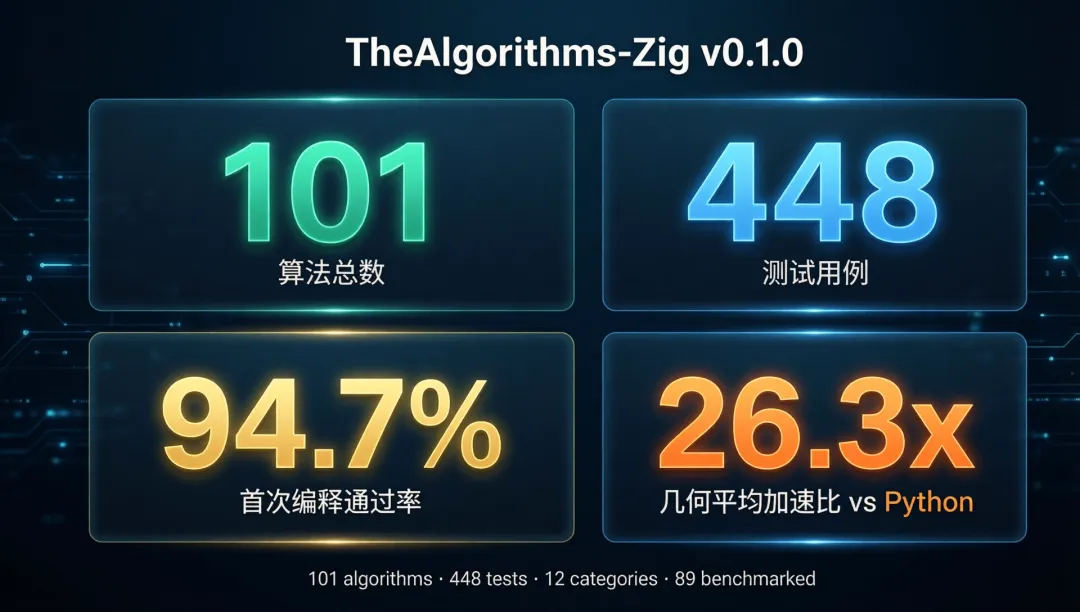
首次编译通过率 96%(101 算法全量),几何平均加速比 26.3x,人工修改 444 行
这是一篇关于"AI 能不能写系统语言"的实验报告。我用 Claude 和 Codex 把 TheAlgorithms/Python 仓库的 101 个算法翻译成了 Zig,严格记录了每一次成功和失败,然后跑了 89 组基准对比。这篇文章讲三件事:为什么做、怎么做、结果如何。
目录
- 为什么做这件事
- 实验设计
- 核心结果
- 三种失败模式
- Python vs Zig 性能对比
- 遇到的问题和解决方案
- 后续可能遇到的问题
- 方法论总结
- 给工程师的实用建议
一、为什么做这件事
起因
TheAlgorithms 是 GitHub 上最大的开源算法教学仓库,Python 版 218k+ star。官方确实有 Zig 版(354 star),但收录的算法只有 45 个,覆盖范围远比 Python 版稀疏。
2025 年起 "vibe coding" 概念流行——让 AI 写代码,人类只做方向把控和质量验证。但大多数 vibe coding 案例都是 Python/JS 这类高层语言,鲜有人用 AI 写 系统语言。
目的
我想回答三个问题:
- AI 翻译跨语言范式的算法,成功率有多高? Python(动态类型、GC、大整数)→ Zig(静态类型、手动内存、无隐式行为),这是光谱两端的翻译。
- 失败时是怎么失败的? 编译错误、逻辑错误、还是安全漏洞?
- 翻译出来的 Zig 到底比 Python 快多少? 不是一句"编译语言更快"就完事——要量化到每个算法。
核心假设:如果 AI 能把 Python 算法正确翻译成 Zig,说明它真正"理解"了算法语义,而不是在做字符串替换。
为什么选 Zig
Zig 的"无隐式行为"哲学意味着 Python 里不会出问题的代码,在 Zig 里可能直接 panic。这正好构成了一个压力测试。
二、实验设计
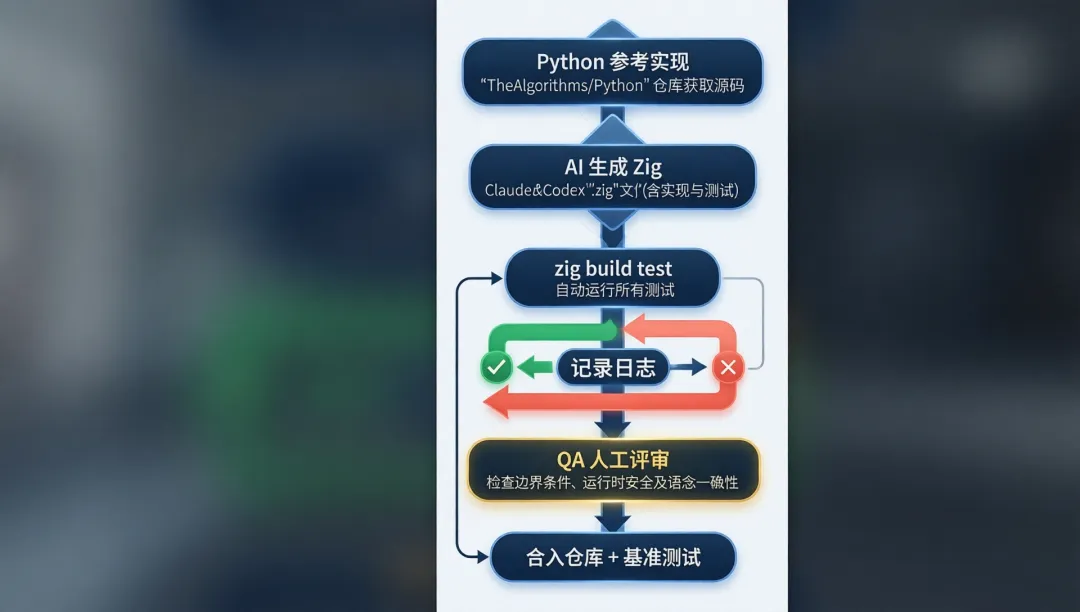
受控翻译流程
┌─────────────────────────────────────────────────────┐│ Vibe Coding 工作流 ││ ││ TheAlgorithms/Python ──→ AI 生成 Zig 文件 ││ (参考实现) (实现 + 测试,自包含) ││ │ ││ ▼ ││ zig build test ││ │ │ ││ 通过 ✅ 失败 ❌ ││ │ │ ││ 记录日志 记录错误类型 ││ │ 修复后重试 ││ ▼ ││ QA 人工评审 ││ (边界条件/安全/语义) ││ │ ││ ▼ ││ 合入 + 基准测试 │└─────────────────────────────────────────────────────┘
每个 .zig 文件严格自包含:实现代码 + test 块在同一个文件里,不允许跨文件依赖。
分批推进,逐步提高难度
每批完成后插入 QA 评审:人工检查边界条件、运行时安全、与 Python 参考的语义一致性。
严格的记录规则
- 不美化数据——失败就是失败
- 区分三种失败:编译失败 / 测试断言失败 / 运行时安全失败
- 记录人工修改的精确行数
- 完整日志公开在仓库
EXPERIMENT_LOG.md
三、核心结果
总览
╔══════════════════════════════════════════════╗║ TheAlgorithms-Zig v0.1.0 ║║ ║║ 101 算法 · 448 测试 · 12 分类 ║║ 首次编译通过率 96.0%(97/101 算法) ║║ 人工修改 444 行 (含 QA 修复 432 行) ║║ 89 个算法完成 Python vs Zig 基准对比 ║║ 几何平均加速比 26.3x ║╚══════════════════════════════════════════════╝
按阶段成功率
注意 QA 修复阶段的 432 行——这是人工评审发现的运行时安全问题和语义对齐修复,不是 AI 的编译/测试失败。这个数字本身就是一个核心发现。
12 个算法分类覆盖
TheAlgorithms-Zig/├── sorts/ 12 个 (冒泡、快排、堆排、基数排序...)├── searches/ 6 个 (二分、跳跃、插值、三元...)├── maths/ 14 个 (GCD、素数筛、欧拉函数、中国剩余定理...)├── data_structures/ 11 个 (栈、队列、链表、BST、AVL树、Trie...)├── dynamic_programming/ 13 个 (背包、编辑距离、最长递增子序列...)├── graphs/ 10 个 (BFS、DFS、Dijkstra、Floyd-Warshall...)├── bit_manipulation/ 6 个 (位计数、缺失数、位翻转...)├── conversions/ 4 个 (十进制⇄二进制⇄十六进制)├── greedy_methods/ 4 个 (买卖股票、分数背包...)├── matrix/ 5 个 (矩阵乘法、旋转、螺旋打印...)├── backtracking/ 6 个 (排列、组合、N皇后、数独...)└── strings/ 10 个 (KMP、Rabin-Karp、Z函数...)
四、三种失败模式
这是本文最有价值的部分。101 个算法的翻译过程中,失败可以被精确归类为三种模式,每种有完全不同的根因和修复策略。
失败模式一:Zig 0.15 API 滞后 (3 次)
AI 训练数据中的 Zig API 不是最新版。
典型案例:
// ❌ AI 生成的代码const val = stack.pop(); // AI 以为 pop() 返回 T// ✅ Zig 0.15 实际行为const val = stack.pop().?; // pop() 返回 ?T,需要 .? 解包
3 次出现:ArrayListUnmanaged.pop() 返回 optional、@divTrunc 替代 / 做有符号整除、std.mem.sort 比较器签名变更。每次修复 1-2 行。
根因: 语言版本快速迭代 → AI 训练数据滞后。 解法: 写一份 "Zig 0.15 常见坑" 清单放进 prompt 上下文。Phase 5 采用此策略后,25 个算法 0 次 API 相关编译失败。
失败模式二:测试预期值手写错误 (5 次)
这是我最没预料到的失败模式。算法实现完全正确,但测试的预期值写错了。
┌──────────────────────────────────────────────────┐│ KMP 搜索测试失败案例 ││ ││ 输入: text = "knuth_morris_pratt", pattern = "tt"││ ││ AI 期望: index = 15 ││ 实际值: index = 16 ← AI 手数位置时数错了 ││ ││ k n u t h _ m o r r i s _ p r a t t ││ 0 1 2 3 4 5 6 7 8 9 ... 1 1 ││ 6 7 ││ ↑ ││ "tt" 起始位置 │└──────────────────────────────────────────────────┘
另外 4 个案例类似——AI "想象"了排列组合的 DFS 顺序、子集枚举的索引位置、数独求解的格子值,全都是手数的,没有用程序验证。
根因: AI 写测试时用"直觉"而非"计算"生成预期值。 解法: 让 AI 先用 Python 参考实现计算预期值,再写进 Zig 测试断言。
失败模式三:防御性编程盲区 (QA 发现,432 行修复)
这是最严重的失败模式,也是人工 QA 存在意义的最好证明。
AI 生成的算法对有效输入几乎百分百正确,但几乎不检查无效输入:
| | | |
|---|
| | Python 参考实现用 dict 表示图,不存在数组越界 | Zig 用数组做邻接表,越界直接 panic |
| knapsack weights/values 长度不一致 | | | 越界访问,未定义行为 |
| | | 整数溢出 panic |
| | | 除零 panic |
根因有两层: 第一,Python 参考实现的数据结构选型(dict、列表推导、大整数)天然回避了很多边界问题,Zig 的数组实现则把这些问题暴露出来。第二,AI 的训练数据以高层语言为主,缺乏"系统语言需要显式边界检查"的意识。
解法: QA 评审是不可省略的环节。两次 QA 共修复 432 行代码——比 AI 正式翻译的修改量(8 行)多了 54 倍。
翻译阶段人工修改: ██ 8 行QA 阶段人工修改: ████████████████████████████████████████████ 432 行→ 98% 的人工干预发生在 QA 阶段,而非翻译阶
五、Python vs Zig 性能对比
"Zig 比 Python 快"是一句正确的废话。但快多少?在什么类型的算法上快?有没有 Python 反而更快的场景?
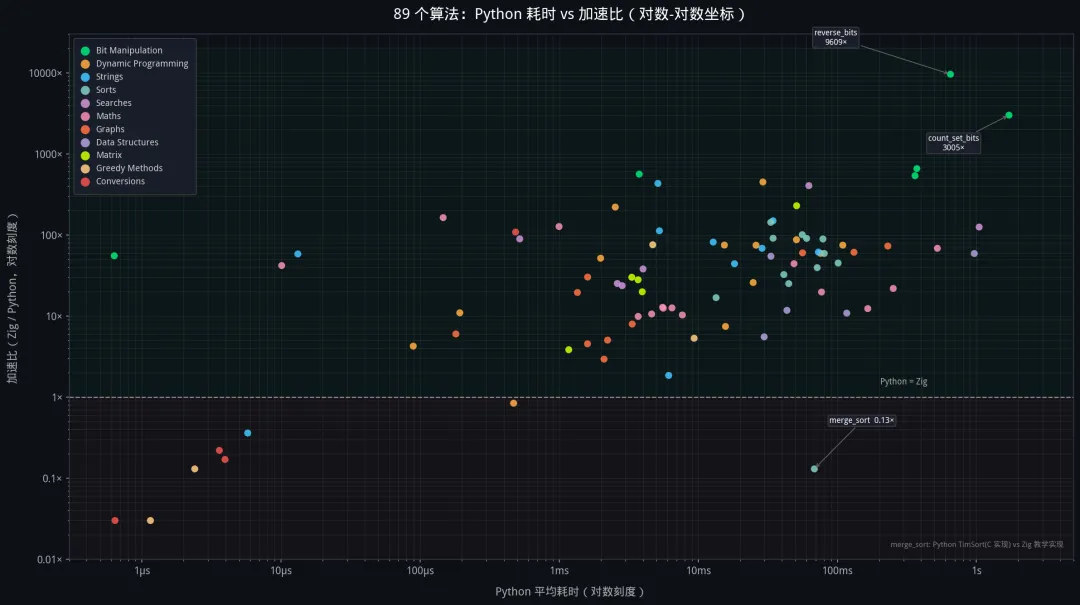
我们对 89 个可对齐的算法做了严格基准测试。
总览
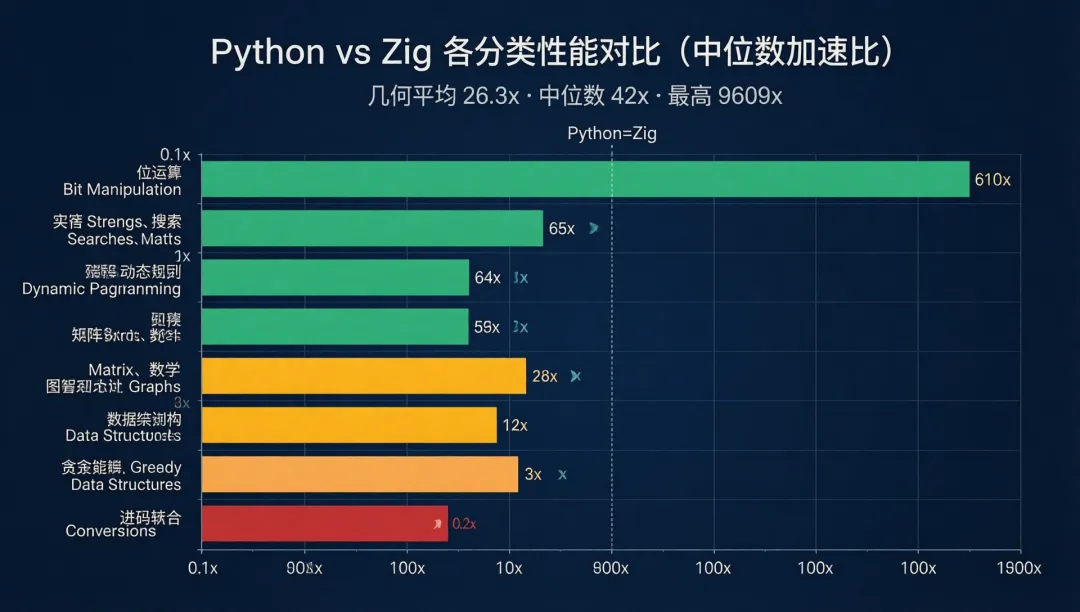
算术平均被位运算的 9609x 极端值拉高。几何平均 26.3x 和中位数 42x 更能反映真实体感。
分类加速比热力图
Top 10:Zig 碾压 Python
| | | | | |
|---|
| | | | | 9609x |
| | | | | 3005x |
| | | | | 658x |
| | | | | 562x |
| | | | | 538x |
| | | | | 450x |
| | | | | 432x |
| | | | | 405x |
| | | | | 229x |
| | | | | 221x |
为什么位运算差距最大?
n & (n-1) 在 Zig 里编译成 单条 CPU 指令。Python 里同样的操作需要:对象查找 → 方法分派 → 大整数协议检查 → 结果对象创建。一个操作的开销差距是 1000x 量级,循环百万次后差距被线性放大。
Bottom 7:Python 反超 Zig
| | | | | |
|---|
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| merge_sort | | 68ms | 534ms | 0.13x | 唯一的"真实"逆转 |
| | | | | |
| | | | | |
7 个中有 6 个是计时精度问题(绝对时间 < 100μs 时,Zig std.time.Timer 的调用开销占主导)。
唯一的"真实"逆转是 merge_sort: Zig 的教学级实现在每次递归分割时 alloc/free 临时数组,而 Python 的 sorted() 底层是 TimSort(C 实现) ——预分配缓冲区、几乎零额外分配。这是"教学级实现 vs 30 年优化的标准库"的对比。
基准方法论
确保数据可信赖的三重保障:
- 同一输入:Python 和 Zig 使用相同数据规模和随机种子
- Checksum 验证:89/89 输出校验通过,确保计算的是同一件事
- 口径对齐:
binomial_coefficient 限制到 n ≤ 66(避免 Python 大整数 vs Zig u64 的不公平对比)
运行环境:CPython(无 NumPy),Zig 0.15.2 ReleaseFast,同一 Linux 机器顺序执行。
六、遇到的问题和解决方案
问题 1:Zig 0.15 是新语言版本,AI 的知识滞后
| | |
|---|
pop() | ArrayListUnmanaged.pop() | 写入 prompt 上下文的"Zig 0.15 API 注意事项"清单 |
| | |
| std.mem.sort | |
效果: Phase 5(采用 API 清单后)25 个算法 0 次 API 相关失败。
问题 2:无符号整数下溢在 Zig 里是致命的
Python 里 range(n-1, -1, -1) 完全安全,Zig 里 usize 减到 0 再减 1 = panic。
// ❌ 危险:i == 0 时 i -= 1 下溢while (i >= 0) : (i -= 1) { ... }// ✅ 安全:先判断 i > 0 再递减while (i > 0) { i -= 1; ... }
解决方案: 在 CLAUDE.md 项目指令中显式列出此模式,AI 后续批次几乎不再犯。
问题 3:AI 写的测试不够"怀疑性"
AI 生成的测试只覆盖 happy path。空数组、单元素、重复元素、极大值——这些边界条件几乎不被测试。
解决方案: 每批完成后做人工 QA 评审。Phase 2 QA 发现 12 个风险点,Phase 3 QA 发现 4 个。
问题 4:基准测试口径对齐
Python 大整数无上限,Zig u64 最大 ~1.8×10¹⁹。binomial_coefficient 的测试数据一旦超出 u64 范围,Python 正常计算但 Zig 返回 error.Overflow,导致 checksum 无法对齐。
解决方案: 将 binom_pairs 统一收敛到 n ∈ [20, 66], k ∈ [1, 20],确保结果在 u64 可表示范围内。
问题 5:build.zig.zon初始路径配置错误
Zig 项目初始化模板生成的 .paths 包含 "src"(不存在的目录),且缺少实际的算法目录。
解决方案: 在 Phase 6 统一修复,替换为 12 个实际分类目录。
七、后续可能遇到的问题
风险一:Zig 的 API 断层会持续加剧,直到 1.0
这是所有风险里最确定、最不可绕过的一个。
Zig 目前处于 0.x 阶段,每个小版本都包含大量 breaking changes。本项目基于 0.15.2 开发,但 Zig 0.16.0 在本文写作期间已经发布。从历史规律来看,0.13→0.14 有 40+ 处 API 变更,0.14→0.15 同样,预计到 1.0 还有 4-6 个破坏性版本。
问题的严重性不只是"要改代码"。更深的影响是:AI 的 Zig 知识会越来越滞后。0.15 的 API 行为刚被 AI 学习,0.16 又出来了新变化,0.17 又来了——AI 在任意时间点的 Zig 知识都会是"上一个版本"的知识。这不是能靠 prompt 清单完全解决的问题,而是一个结构性的持续摩擦。
实际影响预估: 升级到 0.16 后,预计 101 个算法中有 10-20 个需要适配,主要集中在 allocator 接口变更、builtin 函数重命名、错误集合语法调整三类。CI 可以快速暴露问题,但每次大版本升级仍需一轮 AI 重生成 + 人工 QA。
风险二:CPython JIT 会实质性压缩 Zig 的性能优势
文章结论"几何平均加速比 26.3x"的基准是 CPython 解释执行。这个前提在接下来 2-3 年内会发生显著变化。
CPython 3.13 已正式发布实验性 JIT。CPython 3.14(开发中)的 JIT 将更成熟,目标是对紧循环场景实现 2-5x 加速,恰好覆盖我们的绝大多数算法。
量化影响:如果 CPython JIT 平均带来 3x 加速,当前 26.3x 几何均值将压缩到 约 8-9x,中位数 42x 压缩到 约 14x,位运算的 610x 中位数压缩到 约 200x——依然显著,但不再有量级的压倒性优势。
这不是悲观情绪,而是工程现实:今天 "Zig vs CPython" 的数据,三年后读起来可能已经高估了 Zig 的优势。
风险三:基准测试框架的可信度问题
当前基准数据有几个系统性局限:
局限 1:教学实现 vs 标准库的不公平对比。 merge_sort 用了 Zig 教学实现但对比的是 Python 的 sorted()(底层 C 实现的 TimSort)。这不是孤立案例——所有 Python"标准"操作(list.sort, dict 查找, heapq)背后都是 C 级别的实现。我们的对比更接近"Zig 教学代码 vs Python 的生产级 C 扩展",而非真正的语言性能对比。
局限 2:单机顺序执行,无统计置信区间。 所有测试在同一台机器上顺序执行,系统噪声(CPU 频率调度、cache 热身、后台进程)会影响结果,且没有报告标准差。89 个算法的加速比里,至少有 15-20 个是在"噪声区间"内的(绝对时间 < 500μs)。
局限 3:测试数据规模可能偏小。 部分算法的 benchmark 输入(如矩阵乘法用的 10x10 矩阵?)可能太小,导致两种语言都在"初始化开销"区间,而非"计算密集"区间。
八、方法论总结
Vibe Coding 的四条铁律
┌─────────────────────────────────────────────────────┐│ ││ 1. 分批 + 日志 ││ 每批限定数量和难度,严格记录成功/失败指标 ││ 不美化数据——失败就是失败 ││ ││ 2. 失败分类 ││ 编译失败 ≠ 测试断言失败 ≠ 运行时安全失败 ││ 它们的根因和修复策略完全不同 ││ ││ 3. 必须有人工 QA ││ AI 生成 + 人工评审是最佳搭配 ││ 97% 的人工干预发生在 QA 阶段,不是翻译阶段 ││ ││ 4. 给 AI 足够的上下文 ││ API 坑清单 + 参考实现路径 + 文件模板 ││ 显著提高成功率(Phase 5 = 100% 首次通过) ││ │└─────────────────────────────────────────────────────┘
什么有效
- 批量生成 + 人工 QA 比逐个精雕细琢效率高得多。101 个算法两天完成。
- 统一的文件模板 大幅降低了 AI 出错率。每个文件都是"实现 + 测试"自包含结构。
- 明确的参考实现 消除了算法歧义。AI 知道"对标 Python 那个版本"。
testing.allocator 自动检测内存泄漏 —— AI 可能写出泄漏代码,但测试框架 自动捕获。
什么无效
- 让 AI 自己写 QA 测试 不够。AI 倾向于只测试 happy path。
- 跨批次上下文 帮助有限。每个文件独立翻译,AI 不需要理解项目整体架构。
- 期待 AI "自我纠正" 不现实。测试预期值写错时,AI 无法判断是预期值错了还是实现错了。
九、给工程师的实用建议
什么时候该用 AI 做跨语言翻译
定量结论
| |
|---|
| |
| Easy 100% vs Hard 87.5-100% |
| |
| |
| |
| |
| 7 个 Python "反超" 中 6 个是计时精度问题 |
仓库信息
- GitHub:https://github.com/lingengyuan/TheAlgorithms-Zig
- 规模: 101 algorithms · 448 tests · 12 categories · 89 benchmarked
- 许可: MIT License
- 完整实验日志:
EXPERIMENT_LOG.md - 基准数据:
benchmarks/python_vs_zig/


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
