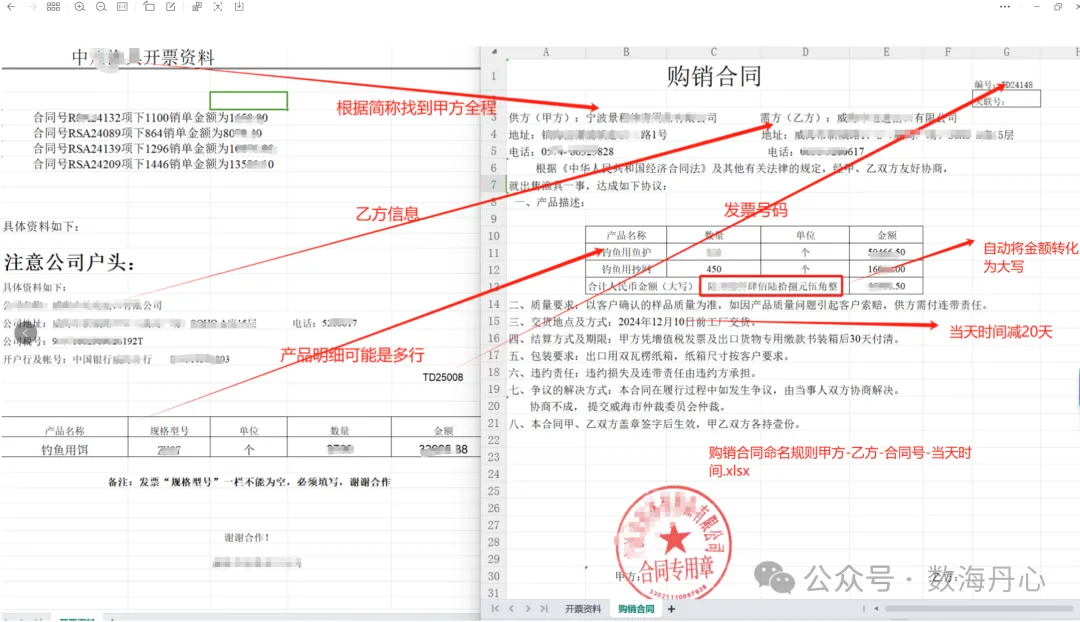
from datetime import datetime, timedeltaimport loggingimport osimport pandas as pdimport reimport numpy as npfrom openpyxl import load_workbookfrom openpyxl.styles import Font, Alignmentfrom openpyxl.styles import Border, Side# -------------------------- 配置区(仅修改这里即可,无需动核心代码)--------------------------LOG_LEVEL = logging.DEBUG # 日志级别(不用改)LOG_FILE = 'logs/app.log' # 日志文件路径(不用改,自动生成)TEMPLATE_PATH = './data/购销合同模板.xlsx' # 集团合同模板路径,替换成自己的路径FACTORY_INFO_PATH = './data/杂品工厂抬头信息.xlsx' # 工厂信息表路径,替换成自己的路径INPUT_DIRECTORY = './' # 开票资料所在目录,替换成自己的路径PARTY_A_INFO = { # 甲方信息,替换成自己公司的信息 "TD": {"name": "威海卓达进出口有限公司", "addr": "威海市新威路17-2(威高广场)SOHO A座15层", "phone": "0631-5280617", "short_name": "卓达"}, "MI": {"name": "威海名禾渔具有限公司", "addr": "威海市环翠区新威路17-2(威高广场SOHO A座)", "phone": "0631-5280617", "short_name": "铭禾"}}# ----------------------------------------------------------------------------------------# 创建日志目录(如果不存在)log_dir = os.path.dirname(LOG_FILE)if log_dir and not os.path.exists(log_dir): os.makedirs(log_dir)# 配置日志logging.basicConfig( filename=LOG_FILE, # 日志文件路径 level=LOG_LEVEL, # 日志级别 format='%(asctime)s - %(name)s - %(levelname)s - %(message)s', # 日志格式 datefmt='%Y-%m-%d %H:%M:%S' # 日期格式)def number_to_chinese_amount(number): """ 将阿拉伯数字转换为中文金额大写(无需修改,直接用) :param number: 数字(整数或浮点数) :return: 中文金额大写字符串 """ units = ['', '万', '亿'] digits = ['零', '壹', '贰', '叁', '肆', '伍', '陆', '柒', '捌', '玖'] scales = ['', '拾', '佰', '仟'] if not isinstance(number, (int, float)): return "无效输入" # 处理负数 if number < 0: return "负数不支持转换" # 分离整数和小数部分 number = round(number, 2) # 保留两位小数 integer_part, decimal_part = f"{number:.2f}".split('.') integer_part = int(integer_part) decimal_part = int(decimal_part) # 转换整数部分 def convert_integer(n): if n == 0: return digits[0] result = '' unit_index = 0 while n > 0: part = n % 10000 if part != 0: part_str = '' for i, digit in enumerate(str(part)[::-1]): if digit != '0': part_str = digits[int(digit)] + scales[i] + part_str else: if part_str and part_str[0] != digits[0]: part_str = digits[0] + part_str result = part_str + units[unit_index] + result else: if result and result[0] != digits[0]: result = digits[0] + result n = n // 10000 unit_index += 1 return result # 转换小数部分(角和分) def convert_decimal(n): if n == 0: return '整' jiao = n // 10 # 角 fen = n % 10 # 分 result = '' if jiao != 0: result += digits[jiao] + '角' if fen != 0: result += digits[fen] + '分' return result # 组合结果 chinese_integer = convert_integer(integer_part) chinese_decimal = convert_decimal(decimal_part) return chinese_integer + '元' + chinese_decimaldef is_factory_in_column_name(factory_name, column_names): """判断工厂简称是否在列名中(无需修改)""" return any(factory_name in str(col) for col in column_names)def get_date(): """获取所需日期(无需修改)""" today = datetime.now() today_str = today.strftime('%Y-%m-%d') # 获取前20天、前5个月日期(适配合同交付、签订时间,可根据需求修改天数) five_months_ago = today - timedelta(days=5 * 30) # 近似计算,每月按30天 five_months_ago_str = five_months_ago.strftime('%Y-%m-%d') twenty_days_ago = today - timedelta(days=20) twenty_days_ago_str = twenty_days_ago.strftime('%Y-%m-%d') return twenty_days_ago_str, five_months_ago_str, today_strdef deal_with_input(file_path): """解析开票资料,提取所需信息(无需修改)""" result_data = {} result_data["delivery_time"], result_data["sign_time"], result_data["today_time"] = get_date() # 读取开票资料(兼容.xls和.xlsx格式) if file_path.endswith('.xls'): data = pd.read_excel(file_path, engine='xlrd', header=None) else: data = pd.read_excel(file_path, header=None) # 定位第一行非空行,作为列名 first_non_empty_row = data.dropna(how='all').index[0] data.columns = data.iloc[first_non_empty_row] data = data.iloc[first_non_empty_row + 1:].reset_index(drop=True) # 清洗数据,去除空行空列 data_no_na = data.dropna(how='all').reset_index(drop=True) df = data_no_na # 定位并提取产品明细(关键词可根据需求修改) start_index = df[df.apply(lambda row: row.astype(str).str.contains('品名|产品名称').any(), axis=1)].index[0] end_index = df[df.apply(lambda row: row.astype(str).str.contains('备注|备注说明').any(), axis=1)].index[0] prod_infos = data_no_na.iloc[start_index:end_index] prod_infos.columns = prod_infos.iloc[0] prod_infos = prod_infos[1:].reset_index(drop=True) # 删除可能残留的“品名”行,清洗明细数据 mask = prod_infos.apply(lambda row: row.astype(str).str.contains('品名|产品名称').any(), axis=1) prod_infos = prod_infos[~mask].dropna(axis=1, how='all').reset_index(drop=True) # 汇总金额并转换为中文大写 total_amount = prod_infos['金额'].sum() chinese_amount = number_to_chinese_amount(total_amount) # 添加金额汇总行 new_row = [f"合计人民币金额(大写):{chinese_amount}"] + [np.nan] * (len(prod_infos.columns) - 2) + [total_amount] prod_infos.loc[len(prod_infos)] = new_row result_data["prod_infos"] = prod_infos # 提取合同号(正则规则可根据需求修改) pattern = r'(TD\d{5}|MI\d{5})' matches = df.applymap(lambda x: re.findall(pattern, str(x))).stack().tolist() unique_matches = list(set([item for sublist in matches for item in sublist])) # 匹配甲方信息 if len(unique_matches) == 1: result_data["contract_num"] = unique_matches[0] prefix = "TD" if "TD" in unique_matches[0] else "MI" result_data["partyA_info"] = PARTY_A_INFO[prefix] result_data["partyA_name"] = PARTY_A_INFO[prefix]["short_name"] # 匹配乙方信息(工厂信息表) df_factory = pd.read_excel(FACTORY_INFO_PATH, header=0) result_flag = df_factory['工厂简称'].apply(is_factory_in_column_name, column_names=df.columns) partyB_infos = df_factory[result_flag].iloc[0].to_dict() result_data["partyB_info"] = partyB_infos return result_datadef write_excel(data): """将提取的信息写入合同模板(无需修改)""" # 设置表格边框(美化格式) thin_border = Border( left=Side(style='thin'), right=Side(style='thin'), top=Side(style='thin'), bottom=Side(style='thin') ) # 加载集团合同模板 wb = load_workbook(TEMPLATE_PATH) ws = wb.active # 写入合同编号 ws['E1'] = f"编号:{data['contract_num']}" # 写入甲乙方信息 ws['A3'] = f"供方(甲方):{data['partyA_info']['name']} 需方(乙方):{data['partyB_info']['工厂全称']}" ws['A4'] = f"地址:{data['partyA_info']['addr']} 地址:{data['partyB_info']['地址']}" ws['A5'] = f"电话:{data['partyA_info']['phone']} 电话:{data['partyB_info']['电话']}" # 写入产品明细 df = data["prod_infos"] start_row = 10 # 产品明细起始行,可根据模板修改 start_col = 2 # 产品明细起始列,可根据模板修改 # 写入列名并添加边框 for col_idx, col_name in enumerate(df.columns, start=start_col): cell = ws.cell(row=start_row, column=col_idx, value=col_name) cell.border = thin_border # 写入明细数据并添加边框 for row_idx, row in enumerate(df.values, start=start_row + 1): for col_idx, value in enumerate(row, start=start_col): cell = ws.cell(row=row_idx, column=col_idx, value=value) cell.border = thin_border # 写入合同条款(可根据集团模板修改) next_row = start_row + len(df) + 2 ws[f"A{next_row}"] = f"二、质量要求:以客户确认的样品质量为准,如因产品质量问题引起客户索赔,供方需付连带责任。" ws[f"A{next_row+1}"] = f"三、交货地点及方式:{data['delivery_time']}前工厂交货。" ws[f"A{next_row+2}"] = f"四、结算方式及期限:甲方凭增值税发票及出口货物专用缴款书装箱后30天付清。" ws[f"A{next_row+3}"] = f"五、包装要求:出口用双瓦楞纸箱,纸箱尺寸按客户要求。" ws[f"A{next_row+4}"] = f"六、违约责任:违约损失及连带责任由违约方承担。" ws[f"A{next_row+5}"] = f"七、争议的解决方式:本合同在履行过程中如发生争议,由当事人双方协商解决。协商不成,提交威海市仲裁委员会仲裁。" ws[f"A{next_row+6}"] = f"八、本合同甲、乙双方盖章签字后生效,甲乙双方各持壹份。" ws[f"B{next_row+15}"] = f"甲方:" ws[f"F{next_row+15}"] = f"乙方:" ws[f"F{next_row+17}"] = data['sign_time'] # 创建结果文件夹(自动生成) os.makedirs("./result", exist_ok=True) # 保存合同文件(命名格式可修改) output_path = f"./result/{data['partyB_info']['工厂简称']}-{data['contract_num']}-购销合同-{data['today_time']}.xlsx" wb.save(output_path) print(f"合同生成成功:{output_path}")if __name__ == "__main__": # 批量处理指定目录下的所有Excel开票资料 excel_files = [os.path.join(INPUT_DIRECTORY, f) for f in os.listdir(INPUT_DIRECTORY) if f.endswith(('.xlsx', '.xls'))] for file in excel_files: try: logging.info(f"开始处理文件:{file}") result_data = deal_with_input(file) write_excel(result_data) logging.info(f"文件{file}处理成功") except Exception as e: logging.error(f"文件{file}处理失败,错误信息:{str(e)}") print(f"文件{file}处理失败,可查看logs文件夹下的日志了解详情")


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
