期刊图片复现|Python绘制数据在100次随机划分情况下模型的模型性能评估(包括R2、RMSE及标准差)散点图
- 2026-07-04 05:22:33
期刊图片复现|Python绘制数据在100次随机划分情况下模型的模型性能评估(包括R2、RMSE及标准差)散点图

论文:Machine learning prediction of pore structure and nitrogen content of N-doped biochar derived from biomass pyrolysis: Effects of biomass elemental compositions, preparation processes, and preparation methods 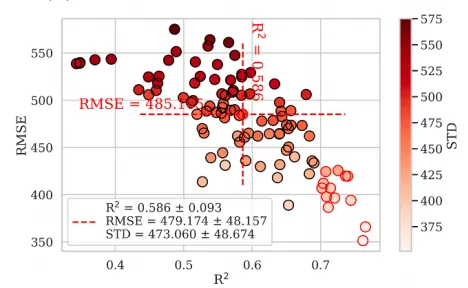
论文原图 为了全面评估模型的稳定性,此图通过改变随机种子进行了100次不同的数据分割,从而获得了100组独立的测试结果 。在训练过程中,采用五折交叉验证方法,利用基于RMSE的网格搜索对超参数进行了优化筛选 。最终,利用最佳超参数在训练集上重新训练模型,并在测试集上计算R2、RMSE和STD,图中的每一个散点即代表这100次随机划分中某一次的具体预测性能表现 。展示了RF模型在预测SSA时的性能评估结果,横轴代表R2,纵轴代表RMSE,颜色则表示STD。统计数据显示,该模型在多次测试中的平均R2为0.586±0.093,平均RMSE为479.174±48.157,平均标准差为473.060±48.674,红色虚线十字定位了这些均值的中心位置 。图中数据点呈现出从左上到右下的分布趋势,说明随着R2的增加,RMSE相应降低;同时,右下角聚集的颜色较浅的数据点表明,当模型预测精度较高时,其性能也更为稳定,而左上角的深红色数据点则对应着高误差和高波动性的较差预测结果 。 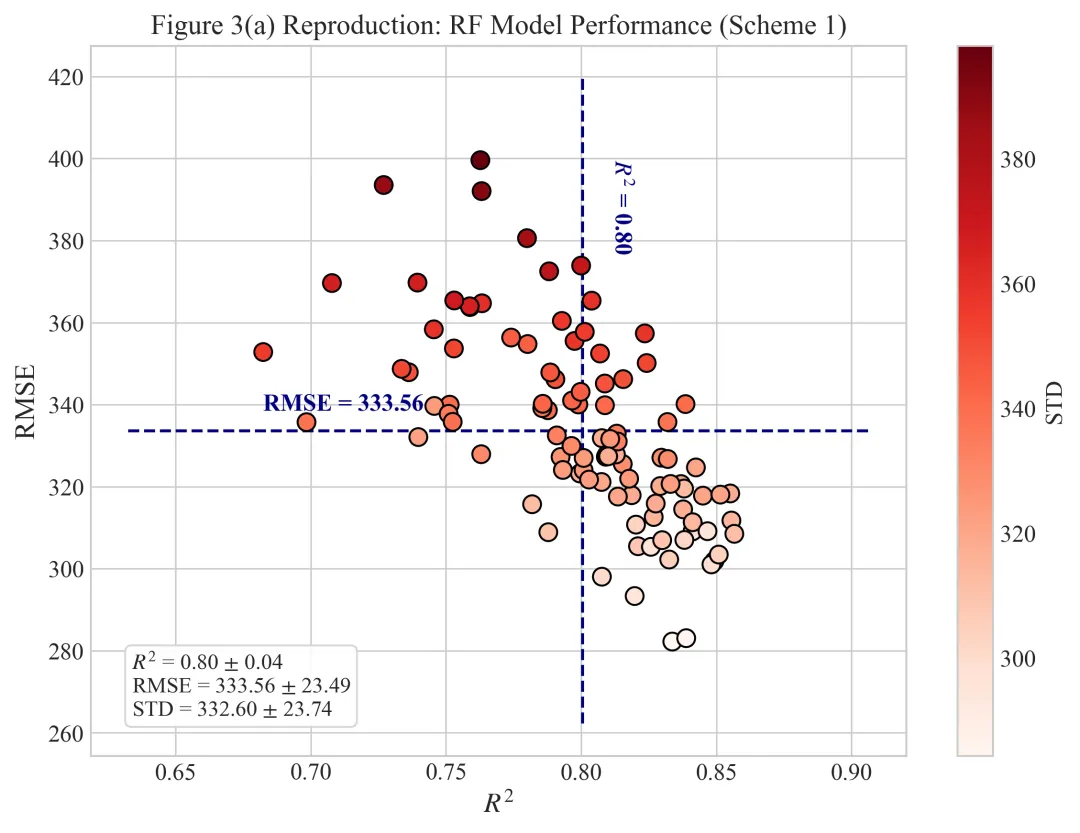
仿图 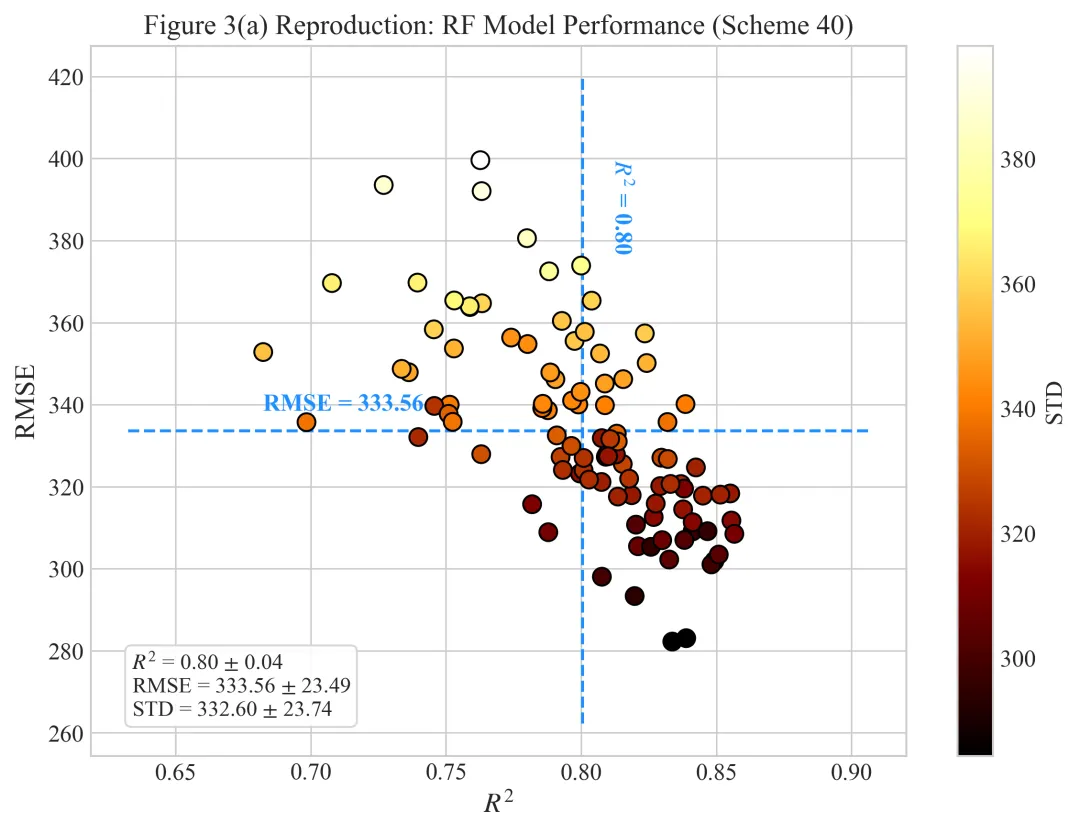
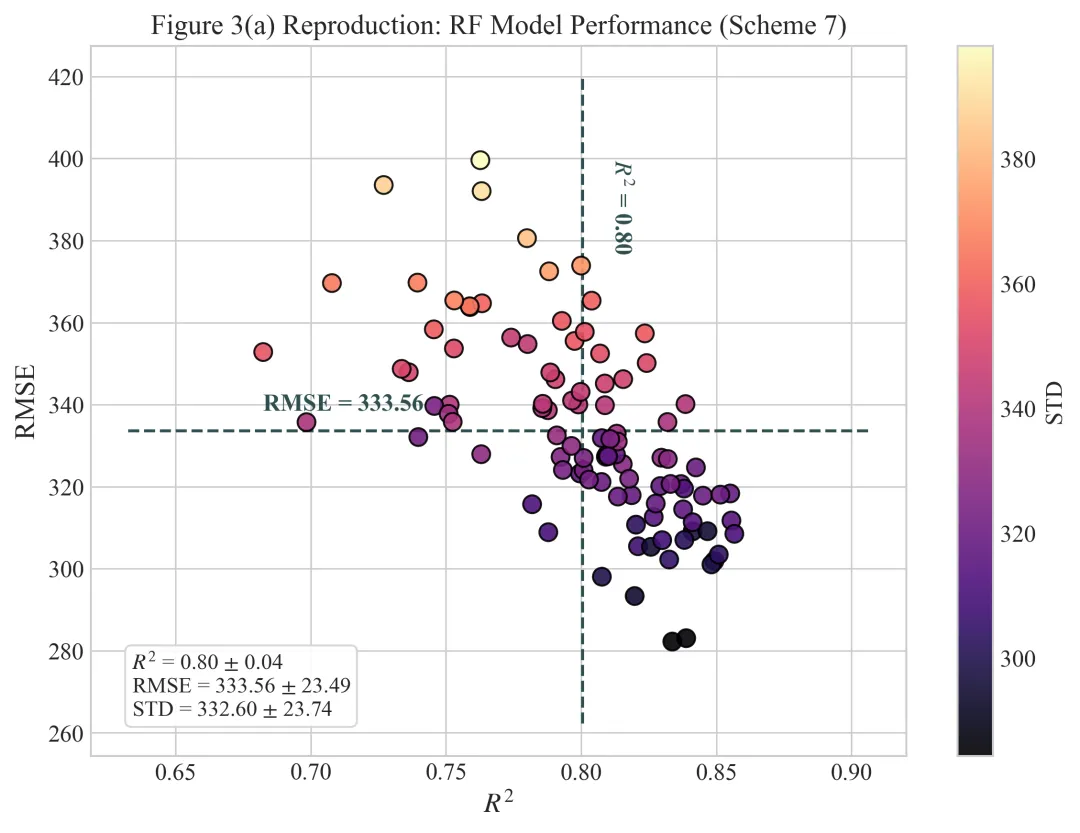
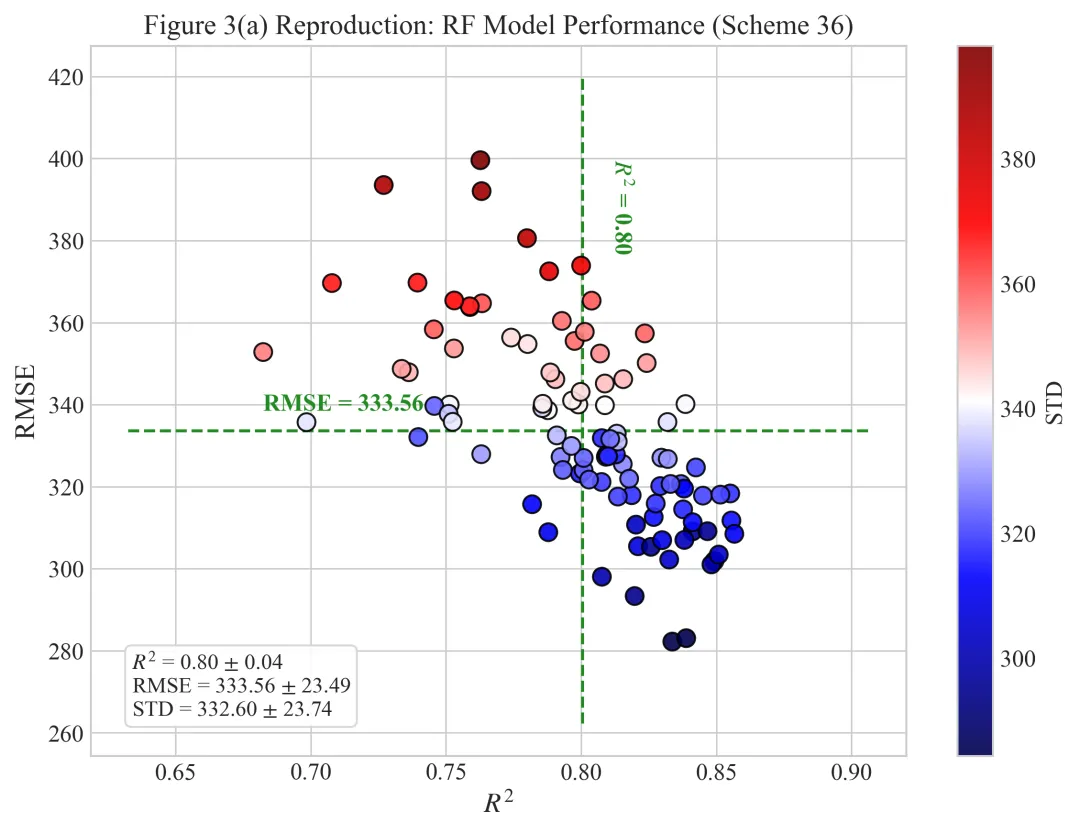
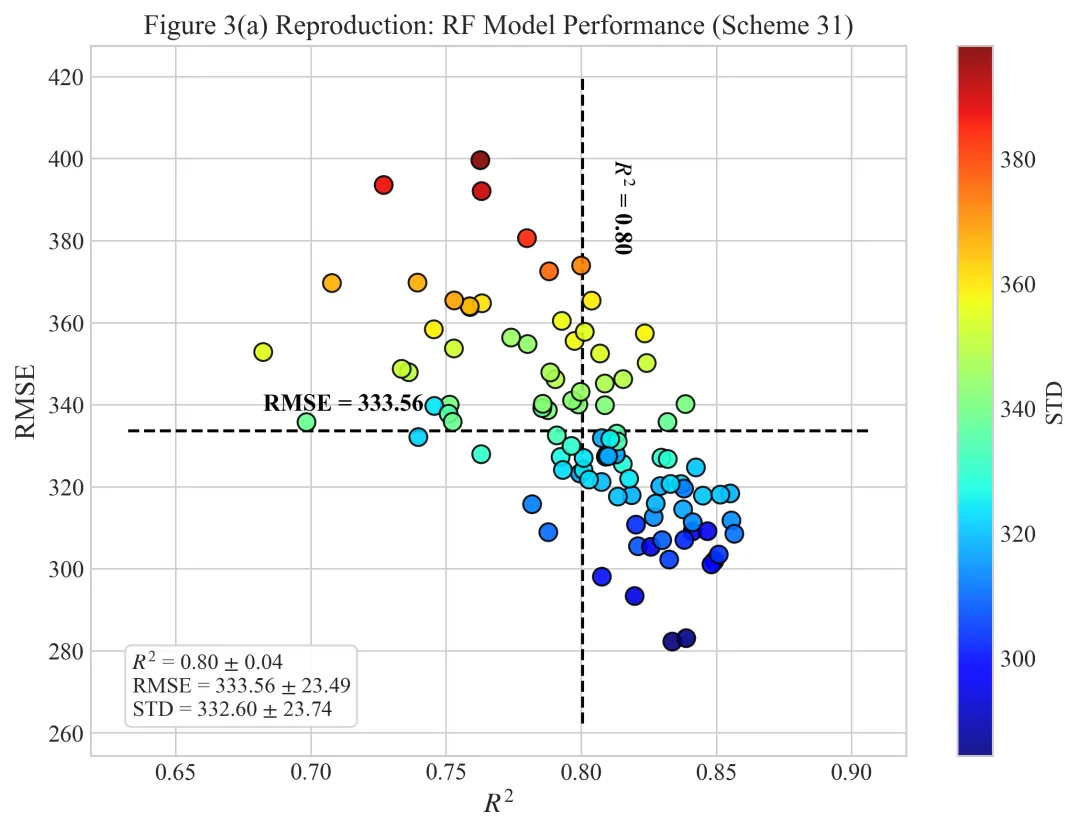
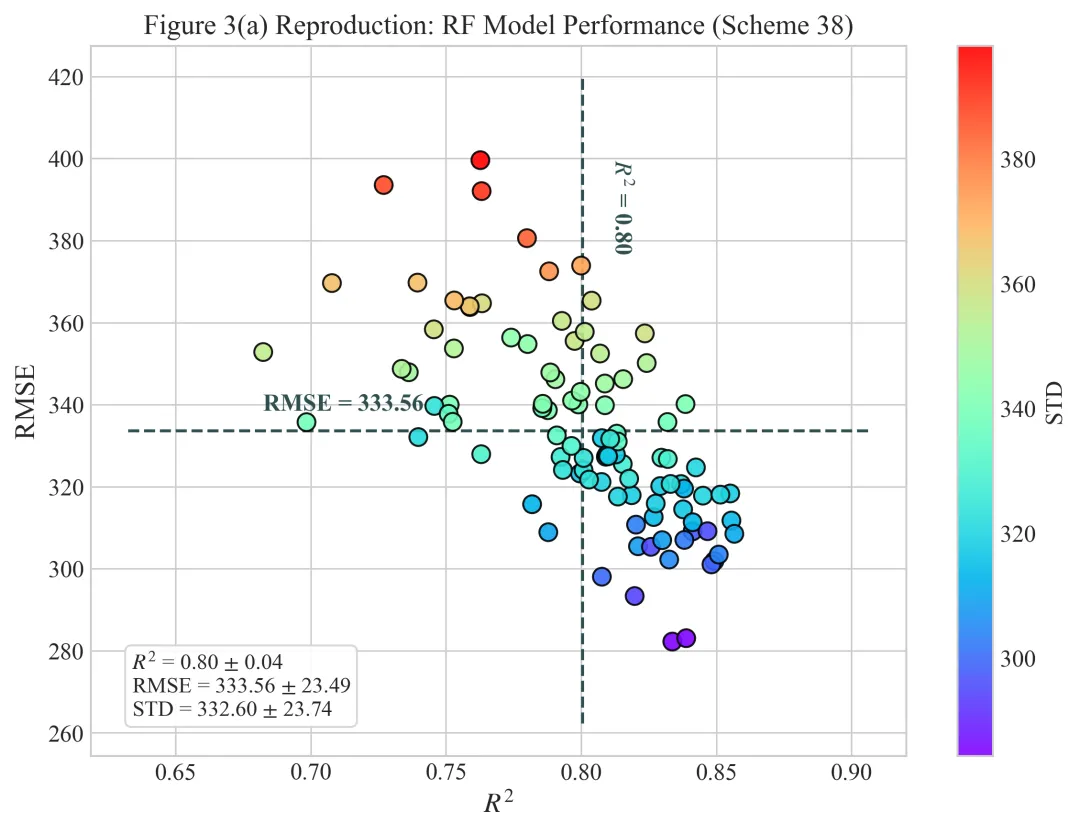
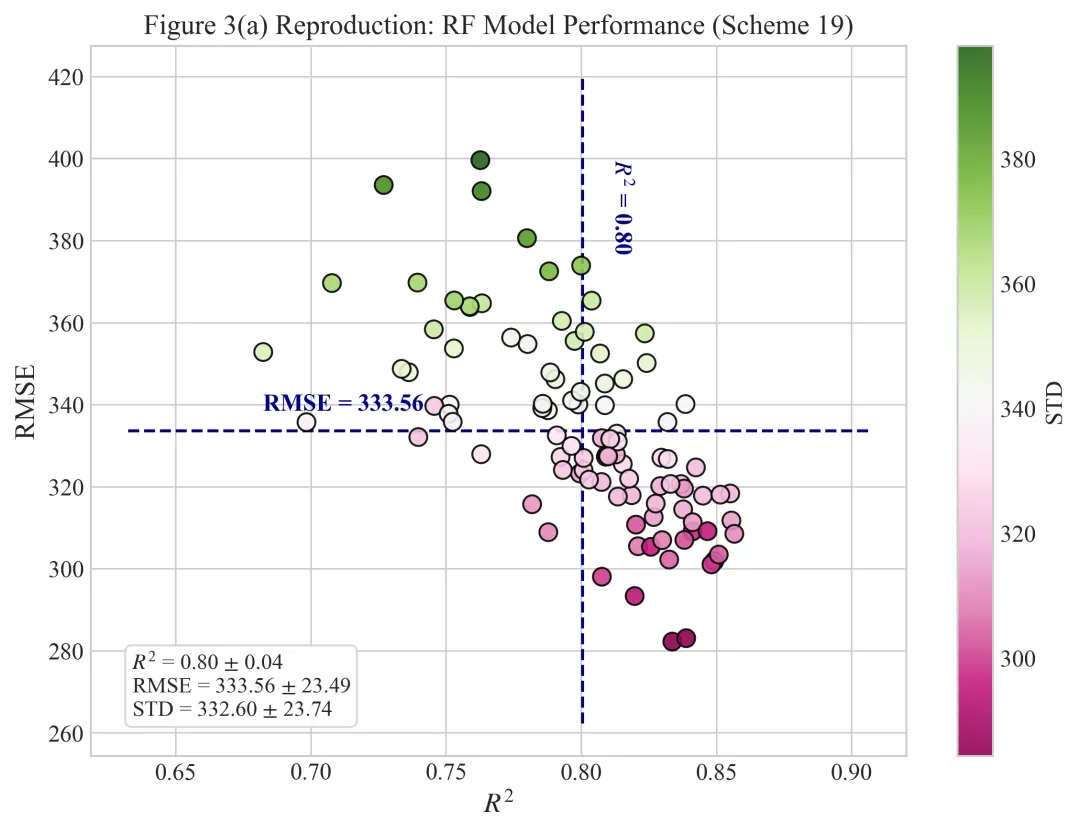
多种配色 



库的导入以及字体设置 

颜色库的设置以及配色方案的设置与选择 

绘图函数:颜色获取,计算R2、RMSE、STD这三个指标的均值和样本标准差,这些统计量将用于后续在图中展示模型的整体性能和波动情况 

绘图函数:创建画布与绘制核心散点 

绘图函数:绘制均值辅助线,分别绘制垂直线和水平线。这两条线交叉点即为所有随机实验结果的平均性能点。 

绘图函数:设置坐标轴与统计信息框。 

执行部分:数据读取与编码,因为RF不能直接处理字符串类别的特征,所以需要将PM, AAT, NDT这些列从文本转换为数字。 







期刊图片复现|Python绘制二维偏依赖PDP图 期刊复现|python绘制基于SHAP分析和GAM模型拟合的单特征依赖图 期刊图片复现|python绘制带有渐变颜色shap特征重要性组合图(条形图+蜂巢图) 期刊复现|用Python绘制SHAP特征重要性总览图、依赖图、双特征交互效应SHAP图,解锁XGBoost模型的终极奥秘 期刊图片复现|Python绘制shap重要性蜂巢图+单特征依赖图+交互效应强度气泡图+交互效应依赖图(回归+二分类+分类) 

公众号中的所有所有的免费代码都已经下架了,都并入到付费部分里了,付费合集代码和数据的购买通道已经开通,全部合集100元,后续将会持续更新,决定购买请后台私信我,注意只会分享练习数据和代码文件,不会提供答疑服务,代码文件中已经包含了每行代码的完整注释,购买前请确保真的需要!!!
代码绘制成果展示
代码解释
第一部分
# =========================================================================================# ====================================== 1. 环境设置 =======================================# =========================================================================================import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.ensemble import RandomForestRegressorfrom sklearn.model_selection import train_test_split, GridSearchCVfrom sklearn.metrics import r2_score, mean_squared_errorfrom sklearn.preprocessing import LabelEncoder
第二部分
# =========================================================================================# ======================================2.颜色库=======================================# =========================================================================================COLOR_SCHEMES = {1: {'cmap': 'Reds', 'line_text': 'navy'},}SCHEME_ID = 1#设置配色方案scheme = COLR_SCHEMES.get(SCHEME_ID, COLOR_SCHEMES[1]) #获取配色
第三部分
# =========================================================================================# ======================================3.绘图函数=======================================# =========================================================================================def plot_model_performance(r2_list, rmse_list, std_list):cmap_name = scheme['cmap'] #获取颜色映射名称line_text_color = scheme['line_text'] #获取线条和文字颜色r2_mean = np.mean(r2_list) #R2平均值r2_std_dev = np.std(r2_list, ddof=1) #R2标准差rmse_mean = np.mean(rmse_list) #RMSE平均值rmse_std_dev = np.std(rmse_list, ddof=1) #RMSE标准差std_mean = np.mean(std_list) #残差标准差的平均值std_std_dev = np.std(std_list, ddof=1) #残差标准差的标准差
第四部分
#创建画布fig, ax = plt.subplots(figsize=(8, 6))#绘制散点图sc = ax.scatter(r2_list, #x轴rmse_list, #y轴c=std_list, #颜色依据cmap=cmap_name, #颜色条edgecolors='k', #散点边缘的颜色s=80, #散点的大小alpha=1, #透明度zorder=2)cbar = plt.colorbar(sc, ax=ax) #添加颜色条cbar.set_label('STD', fontsize=12) #颜色条标签
第五部分
#R2均值虚线ax.vlines(r2_mean, # xymin=min(rmse_list) - 20, #起点ymax=max(rmse_list) + 20, #终点colors=line_text_color, #颜色linestyles='--', #样式label='_nolegend_', #图例标签zorder=1) #图层顺序#RMSE均值虚线ax.hlines(rmse_mean, # yxmin=min(r2_list) - 0.05, #起点xmax=max(r2_list) + 0.05, #终点colors=line_text_color, #颜色linestyles='--', #样式label='_nolegend_', #图例标签zorder=1) #图层顺序
第六部分
ax.set_xlabel('$R^2$', fontsize=14) #x轴标题ax.set_ylabel('RMSE', fontsize=14) #y轴标题#图框中显示的统计文本内容legend_text = (f'$R^2$ = {r2_mean:.2f} $\pm$ {r2_std_dev:.2f}\n'f'RMSE = {rmse_mean:.2f} $\pm$ {rmse_std_dev:.2f}\n'f'STD = {std_mean:.2f} $\pm$ {std_std_dev:.2f}')#文本框样式属性props = dict(boxstyle='round', #边框样式,圆角矩形facecolor='white', #填充颜色alpha=0.9, #透明度edgecolor='lightgrey') #边缘颜色#添加统计信息文本框ax.text(0.05, #x0.05, #ylegend_text, #文本内容transform=ax.transAxes, #坐标变换fontsize=11, #字体大小verticalalignment='bottom', #垂直对齐bbox=props) #边框样式
第七部分
# =========================================================================================# ======================================4.执行部分=======================================# =========================================================================================if __name__ == "__main__":df = pd.read_excel(r'data.xlsx' ) # 读取Excel数据文件le = LabelEncoder() #实例化标签编码器cat_features = ['PM', 'AAT', 'NDT'] #定义需要进行编码的类别特征列名existing_cols = [col for col in cat_features if col in df.columns] #检查数据集中实际存在的类别列df_processed = df.copy() #复制原始数据for col in existing_cols:df_processed[col] = le.fit_transform(df_processed[col]) #对类别特征进行数字化编码X = df_processed.drop(columns=['SSA']) #特征变量y = df_processed['SSA'] #目标变量
第八部分
r2_list = [] # 初始化R2结果列表rmse_list = [] # 初始化RMSE结果列表std_list = [] # 初始化STD结果列表#参数网格param_grid = {'n_estimators': [10, 20, 30],'max_depth': [3, 4]}print(f"开始运行 {n_iterations} 次随机测试")start_time = time.time() #开始时间# 建立网格搜索交叉验证器grid_search = GridSearchCV(estimator=rf,param_grid=param_grid,cv=5,scoring='neg_root_mean_squared_error',n_jobs=-1,verbose=0)#执行网格搜索grid_search.fit(X_train, y_train)#获取最佳模型best_model = grid_search.best_estimator_y_pred = best_model.predict(X_test) #在测试集上进行预测r2 = r2_score(y_test, y_pred) # R2rmse = np.sqrt(mean_squared_error(y_test, y_pred)) #RMSEresiduals = y_test - y_pred #预测残差std_val = np.std(residuals, ddof=1) #残差的标准差r2_list.append(r2) #将R2结果存入列表rmse_list.append(rmse) #将RMSE结果存入列表std_list.append(std_val) #将STD结果存入列表
第九部分
#每10次循环打印一次进度if (seed + 1) % 10 == 0:elapsed = time.time() - start_time #计算已耗时print(f"进度: {seed + 1}/{n_iterations} | 耗时: {elapsed:.1f}s | "f"当前最佳参数: {grid_search.best_params_}")total_time = time.time() - start_time #计算总运行耗时print(f"总耗时: {total_time:.1f} 秒")#调用绘图函数plot_model_performance(r2_list, rmse_list, std_list)
如何应用到你自己的数据
1.设置配色:
SCHEME_ID = 1#设置配色方案2.设置绘图结果的保存地址:
plt.savefig(fr'scheme_{SCHEME_ID}_optimized.png', dpi=300, bbox_inches='tight')3.设置原始数据的保存路径:
df = pd.read_excel(r'data.xlsx' ) # 读取Excel数据文件4.定义原始数据中的文本特征数据:
cat_features = ['PM', 'AAT', 'NDT'] #定义需要进行编码的类别特征列名5.设置超参数:
param_grid = {'n_estimators': [10, 20, 30],'max_depth': [3, 4]}
6.设置试验次数:
n_iterations = 100 #设置随机试验的迭代次数推荐
获取方式
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

