 Andrej Karpathy 干了一件事,让我盯着屏幕看了整整二十分钟。
Andrej Karpathy 干了一件事,让我盯着屏幕看了整整二十分钟。
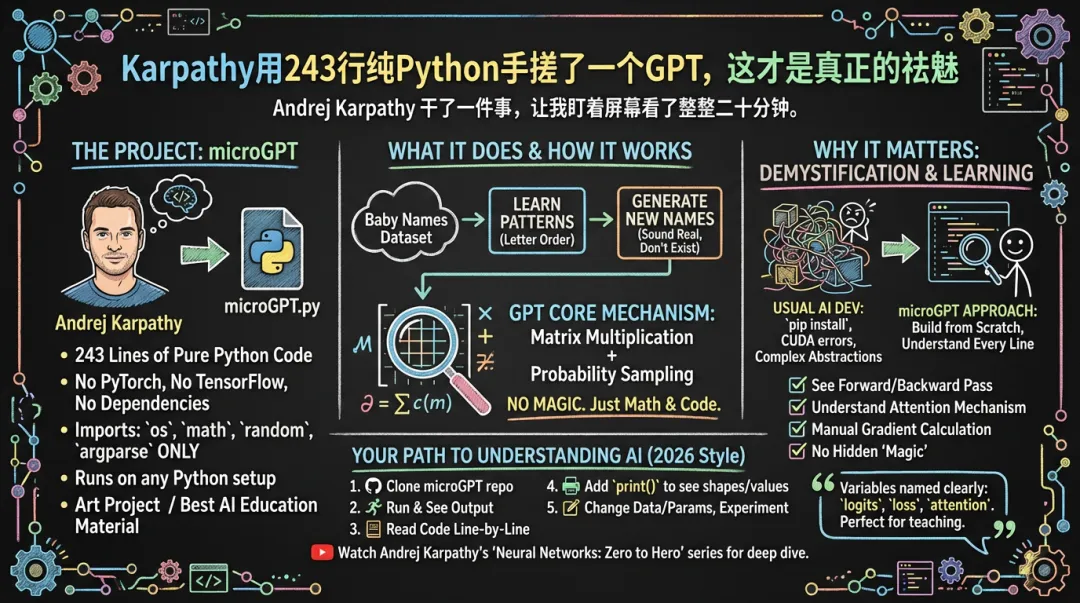
他用 243 行纯 Python 代码,从零训练了一个 GPT。
不是调 API。不是套壳。是从头到尾,forward pass、backward pass、attention 机制、参数更新,全部手写。整个文件的 import 只有四个东西:os、math、random、argparse。没有 PyTorch,没有 TensorFlow,没有任何第三方依赖。你把这个 .py 文件丢到任何一台装了 Python 的电脑上,直接就能跑。
他管这个叫 microGPT,说是一个「art project」。地址在:
https://gist.github.com/karpathy/8627fe009c40f57531cb18360106ce95
我觉得这个定位太谦虚了。这东西是目前互联网上最好的 AI 教育材料,没有之一。
先说它到底在做什么
microGPT 的任务很简单:下载一个婴儿名字的数据集 → 学习这些名字里的字母排列规律 → 生成新的、听起来像真名但从未存在过的名字。
对,就这么朴素。它不能跟你聊天,不能写代码,不能帮你做 PPT。它只是一个最小化的语言模型,用来证明一件事——GPT 的核心机制,本质上就是矩阵乘法加上一点点概率采样。
这个 demo 的力量不在于它能做什么,在于它让你亲眼看到「哦,原来就这么回事」。
为什么我觉得这件事很重要
做过 AI 开发的人都知道,现在跑一个 transformer 模型是什么体验。你 clone 一个 repo,先 pip install -r requirements.txt,看着 400 个包往下载,然后大概率在某个 CUDA 版本或者 numpy 兼容性问题上卡住。你花两个小时调环境,最后发现自己连模型长什么样都没看到。
这个过程消灭了多少人的学习热情,我不敢想。
我自己不是 CS 科班出身,当年学深度学习的时候,最痛苦的不是数学,是那堆工程化的抽象层。PyTorch 的 nn.Module 封装得太好了,好到你根本不知道 attention 到底在算什么。你调通了代码,loss 在降,模型在收敛,你甚至能部署上线——但你心里清楚,你对里面发生的事情只有一个模糊的直觉。
Karpathy 这 243 行代码,把所有抽象层全部炸掉了。
每一个矩阵运算都是裸的 Python 列表操作。每一个梯度计算都是手动链式法则。你看着代码就能数出来,一个 token 从输入到输出经过了几次乘法、几次加法、几次 softmax。所有的 magic 都被摊开在阳光下,你会发现——真的没有 magic。
这个人为什么值得你关注
简单交代一下背景。Andrej Karpathy 是 OpenAI 的联合创始人之一,后来去 Tesla 当 AI 总监领导自动驾驶视觉团队,再后来又回到 OpenAI 干了一阵,现在基本是独立身份在做 AI 教育。
他之前有一个非常出名的项目叫 nanoGPT,大概 600 行代码实现了一个可以在莎士比亚文本上训练的小型 GPT。那个项目已经够精简了,还是用了 PyTorch。想看在这里:https://github.com/karpathy/nanoGPT
这次 microGPT,连 PyTorch 都扔了。
你能感受到他在追求一种极致:把大语言模型这个概念压缩到最小信息量,小到你没有任何借口说「我看不懂」。
说实话,AI 领域现在最缺的不是更大的模型、更多的算力,是有人愿意把这些东西掰开了揉碎了讲给普通人听。Karpathy 是极少数同时具备顶级技术能力和顶级教学能力的人。他在 YouTube 上的那些视频——从 backpropagation 到 tokenizer 到 GPT——是我见过的最好的深度学习课程,比绝大多数大学教授讲得清楚十倍。
而且全部免费。
我怎么看这件事
有人可能会说,243 行代码训练一个只能生成假名字的模型,有什么实际用处?
没有实际用处。这不是重点。
重点是,当你能用最基础的工具把一个 GPT 从零搭起来的时候,你对大语言模型的理解会发生质变。你不再是一个「会调 API 的用户」,你变成了一个「知道引擎怎么运转的人」。这两种人在接下来几年的 AI 浪潮里,处境会完全不同。
我一直觉得,学 AI 最好的方式不是读论文,不是刷课程,是自己动手把东西造出来。哪怕造的东西很粗糙、很小、完全没有商业价值。造的过程本身就是学习。 Karpathy 这个 microGPT 提供了一个完美的起点:代码量小到你一个下午就能通读,逻辑清晰到你可以逐行加注释,而且它真的能跑、能训练、能生成结果。
我上周花了一个晚上把代码从头到尾读了一遍,在几个关键位置加了 print 把中间结果打出来看。说真的,attention 机制的 Q、K、V 矩阵运算,我之前看过无数篇博客和论文插图,都不如亲眼看着那些数字在 Python 列表里流动来得直观。有一瞬间甚至有点感动——就这?就这。大语言模型席卷全世界,底层就是这些东西在反复运算。
顺便说一句,我发现 Karpathy 写代码有一个习惯:变量命名极其直白。不搞花里胡哨的缩写,不用框架里的黑话。logits 就是 logits,loss 就是 loss,连 attention 函数里的注释都写得像在跟人说话。这种风格太适合教学了。很多开源项目代码质量很高,但对新手极不友好,因为作者默认你已经懂了 80% 的上下文。Karpathy 不做这个假设。
你可以怎么用这个东西
如果你对 AI 有兴趣,想真正理解大语言模型而不只是会用 ChatGPT,我建议的路径是这样的:
- 去 GitHub 搜 Karpathy 的 microGPT 仓库,把代码 clone 下来
- 然后从第一行开始读代码,每个不理解的地方就停下来查
- 在关键位置加
print(),把矩阵的 shape 和数值打出来看 - 试着改点东西——换个数据集、调个超参数、加一层 attention——看会发生什么
整个过程不需要 GPU,你的笔记本 CPU 就够了。不需要装任何额外的包。这大概是入门门槛最低的 transformer 实现了。
如果英文阅读没障碍,Karpathy 在 YouTube 上有配套的讲解视频,搜「Andrej Karpathy neural networks zero to hero」就能找到完整的系列。从最基础的导数和梯度开始讲,一路讲到 GPT。我当年就是靠这个系列入的门,比任何付费课程都管用。
243 行代码,四个标准库 import,一个能跑的 GPT。
这就是 2026 年学 AI 该有的样子。



