基于Python的数字音频处理:音频压缩方法(二)参数编码
- 2026-07-03 20:54:21
基于Python的数字音频处理:音频压缩方法(二)参数编码这里我们介绍最基本的线性预测编码(LCP)。其从信号处理的角度,把短时语音建模为一个自回归过程:在一个足够短的时间窗内,音频可以被近似为平稳信号,当前样本可以表示为若干个过去样本的线性组合加上一项预测误差: 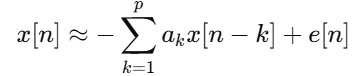
从系统函数的角度看,相当于假设信号是一个全极点型IIR滤波器的输出。在语音分析–合成框架中,LPC 的角色可以概括为: 我们实验的音频依然是从学习通资料里get的元音/a/和元音/e/的发音。 我们对两段元音语音分别进行预处理和12阶LPC分析后,得到前几个共振峰频率,并生成了对应的频谱和谱包络图。实验结果如下:元音 /a/:前三个共振峰频率约为F1 ≈ 793.8 Hz,F2 ≈ 1289.2 Hz,F3 ≈ 1587.8 Hz;元音 /e/:前三个共振峰频率约为F1 ≈ 365.1 Hz,F2 ≈ 1556.6 Hz,F3 ≈ 2549.4 Hz。三个共振峰分别与开口度、舌位和高频分布有关,不多赘述。 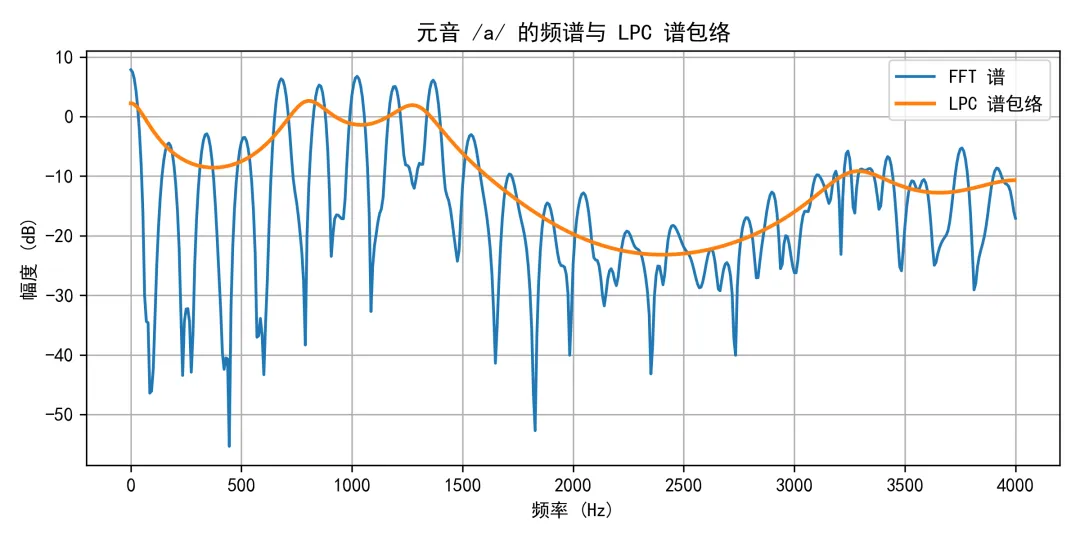
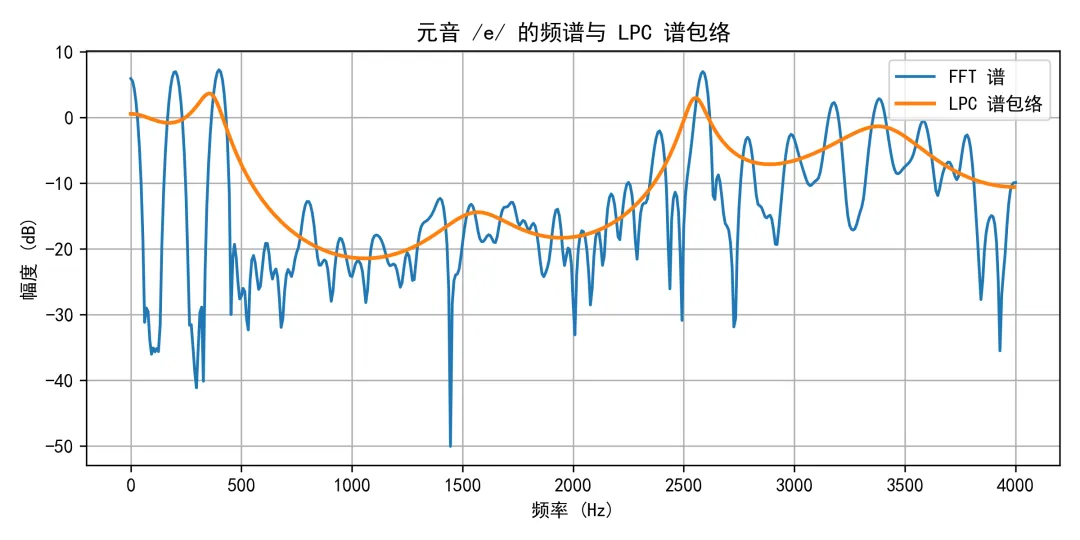
在参数合成部分,我们使用这些 LPC 参数和一个固定基频的脉冲串激励,分别合成了约 0.5 s 的 /a/ 和 /e/ 语音。大家可以用播放器听一听,感受参数编码下合成语音的音色和可懂度。我个人听感效果可以。 当然,实验中我们假设每一帧语音是平稳的,仅使用全极点滤波器近似声道,激励信号也被简化为固定基频的理想脉冲串,是非常非常简化的模型。实际往往在此基础上引入更复杂的声源模型、更精细的谱建模,甚至直接用深度神经网络学习从参数到波形的映射。但无论模型多么复杂,其核心思路依然是本文所展示的这种基本框架。
在音频压缩的发展历程中,最直接的做法是对语音波形本身进行采样、量化和压缩,也就是所谓的波形编码。这类方法从“信号长什么样”出发,基于Python的数字音频处理:音频压缩方法(一)波形编码对每一个采样点进行处理,设计相对简单,但为了保持较好的音质,往往需要较高的比特率。如果我们能直接对这个发声过程进行建模,用少量具有物理意义的参数来描述语音,而不是逐点传输波形,就有可能在较低比特率下保持可懂、可辨认的语音质量。这类方法被统称为参数编码。
从生理结构上看,人说话可以粗略分为两个部分:声源和声道。如果把声源看成系统的输入,把声道看成一个具有若干共振峰的滤波器,那么语音生成过程就可以被看作一个典型的“源–滤波”系统,一旦相关参数被估计和编码,我们就可以在接收端用相同的源–滤波模型进行合成,从而重建出具有可懂度的语音。
分析端:对每一帧语音信号进行自相关分析和递推,估计出 LPC 系数和增益,同时根据残差信号的周期性来估计基频,并判断该帧是有声音素还是无声音素;
合成端:构造相应的激励信号(例如有声音素用脉冲串、无声音素用噪声),再通过由 LPC 系数定义的全极点滤波器进行滤波,从而合成出近似原始的语音。
这样,每一帧语音只需传输一小组系数和几个激励参数,就能在另一端重建出具有可懂度的语音波形,实现了参数编码的高压缩率优势。
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 现在做RNA-seq分析,还要掌握Linux和R吗?
- Python写三行,C写三十行:我们为何还要学"底层语言"?
- 国产 Linux 新颜值!灵墨 LingmoOS:Mac 风格界面太惊艳
- 拆解Linux共享内存原理:“零拷贝”通信的核心机制
- 2026年,你眼中的最佳Linux桌面发行版优选清单!
- 一千多个Python日常开发常用第三方库清单教程和代码示例
- Python requests模块详细介绍
- 2025年GESP 09月认证-->Python二级真题解析(编程题1-优美的数字)
- Linux 基础:Debian 介绍
- Python高效编程:一篇文章彻底搞懂map()函数
