
Python 之所以能在全球开发者中占据核心地位,其核心哲学在于对“可读性”的极致追求。正如 Django 核心开发者 James Bennett 所言,代码被阅读的次数远多于编写的次数。Python 的设计理念——即 Guido van Rossum 所倡导的“清晰、易读、易懂”——使得即使是非专业编程人员也能通过源代码逻辑推断出程序的运行意图。然而,这种对人类友好的“源代码”与计算机底层硬件之间存在着天然的鸿沟。
计算机的物理核心是 CPU,本质上是一块刻有复杂电路的硅片。它通过特定的电信号模式进行运算,我们将这些电信号模式定义为“指令”或“机器码”(Machine Code)。虽然我们可以通过汇编语言(Assembly)将其转化为人类勉强可读的形式,但对于追求开发效率和逻辑表达的现代程序员来说,直接编写汇编代码显然是不现实的。
为了弥合人类可读的源代码与机器可执行的二进制指令之间的差距,编程领域演化出了两种主流路径:
- 编译型语言(Compiled Languages):通过编译器(Compiler)一次性将源代码直接转换为目标机器的机器码。
- 解释型语言(Interpreted Languages):在运行时由解释器逐行将源代码翻译为机器码并立即执行。
Python 通常被归类为解释型语言,但其背后的执行机制(尤其是 CPython 实现)远比简单的逐行翻译复杂。它在追求人类友好性的同时,通过一种中间形态——字节码(Bytecode),在可读性与执行效率之间找到了平衡点。了解 Python 如何从优美的文字转化为 CPU 的电信号,是深入掌握这门语言的第一步。

字节码与 Python 虚拟机 (PVM)
尽管 Python 常被称为解释型语言,但其底层运行机制实际上采用了一种“混合模式”。它并不会直接将源代码翻译成物理 CPU 能够理解的机器码,而是先将其编译成一种中间状态——字节码(Bytecode)。这种字节码是专门为一种“虚拟 CPU”设计的指令集,而这个虚拟 CPU 就是 Python 虚拟机(PVM)。
这种架构并非 Python 独有。正如 Java 运行在 JVM 上,.NET 语言(如 C#)运行在 .NET VM 上一样,Python 也会在执行前完成一次隐式的编译。当你编写一个如 Fibonacci 数列计算的函数时,Python 首先会对源码进行语法分析,并生成对应的 .pyc 文件。在 Python 2 中,这些文件通常散落在源码目录下;而在 Python 3 中,它们被统一管理在 __pycache__ 目录下。这些 .pyc 文件本质上就是二进制的字节码,它是 Python 执行的核心。当模块被再次导入或程序重新运行时,Python 会优先加载这些已编译的字节码,从而跳过重复的编译步骤,显著提升启动效率。PVM 的角色就是作为一个软件层,负责解释这些字节码指令,并将其映射到当前运行环境的物理处理器架构上。

剖析 Python 代码对象 (Code Objects)
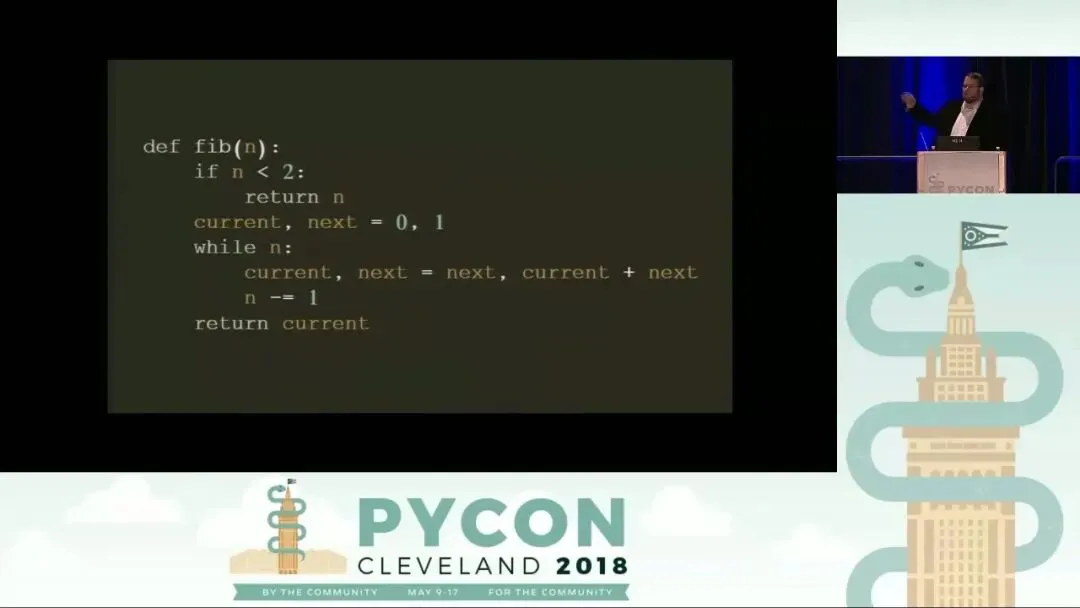
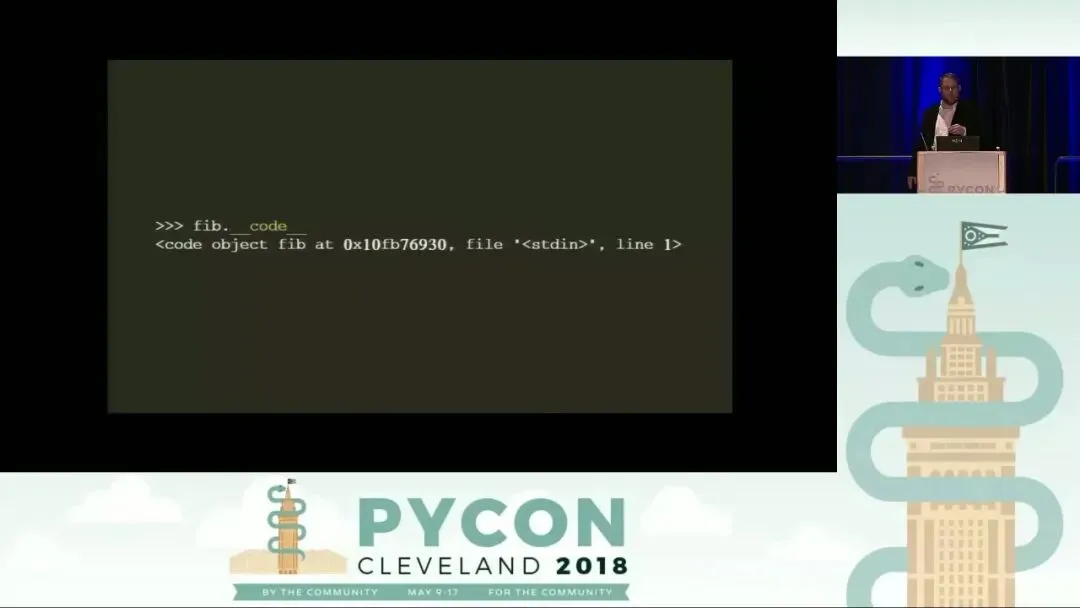
当我们在 Python 解释器中定义一个函数(例如斐波那契函数)时,Python 不仅仅是存储了源代码,而是将其编译并封装在一个函数对象中。这个函数对象内部包含了一个关键的属性:__code__。这就是所谓的 Python 代码对象(Code Object),它包含了 Python 执行该函数所需的所有元数据和指令。
通过对代码对象的深入剖析,我们可以揭示 Python 虚拟机在幕后是如何工作的:
-
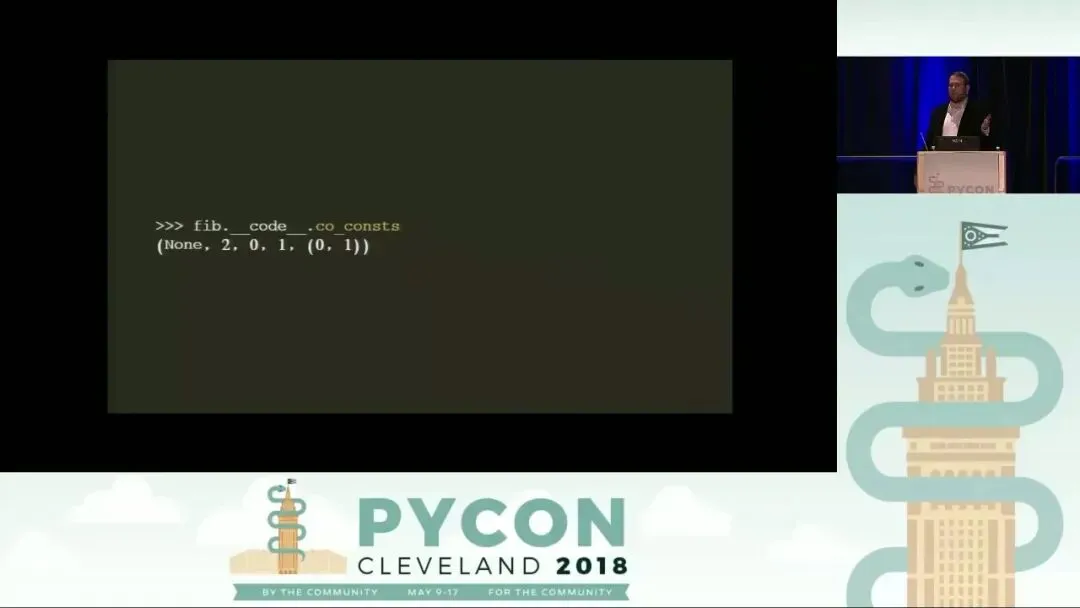
常量池 (co_consts):
这是一个包含函数体内引用的所有字面量(Literal)或常量值的元组。在斐波那契函数中,我们可以看到 0, 1, 2 以及元组 (0, 1)。特别值得注意的是,其中还包含了一个 None。尽管我们的源代码中可能没有显式写出 None,但 Python 编译器会自动将其加入。这是因为如果函数执行完毕而没有遇到显式的 return 语句,Python 必须准备好返回 None。由于在编译阶段无法预知是否会触达 return,编译器必须预先加载 None 以备不时之需。
-
局部变量与名称 (co_varnames & co_names):
- co_varnames:存储函数内部所有局部变量名称的元组。例如,在斐波那契函数中,它包含了 n, current, next。
- co_names:存储函数引用的非局部名称(如全局变量或内置函数)。如果函数是纯局部的,该元组将为空。
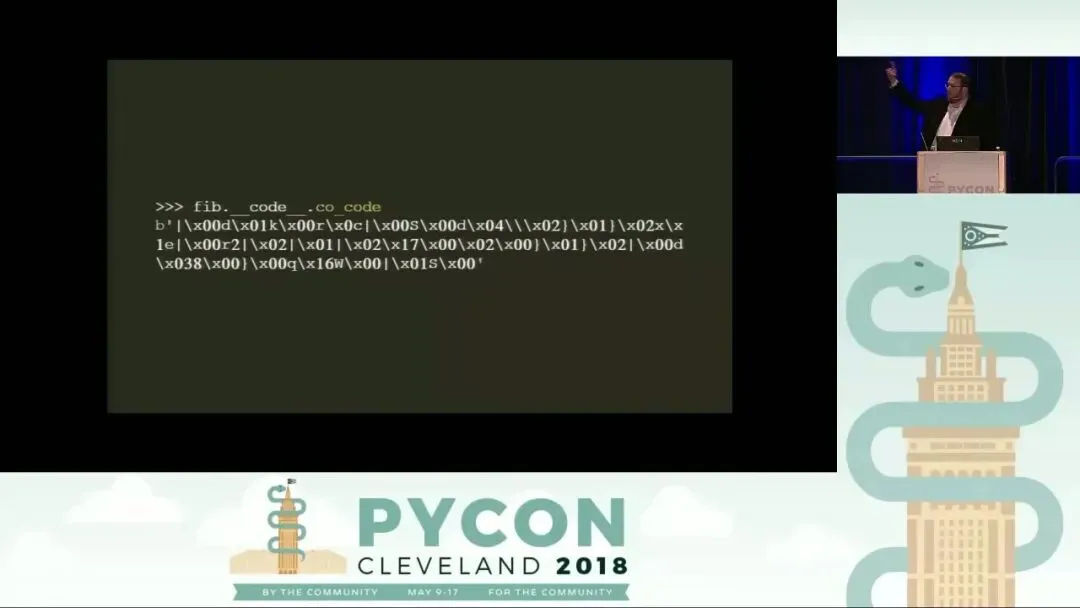
- 字节码序列 (co_code):
这是代码对象的核心,一个 bytes 类型的对象。虽然在控制台打印时,某些字节可能会显示为 ASCII 字符(如 |),但它本质上是一系列代表操作指令的数值。例如,第一个字节如果是 |,其对应的十进制 ASCII 码是 124。
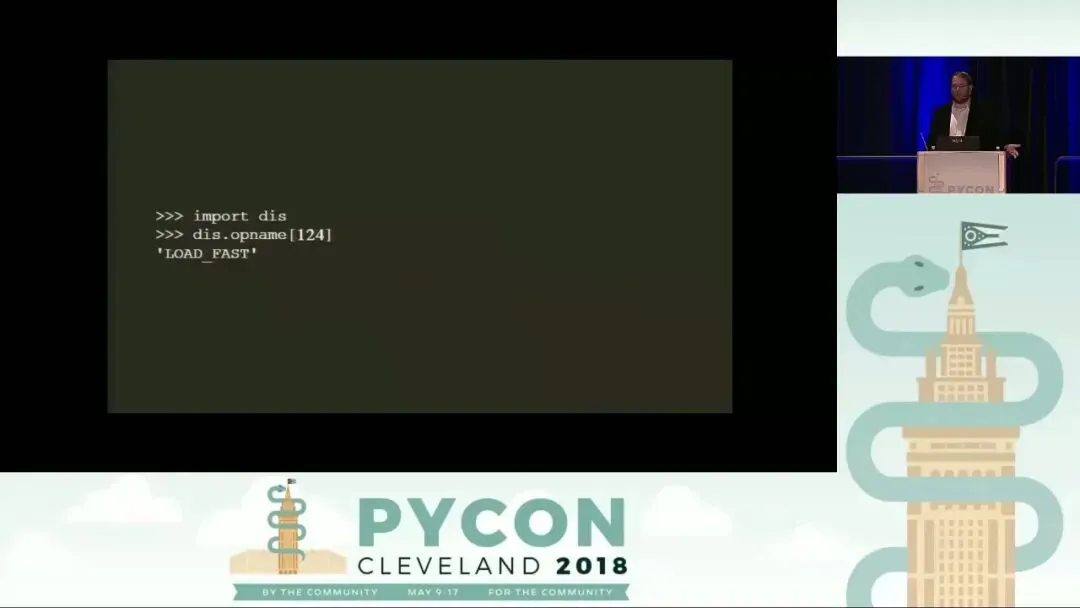
通过 Python 标准库中的 dis.opname 列表,我们可以查到索引 124 对应的指令是 LOAD_FAST。紧随其后的字节(如 0)则是该指令的参数。因此,字节码序列中的 124, 0 实际上构成了指令 LOAD_FAST 0。这条指令的具体含义是:去 co_varnames 元组中查找索引为 0 的变量(即 n),并将其压入评估栈(Evaluation Stack)中。
使用 dis 模块反汇编字节码
在深入了解字节码的二进制结构后,手动解析字节流显然是一项异常艰巨的任务。为了提高效率,Python 提供了一个内置的利器:dis 模块。通过调用 dis.dis() 函数,我们可以将复杂的二进制字节码转换为人类可读的汇编指令格式。该函数具有极高的灵活性,它不仅可以接收函数对象,还可以处理源代码字符串或几乎任何 Python 对象。
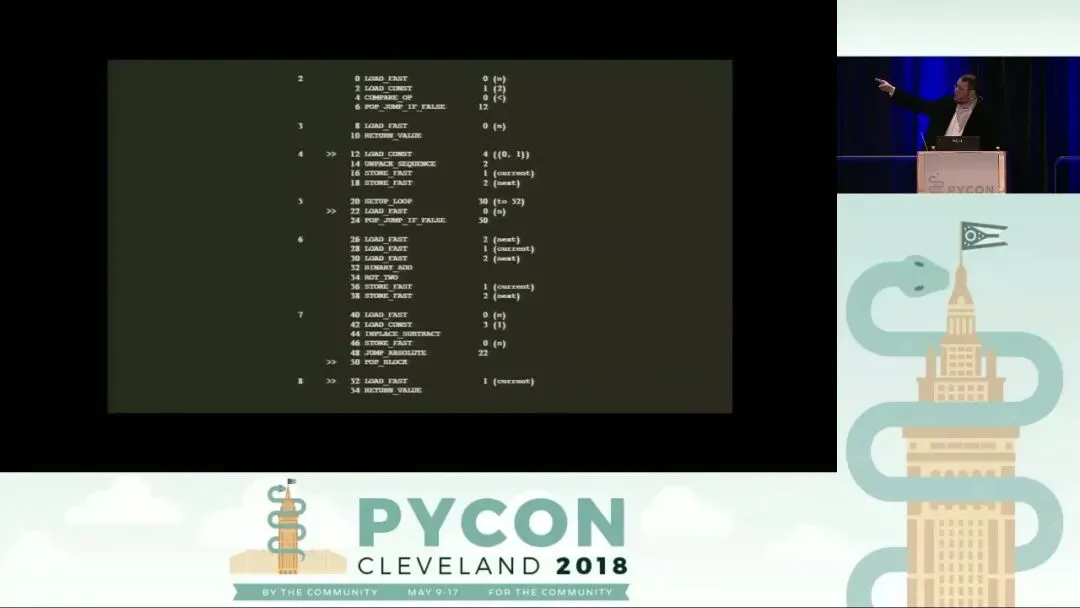
以 Fibonacci 函数为例,反汇编后的输出包含了几个关键维度:
- 源码行号(Line Numbers):输出结果最左侧的数字(如 2, 3, 4…)对应原始 .py 文件中的行号。你会发现,Python 的每一行源代码通常都会被编译成多条字节码指令。
- 指令偏移量(Instruction Offsets):在指令名称左侧的数字(如 0, 2, 4…)表示该指令在字节序列中的位置。值得注意的是,从 Python 3.6 开始,这些偏移量始终是偶数。这是因为 Python 引入了固定长度的指令格式:无论某条指令是否需要参数,它都会占用两个字节(一个字节用于 Opcode,一个字节用于 Argument)。这种设计极大地简化了解释器遍历字节码的逻辑。如果参数过大,则会通过 EXTENDED_ARG 指令扩展,但整体依然保持 2 字节的倍数。而在 Python 3.5 及更早版本中,偏移量可能是奇数,因为当时的指令长度是不固定的。
- 跳转标记(Jump Targets):在偏移量旁边,你可能会看到右尖括号 >>。这标志着该指令是一个“跳转目标”。例如,在循环结构或条件判断中,其他的跳转指令(如 POP_JUMP_IF_FALSE)可能会将执行流引导至此处。这对于理解代码的逻辑流(如循环的起始点)非常有帮助。
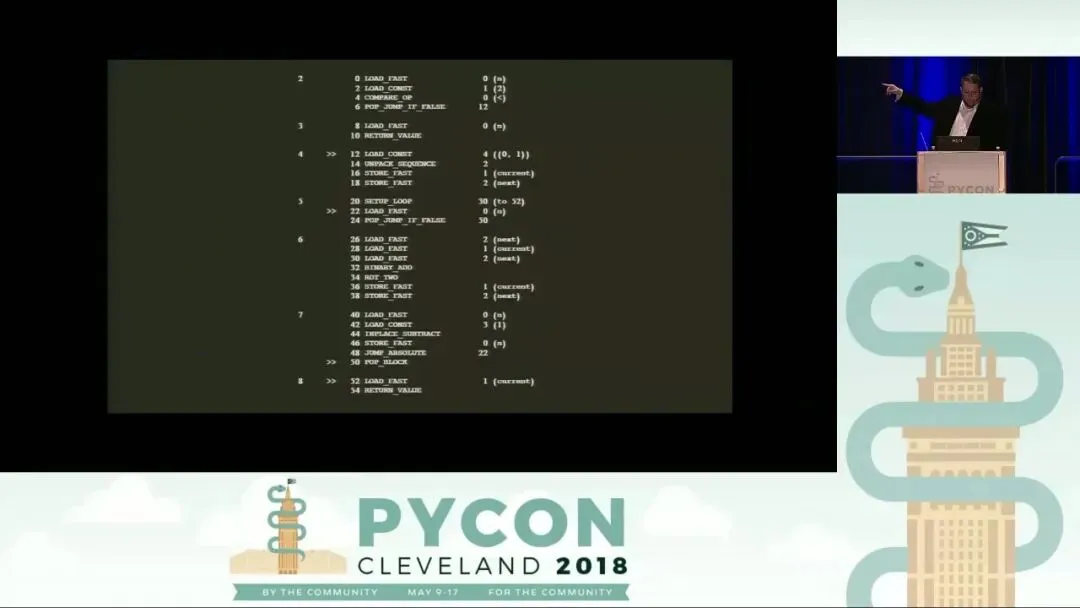
栈式架构:Python 的执行机制
深入理解 CPython 的执行模型,首先要认识到它是一个基于栈(Stack-based)的虚拟机。与基于寄存器的架构不同,Python 的所有操作几乎都围绕着栈这种“后进先出”(LIFO)的数据结构展开。在 CPython 的执行过程中,实际上存在三种关键的栈结构协同工作:
- 调用栈 (Call Stack):这是最顶层的结构。每当一个函数被调用时,Python 就会创建一个新的“调用帧”(Call Frame)并将其推入调用栈。这个帧包含了该函数执行所需的全部上下文。当函数执行完毕返回时,对应的帧会被从调用栈中弹出,并将返回值传递给前一个帧。

-
求值栈 (Evaluation Stack / Data Stack):这是函数内部执行逻辑的核心。绝大多数字节码指令都在操作这个栈。无论是加载变量、进行数学运算还是调用子函数,数据都会在求值栈中频繁地压入(Push)和弹出(Pop)。
-
块栈 (Block Stack):用于追踪当前活动的控制结构,如 try-except 块、with 语句或循环体。由于 break 和 continue 等语句需要知道当前的控制流边界,Python 通过块栈来精确管理这些嵌套关系。每进入一个支持的块,就推入一个条目,退出时弹出。
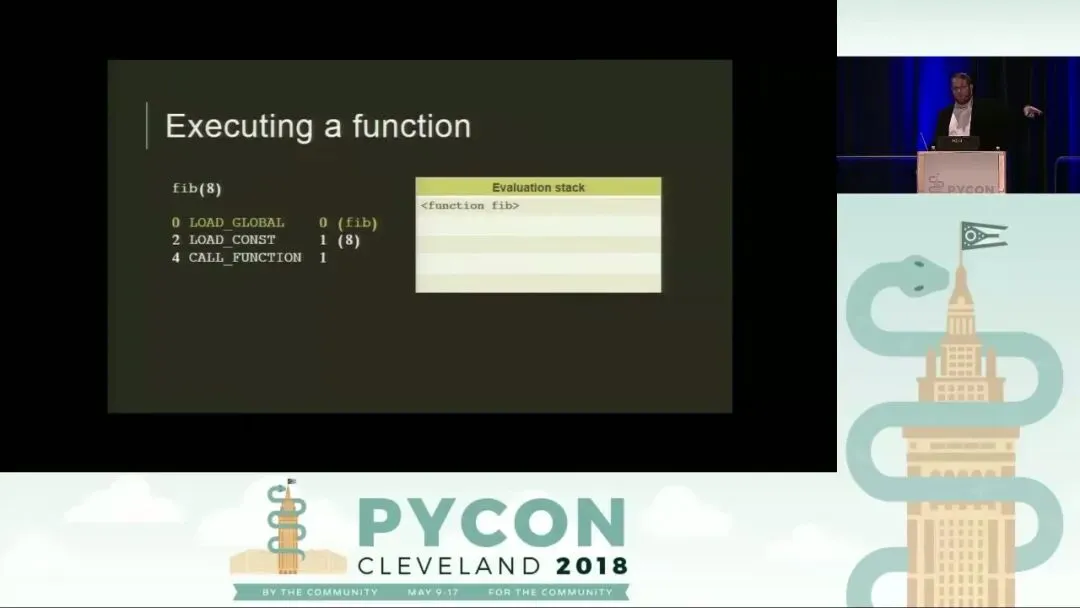
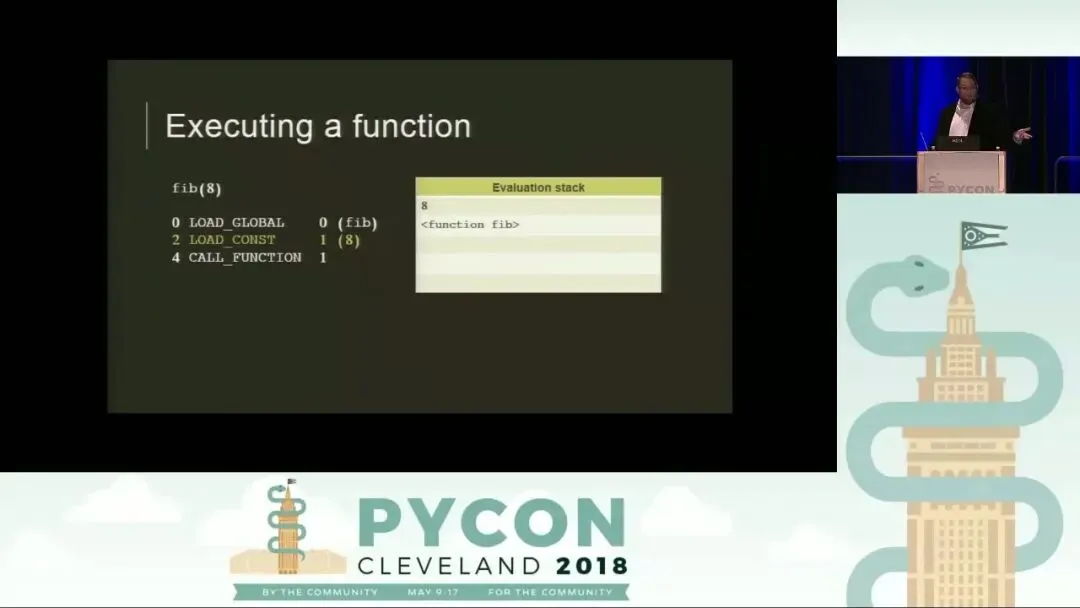
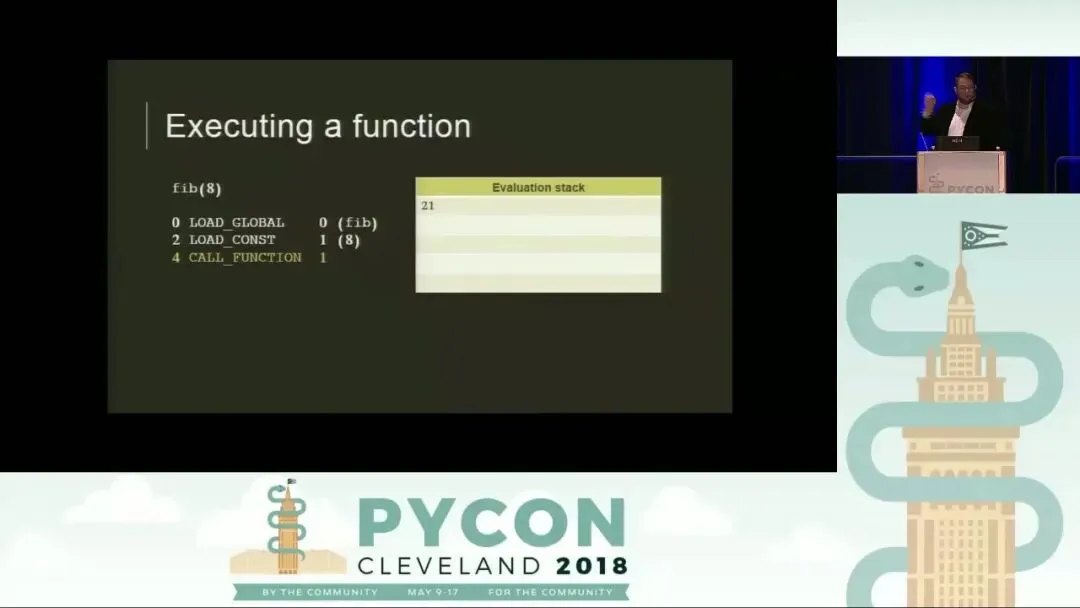
以调用 fib(8) 为例,Python 虚拟机的执行步骤如下:
- LOAD_GLOBAL: 从全局命名空间(co_names)找到函数对象 fib,并将其压入求值栈。
- LOAD_CONST: 从常量池(co_consts)中取出参数 8,压入求值栈。此时栈顶是 8,下方是 fib 函数对象。
- CALL_FUNCTION: 这是一个关键指令。它的参数(在本例中为 1)表示位置参数的数量。它会从栈中弹出指定数量的参数,再弹出函数对象,随后创建一个新的调用帧并开始执行函数内部代码。当 fib(8) 计算得出结果 21 后,该帧被销毁,结果 21 被压回原来调用者的求值栈顶。
字节码的实际应用与编译器优化
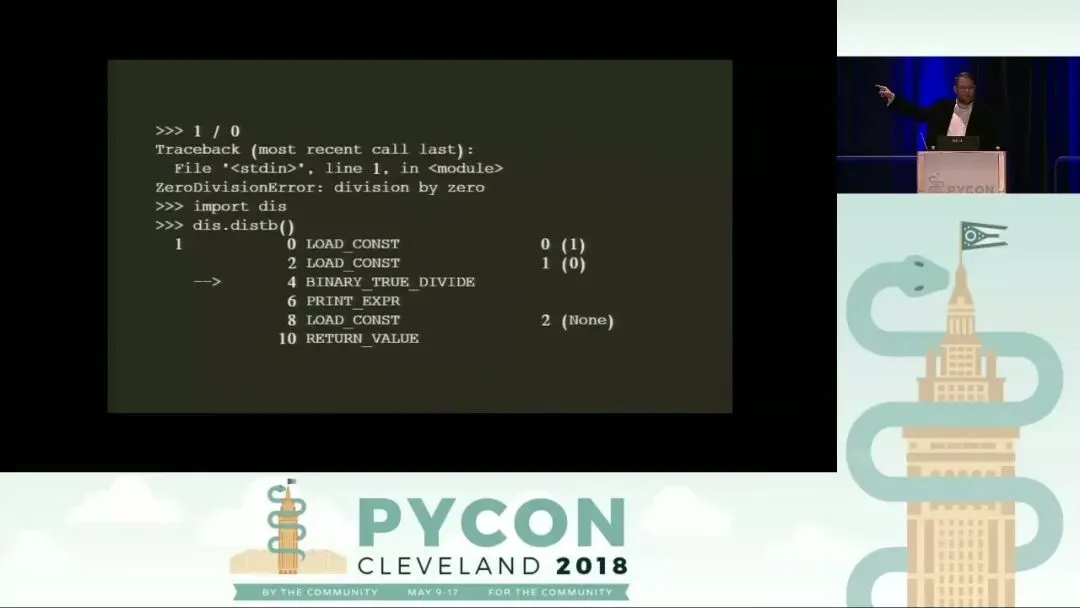
深入理解 Python 字节码不仅是理论上的探索,在实际开发与调试中也具有极高的应用价值。Python 标准库中的 dis 模块是我们的得力助手,它详尽记录了所有字节码指令的行为、参数及其底层逻辑。一个非常实用的技巧是使用 dis.distb() 函数。当你遇到难以捉摸的异常时,该函数可以反汇编发生异常时的调用栈帧,并直接指向导致崩溃的那条特定字节码指令。例如,在处理“除以零”的错误时,dis.distb() 能让你瞬间看透是哪一个操作数出了问题。
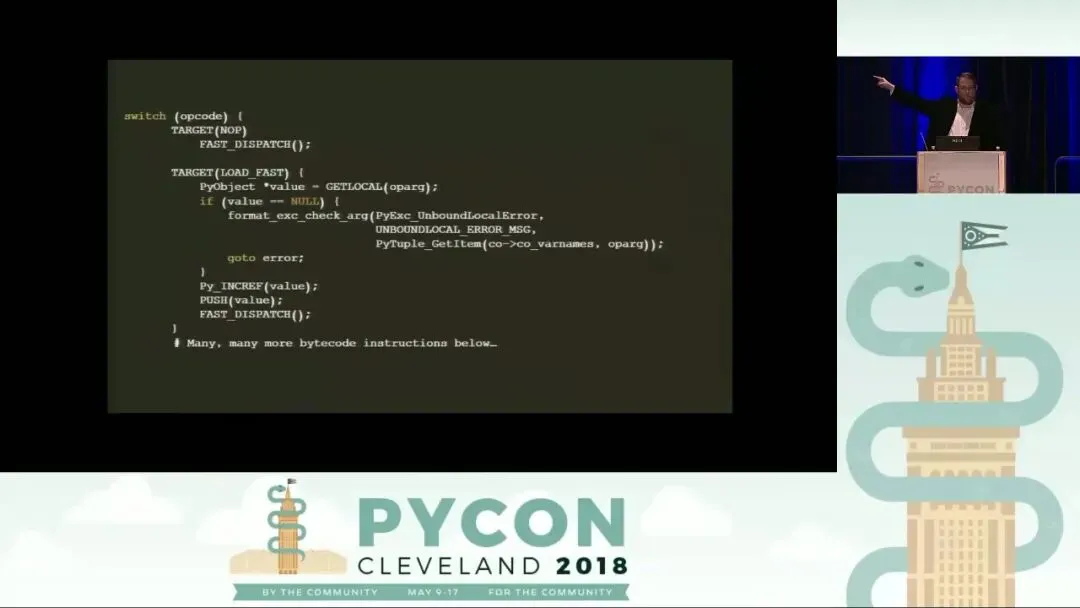
从架构角度看,Python 虚拟机(PVM)本质上是一个栈式机(Stack-oriented machine),这与 Forth 或 Factor 等语言的设计哲学异曲同工。Python 解释器的核心源码(通常是 C 语言实现)展示了一个巨大的 switch 语句,它根据指令的十进制值来决定执行逻辑。理解这种“压栈、操作、出栈”的模式,能让你像阅读 C 语言那样去推理 Python 代码的执行效率。
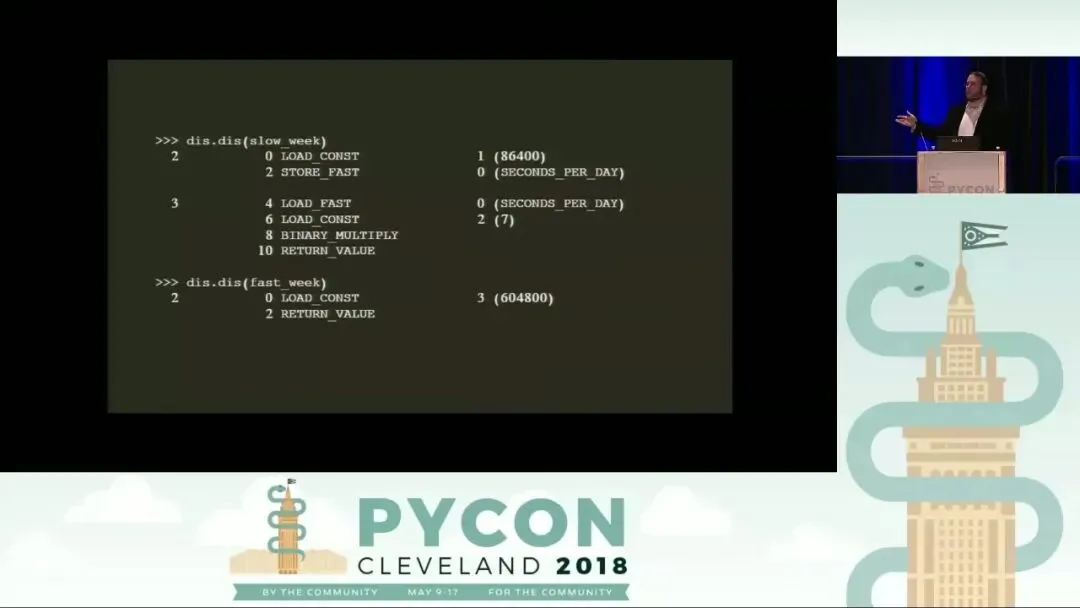
编译器优化是字节码学习中的另一个亮点。以计算一周秒数的两个函数为例:函数 A 先将每天秒数存入变量再相乘,而函数 B 直接返回 7 * 86400。通过 dis.dis() 反汇编可以发现,函数 B 的字节码中根本没有乘法指令,取而代之的是一个预计算好的常量 604800。这就是所谓的“常量折叠”(Constant Folding)优化。Python 编译器在编译阶段识别出两个整数常量进行运算,由于它们的值是不可变的,编译器直接在生成字节码时完成了计算,从而省去了运行时的计算开销。

性能分析:从字节码看代码效率
在 Python 性能优化的世界里,字节码(Bytecode)是揭开“为什么这段代码更快”谜题的钥匙。通过分析字节码指令,我们可以从底层理解解释器的运行逻辑。

1. 字面量与构造函数的博弈
一个经典的面试题是:为什么使用 [] 或 {} 字面量比调用 list() 或 dict() 快?通过 dis 模块观察发现,{} 仅需 2 条指令即可完成对象的创建与存储;而调用 dict() 则需要 3 条指令,且其中包含一条昂贵的 CALL_FUNCTION 指令。这意味着 Python 必须在调用栈上推入一个新的帧(Frame),执行函数体后再将其弹出,这种开销在高性能要求的循环中是不容忽视的。
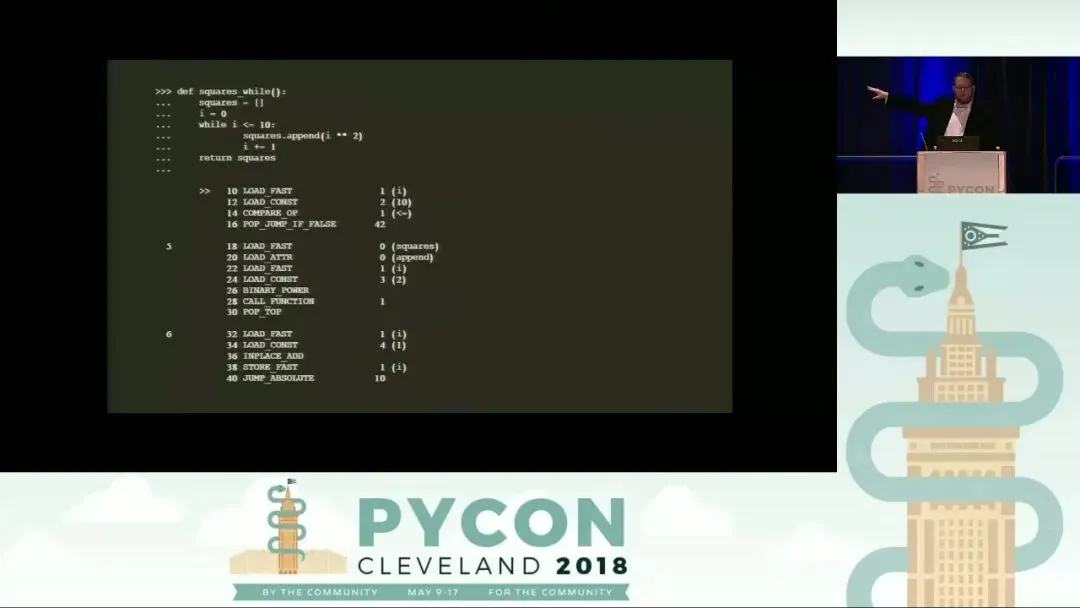
2. 循环结构的演进:从 While 到列表推导式
我们以计算前 10 个平方数为例,对比三种实现方式:
- While 循环:逻辑最原始,包含约 15 条指令。它需要手动维护计数器、进行条件判断和跳转,效率最低。
- For 循环 (range):指令数精简至 9 条。Python 内部对迭代器进行了优化,减少了手动维护状态的开销。
- 列表推导式:虽然指令数也是 9 条,但这里存在一个“性能陷阱”。列表推导式实际上会创建一个临时的函数对象并调用它,涉及到栈帧的推入与弹出。虽然它在语法上更简洁,但在某些微观基准测试中,它并不总是比高度优化的 for 循环快。这提醒我们:并非指令数越少就一定越快,不同指令的执行成本(Weight)截然不同。

3. 高性能 Python 的避坑指南
如果你追求极致性能,以下是基于字节码特性的几条通用准则:
- 优先使用 C 实现的内置模块:Python 本质上是慢的,微观优化(Micro-optimization)在 C 语言实现的内置函数面前往往微不足道。与其纠结字节码,不如寻找标准库中是否有 C 语言编写的替代方案。
- 减少循环内的变量查找:LOAD_CONST 和 LOAD_FAST(局部变量)极快,而 LOAD_GLOBAL 或 LOAD_NAME 则较慢,因为后者需要搜索多个命名空间。建议在循环前将全局变量或属性引用赋值给局部变量(Alias)。
- 警惕属性访问与索引:LOAD_ATTR(属性访问)和 BINARY_SUBSCRIPT(字典/列表索引)在字节码层面属于重型操作。如果循环中频繁访问同一对象的属性,请务必将其本地化。


