如何让 R+Python 报告“自己长出来”?揭秘 Positron+Quarto 自动化报告保姆级教程,一学就会
- 2026-07-02 11:14:26
01 为什么你该立刻学会这套工作流?
如果你还在用 Jupyter 写分析、再用 Word 贴图写报告,或者 R 和 Python 各开一个窗口来回倒数据——这篇文章会直接帮你省下至少一半的重复劳动。
我们接下来要用的组合是:Positron(原 RStudio 新一代 IDE)+ Quarto 文档 + R 与 Python 混编。
效果是:一个 .qmd 文件里,R 负责数据与出图,Python 负责特征与建模,点一次「渲染」就得到可分享的 HTML 报告。 不用再复制粘贴、不用再手动更新图表,真正实现「写一次,到处用」。
本文会分步骤、带代码、带避坑地讲清楚从环境到出图的完整流程,保证你看完就能在自己的电脑上跑通,并用到日常的数据分析或自动化报告中。
先看三个真实场景,有没有你的影子:
小 A:每周五下午从数据库拉数、在 Python 里算指标、再贴到 Excel 做表、最后复制到 PPT,一次要搞两小时,改一个数整份报告都要动。 小 B:用 R 做统计和画图很顺手,但模型和特征工程在 Python 里写的,每次都要导出 CSV 再在 R 里读,路径和编码问题不断。 小 C:想写一份「可复现」的分析报告给同事或面试官看,但代码散在 Jupyter、R 脚本和 Word 里,别人根本跑不通。
如果你中了任意一条,下面这套 Positron + Quarto + R/Python 混编 的流程,就是为你准备的。跟着做一遍,以后周报、分析报告、教程都能在一个文件里搞定,点赞、转发、收藏一次,需要时随时翻出来用。
02 基础知识:Positron、Quarto、R+Python 分别解决什么?
1. Positron:为什么选它写 Quarto?
Positron 是 Posit(原 RStudio)推出的新一代 IDE,对 Quarto、R、Python 的支持是「原生级」的:
内置 Quarto 渲染与预览 同时识别 R 与 Python 代码块并高亮、补全 与 Conda/venv 集成,方便切换环境 非常强大的AI助理(我们成立R语言AI编程的初衷,欢迎大家入群)
2. Quarto:一个文件多种输出
Quarto 是新一代「技术文档 + 报告」的格式与引擎:
一个 .qmd文件里可以写 Markdown + 多语言代码块(R、Python、Julia 等)渲染时自动执行代码、把结果(表格、图、文字)嵌进文档 可输出 HTML、PDF、Word、PPT 等,适合做周报、分析报告、教程
和 R Markdown 相比,Quarto 更通用(不绑死在 R 生态),和 Jupyter 相比,它又天生适合「报告式」排版和多语言混编。
3. R + Python 混编:各司其职
R:数据整理(tidyverse)、统计、出图(ggplot2)非常顺手。 Python:特征工程、机器学习、复杂逻辑更常见。
在 Quarto 里用 reticulate 包,可以让 R 调用指定的 Python(如 Anaconda 某环境),在同一个文档里:
用 R 生成或读入数据 把数据传给 Python 做计算 再把结果传回 R 做表格与可视化
这样你就不用在两个软件之间导 CSV、改路径,全部在一个 .qmd 里完成,且可重复执行、可版本管理。
03 环境准备:少走弯路的 3 步
第 1 步:安装 Anaconda 与 R
Anaconda:从官网安装,并创建一个专用于「数据分析」的环境(如 aicm、data_sci)。创建后在该环境中安装:pip install pandas numpy,必要时可加scikit-learn等。建议环境名用英文、不要有空格,避免路径问题。R:从 CRAN 安装最新版 R(建议 4.2 及以上,我们R语言博士团队目前是采用R4.4.1)。在 R 控制台依次执行: install.packages("reticulate")、install.packages("tidyverse")、install.packages("knitr");若你打算用 R 来触发 Quarto 渲染,可再装install.packages("quarto")。
自检:在 R 里运行 reticulate::conda_list(),应能看到你的 Conda 环境列表;再在对应环境中确认有 Python 和 pandas,这样后面 use_condaenv() 才能生效。
第 2 步:安装 Positron 与 Quarto CLI
Positron:从 Posit 官网(posit.co)下载对应系统的 Positron 安装包,安装后首次打开可选择 R 和 Python 的解释器路径;若本机已装 R 和 Anaconda,一般会自动识别。 Quarto:从 Quarto 官网(quarto.org)下载并安装 Quarto CLI。安装完成后,在终端或 CMD 执行 quarto check,会列出已检测到的 R、Python、LaTeX 等,便于查缺补漏。
在 Positron 里新建或打开一个 .qmd 文件,右上角或菜单中应出现「Render」或「预览」;点一次即可从当前文档渲染出 HTML(或你在 YAML 里配置的其他格式)。
第 3 步:在 Quarto 里锁定 Python 环境(关键)
打开Positron,创建一个文件夹,然后在这个文件夹下面创建一个qmd文件,例如:test.qmd。如下图所示:
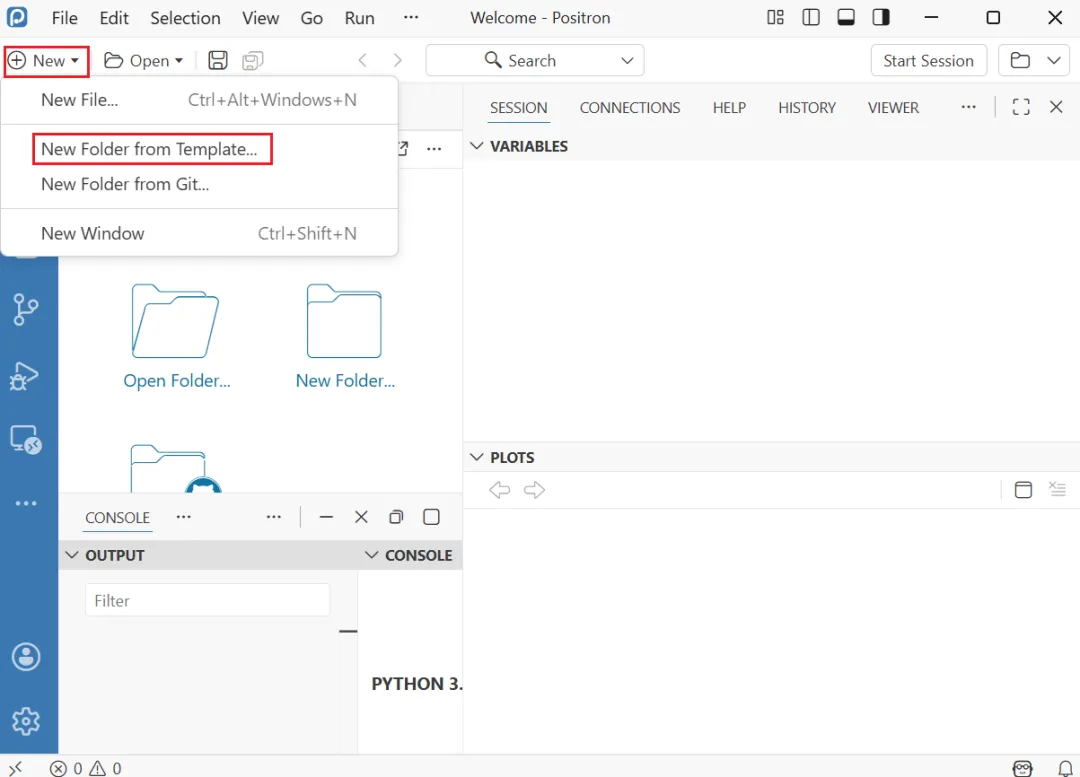
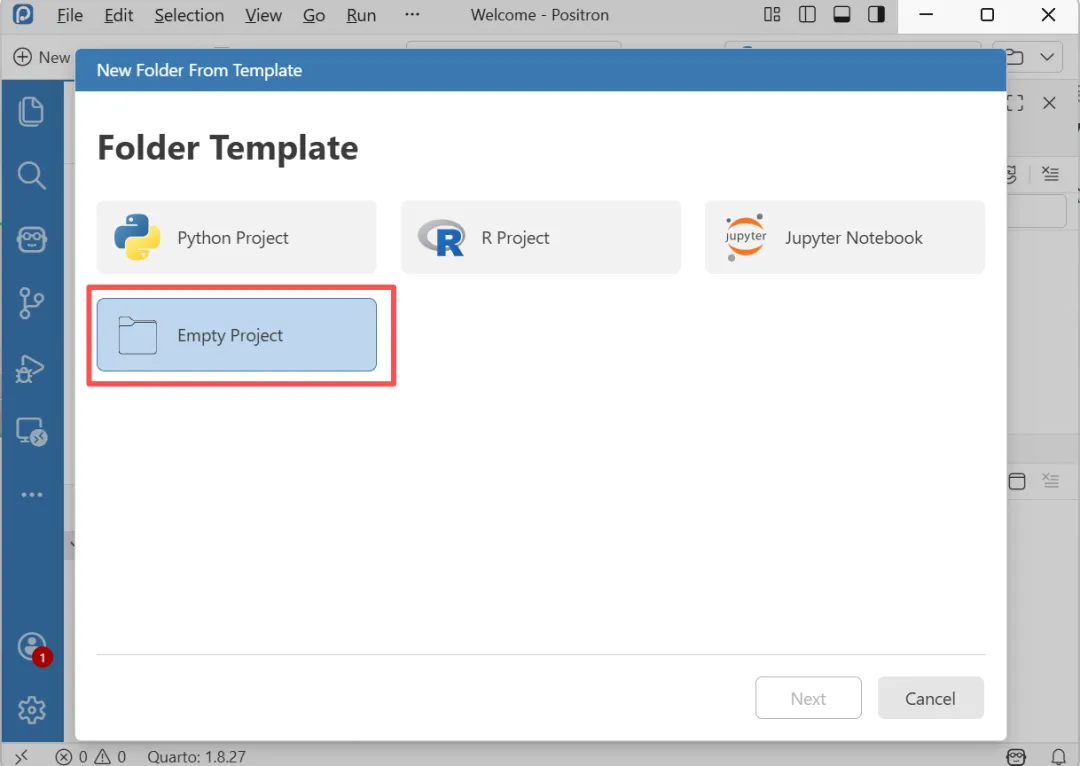
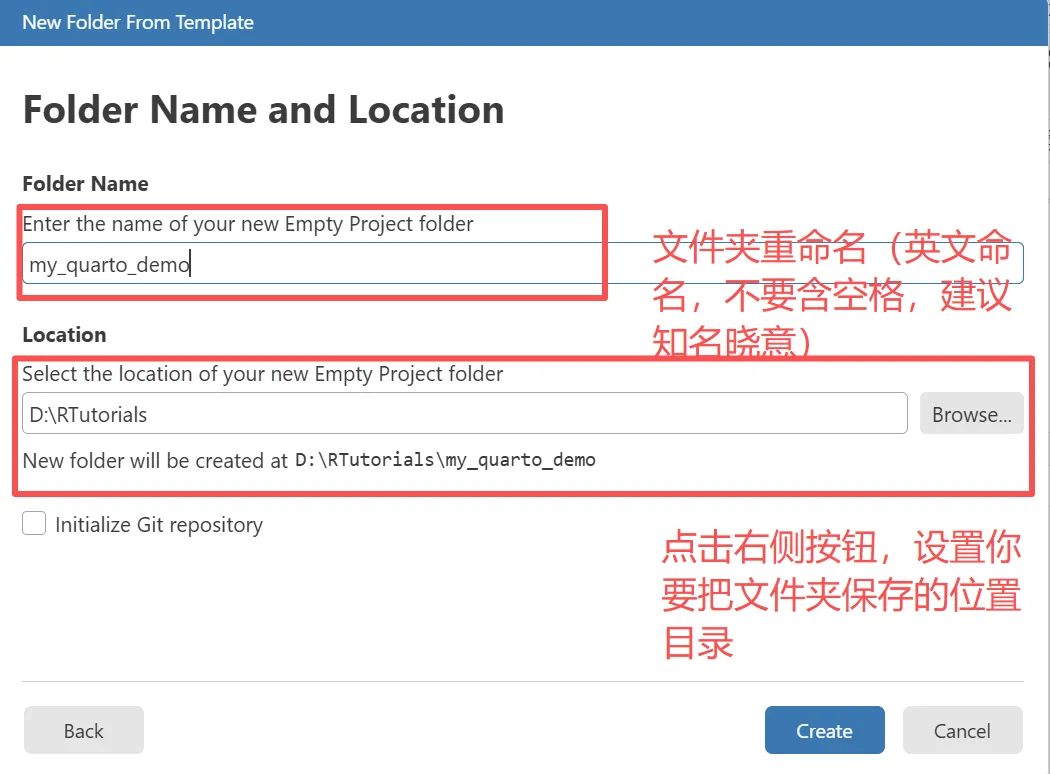
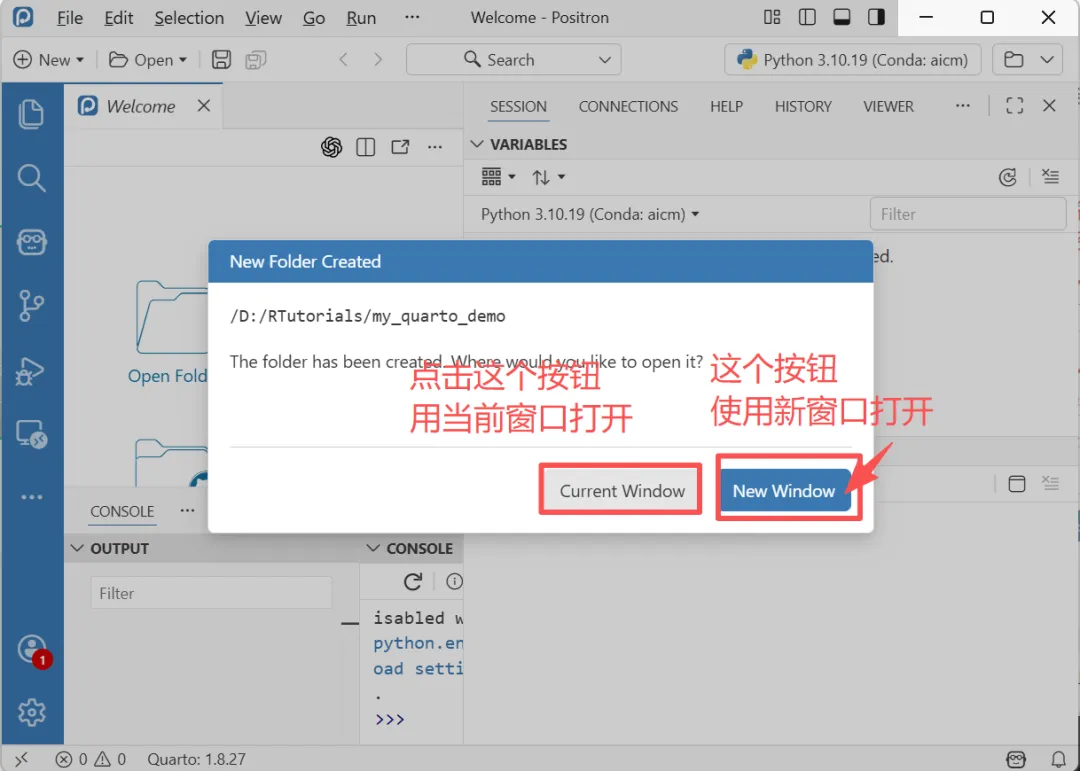
在 .qmd 里,第一个代码块必须是 R 的 setup,用来加载 reticulate 并锁定你要用的 Conda 环境,避免后面 Python 块用了「错的」解释器。
# 在 R 块中library(reticulate)library(tidyverse)library(knitr)# 改成你自己的环境名,例如 base 或 data_sciuse_condaenv("D:/ProgramData/Anaconda3/envs/aicm", required = TRUE)# 验证是否进入该环境py_config()渲染后查看输出里的 py_config():确认 python 路径指向你的 Conda 环境,这样后续 Python 块才会用同一环境。
04 完整流程:从数据到图表,一个 .qmd 搞定
下面按「环境初始化 → 数据准备(R) → 特征与逻辑(Python) → 可视化(R)」走一遍,你可以直接复制到自己的 .qmd 里试。
步骤 1:YAML 头与 HTML 输出
在 .qmd 文件最开头写:
---title:"Quarto 混合语言数据科学工作流"subtitle:"使用 R (reticulate) 调用 Anaconda 与 Python 协同"author:"R语言博士团队"date:"2026-02-21"format:html:theme:cosmotoc:truecode-copy:trueself-contained:true---toc: true自动生成目录;code-copy: true方便读者复制代码;self-contained: true生成单文件 HTML,便于分享。
步骤 2:环境初始化(第一个 R 块,必做)
library(reticulate)library(tidyverse)library(knitr)use_condaenv("D:/ProgramData/Anaconda3/envs/aicm", required = TRUE)py_config()把 "D:/ProgramData/Anaconda3/envs/aicm" 换成你本机的环境名或路径。若希望用系统 Python,可改用 use_python("/path/to/python", required = TRUE)。
步骤 3:数据准备(R)
用 R 的 tidyverse 生成或读入原始数据,并做简单计算:
set.seed(42)raw_data <- data.frame( month = seq(as.Date("2025-01-01"), by = "month", length.out = 12), sales_volume = c(120, 145, 130, 170, 210, 205, 240, 280, 260, 300, 320, 350), unit_price = runif(12, 15, 25))raw_data <- raw_data %>% mutate(revenue = sales_volume * unit_price)kable(head(raw_data), caption = "R 生成的原始数据预览")这里 raw_data 会在后续被 Python 直接使用,无需写文件。
步骤 4:特征工程与逻辑(Python)
在 Quarto 里,R 中的对象可以通过 r.xxx 在 Python 里访问。注意:从 R 传过来的日期列,在 Python 里要先转成 datetime,再使用 .dt 访问器,否则容易报错。
import pandas as pdimport numpy as npdf = r.raw_data.copy()df['month'] = pd.to_datetime(df['month'])df['month_str'] = df['month'].dt.strftime('%Y-%m-%d')df['revenue_growth'] = df['revenue'].pct_change() * 100df['performance'] = np.where(df['revenue_growth'] > 5, 'High Growth', np.where(df['revenue_growth'] > 0, 'Stable', 'Decline'))df['revenue_growth'] = df['revenue_growth'].fillna(0)df['revenue'] = df['revenue'].astype(float)计算完后,Python 里的 df 会在 R 里以 py$df 的形式存在,可直接用于下一步。
步骤 5:回到 R 做可视化
用 py$df 取回数据,做必要的类型转换(尤其是日期和因子),再用 ggplot2 出图:
library(lubridate)processed_data <- py$df %>% mutate( month = as.Date(as.character(month_str)), revenue = as.numeric(as.character(revenue)), performance = factor(as.character(performance), levels = c("High Growth", "Stable", "Decline")) )# 防御性检查:避免日期全是 NAif (all(is.na(processed_data$month))) {stop("错误:month 列转换后全是 NA!请检查 Python 传回的格式。")}ggplot(processed_data, aes(x = month, y = revenue)) + geom_area(fill = "steelblue", alpha = 0.2) + geom_line(color = "steelblue", linewidth = 1) + geom_point(aes(color = performance), size = 3) + scale_x_date(date_labels = "%Y-%m") + scale_color_manual(values = c("High Growth" = "#27ae60","Stable" = "#f1c40f","Decline" = "#e74c3c")) + theme_minimal() + labs(title = "R & Python 协同分析", x = "时间", y = "营收")到这一步,点击 Positron 的 Render,就能得到一份包含「数据表 + 增长率逻辑 + 图表」的完整 HTML 报告。
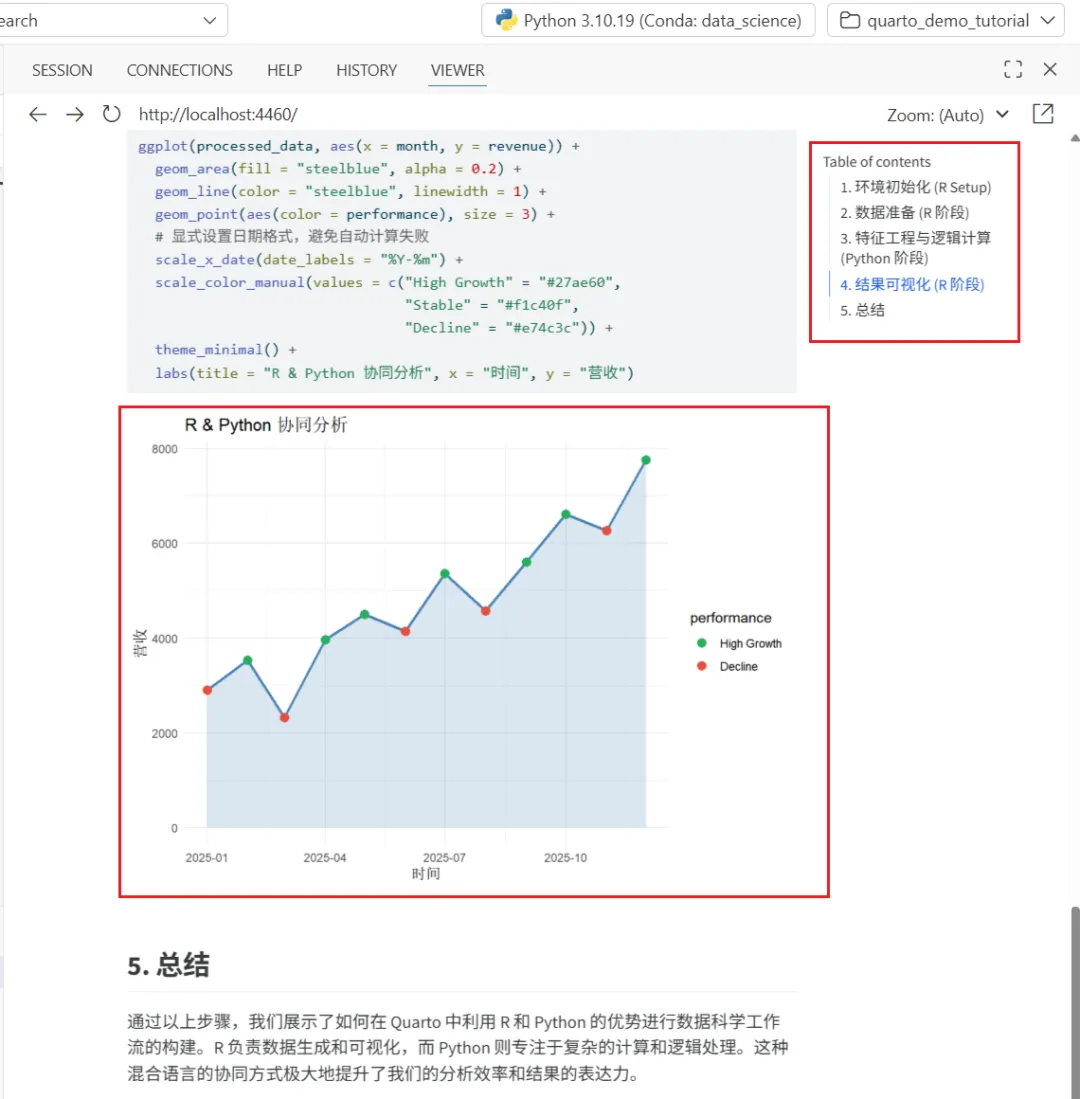
05 常见坑与排查(省下你半天排错时间)
Python 块报错「没有 pandas」
说明当前用的不是你在 setup 里指定的 Conda 环境。请确认 use_condaenv(...)的环境名与conda_list()里一致,且该环境中已安装 pandas、numpy。R 里
py$df的日期变成 NAR 与 Python 之间传日期时,建议在 Python 里先转成字符串(如 month_str),再在 R 里用as.Date(as.character(...))转回日期,并做一次if (all(is.na(...)))的检查,便于快速定位问题。渲染很慢或卡住
先单独在 R 里跑一遍 setup 块和主要 R 块,再在 Python 里跑对应块,确认无报错后再整体渲染;有时是某一步报错导致后续未执行。 想用 PDF 输出
需安装 LaTeX(如 TinyTeX)。在 YAML 里增加 format: pdf:或format: pdf: default,并保证图中中文等字体配置正确(可先以 HTML 为主验证逻辑)。
5 分钟自检清单(渲染前过一遍):
[ ] 第一个代码块是 R 的 setup,且已执行 use_condaenv(...)和py_config()。[ ] py_config()里的 python 路径属于你要用的 Conda 环境。[ ] R 里存在 raw_data(或你命名的数据对象),再运行 Python 块。[ ] Python 里用 r.raw_data取数后,日期列已用pd.to_datetime转好,再使用.dt。[ ] R 里用 py$df取回数据后,用as.character()/as.Date()等做了类型转换,并做了简单的 NA 检查。
按这份清单排查,大部分「第一次跑不通」的问题都能快速定位。
06 如何用到「周报/月报、分析报告、教程/笔记」里?
周报/月报:把数据源改成你的数据库或 CSV,保留「R 取数 → Python 特征/指标 → R 出图」结构,每周只改数据路径或日期参数,重新渲染即可。甚至可以配合 Windows 任务计划程序或 cron,定时跑 R 脚本渲染指定 .qmd,实现「周一早上自动生成上周周报」。 分析报告:在 .qmd 里用 ##、###分节,每节对应一个分析问题(例如:描述统计、趋势、分组对比),代码块按顺序执行,报告自然成章;客户或领导要 PDF 就渲染 PDF,要网页就发 HTML,同一份源文件多格式输出。教程/笔记:把「步骤 1~5」做成模板,学员或同事拿到后只需改环境名和数据,即可复现。
07 小结与下一步
使用 Positron + Quarto,在一个 .qmd 里混编 R 与 Python,可实现从数据到图表的一键渲染,适合做自动化报告与教程。 关键三步:环境准备(Anaconda + R + reticulate)→ 第一个 R 块锁定 Conda 环境 → R 数据 → Python 计算 → R 出图。 注意 R 与 Python 之间日期与类型的传递(建议日期在 Python 转字符串,在 R 再转回日期),并做好防御性检查。
建议你立刻行动,在电脑上新建一个 .qmd,把本文的步骤 1~5 贴进去,把环境名改成自己的,点一次 Render。跑通一次后,再把自己的数据源和业务指标换进去,就能形成你自己的「自动化报告流水线」。
互动时刻
您想用qmd文件做什么有价值的事情,欢迎留言告知我们。
📌 资源领取(必看)
公众号后台回复消息 「Quarto教程」:获取完整 Quarto 项目模板、R+Python 环境配置清单、配套笔记。 加入R语言AI编程群,获取和学习我们更多干货笔记和避坑指南。
如果这篇对你有帮助,欢迎点赞、在看、转发到朋友圈或数据/技术群,让更多同事和朋友用上 Positron + Quarto 的 R+Python 自动化报告工作流。
我是R语言AI编程王博士,专注AI赋能R语言编程和Positron新一代数据科学IDE实战。
我们下期文章再见。


