基于Python的数字音频处理:音频压缩方法(三)混合编码
- 2026-06-27 05:33:08
基于Python的数字音频处理:音频压缩方法(三)混合编码在前一部分实验中,我们利用线性预测编码(LPC)实现了语音的参数化表示,并通过“脉冲+全极点滤波器”的方式合成了元音信号。实验表明,仅使用少量 LPC 系数和简单的声源模型,就可以重建语音的主要谱形结构。在传统 LPC 合成中,有声音素用规则脉冲串作为激励,无声音素用白噪声作为激励。很自然就可以想到,如果在保持 LPC 声道建模优点的同时,能够更精细地描述激励结构(波形编码的思想基于Python的数字音频处理:音频压缩方法(一)波形编码),就能显著提高语音质量。这类方法被称为 混合编码(Hybrid Coding),其中一种代表性技术是多脉冲线性预测编码(Multi-Pulse Linear Predictive Coding,MPLPC),其在早期蜂窝通信中应用较广,因为它在比特率与语音质量之间取得了较好平衡。
我们对音频进行 LPC 分析(与前一实验相同),得到残差信号,再在每帧内选取若干个幅度最大的残差样本作为“多脉冲”,用这些脉冲构造新的激励信号,再通过 LPC 滤波器合成语音与规则脉冲合成进行对比。其中合成的元音波形如下: 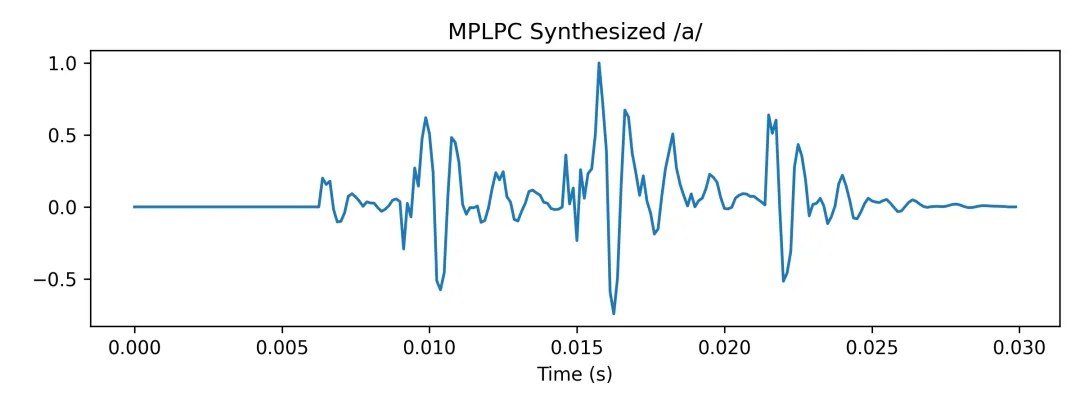
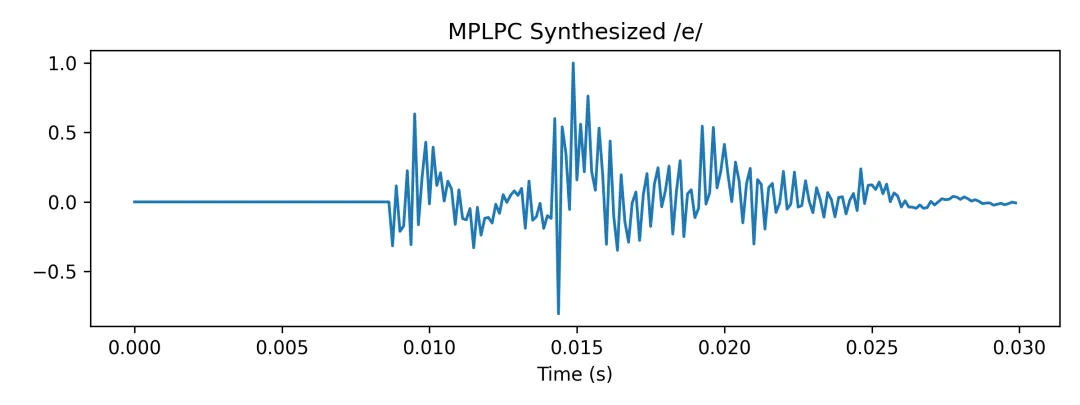
效果显著变好!
合成的语音和原语音也放出,大家可以播放听一听。
我个人听感是MPLPC的效果不如LPC,其对于共振的处理太强了,理论上因为元音是周期主导的信号,所以规则周期激励更合理。如果是整段语句多个音节的话MPLPC会效果更好。那么有没有可能改进目前的实验让MPLCP的结果好于LCP呢?
有的。在保持 LPC 声道模型不变的前提下,对激励信号进行更精细的建模。通过匹配追踪(Matching Pursuit)方式逐步选取能够最小化合成误差的脉冲位置和幅度,使合成语音在波形结构上更接近原始信号。即一次次迭代更新误差,重复 M 次,我们这里取M=40的结果如下:
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

