写在前面的话
为父则刚。昨天,君哥和我联系,让我帮他刷个单,成人用品方面的,说是帮朋友刷的。刷完单,告诉他金额,他找朋友要一下,再给我。单子完成之后,我发他截图,他秒转给我了,这让我有一种错觉,是不是君哥自己的生意,难道君哥开始卖成人用品了。君哥在我心中,编程方面是大神级的存在,有着南方人专属的聪慧和灵气,如今也转战实体经济了吗,但南方人可能对面子看的还是比较重的,我没有向君哥求证。不过,真是那样,也没啥,成人用品也是合法买卖,只是说出去不太好听而已,为了生活,又有利可图,做做也没事,就像很多人在家靠打游戏挣钱,在别人看来是不务正业,但实际上人家一天打十几个小时也很辛苦。所以,做自己喜欢的事就好,过好自己的生活,不要在意别人的看法。
[306]-------->底部有张生活照片和昨日花销
【关键词】python、服务器、可用带宽、回复截断
一、python接口相关(一级)
1.查服务器可用带宽(二级)
描述:现在服务器有点慢,查下具体多么慢,看能不能查下可用带宽,到达什么标准才可以测试。
开工:
第一步:测试(三级)
20250109周四时间段:11:07-11:20
查资料,搜索结果如下:
Linux:
使用 iftop(实时监控带宽使用):
安装:sudo apt install iftop 或 sudo yum install iftop。
运行:sudo iftop。
查看网络流量(显示进出带宽使用)。
使用 nload:
安装:sudo apt install nload。
运行:nload。
注:试下行不行。效果不是太好,看看是不是程序的事。
第二步:查看接收程序(三级)
20250109周四时间段:15:08-15:20
20250109周四时间段:15:20-15:40
20250109周四时间段:16:13-16:20
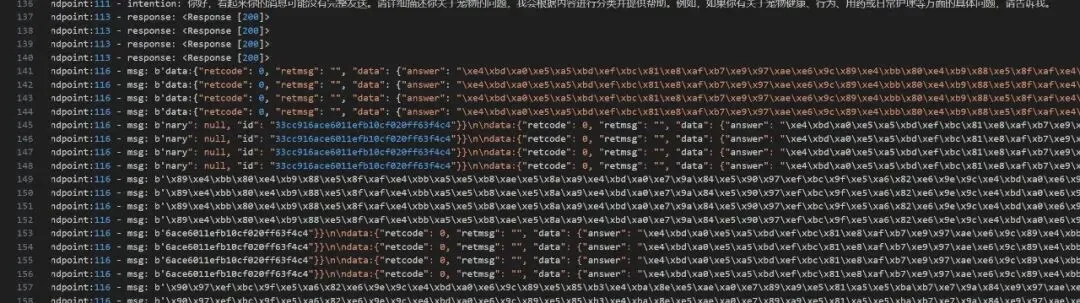
当发【你好你好】时,接收好像不正确,如下:
图7a-1
注:这个数据好像不是以/n/n结尾的,想着统一采用龙哥的方式,按行读取试试。
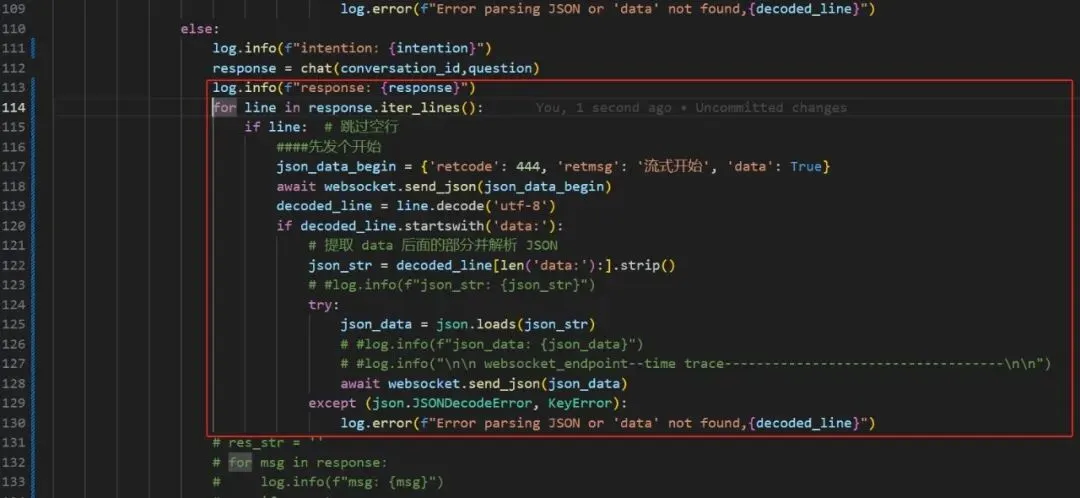
修改代码如下:
图7a-2
注:按行读取。测试一下看看效果。还可以,接下来,处理回答被截断问题,争取今天解决。就在本地处理,不要切来切去,跳来跳去。截图如下:
图7a-3
注:看下这个提示词,是不是没加字数控制。
第三步:查看提示词(三级)
20250109周四时间段:16:57-17:00
20250109周四时间段:17:00-17:20
20250109周四时间段:17:20-17:40
20250109周四时间段:17:40-18:00
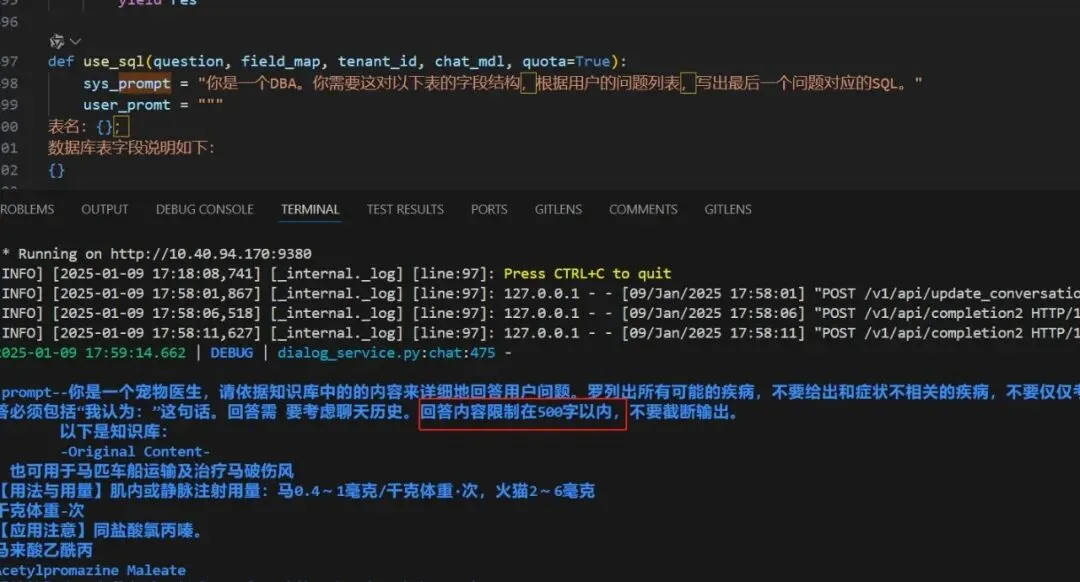
这个在要ragflow里面更改,更改后,查看到的提示词日志,截图如下:
图7a-4
注:看了一下,是有内容限制的,为啥输出内容还超500字呢。是不是这不是问通义千问呢,是不是这口 是个中间阶段,debug搞一下。
第四步:debug追踪提示词(三级)
20250109周四时间段:18:13-18:20
20250109周四时间段:18:28-18:40
20250109周四时间段:19:46-20:00
接下来,追踪一下,看看传一个问题过去,它是怎么演化的,有两个诉求,或者限制在500字以内,或者进行续问。
a.看阿里文档 (四级)
20250109周四时间段:19:49-20:00
20250109周四时间段:23:14-23:20
用的模型如下:
qwen-plus@Tongyi-Qianwen
注:大模型接口说明如下:
通义千问超大规模语言模型增强版,支持中文、英文等不同语言输入。
模型支持32k tokens上下文,为了保证正常的使用和输出,API限定用户输入为30k tokens。
注:接下来看看有没有接口说明。
b.寻找接口说明(四级)
20250109周四时间段:23:15-23:20
incremental_output
控制流式输出模式;即后续输出内容是否包含已输出的内容。设置为True时,将开启增量输出模式,后面输出不会包含已经输出的内容,您需要自行拼接整体输出;设置为False则会包含已输出的内容。您可以参考流式输出代码。
默认False:
I
I like
i like apple
True:
I
like
apple
该参数只能在stream为True时使用。
重要
incremental_output暂时无法和tools参数同时使用。
parameters.max_tokens
这个应该可以,解释如下:
用于限制模型生成token的数量,max_tokens设置的是生成上限,并不表示一定会生成这么多的token数量。其中qwen-turbo最大值和默认值为1500,qwen-max、qwen-max-1201 、qwen-max-longcontext 和 qwen-plus最大值和默认值均为2000。
注:接下来试试parameters.max_tokens。
c.试试parameters.max_tokens(四级)
20250109周四时间段:23:36-23:40
20250109周四时间段:23:41-00:00
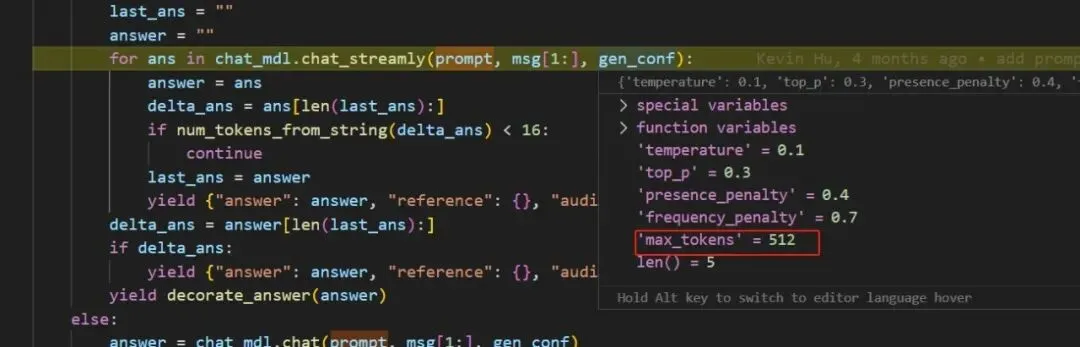
看一个debug截图,如下:
图7a-5
注:这个应该在数据库里改。
把512修改为256,如下:
{"temperature": 0.1, "top_p": 0.3, "presence_penalty": 0.4, "frequency_penalty": 0.7, "max_tokens": 256}注:接下来,再试试还会不会截断。
d.再聊天(四级)
20250109周四时间段:23:58-00:00
20250110周五时间段:09:21-09:40
20250110周五时间段:10:08-10:20
再聊天还是被截断,再查查接口,看看有没有其它的解决方案,再此之前,debug一下,看看max_tokes更改过来没有。看了一下,改过来了,再跑一遍试试。
e.再次聊天(四级)
20250110周五时间段:10:09-10:20
现在连不上,本地的连不上,截图如下:
图7a-6
注:按理说,本地连不上不合理,看下卡在哪里了。应该是chat_sev卡住了,重启一下。
2.回复截断(二级)
描述:现在回复老被截断,找下原因。
开工:
第一步:重启chat_sev(三级)
20250110周五时间段:10:19-10:20
20250110周五时间段:10:20-10:40
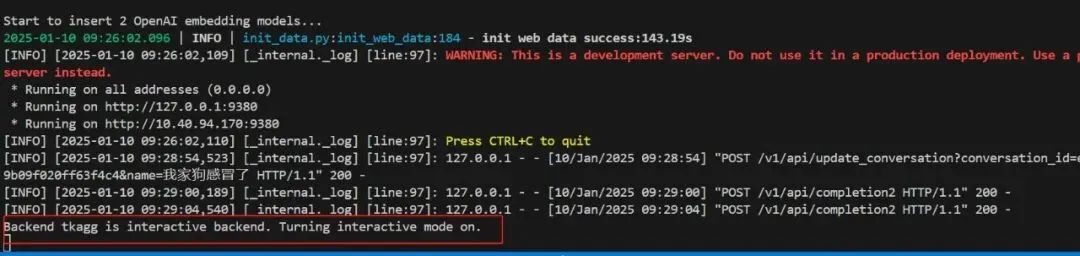
重启下确实好了,现在客户端能连上了。现在ragflow报了一个错,如下:
图7a-7
注:文字版本为
Backend tkagg is interactive backend. Turning interactive mode on.
查下ai看看啥意思,查结果如下,先不管,跑起来发现,还是有截断的情况,截图如下:
图7a-8
注:接下来,追踪下是怎么调知识库的。
第二步:调知识库(三级)
20250110周五时间段:11:04-11:20
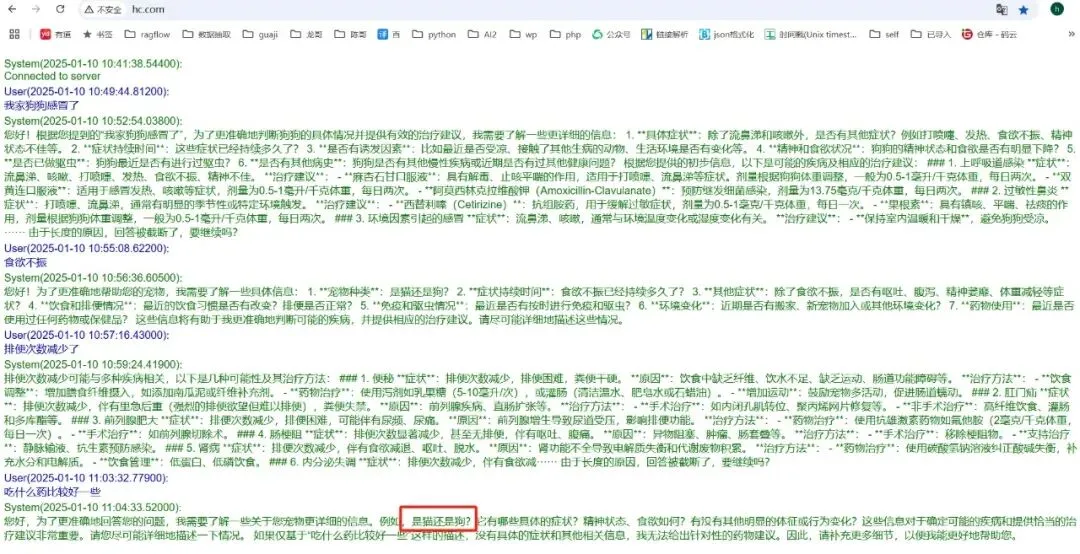
发现一个问题,就是没考虑上下文的问题,截图如下:
图7a-9
注:上文中说过,【我家狗狗感冒了】,它返回,是【猫还是狗】,这个要考虑历史记录的,排查一下。
第三步:考虑历史记录(三级)
20250110周五时间段:11:17-11:20
为什么没有考虑历史记录,需要排查一下。
二、生活照片
拍摄于2025年9月14日,17:04:14,带大宝去晨光买文具,当时大宝七岁九个月。给君哥刷单的后续是,君哥问我忙什么呢,我说在忙抖哥的项目,业余在和咱同事许哥讨论互联网上的变现机会,君哥很感兴趣,说是我这边学会了,可以带带他,他用技术的形式看能不能助力一下,我说可以啊,许哥这边虽说大部分靠人工,但像批量生成视频或下载视频之类的,有技术加持的话,将大大提高效率。聊天结束,觉得还是要消除刻板印象,哪天,一个大学教授摆摊卖皇碟了也不要惊讶,都是为了生活。
图7b-1
《本文完》


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
