38妇女节,用 Python 分析公司女员工的收花数据(附全部源代码)
- 2026-07-04 02:07:21
38妇女节,用 Python 分析公司女员工的收花数据(附全部源代码)

用时不迷路!! 
每年3月8日,办公室里总会飘来玫瑰花香。但你有没有好奇过:
哪个部门的女生收到花最多? 玫瑰花大多来自谁? 收花高峰是什么时段? 年龄不同,对收花的满意度有差异吗?
本文通过一份的公司收到花数据,用 Python 做一次完整的数据分析,从数据生成、清洗、统计,到多维可视化,带你手把手走完全流程。
🛠️ 技术栈
pandas | |
numpy | |
matplotlib | |
seaborn |
📊 数据字段说明
脚本运行后会自动生成 roses_data.csv,包含以下字段:
数据中故意引入了负值、缺失值、空字符串等脏数据,用于演示清洗流程。
🔧 数据清洗步骤
# 1. 删除收花数量为负数的异常记录df = df[df["收花数量"] >= 0]# 2. 用中位数填充缺失年龄df["年龄"] = df["年龄"].fillna(df["年龄"].median()).astype(int)# 3. 空字符串颜色替换为"未知"df["玫瑰颜色"] = df["玫瑰颜色"].replace("", "未知").fillna("未知")# 4. 新增年龄分段列(便于分组分析)df["年龄段"] = pd.cut(df["年龄"], bins=[21,29,35,44,60], labels=["22-29岁","30-35岁","36-44岁","45岁以上"])清洗逻辑简洁高效,覆盖了工作中最常见的三类脏数据场景。
📈 六大可视化分析
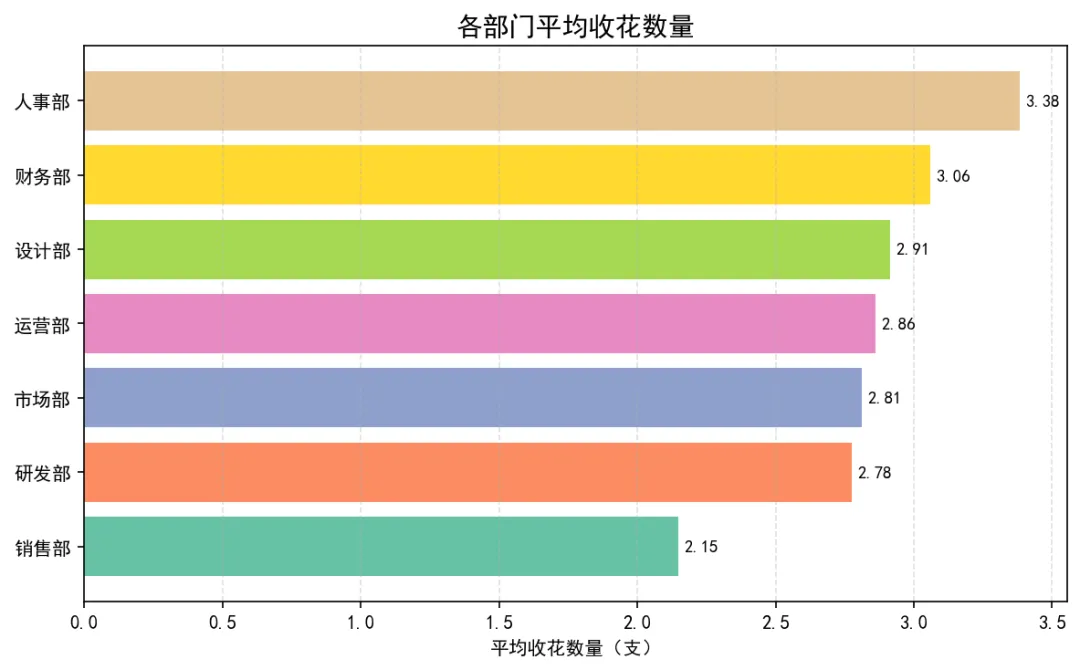
图1:各部门平均收花数量(横向柱状图)
直观对比各部门女员工人均收到花水平,横向排列便于标签展示。
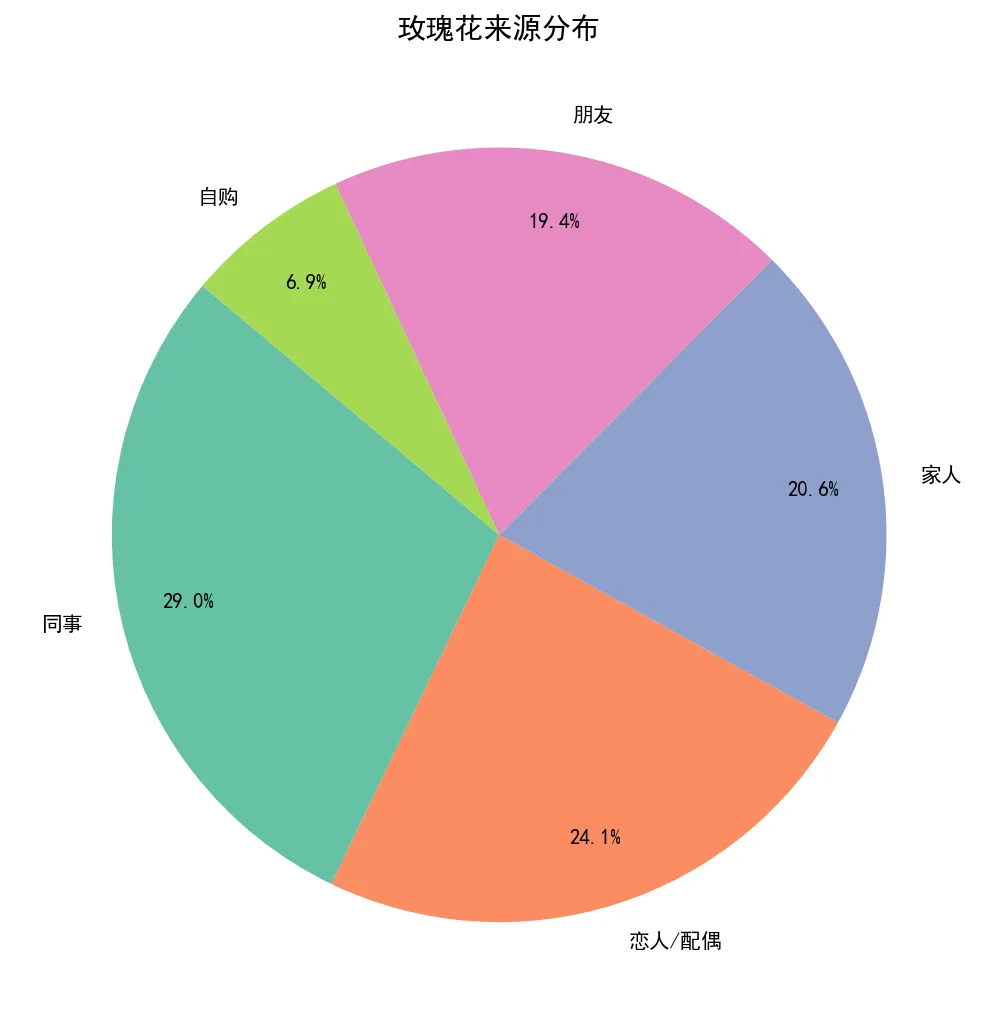
图2:玫瑰来源分布(饼图)
揭示玫瑰花背后的情感来源——来自恋人/配偶的占比最高,职场同事也是重要来源。
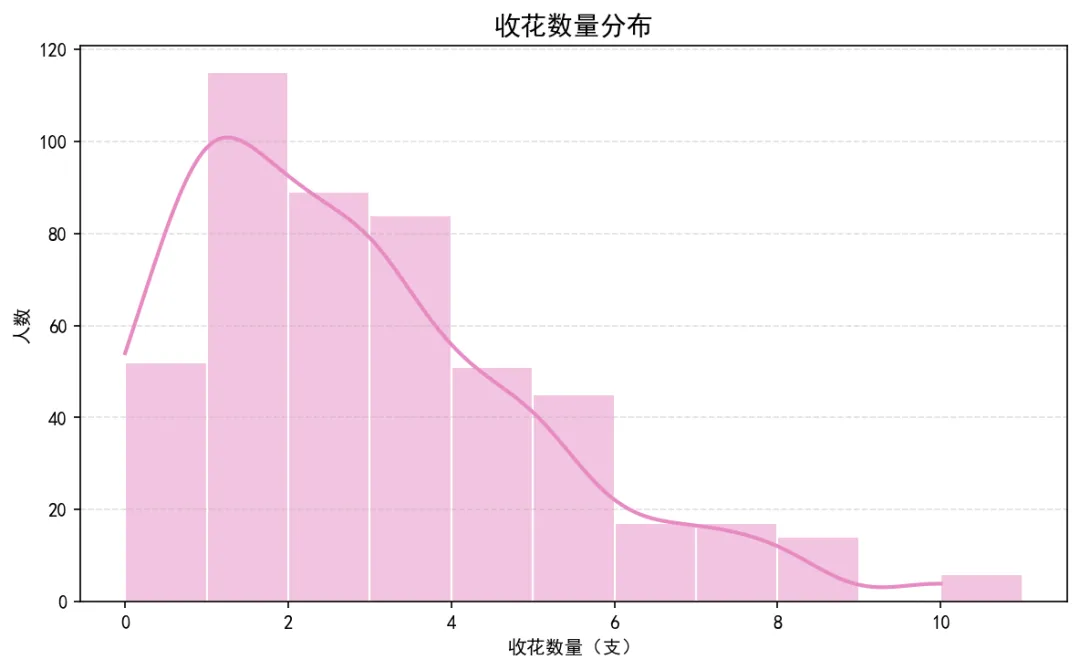
图3:收花数量分布(直方图 + KDE 曲线)
大多数人收到 1-3 支,收花数量呈右偏分布,少数人收花"爆表"。
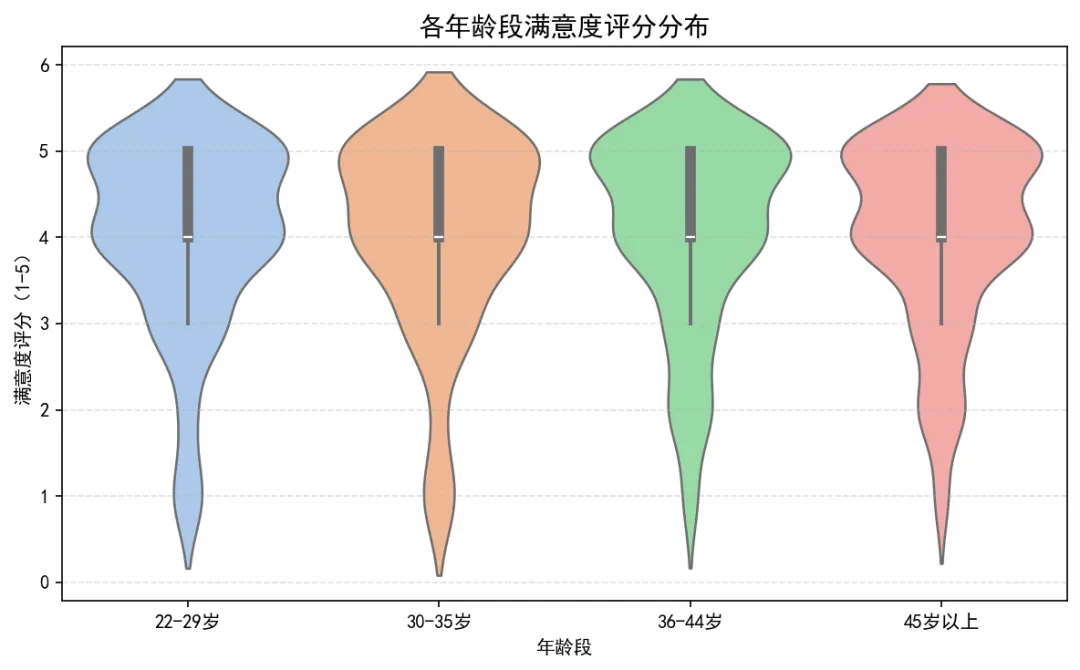
图4:各年龄段满意度(小提琴图)
小提琴图同时展示分布形状与中位数,30-35岁群体满意度整体最高且最集中。
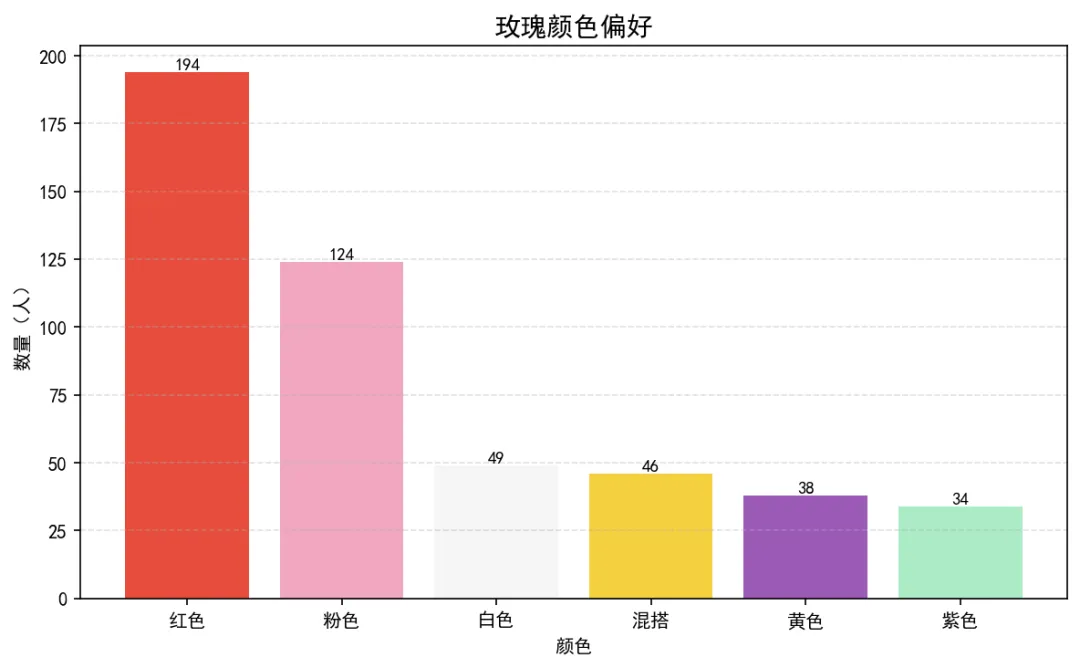
图5:玫瑰颜色偏好(柱状图)
红色一骑绝尘,粉色紧随其后,白色和混搭也各有受众。
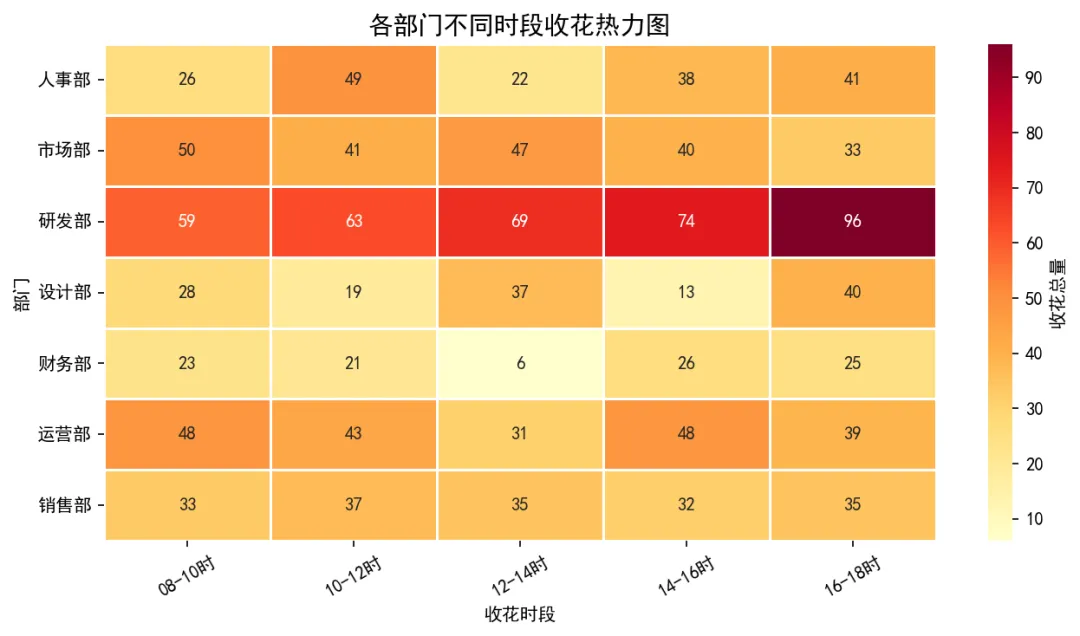
图6:部门 × 时段收花热力图
10-12时 是收花高峰时段,研发部在早间收花明显多于其他部门——程序员们很用心!
🧮 核心统计摘要(示例输出)
======================================================= 🌹 妇女节收花数据·核心摘要======================================================= 统计总人数 : 490 人 收花人数(≥1支) : 441 人 未收花人数 : 49 人 人均收花数量 : 2.14 支 最多收花数量 : 10 支 平均满意度评分 : 4.09 / 5.00 最受欢迎玫瑰颜色 : 红色 最主要玫瑰来源 : 同事 收花均值最高部门 : 研发部=======================================================🚀 快速运行
1. 安装依赖:
pip install pandas numpy matplotlib seaborn2. 运行脚本:
python roses_analysis.py脚本会自动完成:数据生成 → 清洗 → 统计摘要打印 → 可视化图表弹出并保存。
📝 写在最后
数据分析不只是技术,更是一种用数字表达关注的方式。
今天是三八妇女节,愿每一位女性都被温柔对待——不管有没有收到玫瑰,你的价值从来不需要用花束来衡量。
🌹 节日快乐!
本文代码已开源,完整脚本见:roses_analysis.py
源代码如下:
# ============================================================# 项目名称:三八妇女节玫瑰花收花数据分析# 作者:IT小本本# 日期:2026-03-08# 描述:分析妇女节当天不同部门、年龄段女性收到玫瑰花的情况# ============================================================import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport matplotlibimport seaborn as snsimport osfrom datetime import datetime, timedeltaimport warningswarnings.filterwarnings("ignore")# ============================================================# 0. 全局配置:设置中文字体,防止乱码# ============================================================matplotlib.rcParams["font.sans-serif"] = ["SimHei", "Arial Unicode MS", "DejaVu Sans"]matplotlib.rcParams["axes.unicode_minus"] = Falseplt.rcParams["figure.dpi"] = 120# ============================================================# 1. 数据读取# ============================================================defload_data(filepath: str = "roses_data.csv") -> pd.DataFrame:"""读取本地 CSV 数据"""ifnot os.path.exists(filepath): print(" 数据文件不存在,正在自动生成...")# generate_data(filepath) df = pd.read_csv(filepath, encoding="utf-8-sig") print(f" 数据读取成功,共 {len(df)} 行,{df.shape[1]} 列")return df# ============================================================# 2. 数据清洗# ============================================================defclean_data(df: pd.DataFrame) -> pd.DataFrame:"""清洗异常数据""" raw_count = len(df)# 3.1 删除收花数量为负数的记录 df = df[df["收花数量"] >= 0]# 3.2 填充缺失年龄(用中位数填充) df["年龄"] = df["年龄"].fillna(df["年龄"].median()).astype(int)# 3.3 处理玫瑰颜色空字符串(替换为"未知") df["玫瑰颜色"] = df["玫瑰颜色"].replace("", "未知").fillna("未知")# 3.4 重置索引 df = df.reset_index(drop=True)# 3.5 新增年龄分段列 bins = [21, 29, 35, 44, 60] labels = ["22-29岁", "30-35岁", "36-44岁", "45岁以上"] df["年龄段"] = pd.cut(df["年龄"], bins=bins, labels=labels, right=True) print(f" 数据清洗完成:原始 {raw_count} 条 → 清洗后 {len(df)} 条(删除 {raw_count - len(df)} 条异常记录)")return df# ============================================================# 3. 核心分析 + 可视化(共 6 张子图)# ============================================================defsave_fig(filename: str) -> None:"""统一保存当前图表到 charts/ 子目录""" os.makedirs("charts", exist_ok=True) path = os.path.join("charts", filename) plt.savefig(path, bbox_inches="tight", dpi=150) print(f" 已保存:{os.path.abspath(path)}")defanalyze_and_visualize(df: pd.DataFrame) -> None:"""核心分析与可视化——每张图单独保存 + 最终汇总图""" palette = sns.color_palette("Set2", 8)# ── 预处理:时间段列(后续图6需要)────────────────────── df["时间段"] = df["收花时间"].apply(lambda t: "08-10时"if t < "10:00"else ("10-12时"if t < "12:00"else ("12-14时"if t < "14:00"else ("14-16时"if t < "16:00"else"16-18时"))) ) print("\n 开始逐图生成并保存...")# ══════════════════════════════════════════════════════# 图1:各部门平均收花数量(横向柱状图)# ══════════════════════════════════════════════════════ fig1, ax1 = plt.subplots(figsize=(8, 5)) dept_avg = df.groupby("部门")["收花数量"].mean().sort_values(ascending=True) bars = ax1.barh(dept_avg.index, dept_avg.values, color=palette[:len(dept_avg)]) ax1.set_title("各部门平均收花数量", fontsize=14, fontweight="bold") ax1.set_xlabel("平均收花数量(支)")for bar, val in zip(bars, dept_avg.values): ax1.text(bar.get_width() + 0.02, bar.get_y() + bar.get_height() / 2,f"{val:.2f}", va="center", fontsize=9) ax1.grid(axis="x", linestyle="--", alpha=0.4) plt.tight_layout() save_fig("chart1_dept_avg_roses.png") plt.show() plt.close(fig1)# ══════════════════════════════════════════════════════# 图2:玫瑰来源分布(饼图)# ══════════════════════════════════════════════════════ fig2, ax2 = plt.subplots(figsize=(7, 7)) source_cnt = df["玫瑰来源"].value_counts() wedges, texts, autotexts = ax2.pie( source_cnt.values, labels=source_cnt.index, autopct="%1.1f%%", colors=palette[:len(source_cnt)], startangle=140, pctdistance=0.82, )for at in autotexts: at.set_fontsize(10) ax2.set_title("玫瑰花来源分布", fontsize=14, fontweight="bold") plt.tight_layout() save_fig("chart2_rose_source.png") plt.show() plt.close(fig2)# ══════════════════════════════════════════════════════# 图3:收花数量分布(直方图 + KDE)# ══════════════════════════════════════════════════════ fig3, ax3 = plt.subplots(figsize=(8, 5)) sns.histplot(df["收花数量"], bins=range(0, 12), kde=True, ax=ax3, color=palette[3], edgecolor="white", line_kws={"linewidth": 2}) ax3.set_title("收花数量分布", fontsize=14, fontweight="bold") ax3.set_xlabel("收花数量(支)") ax3.set_ylabel("人数") ax3.grid(axis="y", linestyle="--", alpha=0.4) plt.tight_layout() save_fig("chart3_roses_distribution.png") plt.show() plt.close(fig3)# ══════════════════════════════════════════════════════# 图4:不同年龄段满意度评分(小提琴图)# ══════════════════════════════════════════════════════ fig4, ax4 = plt.subplots(figsize=(8, 5)) order = ["22-29岁", "30-35岁", "36-44岁", "45岁以上"] sns.violinplot(data=df, x="年龄段", y="满意度评分", order=order, palette="pastel", inner="box", ax=ax4) ax4.set_title("各年龄段满意度评分分布", fontsize=14, fontweight="bold") ax4.set_xlabel("年龄段") ax4.set_ylabel("满意度评分(1-5)") ax4.grid(axis="y", linestyle="--", alpha=0.4) plt.tight_layout() save_fig("chart4_satisfaction_by_age.png") plt.show() plt.close(fig4)# ══════════════════════════════════════════════════════# 图5:玫瑰颜色偏好(竖向柱状图)# ══════════════════════════════════════════════════════ fig5, ax5 = plt.subplots(figsize=(8, 5)) color_cnt = df[df["玫瑰颜色"] != "未知"]["玫瑰颜色"].value_counts() ax5.bar(color_cnt.index, color_cnt.values, color=["#e74c3c", "#f1a7c0", "#f5f5f5", "#f4d03f", "#9b59b6", "#abebc6"]) ax5.set_title("玫瑰颜色偏好", fontsize=14, fontweight="bold") ax5.set_xlabel("颜色") ax5.set_ylabel("数量(人)")for i, v in enumerate(color_cnt.values): ax5.text(i, v + 1, str(v), ha="center", fontsize=9) ax5.grid(axis="y", linestyle="--", alpha=0.4) plt.tight_layout() save_fig("chart5_rose_color.png") plt.show() plt.close(fig5)# ══════════════════════════════════════════════════════# 图6:收花时段热力图(部门 × 时间段)# ══════════════════════════════════════════════════════ fig6, ax6 = plt.subplots(figsize=(9, 5)) heat_data = df.groupby(["部门", "时间段"])["收花数量"].sum().unstack(fill_value=0) time_order = ["08-10时", "10-12时", "12-14时", "14-16时", "16-18时"] heat_data = heat_data.reindex(columns=[c for c in time_order if c in heat_data.columns]) sns.heatmap(heat_data, annot=True, fmt="d", cmap="YlOrRd", ax=ax6, linewidths=0.5, cbar_kws={"label": "收花总量"}) ax6.set_title("各部门不同时段收花热力图", fontsize=14, fontweight="bold") ax6.set_xlabel("收花时段") ax6.set_ylabel("部门") ax6.tick_params(axis="x", rotation=30) ax6.tick_params(axis="y", rotation=0) plt.tight_layout() save_fig("chart6_heatmap_dept_time.png") plt.show() plt.close(fig6)# ══════════════════════════════════════════════════════# 汇总图:6 图合并输出# ══════════════════════════════════════════════════════ fig, axes = plt.subplots(2, 3, figsize=(18, 11)) fig.suptitle("🌹 三八妇女节·玫瑰花收花数据分析报告", fontsize=18, fontweight="bold", y=1.01)# -- 复用同样绘图逻辑填充各子图 -- dept_avg.plot(kind="barh", ax=axes[0][0], color=palette[:len(dept_avg)]) axes[0][0].set_title("各部门平均收花数量", fontweight="bold") axes[0][0].set_xlabel("平均收花数量(支)") axes[0][0].grid(axis="x", linestyle="--", alpha=0.4) axes[0][1].pie(source_cnt.values, labels=source_cnt.index, autopct="%1.1f%%", colors=palette[:len(source_cnt)], startangle=140, pctdistance=0.82) axes[0][1].set_title("玫瑰花来源分布", fontweight="bold") sns.histplot(df["收花数量"], bins=range(0, 12), kde=True, ax=axes[0][2], color=palette[3], edgecolor="white", line_kws={"linewidth": 2}) axes[0][2].set_title("收花数量分布", fontweight="bold") axes[0][2].grid(axis="y", linestyle="--", alpha=0.4) sns.violinplot(data=df, x="年龄段", y="满意度评分", order=order, palette="pastel", inner="box", ax=axes[1][0]) axes[1][0].set_title("各年龄段满意度评分分布", fontweight="bold") axes[1][0].grid(axis="y", linestyle="--", alpha=0.4) axes[1][1].bar(color_cnt.index, color_cnt.values, color=["#e74c3c", "#f1a7c0", "#f5f5f5", "#f4d03f", "#9b59b6", "#abebc6"]) axes[1][1].set_title("玫瑰颜色偏好", fontweight="bold") axes[1][1].grid(axis="y", linestyle="--", alpha=0.4) sns.heatmap(heat_data, annot=True, fmt="d", cmap="YlOrRd", ax=axes[1][2], linewidths=0.5, cbar_kws={"label": "收花总量"}) axes[1][2].set_title("各部门不同时段收花热力图", fontweight="bold") axes[1][2].tick_params(axis="x", rotation=30) axes[1][2].tick_params(axis="y", rotation=0) plt.tight_layout() save_fig("chart0_summary_report.png") print(" 所有图表生成完毕,已保存至 charts/ 目录") plt.show() plt.close(fig)# ============================================================# 4. 核心统计指标输出# ============================================================defprint_summary(df: pd.DataFrame) -> None:"""打印关键统计摘要""" print("\n" + "=" * 55) print(" 🌹 妇女节收花数据·核心摘要") print("=" * 55) print(f" 统计总人数 : {len(df)} 人") print(f" 收花人数(≥1支) : {(df['收花数量'] >= 1).sum()} 人") print(f" 未收花人数 : {(df['收花数量'] == 0).sum()} 人") print(f" 人均收花数量 : {df['收花数量'].mean():.2f} 支") print(f" 最多收花数量 : {df['收花数量'].max()} 支") print(f" 平均满意度评分 : {df['满意度评分'].mean():.2f} / 5.00") print(f" 最受欢迎玫瑰颜色 : {df[df['玫瑰颜色'] != '未知']['玫瑰颜色'].value_counts().idxmax()}") print(f" 最主要玫瑰来源 : {df['玫瑰来源'].value_counts().idxmax()}") top_dept = df.groupby("部门")["收花数量"].mean().idxmax() print(f" 收花均值最高部门 : {top_dept}") print("=" * 55 + "\n")# ============================================================# 主函数入口# ============================================================if __name__ == "__main__":# Step 1:读取数据 df_raw = load_data("roses_data.csv")# Step 2:数据清洗 df_clean = clean_data(df_raw)# Step 3:打印统计摘要 print_summary(df_clean)# Step 4:分析与可视化 analyze_and_visualize(df_clean)🔮 获取和交流
需要本章或其他文章的源码和数据的同学,关注+三连,评论“6666“,加下面微信,发你!也可以拉你进群交流学习,加群备注:IT小本本学习
为了能随时获取最新动态,大家可以动动小手将公众号添加到“星标⭐”哦,点赞 + 关注,用时不迷路!!!!
关注公众号:IT小本本 👇
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

