作为程序员,日常工作和生活中我们经常需要和网络数据打交道 —— 想快速查询快递物流信息,不用反复打开 APP,几行代码就能自动获取;想每日获取精准的天气预警并保存到本地,避免出门遇雨;想批量爬取电商平台的商品优惠信息,对比不同店铺的性价比;甚至想调用第三方 API 完成手机号归属地查询、身份证实名认证核验…… 这些看似需要复杂网络交互的操作,都能通过 Python 的 requests 库轻松实现。
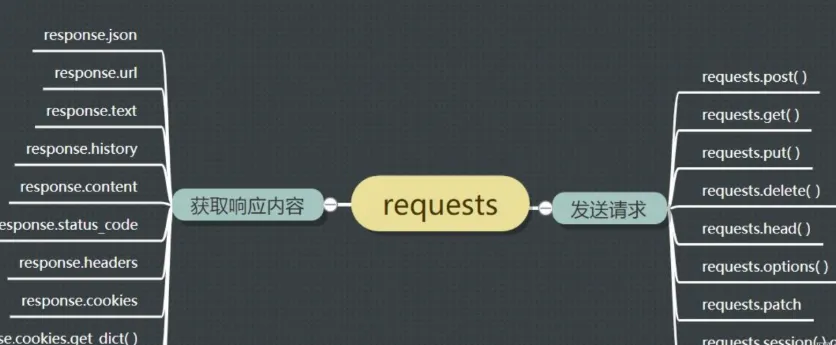
requests 是基于 urllib3 开发的 HTTP 请求库,它以极简的语法、人性化的 API 设计,替代了 Python 内置 urllib 库的繁琐操作,成为 Python 生态中处理网络请求的 “事实标准”。无论是个人开发者制作轻量化工具,还是企业级项目中对接第三方接口,requests 都是无可替代的核心库 —— 它把 “从网络获取 / 提交数据” 的操作,从需要编写几十行底层代码的繁琐过程,简化到几行代码就能落地,是每个 Python 开发者必备的基础工具。
一、安装 requests 库
requests 支持 Python 3.6 及以上版本,安装过程极其简单。打开终端 / 命令提示符,执行以下命令即可完成安装:
# 基础安装命令pip install requests# 若环境存在多Python版本,使用pip3避免冲突pip3 install requests
安装完成后,在 Python 脚本中通过import requests即可导入并使用。
二、基本用法(分 4 个核心步骤)
步骤 1:发送基础 GET 请求
GET 是最常用的 HTTP 请求方法,用于从服务器获取数据。比如获取百度首页内容:
import requests# 发送GET请求,获取响应对象response = requests.get("https://www.baidu.com")# 响应状态码:200表示请求成功,4xx/5xx表示异常print("请求状态码:", response.status_code)# 打印网页内容片段(前100个字符)print("百度首页内容片段:", response.text[:100])
步骤 2:处理 JSON 格式响应
多数第三方 API 返回 JSON 格式数据,requests 内置 JSON 解析方法,无需额外导入 json 库:
# 调用免费IP查询API,获取公网IPresponse = requests.get("http://httpbin.org/ip")# 解析JSON为Python字典(核心方法)ip_data = response.json()print("你的公网IP地址:", ip_data["origin"])
步骤 3:设置请求头模拟浏览器
部分网站会拦截非浏览器的请求,需通过请求头(Headers)模拟浏览器访问:
# 构造浏览器请求头headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"}# 带请求头访问知乎,避免被拦截response = requests.get("https://www.zhihu.com", headers=headers)print("知乎请求状态码:", response.status_code)
步骤 4:传递 URL 参数(无需手动拼接)
查询天气、快递等场景需传递参数,requests 的params参数可自动拼接 URL,避免编码错误:
# 构造查询参数:查询北京今日天气(示例API)params = { "city": "北京", "type": "today", "source": "python"}# 发送带参数的GET请求response = requests.get("http://example.com/weather", params=params)# 实际请求的URL会自动拼接为:http://example.com/weather?city=北京&type=today&source=pythonprint("实际请求URL:", response.url)
三、高级用法
1. 发送 POST 请求提交表单
POST 常用于提交数据(如登录、注册),示例如下:
# 模拟登录表单数据login_data = { "username": "test_user", "password": "test_123456"}# 发送POST请求提交表单response = requests.post("http://example.com/login", data=login_data)print("登录响应结果:", response.text)
2. 设置超时与异常处理
网络请求易超时或失败,需添加异常捕获保证程序健壮性:
import requestsfrom requests.exceptions import Timeout, ConnectionErrortry: # 设置超时时间为3秒,超过则抛出Timeout异常 response = requests.get("https://www.taobao.com", timeout=3) print("淘宝请求成功")except Timeout: print("请求超时:服务器响应过慢,请稍后重试")except ConnectionError: print("连接失败:请检查URL是否正确或网络是否畅通")
3. 会话保持(模拟登录后持续访问)
会话对象可保留登录 Cookie,避免每次请求重新登录:
# 创建会话对象(核心)session = requests.Session()# 第一步:登录(会话自动保存Cookie)login_data = {"username": "my_user", "password": "my_pass"}session.post("http://example.com/login", data=login_data)# 第二步:登录后访问个人中心(自动携带Cookie)profile_response = session.get("http://example.com/profile")print("个人中心内容片段:", profile_response.text[:200])
四、实际应用场景(附深度案例代码)
场景 1:自动查询快递物流(日常高频需求)
对接快递 100 免费 API(需申请 APIKey),输入单号即可自动获取物流轨迹:
import requestsdef query_express(express_no, company): """ 查询快递物流信息 :param express_no: 快递单号 :param company: 快递公司编码(sf=顺丰,yt=圆通,jd=京东) """ url = "https://www.kuaidi100.com/query" params = { "type": company, "postid": express_no, "temp": "0.123456789", # 防缓存参数 "phone": "" # 部分快递需填写手机号后4位 } try: response = requests.get(url, params=params, timeout=5) result = response.json() if result["status"] == "200": print(f"\n【{express_no}】物流轨迹:") # 倒序打印最新物流在前 for item in reversed(result["data"]): print(f"{item['time']} → {item['context']}") else: print("查询失败:", result["message"]) except Exception as e: print("查询异常:", str(e))# 调用示例(替换为真实单号和快递公司编码)query_express("SF1234567890123", "sf")
场景 2:每日自动获取天气并保存(生活实用工具)
对接和风天气 API(需申请免费 Key),每日获取天气并保存到本地文件:
import requestsfrom datetime import datetimedef save_daily_weather(city_id="101010100"): """ 获取并保存每日天气(city_id=101010100为北京) """ url = "https://devapi.qweather.com/v7/weather/now" params = { "location": city_id, "key": "你的和风天气APIKey" # 替换为自己申请的Key } response = requests.get(url, params=params) weather_data = response.json() if weather_data["code"] == "200": # 整理天气信息 weather_info = { "记录时间": datetime.now().strftime("%Y-%m-%d %H:%M:%S"), "城市": "北京", "实时温度": weather_data["now"]["temp"] + "℃", "天气状况": weather_data["now"]["text"], "风力": weather_data["now"]["windDir"] + weather_data["now"]["windScale"] + "级" } # 追加保存到文件 with open("weather_log.txt", "a", encoding="utf-8") as f: f.write(str(weather_info) + "\n") print("今日天气已保存:", weather_info) else: print("天气查询失败,错误码:", weather_data["code"])# 执行函数,每日运行一次即可save_daily_weather()
requests 库的核心价值在于将复杂的 HTTP 协议封装成简单易懂的 API,让开发者无需关注底层的 TCP 连接、报文解析等细节,只需聚焦 “获取 / 提交什么数据” 的业务逻辑。它的设计哲学 “HTTP for Humans”(面向人类的 HTTP),完美契合了 Python“简洁、易用” 的核心特质 —— 无论是个人做轻量化的生活工具,还是企业级的接口对接,requests 都能以极高的效率和稳定性完成工作。
你是否用过 requests 库解决过生活中的实际问题?比如自动获取火车票余票、批量下载公众号文章,或者对接过更有趣的 API(如垃圾分类查询、电影票房统计)?欢迎在评论区分享你的使用场景和代码片段,我们可以一起探讨如何用 requests 把日常的重复操作自动化,让编程真正服务于生活。
总结
- requests 库是 Python 处理 HTTP 请求的核心工具,能简化网络数据获取 / 提交的全流程,适配日常和企业级开发场景;
- 核心用法包括 GET/POST 请求、JSON 解析、请求头设置、会话保持,搭配异常处理可提升程序健壮性;
- 实际应用中可对接快递、天气等公共 API,快速实现自动化工具开发,解决生活中的高频需求。