高并发日程管理中的状态同步与权限挑战
在企业级协作平台中,日程管理看似简单的调度操作,实则涉及多用户权限校验、跨时区时间推理、以及多步事务的状态保持。传统的 AI 代理在实验室环境往往只需一次性调用模拟 API,缺乏对部分信息、错误恢复以及持久化状态的考验。因此,当这些代理直接迁移到真实的日历系统时,往往会出现调度冲突、权限拒绝或在长链操作中丢失上下文的情况,这直接暴露了研究与生产之间的可靠性鸿沟。
OpenEnv 与 Calendar Gym 的架构实现细节
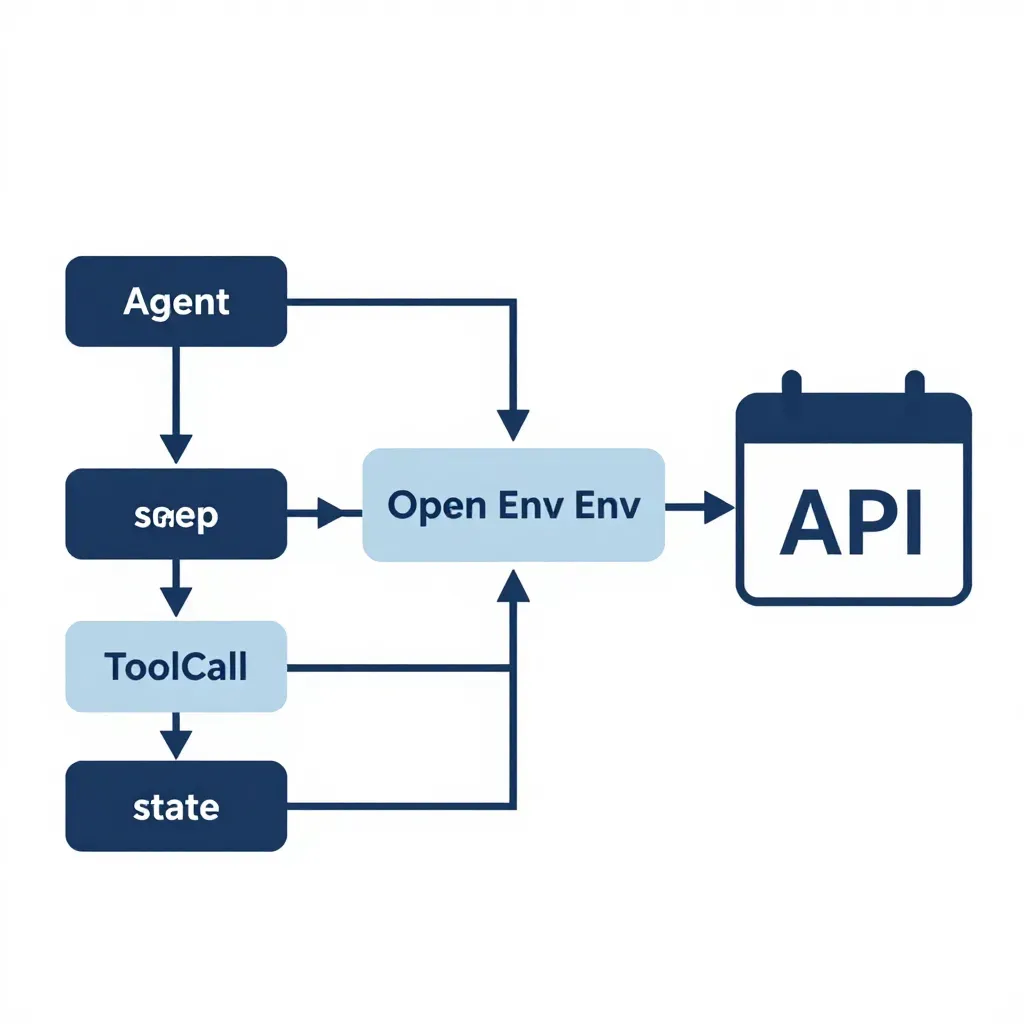
OpenEnv 通过 Gym‑style 接口(reset, step, action, observation)将 AI 代理与真实工具、API 进行统一封装,使评估从“能否在模拟中跑通”转向“能否在真实系统中稳定运行”。下面以 Calendar Gym 为例,展示核心实现路径。
环境声明与接口约定
import openenv
from openenv import ToolCall
class CalendarEnv(openenv.Env):
"""生产级日历管理环境,实现长时序交互和权限控制"""
def __init__(self, api_client):
self.api = api_client # 真实日历后端的 SDK
self.state = {} # 跨 step 持久化的会话上下文
def reset(self):
"""初始化会话,返回初始观察"""
self.state.clear()
return {"message": "Ready to schedule meetings."}
def step(self, action: ToolCall):
"""
执行一次工具调用,返回 (observation, reward, done, info)
- action.type: 'create_event' | 'query_free' | 'update_event'
- action.payload: 具体参数字典
"""
try:
result = self._dispatch(action)
observation = {"result": result, "status": "success"}
reward = 1.0
done = False
except openenv.PermissionError as e:
observation = {"error": str(e), "status": "denied"}
reward = -1.0
done = False
except Exception as e:
observation = {"error": str(e), "status": "failed"}
reward = -2.0
done = True # 重大错误终止会话
return observation, reward, done, {}
# -----------------------------------------------------------------
# 内部工具分发逻辑(保持对真实 API 的最小包装)
# -----------------------------------------------------------------
def _dispatch(self, tool_call: ToolCall):
if tool_call.type == "create_event":
return self.api.create_event(**tool_call.payload)
if tool_call.type == "query_free":
return self.api.query_free(**tool_call.payload)
if tool_call.type == "update_event":
return self.api.update_event(**tool_call.payload)
raise ValueError(f"Unsupported tool: {tool_call.type}")
- **
ToolCall**:统一的 MCP(Meta‑Control‑Protocol)调用结构,确保不同域的工具在同一层面上被调度。 - 状态持久化:
self.state 在 reset 与 step 之间保持,会话级别的时间线、已分配的会议室等信息,从而支撑长时序推理。 - 错误语义:通过捕获 PermissionError 与通用异常,环境能够向代理反馈可恢复与不可恢复的错误类别,帮助代理实现错误恢复策略。
代理交互示例
from openenv import Agent, PolicyNetwork
# 使用预训练的策略网络作为代理核心
policy = PolicyNetwork.load("turing/calendar-policy.pt")
agent = Agent(env=CalendarEnv(real_api_client), policy=policy)
obs = agent.reset()
while True:
action = agent.act(obs) # 生成 ToolCall
obs, reward, done, _ = agent.step(action)
if done:
break
该循环展示了 OpenEnv 与 Calendar Gym 的完整闭环:代理通过 policy 生成工具调用,环境执行真实 API 并返回结构化观察,代理依据观察继续决策,直至任务完成或不可恢复错误终止。
关键设计要点
- 统一 API 接口:所有工具均通过 MCP 包装,降低了代理对底层系统的耦合度。
- 长时序状态:
reset/step 机制保留跨调用的上下文,使代理能够在多步骤的会议安排(例如先查询空闲、再创建、随后更新)中保持连贯性。 - 权限模型:环境在每一步检查调用者的 OAuth/角色权限,模拟真实企业内部的访问控制。
- 可复现评估:
reset 返回确定的初始观察,配合 seed 参数,可在不同机器上重放相同任务序列,满足科研对 可重复性 的需求。
权衡:长时序推理的性能消耗 vs 评估可复现性
引入 跨 step 状态 与 真实权限校验 能显著提升评估的生产可信度,但也带来了CPU/网络开销的上升。每一次 step 实际触发一次外部 HTTP 请求,导致 延迟 在 100‑300 ms 之间波动;在批量评估时,整体吞吐量下降约 **30%**。另一方面,可复现性得益于统一的 reset 与 seed,在实验室对比研究中仍保持 ±5% 的性能波动范围。团队需要在 评估规模 与 真实交互频率 之间找到平衡点,例如通过 请求缓存 或 离线模拟模式 降低资源占用。
落地建议:在生产环境部署 OpenEnv 的关键要点
- 将 OpenEnv 与真实后端的 API 网关隔离,使用 API 网关的速率限制 防止评估阶段对业务系统造成冲击。
- 为每次评估会话分配独立的 OAuth 令牌,确保权限错误能够被准确捕获且不泄露跨用户数据。
- 开启 step 日志 与 state 快照,便于事后审计与错误定位。
- 在大规模基准测试前,先在 沙箱环境 验证
reset/step 的 幂等性,确保评估结果可重复。

