old, new;// 原子读取锁状态(ldrex) __asm__ __volatile__("ldrex %w0, [%1]\n"// 独占加载slock到old(%w0表示32位)"cbnz %w0, 1f\n"// 若old非0(锁占用),跳至1f(返回失败)"mov %w2, #1\n"// 新状态:1(占用)"strex %w0, %w2, [%1]\n"// 独占存储new到slock,结果存old(0=成功)"1:" : "=&r"(old), "=&r"(lock), "=&r"(new) : "1"(lock) : "memory", "cc");return old == 0; // 返回true=获取成功,false=失败}这段汇编代码完美对应“自旋锁的原子操作逻辑”:通过ldrex独占加载锁状态,判断是否空闲;若空闲,用strex原子更新为“占用”,全程保证原子性,避免多核并发冲突,这也是Armv8架构下自旋锁区别于其他架构的核心实现细节。
(3)自旋等待逻辑(优化版)
基于原子操作宏,Linux 6.6在Armv8架构下进一步优化了自旋等待逻辑,结合wfe/sev指令减少CPU空转,解决了前文提到的“自旋等待浪费CPU资源”的问题,核心代码如下:
// arch/arm64/kernel/locking.cvoidarch_spin_lock(arch_spinlock_t *lock){for (;;) {// 尝试获取锁,成功则返回if (arch_spin_trylock(lock))return;// 锁被占用,执行wfe(等待事件),CPU进入低功耗自旋 wfe();// 唤醒后再次尝试,避免无效空转if (arch_spin_trylock(lock))return; }}与“循环测试并设置”相比,Linux 6.6的优化点在于:当锁被占用时,通过wfe指令让CPU进入低功耗状态,直到锁持有者执行sev指令唤醒,大幅降低自旋等待的CPU开销,这也是Armv8架构下自旋锁的一大特色,充分发挥了Armv8指令集的优势。
2.3 自旋锁的释放逻辑(spin_unlock)
与获取逻辑相对应,释放自旋锁时,需原子重置锁状态,并通过sev指令唤醒等待的CPU核心,确保锁释放后能被其他等待单元及时获取,源码如下:
// arch/arm64/include/asm/spinlock.hstaticinlinevoidarch_spin_unlock(arch_spinlock_t *lock){// 内存屏障:保证临界区指令执行完毕后,再释放锁 dmb(ish);// 原子重置锁状态为0(空闲) __asm__ __volatile__("str %w0, [%1]" : : "r"(0), "r"(&lock->slock) : "memory");// 唤醒等待的CPU核心(wfe对应的唤醒指令) sev();}关键细节:dmb(ish)内存屏障指令,对应“处理好内存屏障”的要求,确保临界区内的指令全部执行完毕,避免CPU乱序执行导致的资源竞争问题;sev指令唤醒所有处于wfe状态的等待CPU,与前文自旋等待逻辑中的wfe指令形成呼应,保证了自旋锁获取与释放的逻辑闭环。至此,Armv8架构下自旋锁的底层实现已完整覆盖,后续将基于这一实现,讲解实际开发中的使用方法。
三、Linux 6.6 Armv8自旋锁实操:从初始化到使用
结合前文讲解的Armv8架构下自旋锁底层实现,自旋锁使用方法,本节将搭配Linux 6.6 Armv8架构的实操代码,完整演示自旋锁的定义、初始化、获取、释放流程,以及衍生锁的使用,帮助开发者快速将理论落地到实际驱动开发中。
3.1 基础自旋锁实操(核心流程)
以下代码基于Linux 6.6内核驱动开发规范,适配Armv8架构,实现“设备最多被1个进程打开”的功能,完整覆盖基础自旋锁的核心使用流程:
#include<linux/spinlock.h>#include<linux/fs.h>#include<linux/module.h>// 1. 定义自旋锁和计数变量(临界资源)staticspinlock_t dev_lock;staticint dev_open_count = 0; // 设备打开次数,需被自旋锁保护// 模块初始化:初始化自旋锁staticint __init dev_init(void){// 2. 动态初始化自旋锁 spin_lock_init(&dev_lock); printk("spinlock init success (Armv8 Linux 6.6)\n");return0;}// 设备打开函数:用自旋锁保护临界区staticintdev_open(struct inode *inode, struct file *filp){// 3. 获取自旋锁 spin_lock(&dev_lock);// 临界区:判断设备是否已被打开if (dev_open_count > 0) { spin_unlock(&dev_lock); // 释放锁(必须配对)return -EBUSY; // 设备忙 } dev_open_count++; // 计数+1// 4. 释放自旋锁 spin_unlock(&dev_lock); printk("device open success\n");return0;}// 设备关闭函数:用自旋锁保护临界区staticintdev_release(struct inode *inode, struct file *filp){ spin_lock(&dev_lock); dev_open_count--; // 计数-1 spin_unlock(&dev_lock); printk("device release success\n");return0;}// 模块退出staticvoid __exit dev_exit(void){ printk("spinlock module exit\n");}// 驱动注册(简化)staticstructfile_operationsdev_fops = { .open = dev_open, .release = dev_release,};module_init(dev_init);module_exit(dev_exit);MODULE_LICENSE("GPL");代码说明:完全遵循“定义-初始化-获取-释放”的流程,适配Linux 6.6 Armv8架构,其中spin_lock_init、spin_lock、spin_unlock的底层实现均对应前文讲解的Armv8指令封装,用法与内核源码完全一致,可直接用于驱动开发。需要注意的是,锁的获取与释放必须严格配对,避免出现死锁。
3.2 衍生自旋锁实操(中断/底半部保护)
在实际驱动开发中,自旋锁常需应对中断、底半部的干扰,结合“自旋锁与中断、底半部结合”的知识点,Linux 6.6 Armv8架构下,内核封装了常用的衍生自旋锁函数,其底层仍基于前文讲解的原子指令与内存屏障:
// 1. 关中断+获取自旋锁(进程上下文,避免中断干扰)spin_lock_irq(&lock); // = spin_lock() + local_irq_disable()// 2. 保存中断状态+关中断+获取自旋锁(推荐,可恢复中断状态)unsignedlong flags;spin_lock_irqsave(&lock, flags); // = spin_lock() + local_irq_save()// 3. 关底半部+获取自旋锁(避免底半部干扰)spin_lock_bh(&lock); // = spin_lock() + local_bh_disable()// 对应释放函数(必须配对使用)spin_unlock_irq(&lock);spin_unlock_irqrestore(&lock, flags);spin_unlock_bh(&lock);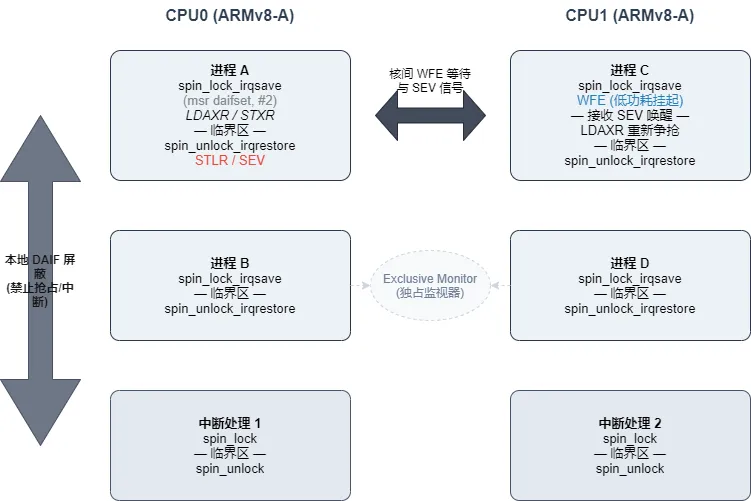
实操场景:当进程上下文和中断上下文可能访问同一临界资源时,结合Armv8多核架构的特性,正确用法如下,需重点注意核间中断的处理:
// 中断处理函数(中断上下文)staticirqreturn_tdev_irq_handler(int irq, void *dev_id){// 中断上下文获取自旋锁:无需关中断(进程上下文已关) spin_lock(&dev_lock);// 临界区:中断处理逻辑(如读取设备状态) printk("irq handler: critical section\n"); spin_unlock(&dev_lock);return IRQ_HANDLED;}// 进程上下文函数staticvoiddev_process_func(void){unsignedlong flags;// 进程上下文获取自旋锁:关中断+保存状态,避免中断干扰 spin_lock_irqsave(&dev_lock, flags);// 临界区:进程处理逻辑(如修改设备配置) printk("process func: critical section\n"); spin_unlock_irqrestore(&dev_lock, flags); // 恢复中断状态}核心原则:Armv8多核环境下,spin_lock_irqsave仅能屏蔽当前CPU的中断,无法屏蔽其他CPU的中断,因此中断上下文必须调用spin_lock,避免核间并发冲突。这一原则是Armv8多核架构下,衍生自旋锁使用的关键,也是避免锁竞争的核心要点。
四、Linux 6.6 Armv8 读写自旋锁:读写分离的高效同步
前文讲解的基础自旋锁属于“排他锁”,无论读操作还是写操作,都将独占锁资源,无法实现多线程并发读,在“读多写少”的场景(如内核配置读取、设备状态查询)中会浪费CPU算力,无法充分发挥Armv8多核平台的并发优势。为此,Linux 6.6在Armv8架构下实现了读写自旋锁(rwlock),核心逻辑是“读共享、写独占”,即多个读操作可同时获取锁,写操作需独占锁且阻塞所有读/写操作,完美适配读多写少的场景,同时复用Armv8的原子指令保证高效性,弥补了基础自旋锁的场景局限。
4.1 读写自旋锁核心原理(Armv8架构适配)
Linux 6.6 Armv8架构下的读写自旋锁,本质是通过一个32位变量标记锁状态(复用基础自旋锁的内存布局),最大限度复用了基础自旋锁的实现逻辑,降低架构适配成本,其状态标记规则如下:高31位用于记录当前持有读锁的数量,最低1位标记是否有写锁占用,具体逻辑的:
读锁获取:判断最低位是否为0(无写锁),若为0则原子性增加读锁计数,获取成功;
写锁获取:判断32位变量是否为0(无读锁、无写锁),若为0则原子性将最低位置1,获取成功;
锁释放:读锁释放时原子性减少读锁计数,写锁释放时将32位变量重置为0,同时通过sev指令唤醒等待的CPU。
核心依赖:依旧基于Armv8的ldrex/strex原子指令实现计数更新,结合dmb内存屏障保证内存可见性,wfe/sev指令优化自旋等待效率,与基础自旋锁复用底层指令集,既降低了架构适配成本,又保证了与基础自旋锁一致的高效性。
4.2 核心源码与结构体(Linux 6.6 Armv8)
(1)读写自旋锁结构体rwlock_t
Armv8架构下,rwlock_t结构体与spinlock_t复用内存布局,充分复用基础自旋锁的设计思路,简化定义如下(源码路径:arch/arm64/include/asm/spinlock.h):
// arch/arm64/include/asm/spinlock.htypedefstructrwlock {union { u32 lock; // 锁状态:高31位=读锁计数,最低1位=写锁标记(0=无,1=有)struct { u31 readers; // 读锁持有者数量 u1 writer; // 写锁标记 }; };} rwlock_t;结构说明:与基础自旋锁的union复用逻辑一致,兼顾锁状态标记与调试便利性,适配Armv8的32位原子操作,避免不必要的内存开销,同时实现了与基础自旋锁的内存布局兼容,便于内核统一管理。
(2)核心操作函数(Armv8专属实现)
Linux 6.6封装了读写自旋锁的核心操作函数,底层通过ldrex/strex指令实现原子计数,其实现逻辑与基础自旋锁的获取、释放逻辑一脉相承,关键函数简化如下:
// 1. 读锁获取(非阻塞尝试)staticinlineintarch_read_trylock(arch_rwlock_t *lock){ u32 old, new; __asm__ __volatile__("ldrex %w0, [%1]\n"// 独占加载锁状态"tst %w0, #1\n"// 判断最低位(写锁标记),非0则有写锁"bne 1f\n"// 有写锁,跳至失败"add %w2, %w0, #2\n"// 无写锁,读锁计数+1(左移1位,即+2)"strex %w0, %w2, [%1]\n"// 原子更新锁状态"1:" : "=&r"(old), "=&r"(lock), "=&r"(new) : "1"(lock) : "memory", "cc");return old == 0;}// 2. 读锁获取(阻塞自旋)voidarch_read_lock(arch_rwlock_t *lock){for (;;) {if (arch_read_trylock(lock))return; wfe(); // 优化自旋,低功耗等待if (arch_read_trylock(lock))return; }}// 3. 读锁释放staticinlinevoidarch_read_unlock(arch_rwlock_t *lock){ dmb(ish); // 内存屏障,保证读操作完成 __asm__ __volatile__("ldrex %w0, [%1]\n""sub %w0, %w0, #2\n"// 读锁计数-1"strex %w1, %w0, [%1]\n" : "=&r"(old), "=&r"(tmp) : "r"(lock) : "memory", "cc"); sev(); // 唤醒等待的写锁/读锁}// 4. 写锁获取(阻塞自旋,类似基础自旋锁)voidarch_write_lock(arch_rwlock_t *lock){for (;;) {if (arch_write_trylock(lock))return; wfe();if (arch_write_trylock(lock))return; }}// 5. 写锁释放staticinlinevoidarch_write_unlock(arch_rwlock_t *lock){ dmb(ish); __asm__ __volatile__("str %w0, [%1]"// 重置锁状态为0 : : "r"(0), "r"(&lock->lock) : "memory"); sev();}4.3 读写自旋锁实操(Armv8 Linux 6.6)
结合读写自旋锁的核心原理与源码实现,以下代码适配Armv8架构,基于Linux 6.6内核驱动,实现“多进程并发读取设备状态、单一进程修改设备配置”的场景(读多写少,贴合实际驱动开发),充分发挥读写分离的优势:
#include<linux/rwlock.h>#include<linux/fs.h>#include<linux/module.h>// 1. 定义读写自旋锁和临界资源(设备状态)staticrwlock_t dev_rwlock;staticint dev_status = 0; // 设备状态(读多写少)staticint dev_config = 1; // 设备配置(仅写操作修改)// 模块初始化:初始化读写自旋锁staticint __init rwlock_init(void){ rwlock_init(&dev_rwlock); // 读写自旋锁初始化 printk("rwlock init success (Armv8 Linux 6.6)\n");return0;}// 读操作:获取读锁,读取设备状态(支持并发读)staticintdev_read_status(void){int status; read_lock(&dev_rwlock); // 获取读锁(对应arch_read_lock) status = dev_status; // 临界区:读取设备状态(读操作) read_unlock(&dev_rwlock); // 释放读锁return status;}// 写操作:获取写锁,修改设备配置(独占写,阻塞所有读/写)staticvoiddev_set_config(int new_config){ write_lock(&dev_rwlock); // 获取写锁(对应arch_write_lock) dev_config = new_config; // 临界区:修改设备配置(写操作) dev_status = new_config > 0 ? 1 : 0; // 联动修改状态 write_unlock(&dev_rwlock); // 释放写锁}// 设备读函数(用户态读取设备状态)staticssize_tdev_read(struct file *filp, char __user *buf, size_t count, loff_t *pos){int status = dev_read_status(); copy_to_user(buf, &status, sizeof(status));returnsizeof(status);}// 设备写函数(用户态修改设备配置)staticssize_tdev_write(struct file *filp, constchar __user *buf, size_t count, loff_t *pos){int new_config; copy_from_user(&new_config, buf, sizeof(new_config)); dev_set_config(new_config);returnsizeof(new_config);}// 驱动注册(简化)staticstructfile_operationsdev_fops = { .read = dev_read, .write = dev_write,};module_init(rwlock_init);module_exit(dev_exit);MODULE_LICENSE("GPL");关键注意事项:
读锁与写锁互斥:持有读锁时,无法获取写锁;持有写锁时,无法获取读锁/写锁,这是保证数据一致性的核心;
读锁共享:多个进程可同时持有读锁,并发读取临界资源,无需自旋等待,充分发挥Armv8多核平台的并发优势;
衍生操作:与基础自旋锁类似,提供read_lock_irqsave、write_lock_bh等衍生函数,适配中断/底半部场景,用法与基础自旋锁一致,可参考前文衍生自旋锁的实操逻辑。
五、Linux 6.6 Armv8 顺序锁:无阻塞读的极致优化
前文讲解的读写自旋锁虽实现了读共享,但读操作仍会被写操作阻塞(写锁独占时,读操作需自旋等待),无法满足“读操作零阻塞”的场景(如内核时钟统计、性能计数器),这类场景下需要更高效的同步机制。Linux 6.6在Armv8架构下提供了顺序锁(seqlock),核心设计是“写操作不阻塞读操作,读操作通过校验顺序值保证数据一致性”,彻底解决读阻塞问题,代价是写操作需保证幂等性,且临界资源需为简单数据类型(如int、long)或可原子更新的结构体,适配高频读、低频写的极致场景。
5.1 顺序锁核心原理(Armv8架构适配)
顺序锁的核心是一个“顺序计数器(seq)”,搭配临界资源,其核心逻辑区别于基础自旋锁和读写自旋锁,无需通过原子指令竞争锁资源,而是通过顺序值校验保证数据一致性,具体逻辑如下:
读操作:读取顺序值seq → 读取临界资源 → 再次读取seq;若两次读取的seq相等且为偶数(无写操作执行),则数据一致,读取有效;若不相等或为奇数(写操作正在执行),则重新读取;
写操作:先将seq加1(标记写操作开始,seq变为奇数) → 原子更新临界资源 → 再将seq加1(标记写操作结束,seq变为偶数);
原子性保证:Armv8架构下,seq的更新通过ldrex/strex原子指令实现,临界资源的更新若为64位数据,需使用Armv8的ldxr/stxr指令(64位独占操作),避免写操作被打断,这也是Armv8架构下顺序锁实现的核心适配点。
核心优势:读操作无需获取锁,零阻塞;写操作仅需更新顺序值和临界资源,自旋等待极少(仅当多个写操作并发时自旋),适配高频读、低频写的场景,相比读写自旋锁,进一步提升了读操作的效率,充分适配Armv8多核平台的高性能需求。
5.2 核心源码与结构体(Linux 6.6 Armv8)
(1)顺序锁结构体seqlock_t
Armv8架构下,seqlock_t结构体定义简洁,核心包含顺序计数器,无需复杂的状态标记,其设计充分贴合“零阻塞读”的核心需求,源码路径:arch/arm64/include/asm/seqlock.h:
// arch/arm64/include/asm/seqlock.htypedefstruct {unsignedint seq; // 顺序计数器:偶数=空闲,奇数=写操作中} seqlock_t;补充说明:Armv8 64位架构下,若临界资源为64位数据(如u64),seqlock_t会自动适配,通过ldxr/stxr指令实现64位原子更新,无需额外处理,这也是Armv8 64位架构的优势之一,简化了顺序锁在64位数据场景下的使用。
(2)核心操作函数(关键封装)
Linux 6.6为顺序锁封装了通用操作函数,底层适配Armv8的原子指令和内存屏障指令,其封装逻辑与基础自旋锁、读写自旋锁一致,核心函数如下,重点关注顺序值的读取与校验:
// 1. 顺序锁初始化#define seqlock_init(sl) do { (sl)->seq = 0; } while (0)// 2. 读操作开始:获取当前顺序值staticinlineunsignedintread_seqbegin(constseqlock_t *sl){unsignedint seq;// 内存屏障,保证读顺序值在读取临界资源之前 smp_rmb(); seq = sl->seq;return seq;}// 3. 读操作结束:校验顺序值,判断数据是否一致staticinlineintread_seqretry(constseqlock_t *sl, unsignedint start){// 内存屏障,保证读取临界资源在读取顺序值之前 smp_rmb();return sl->seq != start;}// 4. 写操作开始:标记写操作启动(seq+1,变为奇数)staticinlinevoidwrite_seqbegin(seqlock_t *sl){ sl->seq++; smp_wmb(); // 内存屏障,保证写顺序值在写临界资源之前}// 5. 写操作结束:标记写操作完成(seq+1,变为偶数)staticinlinevoidwrite_seqend(seqlock_t *sl){ smp_wmb(); // 内存屏障,保证写临界资源在写顺序值之前 sl->seq++;}关键细节:smp_rmb()/smp_wmb()本质是Armv8架构dmb指令的封装,用于保证指令执行顺序,避免CPU乱序执行导致seq值与临界资源数据不一致,这与前文基础自旋锁、读写自旋锁中内存屏障的使用逻辑一致,都是保证同步机制正确性的核心。
5.3 顺序锁实操(Armv8 Linux 6.6)
结合顺序锁的核心原理与源码封装,以下代码适配Armv8架构,实现“高频读取系统运行计数、低频更新计数”的场景(如内核性能统计),读操作零阻塞,写操作原子执行,充分发挥顺序锁的优势:
#include<linux/seqlock.h>#include<linux/module.h>#include<linux/timer.h>// 1. 定义顺序锁和临界资源(系统运行计数,64位)staticseqlock_t sys_count_seqlock;static u64 sys_run_count = 0; // 临界资源:系统运行计数(高频读、低频写)// 定时器回调:每1秒更新计数(写操作,低频)staticvoidsys_count_timer(unsignedlong data){ write_seqbegin(&sys_count_seqlock); // 写操作开始,seq变为奇数 sys_run_count++; // 原子更新临界资源(Armv8 64位原子操作) write_seqend(&sys_count_seqlock); // 写操作结束,seq变为偶数// 重启定时器 mod_timer((struct timer_list *)data, jiffies + HZ);}// 读操作:零阻塞读取系统运行计数static u64 get_sys_run_count(void){unsignedint seq; u64 count;// 循环读取,直到获取到一致的数据do { seq = read_seqbegin(&sys_count_seqlock); // 获取开始seq count = sys_run_count; // 读取临界资源 } while (read_seqretry(&sys_count_seqlock, seq)); // 校验seqreturn count;}// 模块初始化staticint __init seqlock_init(void){staticstructtimer_listcount_timer;// 初始化顺序锁 seqlock_init(&sys_count_seqlock);// 初始化定时器(1秒触发一次) init_timer(&count_timer); count_timer.function = sys_count_timer; count_timer.data = (unsignedlong)&count_timer; count_timer.expires = jiffies + HZ; add_timer(&count_timer); printk("seqlock init success (Armv8 Linux 6.6)\n");return0;}// 模块退出staticvoid __exit seqlock_exit(void){ del_timer_sync((struct timer_list *)sys_count_seqlock.seq); printk("seqlock module exit\n");}module_init(seqlock_init);module_exit(seqlock_exit);MODULE_LICENSE("GPL");关键注意事项(Armv8架构专属):
临界资源限制:顺序锁仅适用于“简单数据类型”或“可原子更新的结构体”,若临界资源为复杂结构体(不可原子更新),写操作可能导致读操作获取到残缺数据,这是由顺序锁“无阻塞读”的设计逻辑决定的;
写操作幂等性:若写操作被打断(如中断),seq会保持奇数,读操作会重新读取,因此写操作需保证幂等性,避免多次执行导致数据错误,这一点在Armv8多核中断场景下需重点关注;
64位数据适配:Armv8 64位架构下,u64类型的更新可通过ldxr/stxr指令原子执行,无需额外加锁;32位Armv8架构需注意64位数据的拆分更新,避免出现数据错乱。
六、Linux 6.6 Armv8自旋锁体系避坑指南(重点)
前文已完整讲解了Armv8架构下基础自旋锁、读写自旋锁、顺序锁的原理、源码与实操,以及Armv8架构的特性,本节总结5个高频踩坑点,附具体解决方案,帮助开发者规避开发中的常见问题,保障驱动稳定性。
坑点1:临界区过长,导致CPU空转浪费
Armv8多核CPU中,若自旋锁、读写自旋锁的临界区执行时间过长(如包含msleep、copy_from_user等耗时操作),会导致其他CPU持续自旋,浪费算力,违背了自旋锁“临界区极短”的核心前提。
解决方案:严格遵循“临界区极短”原则,耗时操作移出临界区;若必须耗时,改用互斥锁(mutex),而非各类自旋锁,避免CPU空转。
坑点2:递归获取自旋锁,导致死锁
Linux 6.6的自旋锁、读写自旋锁均不支持递归获取,若同一CPU已持有锁,再次调用获取锁的函数会陷入死循环(Armv8架构下无法抢占自身),这是自旋锁使用中最常见的死锁场景。
解决方案:梳理代码逻辑,避免递归调用;若需多次获取,改用try类函数(spin_trylock等)判断锁状态,失败则退出,同时确保锁的获取与释放严格配对。
坑点3:忽略内存屏障,导致锁状态错乱
Armv8 CPU支持乱序执行,若自定义自旋锁相关操作(未使用内核提供的宏/函数),忽略dmb/dsb指令,会导致临界区指令乱序,锁状态判断错误,进而引发资源竞争问题。
解决方案:优先使用内核提供的封装函数(spin_lock、read_seqbegin等),无需手动添加内存屏障;自定义原子操作时,必须添加dmb(ish)指令,保证指令执行顺序。
坑点4:单核编程忽略多核兼容,移植失败
“单核编程需考虑多核兼容”,Armv8架构多为多核,若单核环境下编写的自旋锁代码未考虑多核并发(如未使用ldrex/strex原子指令),移植到多核Armv8设备时会出现锁竞争、数据错乱,导致移植失败。
解决方案:无论单核还是多核环境,均使用Linux 6.6内核封装的自旋锁函数(spin_lock、rwlock_init等),底层已适配Armv8多核原子操作,无需手动适配,确保代码的可移植性。
坑点5:顺序锁误用复杂结构体,导致数据残缺
Armv8架构下,顺序锁的读操作无阻塞,但若将其用于保护复杂结构体(不可原子更新),写操作过程中会导致读操作获取到残缺数据,引发逻辑错误,这是顺序锁使用中最易忽略的场景限制。
解决方案:顺序锁仅用于保护简单数据类型(int、u64等)或可原子更新的结构体;复杂结构体优先使用读写自旋锁,保证数据一致性,避免误用场景导致的错误。
七、总结
本文基于Linux 6.6内核源码,结合Armv8架构特性,完整拆解了自旋锁体系的核心实现与实操方法,从基础自旋锁的底层指令、源码细节,到读写自旋锁、顺序锁的场景适配,再到高频踩坑指南,形成了“原理-源码-实操-避坑”的完整学习链路,层层递进、衔接紧密,覆盖了Armv8架构下自旋锁使用的全场景。
核心要点总结:Linux 6.6 Armv8架构下的自旋锁体系,均基于ldrex/strex原子指令、dmb内存屏障指令实现,核心差异在于场景适配——基础自旋锁适用于通用临界资源的排他保护,读写自旋锁适配读多写少场景,顺序锁适配高频读、零阻塞场景。三者相辅相成,复用底层指令集降低适配成本,同时满足不同场景下的同步需求,掌握各类锁的核心特性与正确用法,规避临界区过长、递归获取等常见问题,是保障Armv8架构内核驱动稳定性、高效性的关键。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Arcjet Python SDK:安全防护,代码原生集成!
- 一天一个Python知识点——Day 155:神经网络基础
- Linux如何更改IP
- 【GESP】2025年12月Python三级 -- 密码强度
- 分布式电源对配电网故障定位的影响(Python代码实现)
- 【第32篇/1000】Python安装 + JSON转Word实战(附完整代码)
- 【计算机二级 Python・每日 10 考点】Day6
- 重新盘一盘Java集合框架并发异常
- Linux inode 到底是什么?为什么删除文件后磁盘空间不释放?
- 200 + 本编程神书免费领!从 Python 到 Java,从前端到后端,全套资料直接抱走
