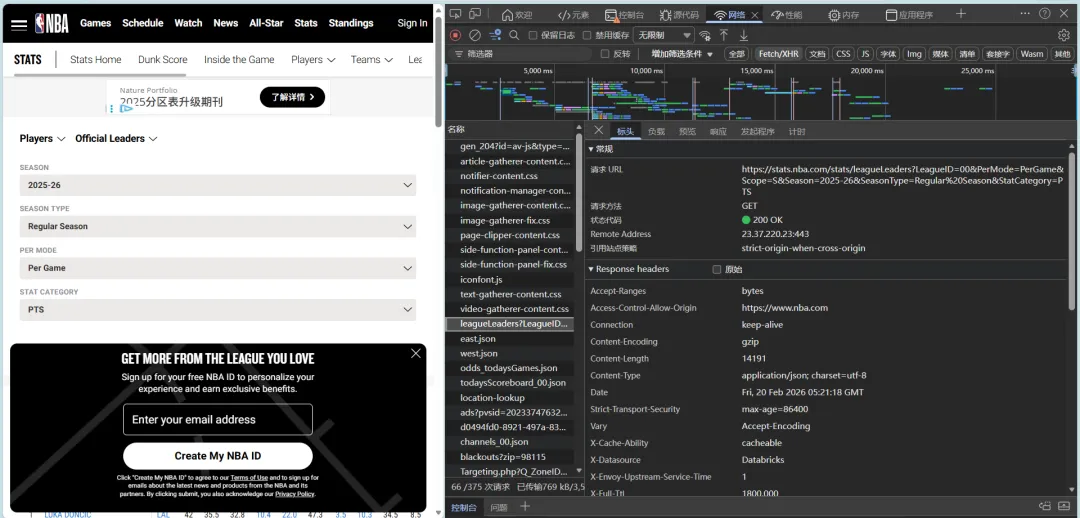
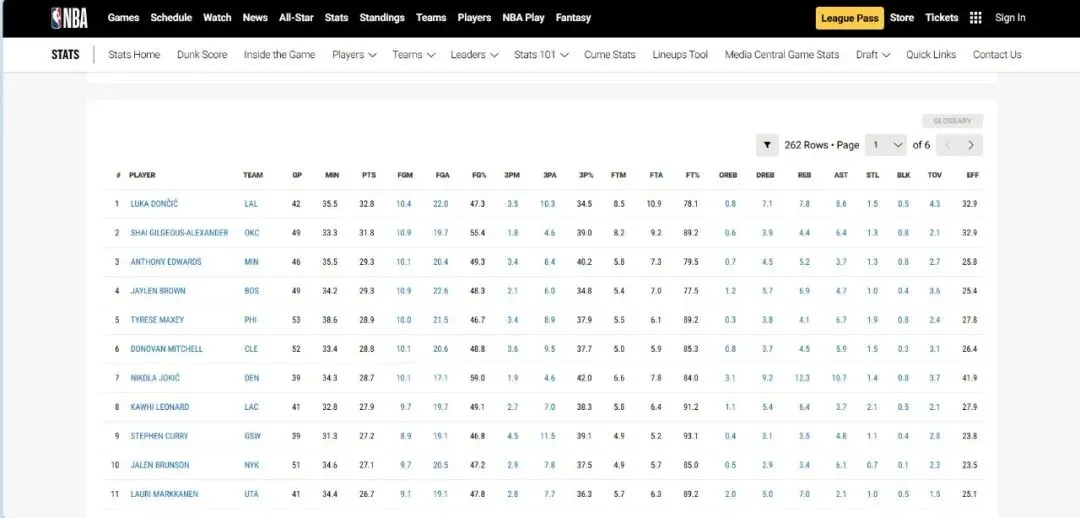
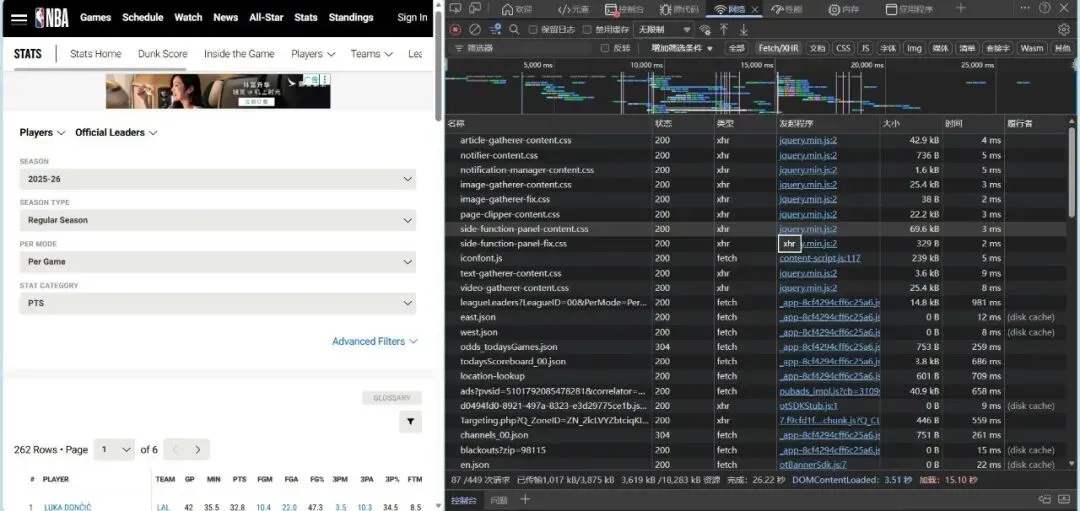
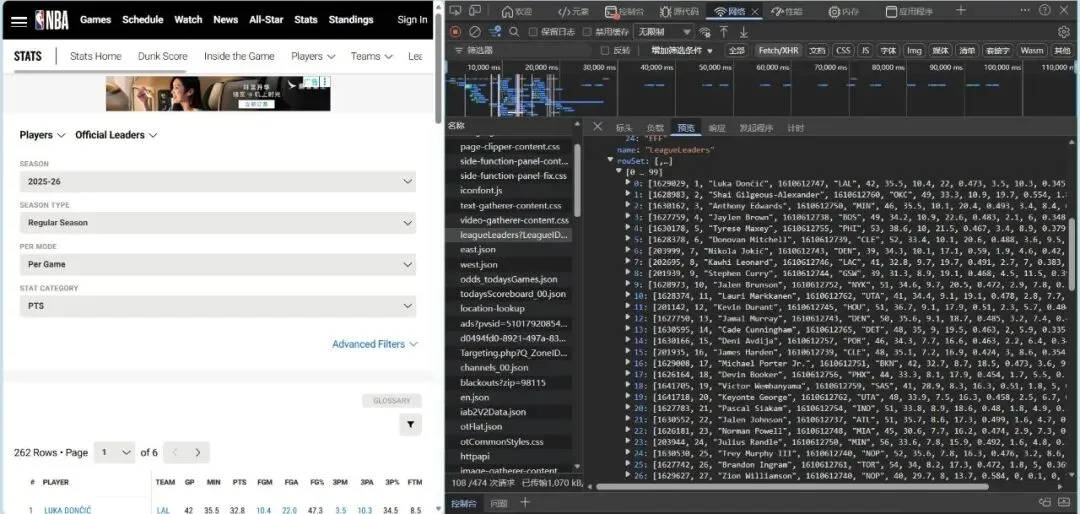
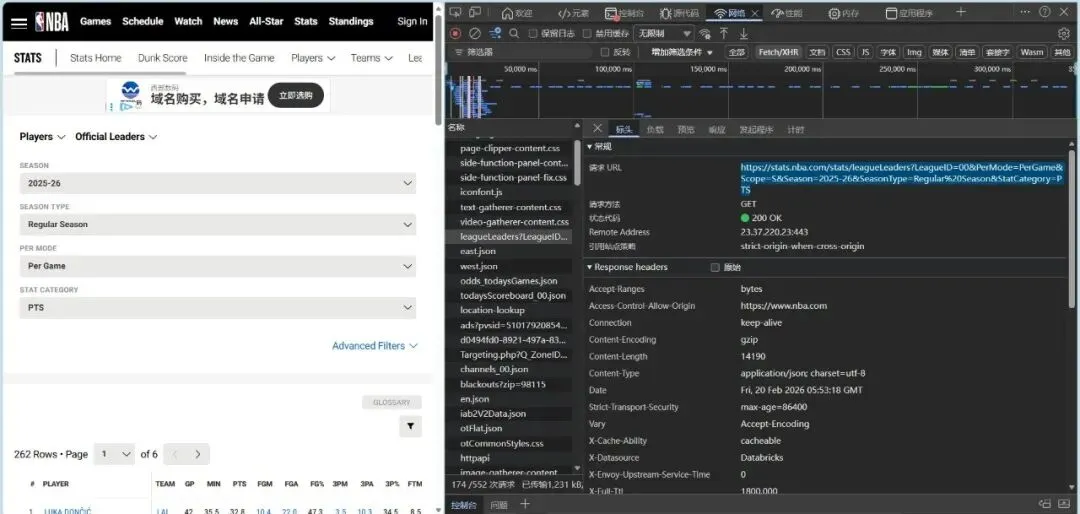
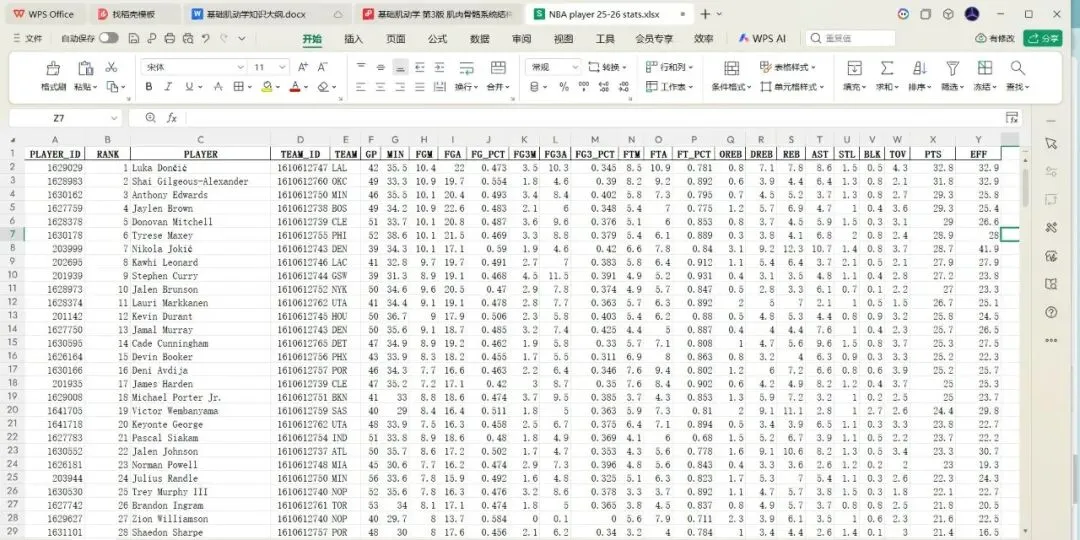
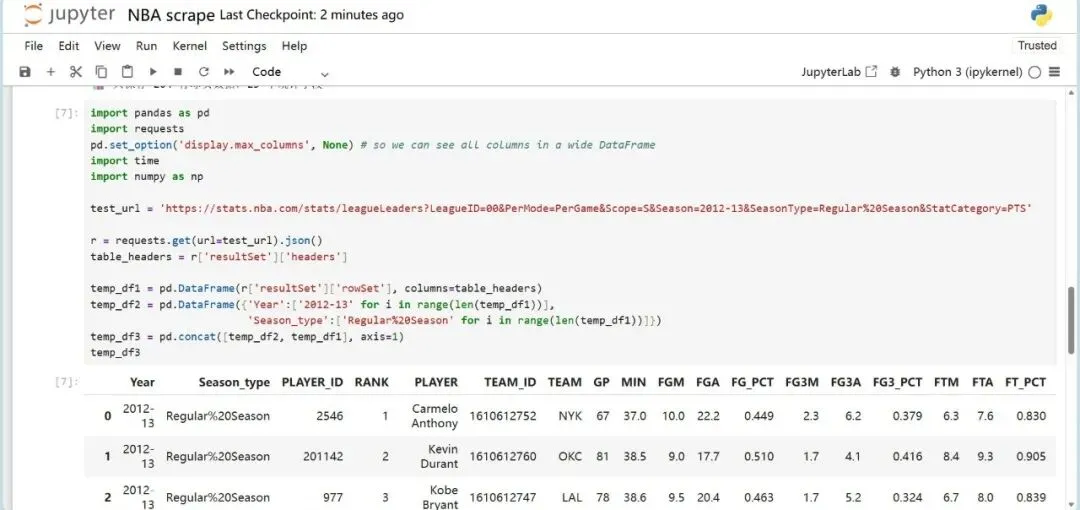
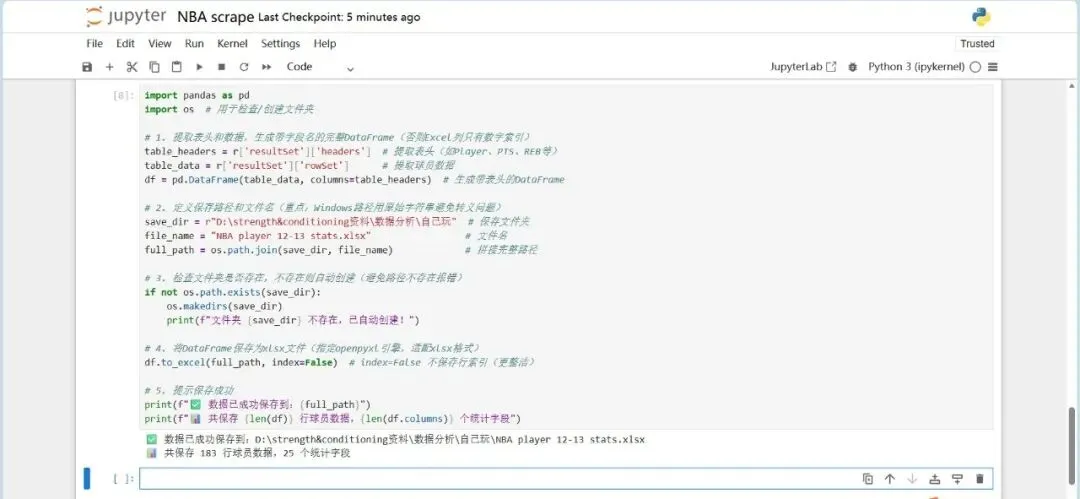
在体育产业数字化深度发展的当下,大数据已成为赛事分析、球员训练优化、商业决策制定的核心支撑,而高质量的体育数据采集则是所有数据分析工作的基础。传统体育数据采集方式存在效率低下、数据格式混乱的问题。相比之下,通过调用官方开放API结合Python编程实现体育大数据集的采集,既能够获取平台方合规开放的结构化数据,保证数据的准确性与权威性,又能依托Python简洁的语法、丰富的请求处理库和数据处理工具,以极低的开发成本实现海量数据的自动化、批量化采集,大幅提升数据采集的效率与稳定性,同时完美适配体育数据“维度丰富、体量庞大”的特性。本文将以NBA官方网站中的大数据为参考,为调取网站API结合Python代码实现体育领域大数据集采集提供一个案例。首先,进行采集与分析前的核心环境搭建:通过导入requests实现与体育网站API的通信以获取原始数据,借助pandas将数据转化为结构化表格并设置显示选项以完整呈现多维度统计信息,同时引入time控制请求节奏保障采集合规稳定,搭配numpy辅助数值计算,为后续批量、高效地构建体育大数据集奠定基础。接下来,进入NBA官方网站,这里我选取网站中“PLAYER STATS”页面中的数据,作为提取目标。从这一步开始,我们需要借助某种消防工具,否则后续会面临请求失败的尴尬问题。(该数据库中共包含262行*23列数据,可见如果使用传统的数据采集方法,将会是多么大的工作量)接下来,我对该页面进行检查(inspect),点击“网络”选项,筛选出“Fetch/XHR”,刷新网页,获取网页上实时加载的各类数据接口。通过对各个数据进行“预览”,找到所需要的数据接口。发现所需要的数据库在league开头的这一数据接口中。这时候点击“标头”,获得我们需要的该数据库请求URL:https://stats.nba.com/stats/leagueLeadersLeagueID=00&PerMode=PerGame&Scope=S&Season=202526&SeasonType=Regular%20Season&StatCategory=PTS也可以选择双击league开头的这一数据接口,跳出的界面正是我们想要的数据,只不过现在数据为json格式,并不是我们需要的表格形式。该页面上方的网址同为我们需要的请求URL。接下来,回到代码,此时需定义NBA官方统计API的请求URL。
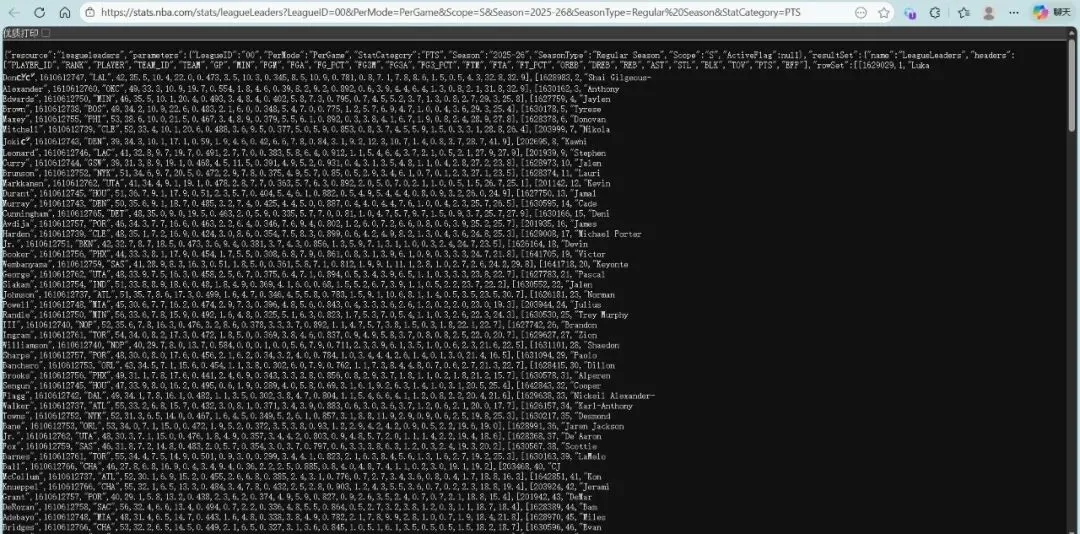
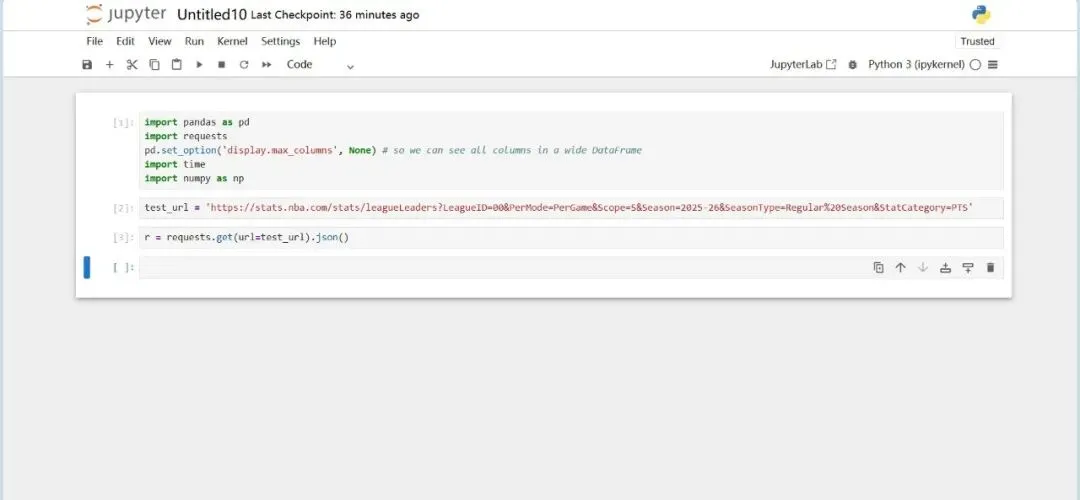
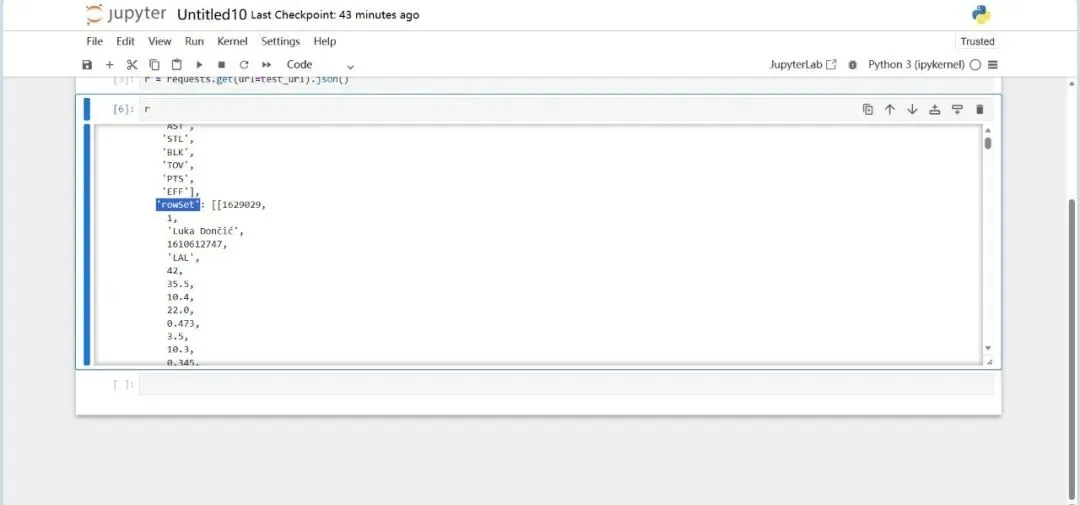
向test_url发送GET请求,获取响应数据,并将响应的JSON格式数据解析为Python字典/列表,赋值给变量r。
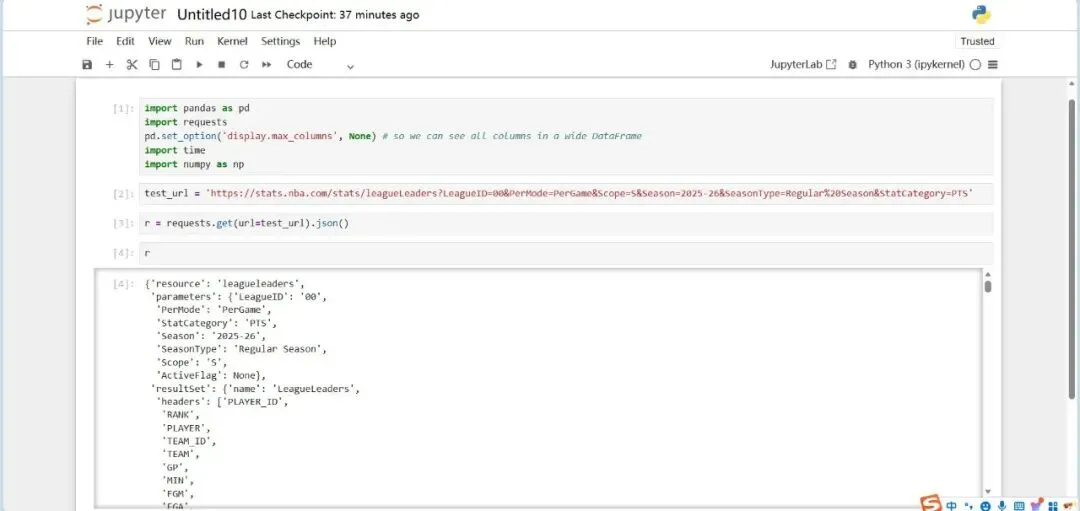
输出r,测试一下。找到其中我们需要提取的结构。
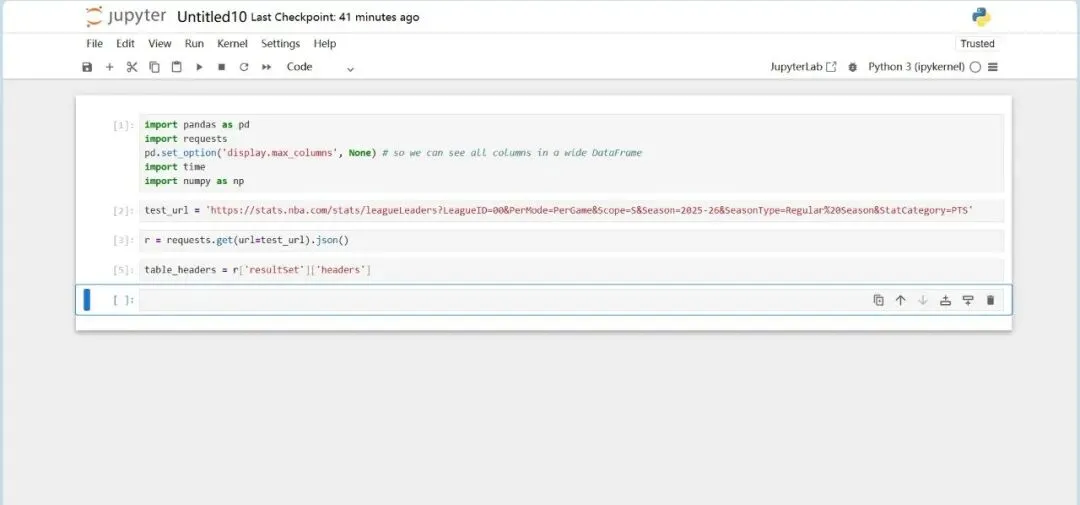
从解析后的JSON数据中,提取结果集(resultSet)里的表头(headers),这些表头对应数据的列名。
找到数据集中的行代码“rowSet”。
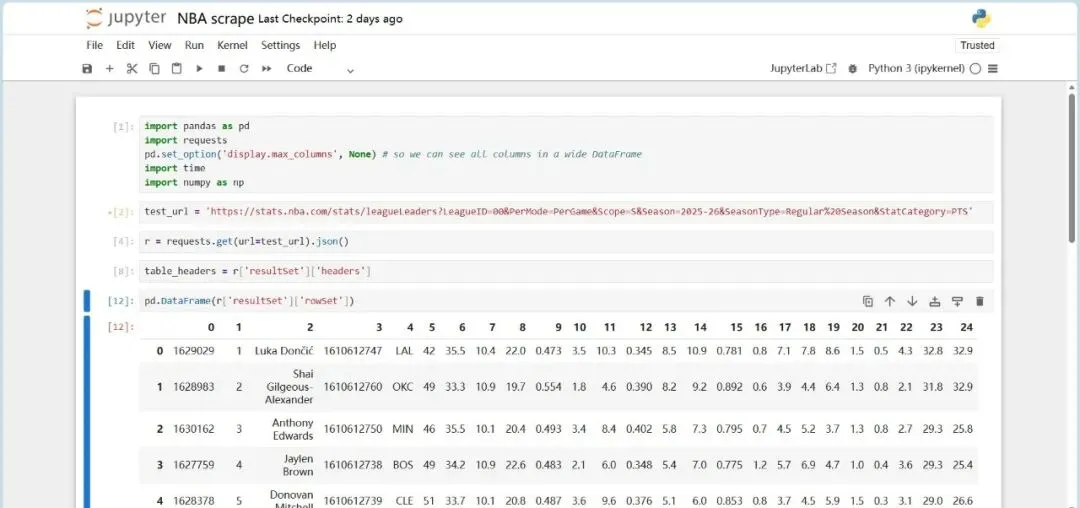
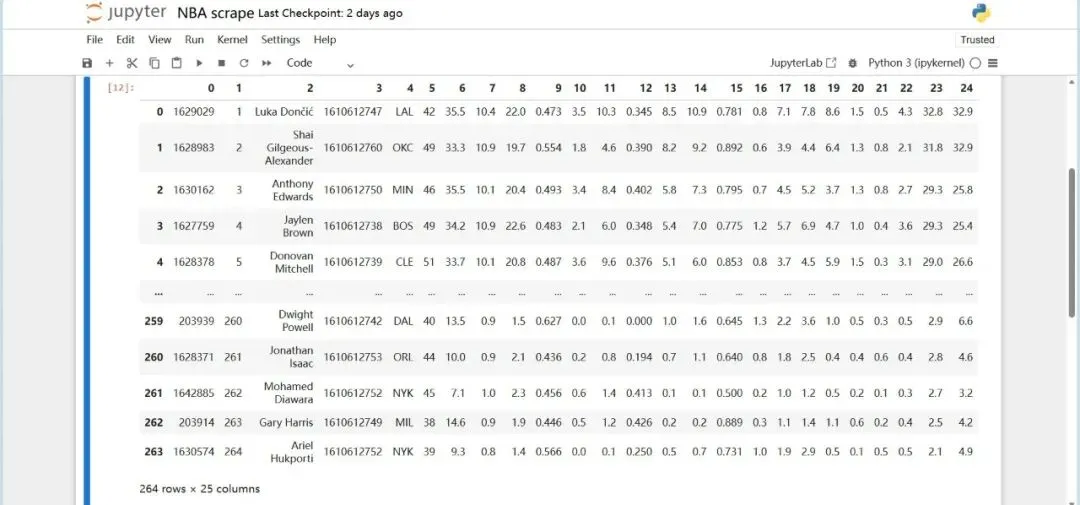
将结果集(resultSet)里的行数据(rowSet)转换为pandas的DataFrame对象,方便后续数据处理、分析和可视化。此时,我们已经得到了我们想要的,规范的表格格式的数据。
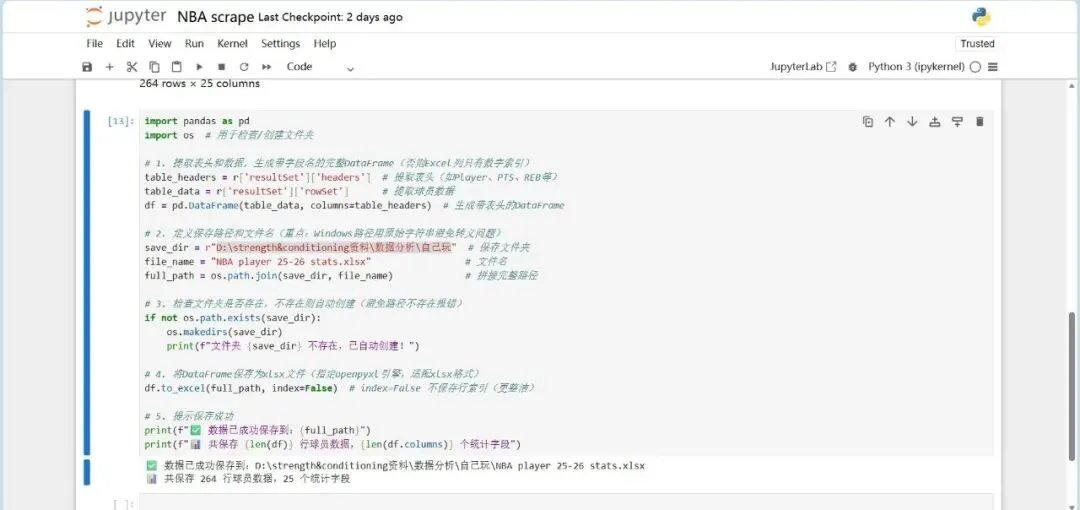
接下来,需要将该数据整理到一份xlsx格式的excel表格中去,将文件命名为“NBA player 25-26 stats”,保存路径为“D:\strength&conditioning资料\数据分析\自己玩”。
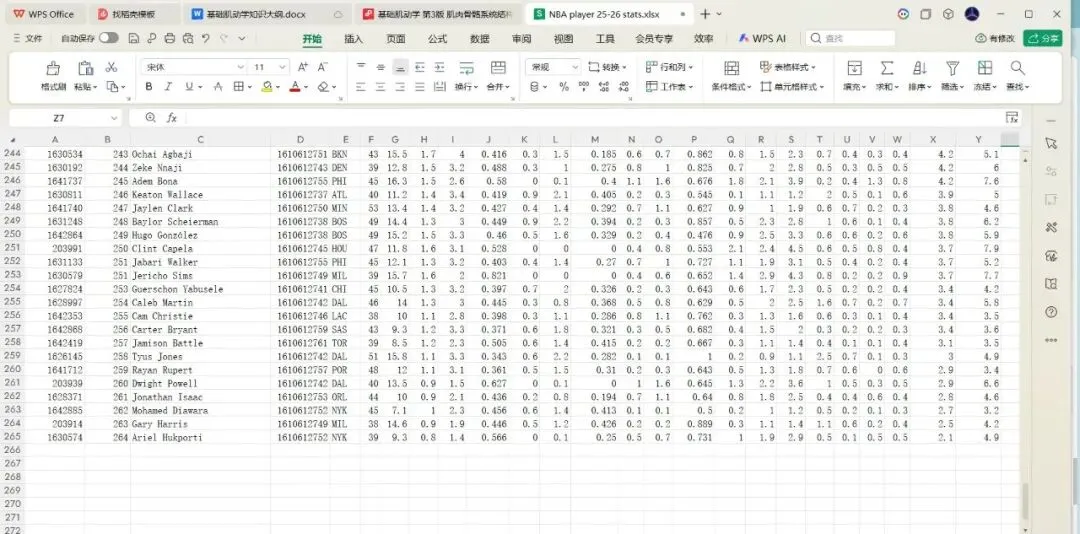
检查一下自己的劳动成果:
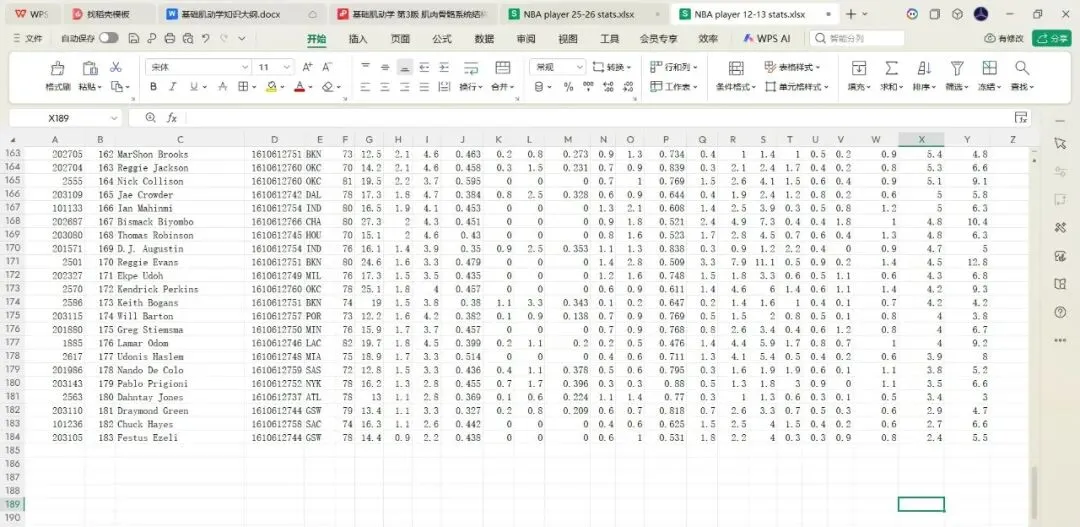
通过不到十分钟的操作,完美的提取到了一个包含6000多个数据的数据集。
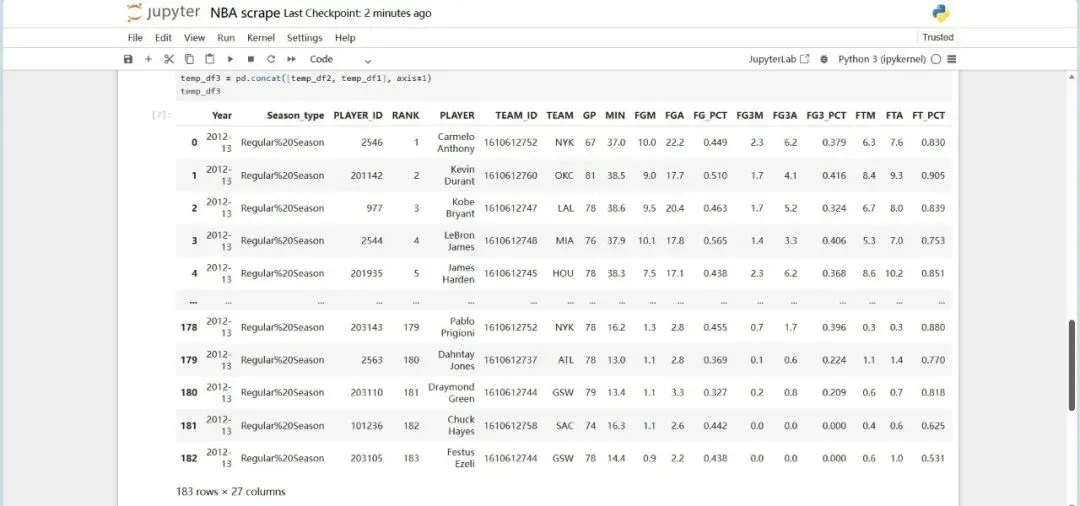
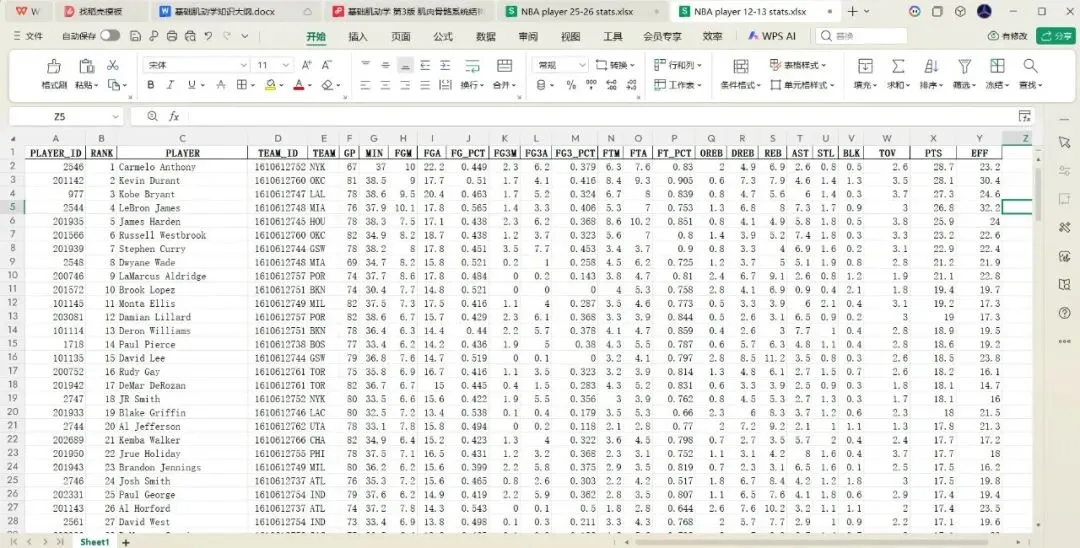
同样的,可以通过调整请求URL中各项的参数(如哪个赛季,常规赛还是季后赛/季前赛),持续获得我们需要的数据。这里,我选择获取2012-13赛季常规赛的球员数据。
同样的,导出excel表格:
It works too.
数据的采集就是如此的高效且有趣,希望这篇文章能让大家的这个年过的开开心心~
END