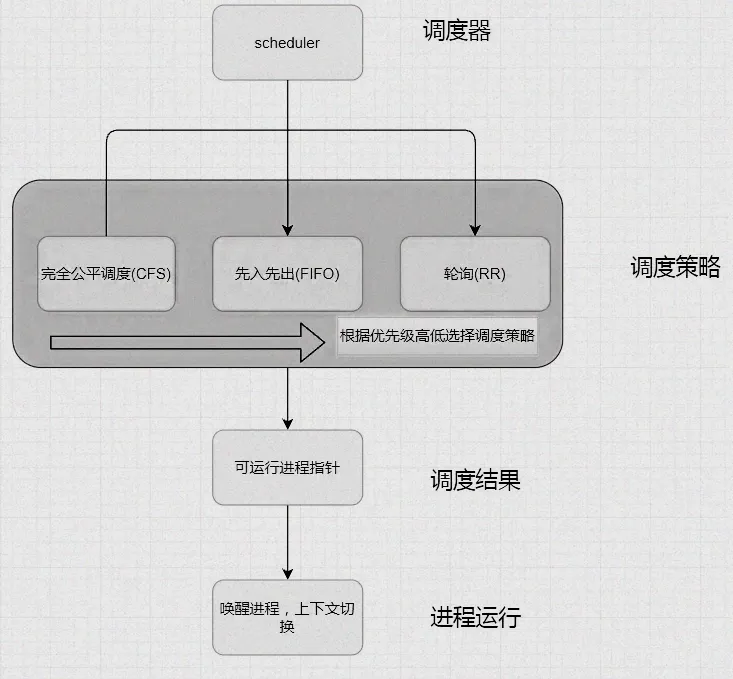
但大家有没有想过,哪怕是多核CPU,同一时刻单个逻辑处理器(即操作系统调度的基本单位)只能专注执行一个线程——这是硬件层面的硬限制,而让多任务“看起来并行”的关键,就是内核的调度机制。
调度机制就像是CPU资源的“专属分配官”,核心工作就是定规则:谁先占用CPU、占用多久、什么时候切换。它的设计直接决定了系统够不够快、能处理多少任务、稳不稳定——比如服务器卡顿、应用响应慢,很多时候不是硬件不行,而是调度策略没适配好。
一、Linux 内核调度的核心原理
1.1 调度的本质
先给大家科普一个关键点:Linux调度的核心,就是解决“CPU不够用”的竞争问题——既要让CPU尽量不空闲(提升利用率),又要让每个进程都有机会运行(避免某些进程被饿死)。
要是没有调度机制,后果会很离谱:比如你运行一个大型计算任务,它会一直霸占CPU,其他程序比如微信、浏览器全卡死,只能等它跑完才能操作——这就是单进程独占CPU的灾难场景,日常用Linux根本没法忍。
调度机制靠两个核心手段解决这个问题:时间片轮转和优先级抢占。先给大家贴一段简单的代码,看看如何查看系统当前的调度策略和时间片相关配置:
# 查看指定进程的调度策略(以PID=1为例,init进程)chrt -p 1# 查看系统调度器相关参数(CFS调度器的时间片配置)cat /proc/sys/kernel/sched_min_granularity_ns # 最小时间片(纳秒)cat /proc/sys/kernel/sched_latency_ns # 目标延迟(纳秒)
时间片轮转就像“轮流值日”:把CPU时间分成一个个小切片(比如10ms),每个进程轮流占用CPU,时间片用完就切换下一个,宏观上就呈现出“并行”的效果。而优先级抢占更简单:高优先级进程就绪时,直接“插队”,暂停当前低优先级进程,优先占用CPU——比如急诊程序优先级高,能优先获得资源。
1.2 三大调度策略
Linux内核给不同场景的进程,设计了三种调度策略,不是“一刀切”,而是精准匹配需求。
咱们先看代码,如何给进程设置调度策略,再逐个拆解:
# 1. 设置进程为实时SCHED_FIFO策略(优先级99,最高)chrt -f -p 99 [PID]# 2. 设置进程为普通SCHED_NORMAL策略(默认)chrt -o -p 0 [PID]# 3. 设置进程为限期SCHED_DEADLINE策略(截止时间优先)chrt -d -p 1000000 2000000 3000000 [PID]# 解释:-d 后三个参数分别是:周期(ns)、截止时间(ns)、运行时间(ns)
先说说实时调度策略,主要用于对延迟要求极高的场景,比如音视频编码、工业控制——差几毫秒就可能出问题。它分两种:
再看普通调度策略,这是咱们日常用得最多的,比如浏览器、编辑器、后台服务,核心是SCHED_NORMAL和SCHED_BATCH:
比如编译Linux内核时,就可以设置这个策略:
# 编译内核时,设置调度策略为SCHED_BATCH,降低优先级chrt -b -p 0 `pgrep make`
最后是限期调度策略(SCHED_DEADLINE),针对有明确截止时间的任务,比如自动驾驶的传感器数据处理——必须在规定时间内完成,否则可能引发危险。它基于EDF(最早截止时间优先)算法,优先调度截止时间最近的任务,上面的代码已经给出设置方式,适合高实时性场景。
总结一下:不同策略适配不同场景,核心是“按需分配”,这也是Linux调度机制灵活的关键。
二、进程优先级
2.1 优先级层级
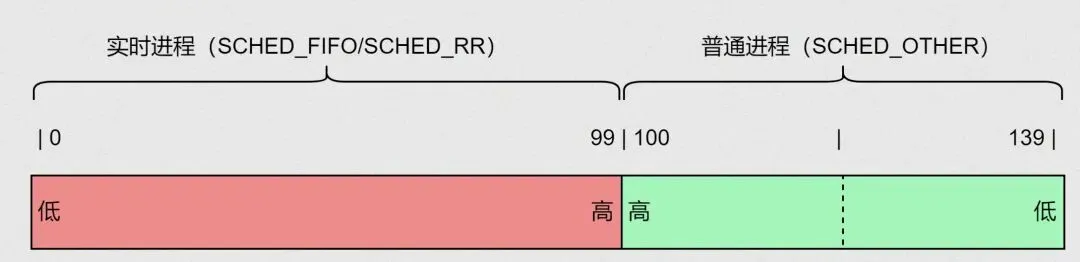
聊完调度策略,再说说“插队权”——进程优先级。Linux给进程分了明确的优先级层级,从高到低依次是:停机调度类进程>限期进程>实时进程>普通进程>空闲进程,层级越高,越容易抢到CPU。
先给大家贴一段代码,查看进程的优先级,直观感受一下:
# 查看进程的静态优先级、实时优先级(以PID=1234为例)ps -o pid,ni,pri,rtprio [PID]# 解释:# ni:nice值(-20~19),普通进程优先级的关键参数# pri:动态优先级,调度器实际使用# rtprio:实时优先级(1~99,非实时进程为0)
限期进程是“最高级打工人”,按截止时间排序,截止时间越近,越先执行——比如自动驾驶的数据处理进程,必须优先跑完。实时进程次之,优先级范围1~99,数值越大优先级越高,比如工业控制的实时任务,通常设置rtprio=90以上。
普通进程是咱们最常接触的,静态优先级范围100~139,和nice值挂钩(静态优先级=120+nice值),nice值越小,优先级越高。比如把浏览器的nice值设为-5,它的静态优先级就是115,比默认nice=0(静态优先级120)的进程更容易抢到CPU。
空闲进程是“兜底的”,优先级最低,只有系统没其他任务时才运行,主要作用是避免CPU空闲浪费资源,用ps命令能看到空闲进程(PID通常为0或14等,不同系统略有差异)。
2.2 优先级参数解析
Linux内核用task_struct结构体描述每个进程,里面藏着4个核心优先级参数,搞懂它们,就能明白调度器是怎么判断“谁先运行”的。
咱们先通过内核源码片段(简化版)看看这几个参数:
# 简化的task_struct优先级相关参数struct task_struct { int prio; // 动态优先级,调度器实际使用 int static_prio; // 静态优先级,由nice值计算(120+nice) int normal_prio; // 推导后的正常优先级(结合静态/实时优先级) int rt_priority; // 实时优先级(1~99,非实时进程为0)};
第一个参数prio(动态优先级),是调度器真正参考的优先级,不是固定的——系统会根据进程的运行状态动态调整。比如一个进程长时间等待(比如等待键盘输入),系统会提高它的动态优先级,让它下次能更快抢到CPU,避免“饿死”。
第二个参数static_prio(静态优先级),是普通进程的“基础优先级”,由nice值计算而来,默认nice=0时,static_prio=120。咱们可以用renice命令修改运行中进程的nice值,间接调整静态优先级:
# 把PID=1234的进程nice值设为-5(提高优先级)renice -n -5 -p 1234# 把PID=5678的进程nice值设为10(降低优先级)renice -n 10 -p 5678
第三个参数normal_prio(正常优先级),是调度器推导出来的中间优先级:实时进程的normal_prio由rt_priority决定,普通进程的normal_prio和static_prio一致,主要用于调度器快速判断优先级高低。
第四个参数rt_priority(实时优先级),是实时进程的专属参数,非实时进程为0。实时进程的优先级完全由rt_priority决定,数值越大,优先级越高——比如用chrt命令设置rt_priority=99,就是最高优先级的实时进程。
三、核心组件
3.1 调度类(sched_class)
Linux调度机制的灵活性,全靠调度类(sched_class)——它是模块化设计,不同调度类对应不同调度策略,按优先级排序,调度器会从高优先级调度类里挑选进程执行。
Linux内核有5种调度类,优先级从高到低依次是:停机调度类>限期调度类>实时调度类>公平调度类>空闲调度类。咱们先看一段内核源码片段,了解调度类的结构(简化版):
# 简化的调度类结构体struct sched_class { // 挑选下一个要执行的进程 struct task_struct *(*pick_next_task)(struct rq *rq); // 放入就绪队列 void (*enqueue_task)(struct rq *rq, struct task_struct *p, int flags); // 移出就绪队列 void (*dequeue_task)(struct rq *rq, struct task_struct *p, int flags); // 调度类优先级(从高到低)} stop_sched_class, dl_sched_class, rt_sched_class, fair_sched_class, idle_sched_class;
停机调度类(stop_sched_class)是最高优先级的,平时用不到,主要用于进程迁移——比如把进程从一个CPU迁移到另一个CPU,确保迁移任务能立即执行,不被其他进程打断。
限期调度类(dl_sched_class)对应SCHED_DEADLINE策略,用红黑树管理进程,按截止时间排序,每次挑选截止时间最近的进程执行。适合有严格时间要求的任务,比如航空航天的实时控制。
实时调度类(rt_sched_class)对应SCHED_FIFO和SCHED_RR策略,给每个优先级维护一个队列,用位图快速找到最高优先级的非空队列——位图查询效率高,能确保实时进程快速被调度。
公平调度类(fair_sched_class)是普通进程的默认调度类,基于CFS完全公平调度器,后面会详细拆解,核心是让每个普通进程公平获得CPU时间。
空闲调度类(idle_sched_class)最低优先级,只有系统没其他任务时,才会执行空闲进程,避免CPU空闲。
这种模块化设计的好处是:如果要新增调度策略,不用修改整个内核,只需新增一个调度类,实现对应的方法即可——比如适配新的异构计算场景,新增调度类就能快速支持。
3.2 CFS 完全公平调度器
普通进程的调度,全靠CFS(完全公平调度器)——它就像一个公平的“蛋糕师”,把CPU时间这块“蛋糕”,公平分给每个普通进程,不会让某个进程多吃多占。
CFS最核心的改进,是抛弃了固定时间片,引入了虚拟运行时间(vruntime)——用vruntime衡量进程的CPU使用情况,vruntime越小,说明进程占用CPU的时间越少,下次越优先执行。vruntime的计算公式很简单:
$$vruntime = 实际运行时间 \times \frac{nice0权重}{进程权重}$$
其中,nice0权重是基准权重(nice=0时的权重,默认1024),进程优先级越高,权重越大,相同实际运行时间下,vruntime增长越慢——比如nice=-5的进程权重比nice=0的大,vruntime增长慢,能获得更多CPU时间。
CFS用红黑树管理就绪态普通进程,红黑树按vruntime排序,最左侧节点是vruntime最小的进程,就是下一个要执行的进程。咱们可以用代码查看进程的vruntime(需要内核支持debugfs):
# 挂载debugfs(如果未挂载)mount -t debugfs none /sys/kernel/debug# 查看指定CPU的CFS就绪队列信息(以CPU0为例)cat /sys/kernel/debug/sched/cpu0
举个实际例子帮大家理解:假设三个普通进程A(nice=-5)、B(nice=0)、C(nice=5),初始vruntime都是0。运行一段时间后,A的vruntime增长最慢,B次之,C最快——此时CFS会优先调度A执行,直到A的vruntime超过其他进程,再切换到vruntime最小的进程,循环往复,实现公平调度。
四、实战:如何 “看透” 内核调度行为
4.1 ftrace 跟踪:捕捉调度事件轨迹
想搞懂调度机制的实际运行情况,第一步就是用ftrace跟踪调度事件——它是内核内置的跟踪工具,不用改内核代码,就能精准捕捉进程唤醒、切换、迁移等事件,相当于给调度过程装了个“监控”。
下面给大家一套完整的ftrace调度跟踪实操代码:
# 1. 挂载debugfs(如果未挂载)mount -t debugfs none /sys/kernel/debug# 2. 清空之前的跟踪记录echo > /sys/kernel/debug/tracing/trace# 3. 启用调度事件跟踪(仅跟踪sched相关事件)echo 1 > /sys/kernel/debug/tracing/events/sched/enable# 4. 运行要跟踪的程序(比如运行一个测试进程)./test_program &# 5. 等待一段时间(比如10秒),然后停止跟踪sleep 10echo 0 > /sys/kernel/debug/tracing/events/sched/enable# 6. 查看跟踪结果(筛选关键事件)grep -E "sched_wakeup|sched_switch|sched_migrate_task" /sys/kernel/debug/tracing/trace
跟踪结果里,有三个关键事件需要关注:
sched_wakeup:进程被唤醒,进入就绪队列——比如进程等待键盘输入完成,被唤醒后,会触发这个事件,我们能看到唤醒时间、唤醒的进程PID。
sched_switch:进程切换,记录当前进程退出CPU、下一个进程进入CPU的信息——比如进程A时间片用完,切换到进程B,会记录两个进程的PID、切换时间。
sched_migrate_task:进程迁移,记录进程从一个CPU迁移到另一个CPU的信息——比如CPU0负载过高,进程被迁移到CPU1,能看到迁移前后的CPU编号、进程PID。
通过这些信息,我们能计算进程从唤醒到执行的延迟(唤醒时间和切换时间的差值),如果延迟过高,可能是就绪队列进程过多,或进程优先级设置过低,需要针对性优化。
4.2 perf 性能分析:揪出调度相关的性能痛点
如果说ftrace是“跟踪细节”,那perf就是“排查痛点”——它能监控调度相关的性能指标,比如上下文切换次数、CPU迁移次数,还能捕捉调度事件的调用栈,快速定位性能瓶颈。
给大家分享几个常用的perf调度分析命令:
# 1. 监控上下文切换、CPU迁移等关键指标(持续10秒)perf stat -e context-switches,cpu-migrations,sched:sched_switch -a sleep 10# 2. 采集调度切换事件的调用栈,保存到perf.data文件perf record -e sched:sched_switch -g -a sleep 10# 3. 查看采集结果(生成火焰图更直观,需安装flamegraph工具)perf report# 生成火焰图(需先下载flamegraph脚本)perf script | ./stackcollapse-perf.pl | ./flamegraph.pl > sched_flamegraph.svg
重点关注两个指标:
上下文切换(context-switches):CPU切换进程时,需要保存当前进程状态、加载下一个进程状态,频繁切换会增加开销,导致系统变慢。如果上下文切换次数过高(比如每秒几万次),可能是线程过多,或线程频繁阻塞(比如频繁IO操作)。
CPU迁移(cpu-migrations):进程在不同CPU间迁移,会导致缓存失效(进程在CPU缓存的数据,迁移后需要重新读取),增加内存访问开销。如果某个进程频繁迁移,可通过CPU亲和性绑定,固定在某个CPU上运行。
通过perf report或火焰图,能看到哪些函数频繁触发调度——比如某个调度算法函数执行时间过长,就是性能瓶颈,需要优化算法或调整调度参数。
4.3 CPU 亲和性与负载均衡:优化多核调度效率
多核CPU环境下,优化调度效率的关键,是做好CPU亲和性和负载均衡——前者避免进程频繁迁移,后者确保每个CPU负载均匀,两者搭配,能显著提升系统性能。
先说说CPU亲和性:就是把进程固定在特定CPU核心上运行,避免缓存失效。比如数据库进程,固定在CPU0和CPU1上,能减少缓存失效带来的性能损失,提高读写速度。实操代码如下:
# 1. 查看进程的CPU亲和性(以PID=1234为例)taskset -cp 1234# 2. 将进程绑定到CPU0和CPU1(二进制掩码0b11,十进制3)taskset -cp 0,1 1234# 或用掩码设置:taskset -p 3 1234# 3. 启动进程时,直接绑定CPU(比如绑定到CPU2)taskset -c 2 ./test_program
再说说负载均衡:确保每个CPU核心的负载都不太高,避免有的CPU忙到卡死,有的CPU空闲。咱们可以用命令查看CPU负载分布,再调整负载均衡参数:
# 1. 查看每个CPU的负载情况(实时更新)mpstat -P ALL 1# 2. 查看负载均衡相关参数cat /proc/sys/kernel/sched_migration_cost_ns # 进程迁移成本(纳秒)# 3. 调整迁移成本(值越大,调度器越谨慎迁移进程)echo 500000 > /proc/sys/kernel/sched_migration_cost_ns
比如mpstat命令输出中,如果CPU0的使用率是90%,CPU1的使用率是20%,说明负载不均衡——可以调整sched_migration_cost_ns参数,让调度器更积极地迁移进程,平衡CPU负载。
五、调度优化实践
5.1 调整 nice 值:轻量级优化普通进程优先级
调整nice值是最常用、最轻量的调度优化手段——不用改内核,不用重启进程,直接调整普通进程的优先级,适配不同场景的需求。
先回顾一下:nice值范围是-20~19,值越小,优先级越高。日常优化的核心原则是:给需要实时响应的进程(比如SSH、浏览器)调低nice值,给CPU密集型后台任务(比如备份、编译)调高nice值。
给大家分享两个实操场景:
# 场景1:启动备份任务,调低优先级(nice=10)nice -n 10 tar -zcvf /backup/archive.tar.gz /home/user/data# 场景2:调整运行中的SSH进程,提高优先级(nice=-5)# 先找SSH进程PIDpid=`pgrep sshd`# 调整nice值renice -n -5 -p $pid# 验证调整结果ps -o pid,ni $pid
比如服务器上,备份任务是CPU密集型,设置nice=10,让它在系统空闲时运行,不影响SSH连接、数据库等关键服务;而SSH是交互式服务,设置nice=-5,确保用户操作能快速响应,不会卡顿。
5.2 cgroups 资源隔离:多租户场景的精准管控
多租户VPS场景中,多个用户的应用共享CPU资源,很容易出现“一个用户的进程占满CPU,其他用户卡顿”的问题——cgroups就是解决这个问题的利器,能实现资源隔离,精准分配CPU权重。
cgroups v2是目前的主流版本,比v1更精准,核心用cpu.weight参数分配CPU权重(范围1~10000),权重越高,获得的CPU时间越多。实操步骤如下(以CentOS 8+为例):
# 1. 确认系统启用cgroups v2mount | grep cgroup2# 2. 创建cgroup分组(分别给MySQL和PHP-FPM)mkdir -p /sys/fs/cgroup/mysqlmkdir -p /sys/fs/cgroup/php-fpm# 3. 设置CPU权重(MySQL=500,PHP-FPM=200)echo 500 > /sys/fs/cgroup/mysql/cpu.weightecho 200 > /sys/fs/cgroup/php-fpm/cpu.weight# 4. 将进程加入对应的cgroup(以MySQL PID=1234为例)echo 1234 > /sys/fs/cgroup/mysql/cgroup.procsecho 5678 > /sys/fs/cgroup/php-fpm/cgroup.procs# 5. 查看cgroup资源使用情况cat /sys/fs/cgroup/mysql/cpu.stat
实际测试中,给MySQL设置cpu.weight=500,PHP-FPM设置200,MySQL能获得更多CPU时间,数据库查询延迟可降低37%——适合多租户场景,确保每个租户的服务质量不受影响。
注意:实时进程必须放在独立的cgroup子树中,避免被cgroup配额限制优先级。比如把实时监控进程加入专门的cgroup,不与普通进程共享配额,确保实时任务能及时执行。
5.3 混合调度策略:平衡实时性与公平性的最佳实践
生产环境中,往往需要兼顾实时性和公平性——比如电商平台,支付接口需要高实时性,普通用户浏览需要公平分配资源,这时候就需要混合调度策略。
推荐遵循“20/80原则”:80% CPU资源分配给普通进程(公平调度),20%预留为实时进程(实时调度),既保证常规业务流畅,又确保关键任务低延迟。实操代码如下:
# 1. 将支付接口进程设置为实时SCHED_FIFO策略(优先级99)pid=`pgrep pay-service`chrt -f -p 99 $pid# 2. 用cgroup预留20% CPU资源给实时进程mkdir -p /sys/fs/cgroup/realtimeecho 200000 > /sys/fs/cgroup/realtime/cpu.max # 20% CPU(单位:微秒/100ms)echo $pid > /sys/fs/cgroup/realtime/cgroup.procs# 3. 突发负载时,临时提升实时进程CPU配额echo 300000 > /sys/fs/cgroup/realtime/cpu.max# 4. 调整CPU为performance模式,提升运行频率echo performance | tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
解释一下:支付接口进程设置为SCHED_FIFO策略,优先级99,能优先抢占CPU;用cgroup预留20% CPU资源,避免实时进程被普通进程挤占;突发负载时,临时提升CPU配额,结合performance模式,能让SLA达标率提升至92%以上。
这种混合策略,适合大多数生产场景——既解决了实时任务的低延迟需求,又保证了普通任务的公平性,避免资源浪费。