期刊图片复现|Python实现基于 XGBoost 与 SHAP 的多分类模型性能评估与可解释性分析全流程框架
- 2026-07-04 21:43:02
期刊图片复现|Python实现基于 XGBoost 与 SHAP 的多分类模型性能评估与可解释性分析全流程框架

论文:Machine learning uncovers dominant fractions of heavy metal(loid)s in global soils 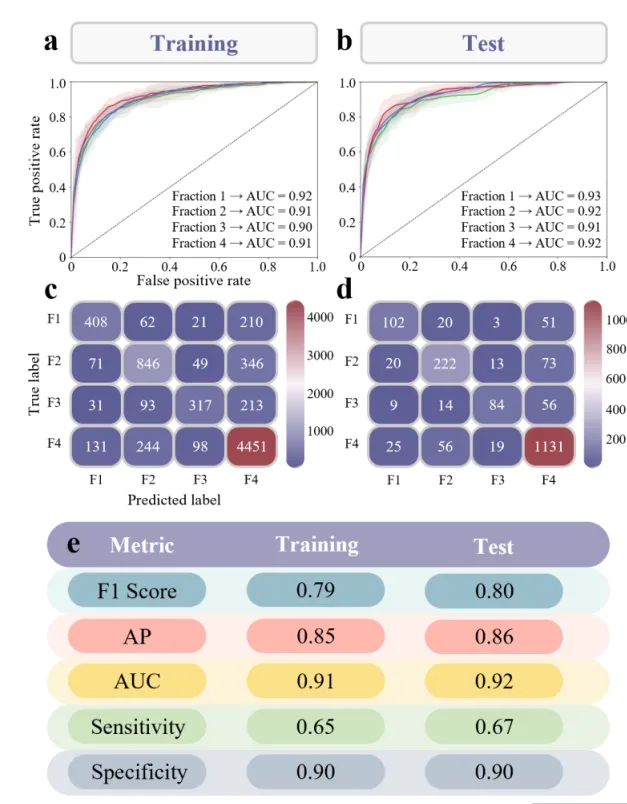
论文原图 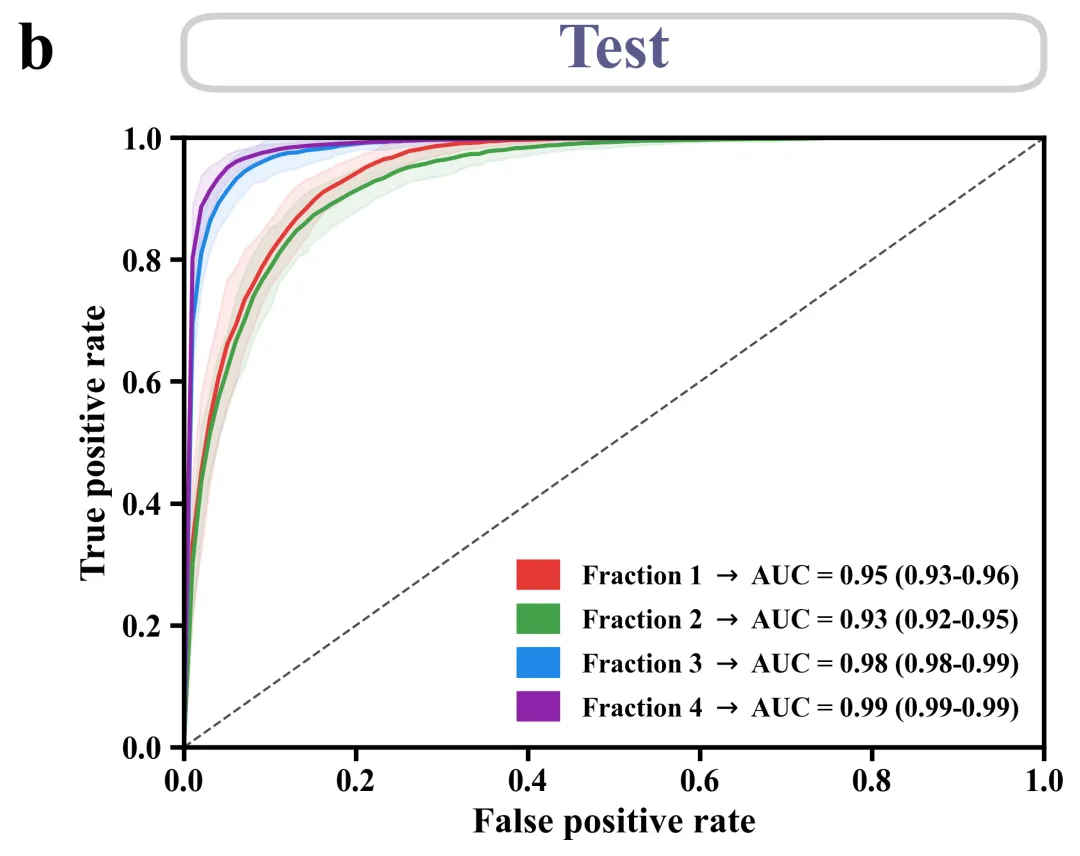
仿图 



库的导入以及字体设置 

颜色库的设置以及配色方案的选择与提取 

蜂巢图抖动计算函数,老演员了,不介绍了 

ROC 曲线绘制函数:用于绘制多分类任务的ROC曲线图。接收多次迭代训练得到的TPR和AUC数据,计算出每一类的平均ROC曲线。此外,它通过计算标准差来绘制围绕曲线的阴影部分,以展示模型表现的95%置信区间波动情况。 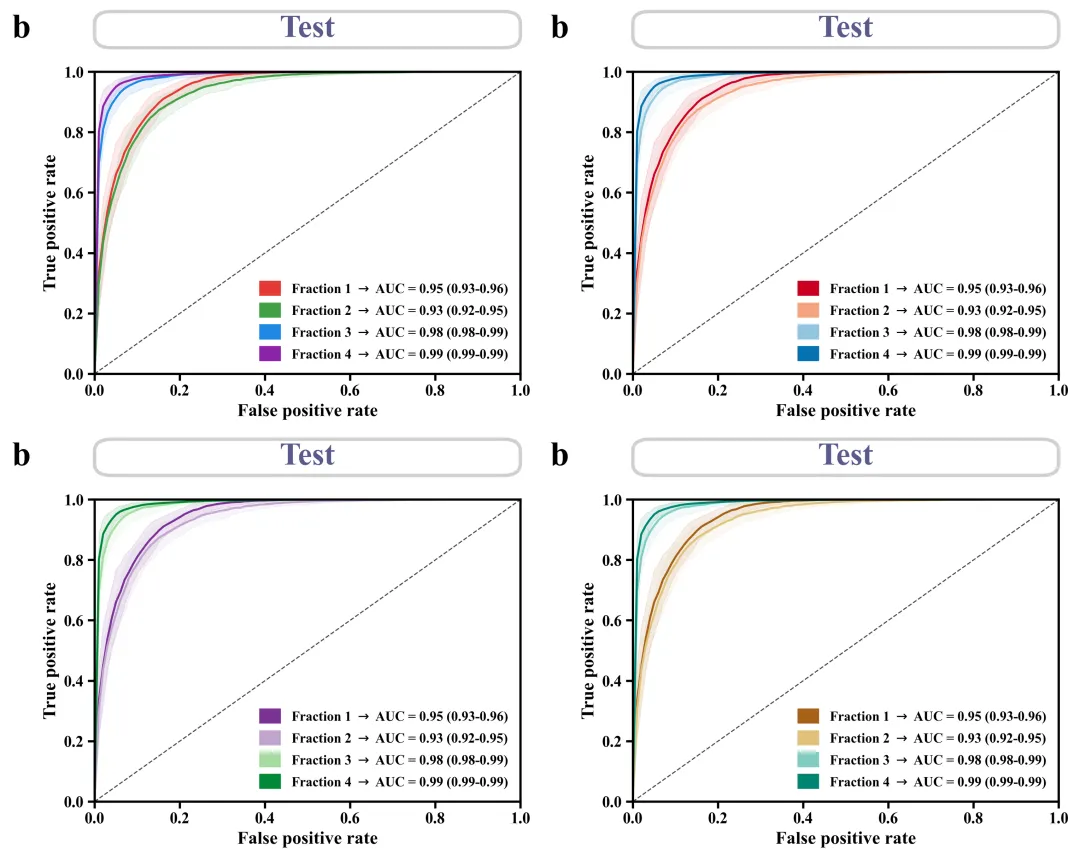


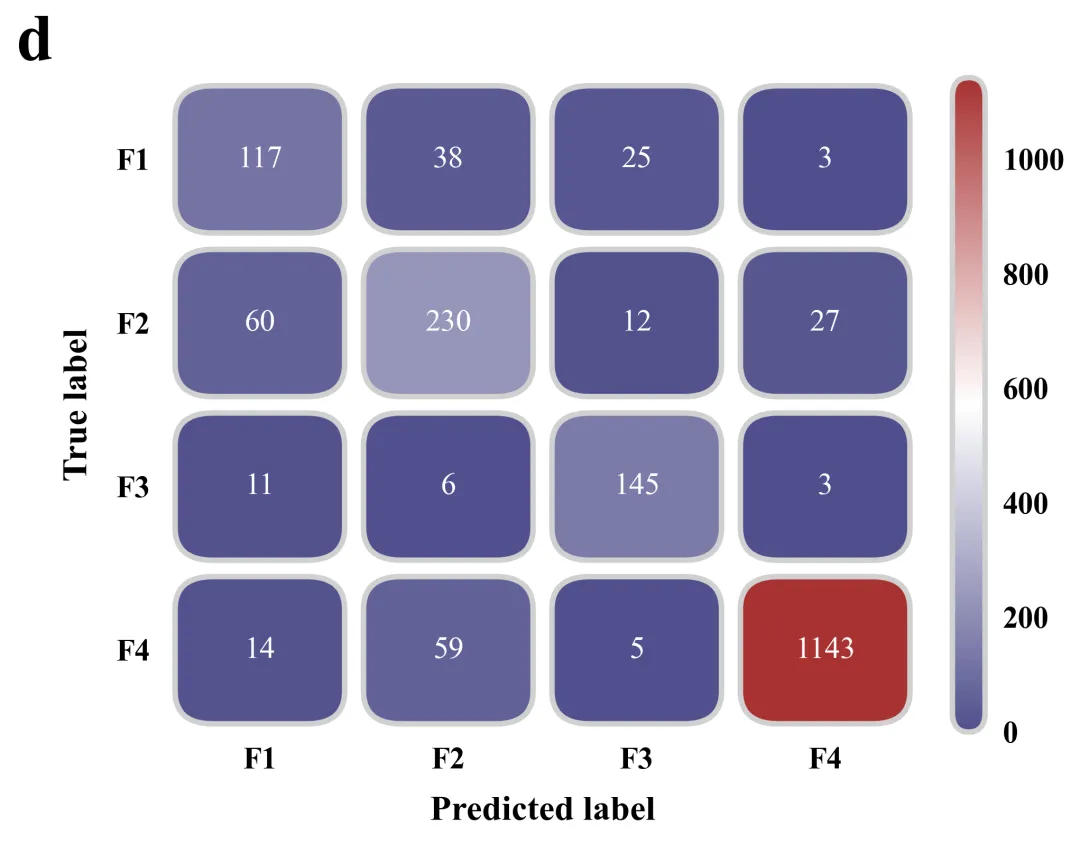
混淆矩阵绘制函数:用于绘制高颜值混淆矩阵。有别于常见的默认热力图混淆矩阵,该函数逐一遍历矩阵数据,为每个数据格子绘制出带有弧度(圆角)的方块。不仅如此,还对图例颜色条也进行了圆角裁剪处理。 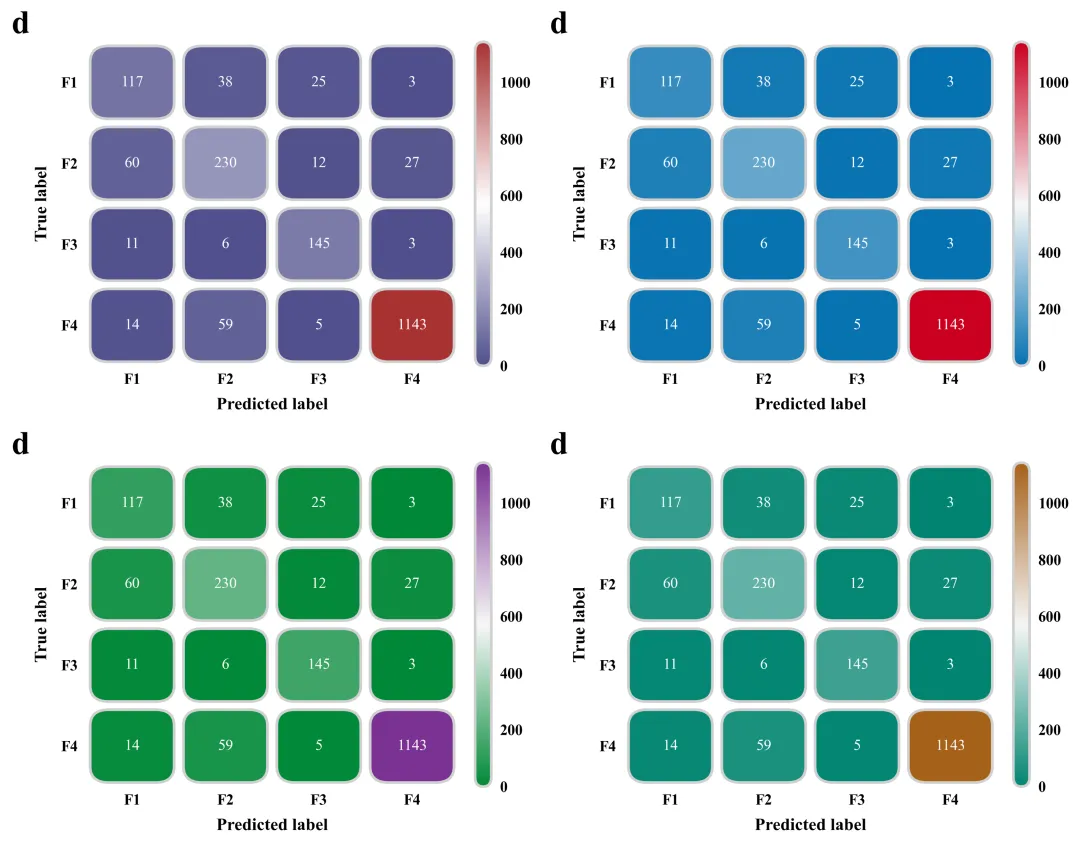


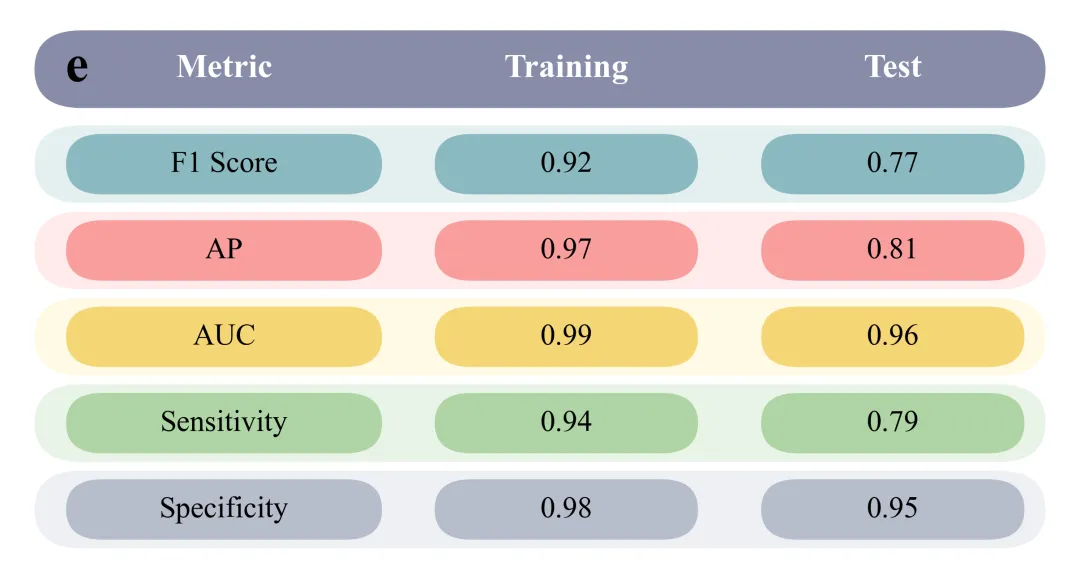
绘制性能指标可视化表格:呈现了训练集和测试集在F1、AP、AUC、敏感性、特异性等指标上的均值和标准差。 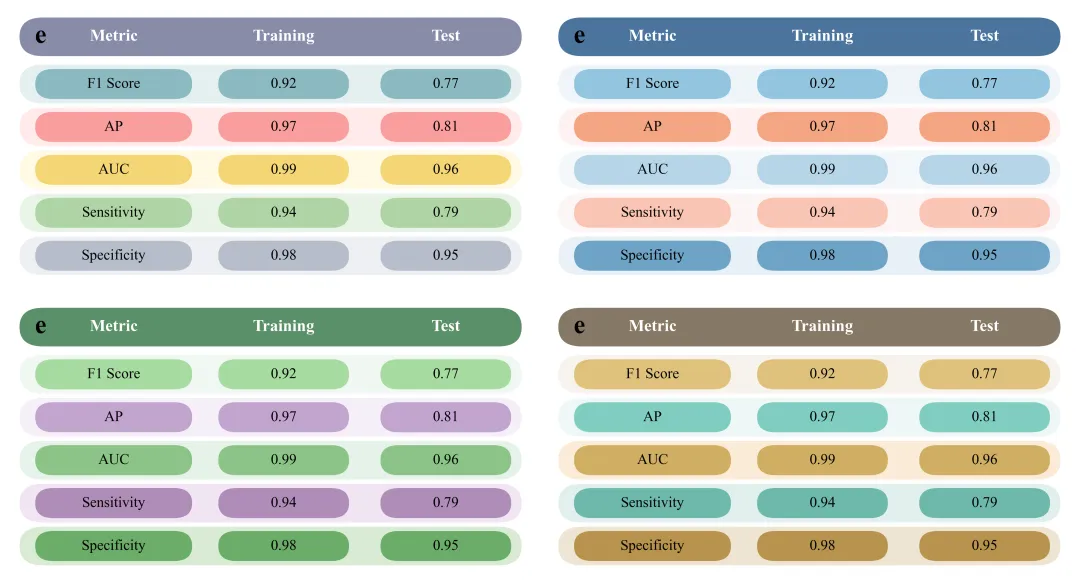


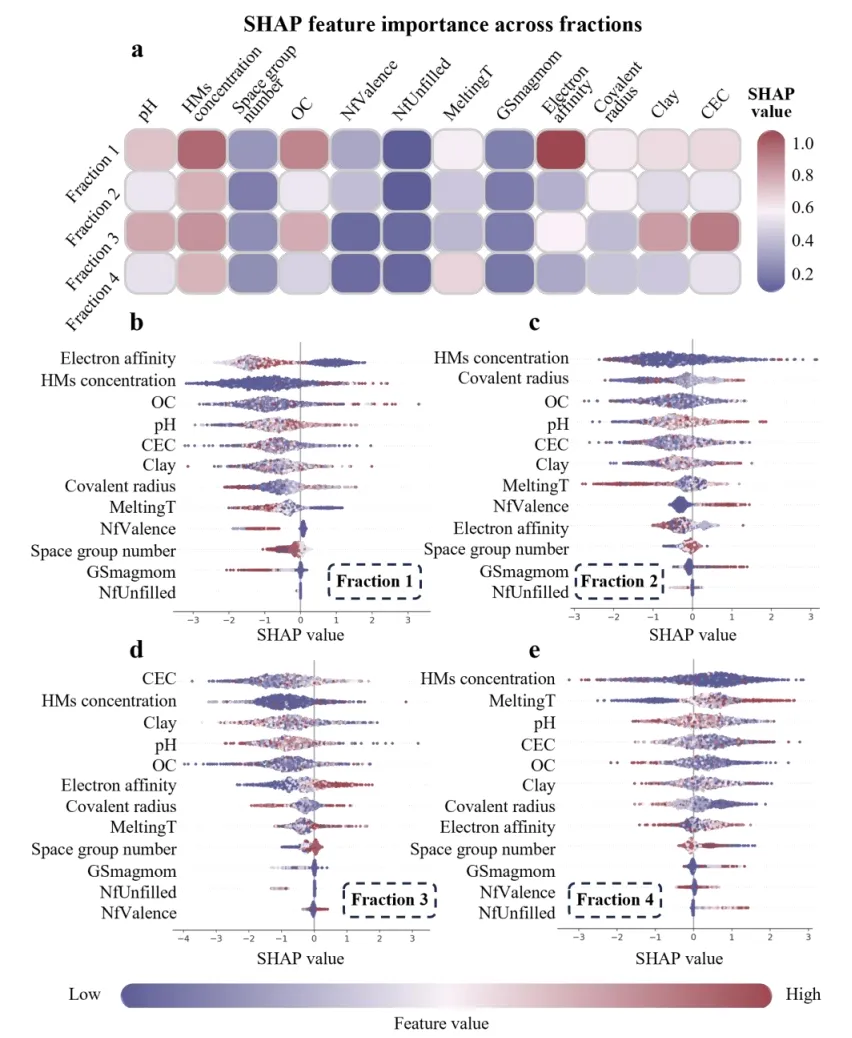
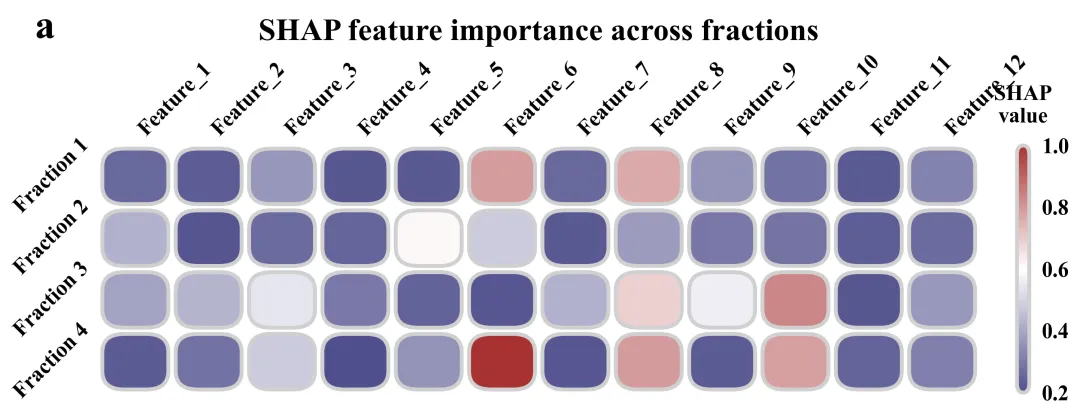
SHAP 特征重要性热图:用于展示归一化后的全局SHAP特征重要性。横轴是所有的输入特征,纵轴是4个类别。分析某一个特定的特征,究竟在预测哪一个类别时发挥了最大的决策权重。 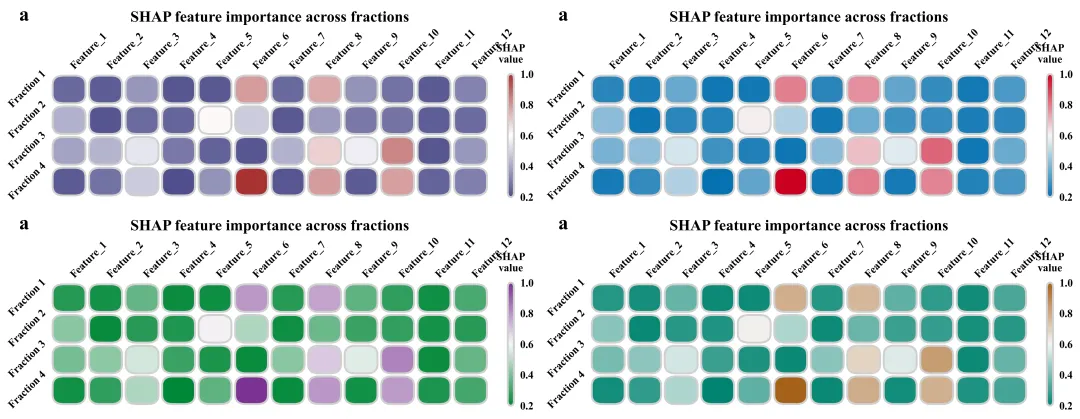


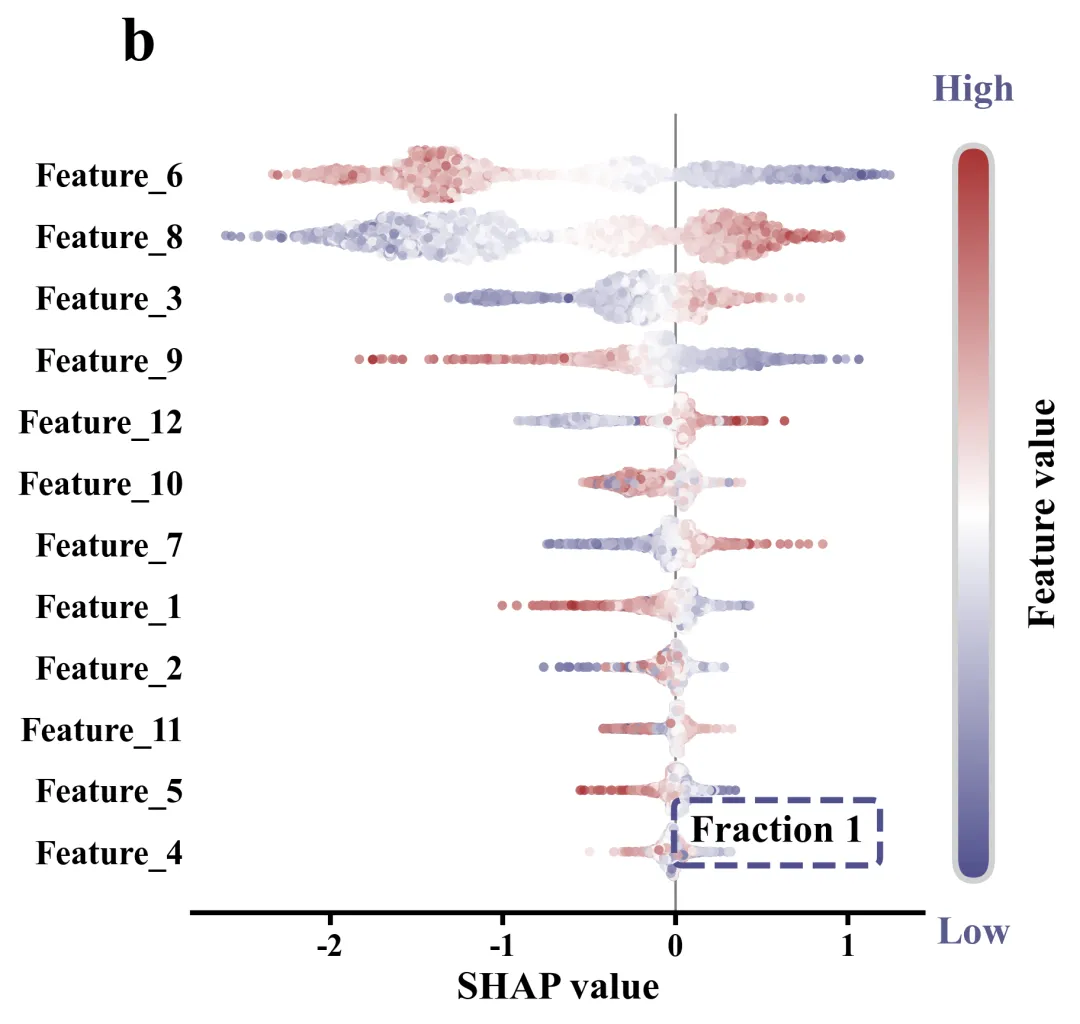
SHAP 特征重要性蜂巢图:首先按照重要度对特征进行排序。对于每个特征,利用前面定义的辅助函数计算每个数据点在图中的 y 轴分散度。散点的颜色映射到了原始数据的高低分布,借此可观察某个特征的值变大/变小时,是将模型的输出推向正向还是负向。 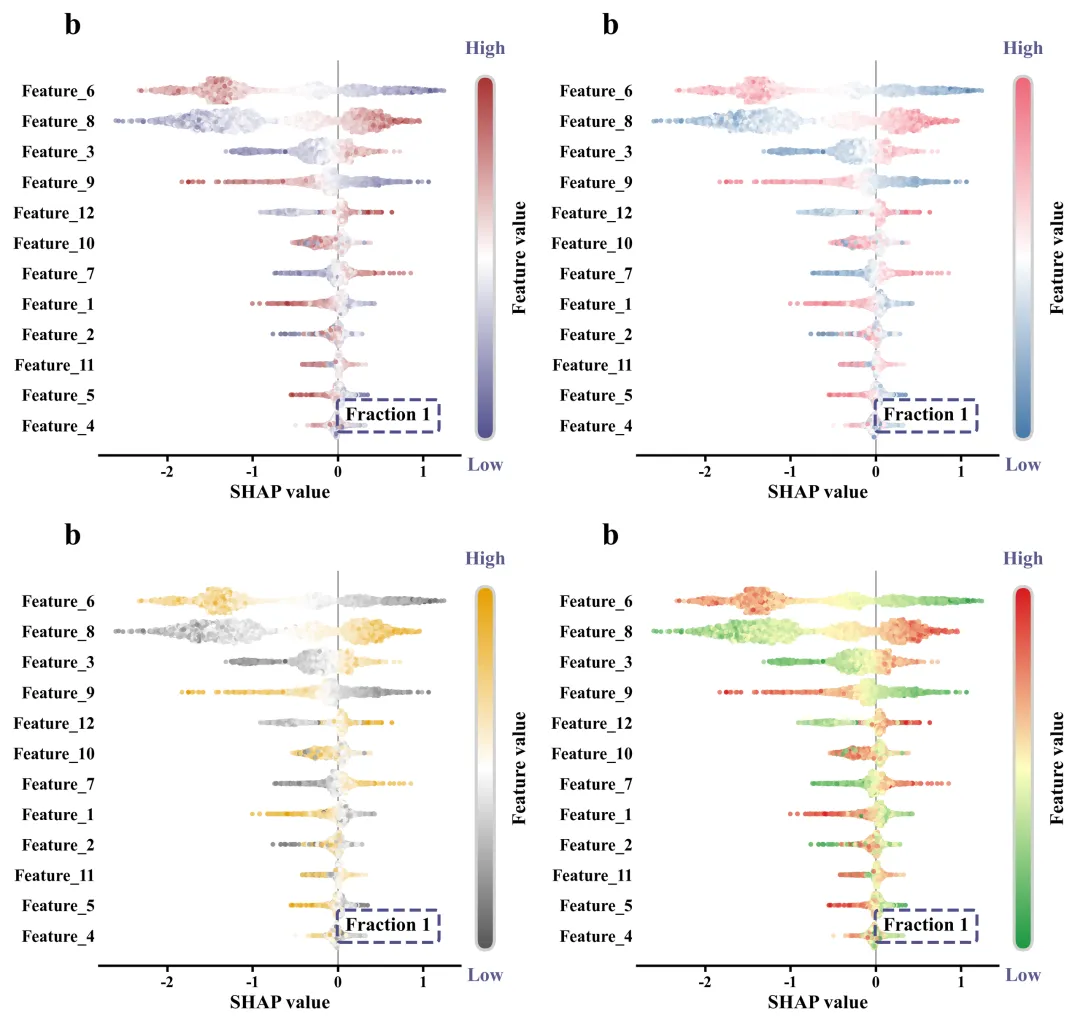


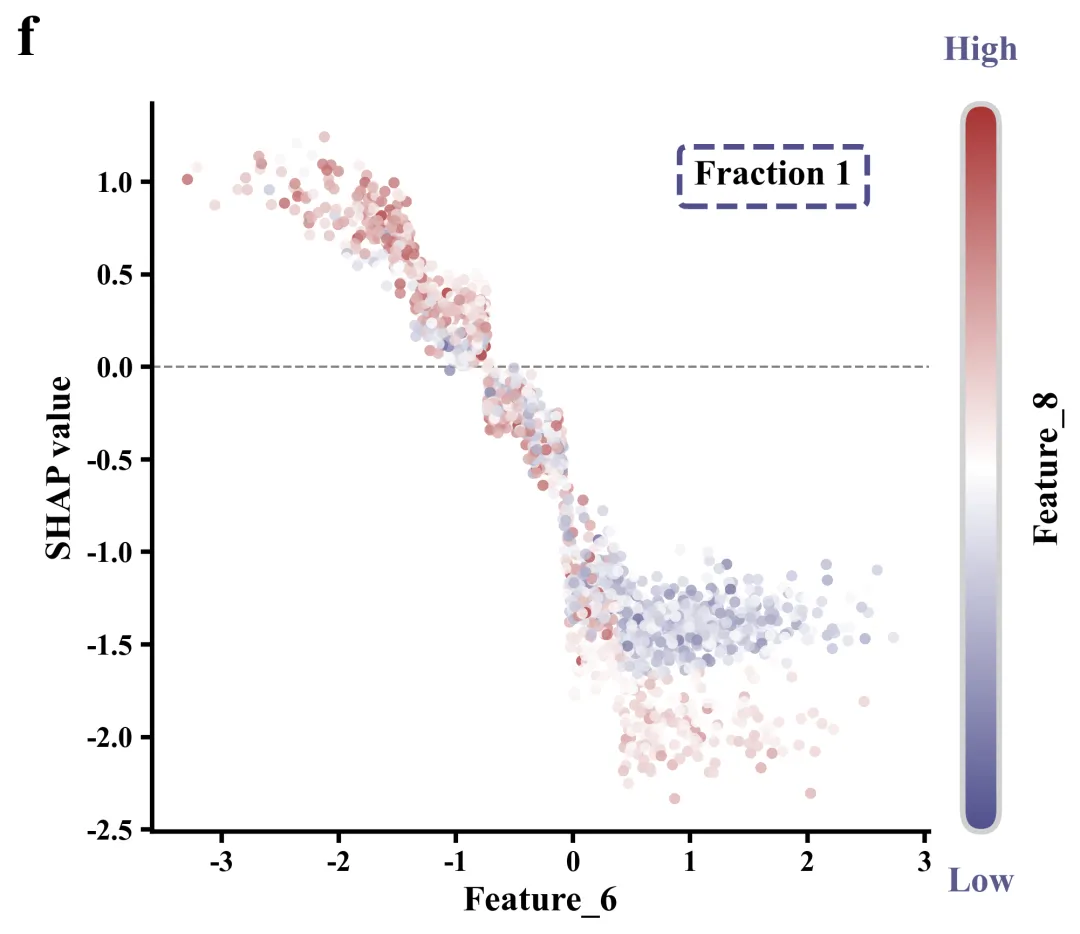
单特征依赖图绘制函数:展示某单一核心特征的具体取值是如何影响该特征对应的SHAP 边际贡献的。同时,为了挖掘特征交互,散点的颜色映射由另外一个次要交互特征控制,从而可分析两个特征对决策结果的联合作用机制。 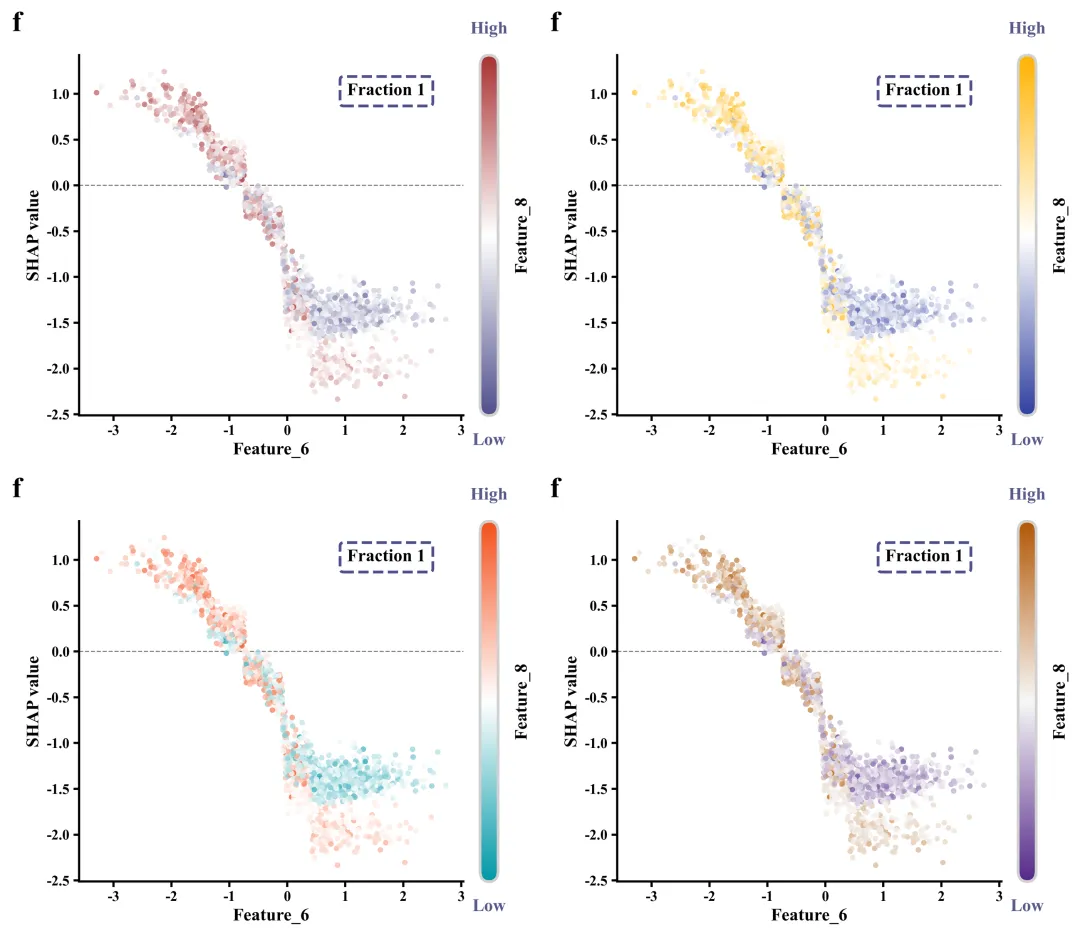


执行部分(数据准备与变量初始化):读取指定路径下的数据,并进行特征和标签的拆分。为了避免单次随机抽样导致评估偏差,设定了运行15次独立的循环迭代,初始化变量容器,用于后续持久化记录每次迭代的模型指标和数据。 

执行部分(交叉验证模型训练核心循环):负责执行15次完全独立的检验。包含分层抽样划分测试/训练集、数据缩放、以及计算并应用类别不平衡权重。通过网格搜索交叉验证来寻找当前划分下的最佳XGBoost模型,并将每次评估获得的各性能指标全数保存。最后动态比对当前轮次的测试集Macro F1得分,找到表现最优的那一次,保存最佳模型和相关数据,用于后续的特征解释。 

执行部分(结果可视化与可解释性分析调用):汇总15次迭代的均值,绘制测试集和训练集的 ROC 曲线、混淆矩阵、性能总表。然后调出此前留下的最强预测模型,实例化SHAP解释器进行模型推断解释。绘制全局特征重要热力图;并遍历每一个类别,针对性绘制各个分类下的特征摘要蜂巢图,以及对于该分类最重要的排名前2特征的依赖图谱。 



期刊图片复现|Python绘制二维偏依赖PDP图 期刊复现|python绘制基于SHAP分析和GAM模型拟合的单特征依赖图 期刊图片复现|python绘制带有渐变颜色shap特征重要性组合图(条形图+蜂巢图) 期刊复现|用Python绘制SHAP特征重要性总览图、依赖图、双特征交互效应SHAP图,解锁XGBoost模型的终极奥秘 期刊图片复现|Python绘制shap重要性蜂巢图+单特征依赖图+交互效应强度气泡图+交互效应依赖图(回归+二分类+分类) 

公众号中的所有所有的免费代码都已经下架了,都并入到付费部分里了,付费合集代码和数据的购买通道已经开通,全部合集100元,后续将会持续更新,决定购买请后台私信我,注意只会分享练习数据和代码文件,不会提供答疑服务,代码文件中已经包含了每行代码的完整注释,购买前请确保真的需要!!!
代码绘制成果展示
代码解释
第一部分
# =========================================================================================# ====================================== 1. 环境设置 =======================================# =========================================================================================import numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom matplotlib.patches import FancyBboxPatch, Patchfrom matplotlib.colors import LinearSegmentedColormap, Normalizefrom sklearn.model_selection import train_test_split, GridSearchCVfrom sklearn.preprocessing import StandardScalerfrom sklearn.metrics import roc_curve, auc, confusion_matrix, f1_score, average_precision_score, roc_auc_score,recall_score
第二部分
# =========================================================================================# ======================================2.颜色库============================================# =========================================================================================COLOR_SCHEMES = {1: {'cmap': ['#4f4f8c', '#ffffff', '#a83232'], 'roc': ['#E53935', '#43A047', '#1E88E5', '#8E24AA'],'table_header': '#878ca8','table_rows': [('#e4f0f0', '#8bb9c0'), ('#ffeaeb', '#f89e9d'), ('#fff9e5', '#f5d676'), ('#e9f4e6', '#aed4a4'),('#eef0f3', '#b5bdcb')]},}SCHEME_ID = 60 #设置当前使用的配色方案global_scheme = COLOR_SCHEMES[SCHEME_ID] #获取对应的配色方案
第三部分
# =========================================================================================# ======================================3.蜂巢图抖动计算函数===================================# =========================================================================================def simple_beeswarm(x_values, nbins=40, width=0.1):hist_range = (np.min(x_values), np.max(x_values)) #数据的最小值和最大值范围if hist_range[0] == hist_range[1]: # 如果最大值等于最小值hist_range = (hist_range[0] - 0.1, hist_range[1] + 0.1) #手动扩展范围counts, edges = np.histogram(x_values, bins=nbins, range=hist_range) #计算直方图,获取各区间的计数和边界bin_indices = np.digitize(x_values, edges) - 1 # 计算每个数据点所属的箱子索引current_width = (counts[i] / max_count) * width # 根据当前箱子的密度计算抖动宽度ys = np.linspace(-current_width, current_width, len(idxs)) # 在宽度范围内生成均匀分布的Y值np.random.shuffle(ys) # 打乱Y值顺序y_values[idxs] = ys # 将计算好的Y值赋给对应的数据点return y_values # 返回计算好的Y轴抖动坐标
第四部分
# =========================================================================================# ======================================4.ROC 曲线==========================================# =========================================================================================def plot_single_roc(tprs, aucs, title_text, letter):#创建画布fig, ax = plt.subplots(figsize=(6.5, 5.5))custom_legend_handles = [] #用于存储自定义图例句柄roc_colors = global_scheme['roc'] #获取颜色auc_lower = max(0.0, mean_auc - 1.96 * std_auc) #置信区间的下限auc_upper = min(1.0, mean_auc + 1.96 * std_auc) #置信区间的上限std_tpr = np.std(tprs[i], axis=0) #标准差tprs_upper = np.minimum(mean_tpr + 1.96 * std_tpr, 1) #TPR的置信区间上限tprs_lower = np.maximum(mean_tpr - 1.96 * std_tpr, 0) #TPR的置信区间下限#绘制平均ROC曲线ax.plot(mean_fpr, mean_tpr, color=color, lw=1.8)#绘制置信区间阴影带ax.fill_between(mean_fpr, tprs_lower, tprs_upper, color=color, alpha=0.1)#图例标签文本label_text = rf"{class_names[i]} $\rightarrow$ AUC = {mean_auc:.2f} ({auc_lower:.2f}-{auc_upper:.2f})"patch = Patch(facecolor=color, edgecolor=color, label=label_text) #图例色块custom_legend_handles.append(patch) #添加到图例句柄列表中#绘制对角虚线ax.plot([0, 1], [0, 1], linestyle='--', lw=1, color='black', alpha=0.7)ax.set_xlim([0.0, 1.0]) #x轴范围ax.set_ylim([0.0, 1.0]) #y轴范围ax.set_xlabel('False positive rate', fontsize=16, fontweight='bold') #x轴标题ax.set_ylabel('True positive rate', fontsize=16, fontweight='bold') #y轴标题# 设置主刻度线ax.tick_params(axis='both', which='major', length=6, width=2, labelsize=14)
第五部分
# =========================================================================================# ======================================5.混淆矩阵绘制函数==========================================# =========================================================================================def plot_custom_confusion_matrix(cm, letter, is_train=True):#创建画布和坐标轴fig, ax = plt.subplots(figsize=(6.5, 5.5))cmap = LinearSegmentedColormap.from_list('custom_cm', global_scheme['cmap'], N=256) #创建渐变色映射norm = Normalize(vmin=0, vmax=cm.max()) #定义数据归一化对象,将矩阵的数值映射到颜色条范围ax.set_xlim(-0.5, 3.5) #x轴范围ax.set_ylim(3.5, -0.5) #y轴范围#遍历坐标轴的所有边框线for spine in ax.spines.values():spine.set_visible(False) #隐藏#去掉刻度线ax.tick_params(top=False, bottom=False, left=False, right=False)ax.set_xticks(range(4)) #设置x轴的刻度位置ax.set_yticks(range(4)) #设置y轴的刻度位置labels = ['F1', 'F2', 'F3', 'F4'] #定义混淆矩阵轴标签名称#设置轴标注字体ax.set_xticklabels(labels, fontsize=14, fontweight='bold')ax.set_yticklabels(labels, fontsize=14, fontweight='bold')#设置轴标题ax.set_xlabel('Predicted label', fontsize=16, fontweight='bold', labelpad=10)ax.set_ylabel('True label', fontsize=16, fontweight='bold', labelpad=10)ax.text(-0.15, 1.05, letter, transform=ax.transAxes, fontsize=30, fontweight='bold', va='center', ha='right')sm = plt.cm.ScalarMappable(cmap=cmap, norm=norm) #创建用于颜色条对象sm.set_array([]) #初始化空数组,以便生成颜色条# 添加颜色条cbar = fig.colorbar(sm, ax=ax, fraction=0.046, pad=0.04)cbar.outline.set_visible(False) #隐藏颜色条外边框cbar.ax.tick_params(size=0, labelsize=14, pad=8) #隐藏颜色条的刻度线label.set_fontweight('bold')
第六部分
# =========================================================================================# ======================================6.绘制性能指标可视化表格=========================================# =========================================================================================def plot_metrics_table(train_vals, test_vals, letter):#创建画布fig, ax = plt.subplots(figsize=(8, 4.2))ax.set_xlim(0, 10) #x轴范围ax.set_ylim(-0.2, 6.2) #y轴范围ax.axis('off') #只保留画布纯白背景bg_header = global_scheme['table_header'] #表头的背景颜色row_colors = global_scheme['table_rows'] #表格各行的交替颜色元组列表metrics_names = ['F1 Score', 'AP', 'AUC', 'Sensitivity', 'Specificity'] #要展示的5个性能指标的名称#添加表头文本ax.text(0.6, 5.55, letter, fontsize=28, fontweight='bold', color='black', va='center', ha='center')ax.text(2.0, 5.55, 'Metric', fontsize=18, fontweight='bold', color='white', va='center', ha='center')ax.text(5.25, 5.55, 'Training', fontsize=18, fontweight='bold', color='white', va='center', ha='center')ax.text(8.35, 5.55, 'Test', fontsize=18, fontweight='bold', color='white', va='center', ha='center')#第一列指标名称ax.text(2.0, #xy_base + 0.45, #ymetrics_names[i], #指标名称fontsize=16, #字号color='black', #字体颜色va='center', #垂直对齐#训练集ax.text(5.25, #xy_base + 0.45, # Yf"{m_tr:.2f} ± {s_tr:.2f}", #数值fontsize=16, #大小color='black', #字体颜色va='center', #垂直对齐ha='center') #水平对齐#测试集ax.text(8.35, #xy_base + 0.45, #yf"{m_te:.2f} ± {s_te:.2f}", #文本fontsize=16, #字体大小color='black', #字体颜色va='center', #垂直对齐ha='center') #水平对齐plt.subplots_adjust(left=0.01, right=0.99, top=0.99, bottom=0.01) #调整边距
第七部分
# =========================================================================================# ======================================7.SHAP 特征重要性热图=========================================# =========================================================================================def plot_shap_feature_importance(shap_data, features, letter):# 创建画布fig, ax = plt.subplots(figsize=(11, 4))cmap = LinearSegmentedColormap.from_list('custom_cm', global_scheme['cmap'], N=256) #创建渐变色norm = Normalize(vmin=0, vmax=1.0) #映射到指定范围内n_features = len(features) #特征的总数量ax.set_xlim(-0.5, n_features - 0.5) #x轴范围ax.set_ylim(3.5, -0.5) #y轴#去掉框线for spine in ax.spines.values():spine.set_visible(False)#配置轴刻度参数ax.tick_params(axis='both', #两个轴which='both', #应用于主刻度及副刻度length=0, #长度top=False, #关闭顶部刻度线bottom=False, #关闭底部刻度线left=False, #关闭左侧刻度线right=False) #关闭右侧刻度线ax.set_xticks(range(n_features)) #设置x轴的标签位置ax.xaxis.tick_top() #x轴的特征名称转移到图表正上方显示#设置x轴顶部的文本ax.set_xticklabels(features, #特征名rotation=45, #旋转ha='left', #水平对齐va='bottom', #垂直对齐fontsize=14, #字体大小fontweight='bold') #加粗ax.set_yticks(range(4)) #设置y轴刻度labels = ['Fraction 1', 'Fraction 2', 'Fraction 3', 'Fraction 4'] #设置四个组分的标签名#设置y轴名称ax.set_yticklabels(labels, #内蓉rotation=45, #旋转ha='right', #水平对齐va='center', #垂直fontsize=14, #大小fontweight='bold') #加粗#添加主标题ax.text(0.5, #x1.4, #y"SHAP feature importance across fractions", #内容transform=ax.transAxes, #坐标系fontsize=20, #字体fontweight='bold', #加粗ha='center', #水平va='bottom') #垂直#子图编号ax.text(-0.05, #x1.4, #yletter, #文本transform=ax.transAxes, #坐标系fontsize=26, #字体大小fontweight='bold', # 标记加粗va='bottom', #垂直ha='right') #水平for label in cbar.ax.get_yticklabels(): # 遍历获取颜色条所有的标签文本label.set_fontweight('bold') # 把标签字体全部调成粗体
第八部分
# =========================================================================================# ======================================8.SHAP 特征重要性蜂巢图=========================================# =========================================================================================def plot_single_shap_summary(sv, features_data, feature_names, fraction_idx, letter):#画布fig, ax = plt.subplots(figsize=(7.5, 6))cmap = LinearSegmentedColormap.from_list('custom_cm', global_scheme['cmap'], N=256)#创建渐变色mean_abs = np.abs(sv).mean(axis=0) #对每一特征的SHAP值求绝对值后算平均数#纵向基准线ax.axvline(x=0, #xcolor='gray', #色linewidth=1, #宽度linestyle='-', #样式zorder=0)ax.set_yticks(range(len(feature_names))) #Y刻度数ordered_names = [feature_names[idx].replace('\n', ' ') for idx in order] #提取排好序的特征名称并将换行符还原为空格#y轴标签ax.set_yticklabels(ordered_names, fontsize=14, fontweight='bold', ha='right')ax.tick_params(axis='y', length=0) #隐藏Y轴刻度线ax.set_xlabel("SHAP value", fontsize=16, fontweight='bold') #X轴标题ax.tick_params(axis='x', labelsize=13, width=2, length=5) #X轴刻度#x轴刻度字体加粗for label in ax.get_xticklabels():label.set_fontweight('bold')#设置边框线ax.spines['top'].set_visible(False)ax.spines['right'].set_visible(False)ax.spines['left'].set_visible(False)ax.spines['bottom'].set_linewidth(2)#子图编号ax.text(-0.05, #x1.05, #yletter, #子图编号transform=ax.transAxes, #坐标系fontsize=26, #大小fontweight='bold', #加粗va='bottom', #垂直ha='right') #水平#图名框属性bbox_props = dict(boxstyle="round,pad=0.4,rounding_size=0.2", #框体属性ec="#4f4f8c", #边颜色fc="none", #填充色lw=2.5, #边线粗细linestyle="--") #线条样式#图名ax.text(0.8, #x0.1, #yf"Fraction {fraction_idx + 1}", #内容transform=ax.transAxes, #坐标系fontsize=16, #字体大小fontweight='bold', #加粗ha='center', #水平va='center', #垂直bbox=bbox_props) #应用属性plt.subplots_adjust(left=0.25, right=0.85, top=0.9, bottom=0.15) #边距
第九部分
# =================================================================================================# ======================================9.单特征依赖图绘制函数=========================================# =================================================================================================def plot_single_shap_dependence(sv, features_data, feature_names, feature_idx, interaction_idx, fraction_idx,letter):#创建画布fig, ax = plt.subplots(figsize=(7.5, 6))cmap = LinearSegmentedColormap.from_list('custom_cm', global_scheme['cmap'],N=256) #自定义线性颜色映射对象x_vals = features_data[:, feature_idx] #特征数据,作为X轴的值y_vals = sv[:, feature_idx] #SHAP值,作为Y轴的值c_vals = features_data[:, interaction_idx] #关联特征,用于决定散点的颜色norm = Normalize(vmin=c_vals.min(), vmax=c_vals.max()) #创建归一化对象,将交互特征数据的值映射到区间内color_vals = cmap(norm(c_vals)) #每个散点对应的具体颜色#y=0的水平参考线ax.axhline(y=0, color='gray', linewidth=1, linestyle='--', zorder=0)feat_name = feature_names[feature_idx].replace('\n', ' ') #主要特征的名称ax.set_xlabel(feat_name, fontsize=16, fontweight='bold') #设置X轴标题ax.set_ylabel("SHAP value", fontsize=16, fontweight='bold') #Y轴标题#配置X轴和Y轴的刻度线参数ax.tick_params(axis='both', labelsize=13, width=2, length=5)#设置刻度标签粗细for label in ax.get_xticklabels() + ax.get_yticklabels():label.set_fontweight('bold')#设置边框ax.spines['top'].set_visible(False)ax.spines['right'].set_visible(False)ax.spines['left'].set_linewidth(2)ax.spines['bottom'].set_linewidth(2)#添加文本ax.text(0.8, #X0.9, #Yf"Fraction {fraction_idx + 1}", #文本内容transform=ax.transAxes, #坐标系fontsize=16, #字体大小fontweight='bold', #粗ha='center', #水平va='center', #垂直bbox=bbox_props) #样式plt.subplots_adjust(left=0.15, right=0.85, top=0.9, bottom=0.15) #调整子图的内边距布局cbar.ax.set_ylabel(f"{inter_name}", fontsize=16, fontweight='bold',labelpad=15)
第十部分
# =================================================================================================# ======================================11.执行部分=====================================================# =================================================================================================if __name__ == '__main__':#目录base_dir = r"性能表现"data_path = os.path.join(base_dir, "data.xlsx") # 数据路径df = pd.read_excel(data_path) # 读取target_col = 'Label' # 目标变量X = df.drop(columns=[target_col]).values # 特征数据y = df[target_col].values # 提取目标变量数据tprs_train = {i: [] for i in range(n_classes)} # 用于记录每次迭代中各个类别在训练集上的TPRaucs_train = {i: [] for i in range(n_classes)} # 用于记录每次迭代中各个类别在训练集上的AUC值tprs_test = {i: [] for i in range(n_classes)} # 用于记录每次迭代中各个类别在测试集上的TPR# 设置模型训练和评估的全局总迭代轮数n_iterations = 15# 超参数范围param_grid = {'max_depth': [3, 5],'learning_rate': [0.05, 0.1],'n_estimators': [50, 100]}
第十一部分
# 外层大循环,根据设定的迭代次数重复进行数据划分和模型训练for iteration in range(n_iterations):# 划分训练集与测试集,使用分层抽样保持类别比例,利用迭代次数作为随机种子保证可重复性X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=iteration)# 标准化处理scaler = StandardScaler()X_train_scaled = scaler.fit_transform(X_train)X_test_scaled = scaler.transform(X_test)# 根据训练集的标签分布计算样本权重,给予少数类更高的权重以缓解类别不平衡问题sample_weights = compute_sample_weight(class_weight='balanced', y=y_train)# 实例化XGBoost分类器xgb_base = XGBClassifier(objective='multi:softprob', # 设置目标函数为输出多分类概率num_class=n_classes, # 分类任务的类别总数eval_metric='mlogloss', # 评估指标random_state=iteration, # 随机种子n_jobs=-1) # 使用的CPU# 实例化网格搜索grid_search = GridSearchCV(estimator=xgb_base, param_grid=param_grid, cv=3, scoring='neg_log_loss', n_jobs=-1)# 执行网格搜索grid_search.fit(X_train_scaled, y_train, sample_weight=sample_weights)xgb_model = grid_search.best_estimator_ # 提取出表现最优的模型y_train_prob = xgb_model.predict_proba(X_train_scaled) # 在训练集上进行预测y_test_prob = xgb_model.predict_proba(X_test_scaled) # 在测试集上进行预测y_train_bin = label_binarize(y_train, classes=[0, 1, 2, 3]) # 将训练集的原始离散标签二值化为多个 0/1 组成的独热矩阵,为后续绘制各类别的 ROC 曲线做准备y_test_bin = label_binarize(y_test, classes=[0, 1, 2, 3]) # 对测试集标签执行相同的二值化操作# 获取当前轮次的硬分类预测标签y_train_pred_iter = np.argmax(y_train_prob, axis=1)y_test_pred_iter = np.argmax(y_test_prob, axis=1)# 获取当前轮次的测试集 Macro F1current_test_f1 = f1_score(y_test, y_test_pred_iter, average='macro')# 判断并保存全局最优模型(用于最终的 SHAP 解释)if current_test_f1 > best_test_f1:best_test_f1 = current_test_f1best_iteration_idx = iterationxgb_model_best = xgb_modelX_test_scaled_best = X_test_scaledX_test_best = X_testbest_params_overall = grid_search.best_params_
第十二部分
# 绘制ROC曲线图plot_single_roc(tprs_train, aucs_train, "Training", "a")plot_single_roc(tprs_test, aucs_test, "Test", "b")# 使用15次迭代累加后求平均的混淆矩阵(四舍五入为整数)cm_train_mean = np.round(cm_train_accumulated / n_iterations).astype(int) # 训练集的平均混淆矩阵cm_test_mean = np.round(cm_test_accumulated / n_iterations).astype(int) # 测试集的平均混淆矩阵train_metrics = [(np.mean(metrics_history_train[k]), np.std(metrics_history_train[k])) for k in metrics_keys]test_metrcs = [(np.mean(metrics_history_test[k]), np.std(metrics_history_test[k])) for k in metrics_keys]# 调用绘图函数plot_metrics_table(train_metrics, test_metrics, "e")print("\n正在计算真实的 SHAP 特征重要性...")shap_min, shap_max = mean_abs_shap.min(), mean_abs_shap.max() # 提取最小值与最大值# 对平均绝对 SHAP 值进行极差归一化处理normalized_shap = 0 + 1 * (mean_abs_shap - shap_min) / (shap_max - shap_min) if shap_max > shap_min else mean_abs_shapfeature_names = df.drop(columns=[target_col]).columns.tolist() # 获取各个特征原本的列名列表# 调用绘图函数,绘制 SHAP 总体特征重要性热力图plot_shap_feature_importance(normalized_shap, feature_names, "a")# 遍历所有类别for i in range(n_classes):# 提取当前类别的SHAP值sv_class = shap_values[i] if isinstance(shap_values, list) else shap_values[:, :, i]mean_abs = np.abs(sv_class).mean(axis=0) # 计算当前类别中,每个特征的平均绝对 SHAP 值以评估重要性order = np.argsort(mean_abs)[::-1] # 针对求得的重要性平均值进行降序排列,获取其对应特征的原始排序索引top1_idx = order[0] # 重要的特征索引top2_idx = order[1] # 第二重要的特征索引# 调用函数绘制SHAP依赖图plot_single_shap_dependence(sv_class, X_test_best, feature_names, feature_idx=top1_idx,interaction_idx=top2_idx, fraction_idx=i, letter=letters_dependence[i])
如何应用到你自己的数据
1.类别数量:
n_classes = 4 #定义分类任务的类别总数量2.设置配色:
SCHEME_ID = 60 #设置当前使用的配色方案3.设置绘制结果的保存地址:
plt.savefig(fr"{title_text}_{SCHEME_ID}ROC.pdf",bbox_inches='tight')4.设置原始数据的保存路径:
base_dir = r"整体性能表现"5.设置目标变量:
target_col = 'Label' # 目标变量6.设置迭代次数:
n_iterations = 157.设置超参数的网格:
param_grid = { 'max_depth': [3, 5], 'learning_rate': [0.05, 0.1], 'n_estimators': [50, 100]}推荐
获取方式
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

