一个实际问题:如何让 AI 读懂你的私有文档?比如公司内部的产品手册、技术文档、会议纪要。答案是:能,而且不难。这个技术叫 RAG (Retrieval-Augmented Generation,检索增强生成)。名字唬人,但原理嘛……你看完可能会觉得"就这?"- V2 — 加上分块重叠 + 相似度过滤,准确率直接翻倍
- V3 — 再加 Rerank 重排序,让最相关的内容排到最前面
依赖很少, `pip install openai chromadb` 就够了,代码直接能跑。你问 ChatGPT:"我们公司的报销流程是什么?"ChatGPT 回:"很抱歉,我无法获取贵公司的内部信息……"废话,它当然不知道。大模型的知识来自训练数据,你公司的内部文档它压根没见过。- 路线 A:微调(Fine-tuning) — 把你的数据喂给模型重新训练。相当于让大模型"死记硬背"你的文档。代价是贵(几十到几百美元一次)、慢(几小时起步)、每次文档更新都得重新训练。
- 路线 B:RAG — 不改模型,改输入。每次用户提问的时候,先从你的文档库里搜出最相关的几段话,塞进 prompt 里,让大模型"开卷考试"。代价极低(只需要一次向量化),实时更新(文档变了重新入库就行)。
打个比方:微调是让学生把整本教材背下来,RAG 是让学生带着教材进考场。你说哪个划说白了: RAG = 搜索 + 大模型 。先搜到相关内容,再让大模型基于搜到的东西生成回答。不管外面包了多花哨的框架,RAG 拆开就两个阶段:原始文档 → 切成小块(Chunk) → 每块转成向量(Embedding) → 存进向量数据库切块 :一篇 10 页的文档不能整篇扔给大模型(会超 token 限制),得切成几百字的小段。向量化 :把每段文字变成一串数字(比如 1536 维的浮点数数组)。语义相近的文字,向量也相近。"今天天气真好"和"今天阳光明媚"的向量距离就很小。打个不太严谨但很直觉的比方:想象一个巨大的坐标系。"苹果手机"和"iPhone"在这个坐标系上的位置很近,因为它们说的是同一个东西;而"苹果手机"和"火锅底料"的位置就离得很远。Embedding 模型干的活就是帮每段文字在这个坐标系里找到"正确的位置"。语义越相似的文字,位置越近。至于模型是怎么学会给文字"定位"的——答案是大量的训练数据。它见过无数的句子对,慢慢学会了哪些句子在说类似的事。这个过程你不需要操心,直接调接口就行。存储 :把这些向量存进专门的向量数据库(ChromaDB、FAISS、Qdrant 等),方便后面快速搜索。用户提问 → 问题转成向量 → 在向量库中搜最相似的几段 → 把这些段落塞进 prompt → 大模型生成回答就这么简单。整个 RAG 的精髓就是一句话: 别让大模型凭记忆答题,给它"开卷" 。pip install openai chromadb
import osfrom openai import OpenAI# DeepSeek API(用于对话生成)deepseek_key = os.getenv("DEEPSEEK_API_KEY")if not deepseek_key: raise ValueError("请设置环境变量 DEEPSEEK_API_KEY")# 硅基流动 API(用于 embedding)siliconflow_key = os.getenv("SILICONFLOW_API_KEY")if not siliconflow_key: raise ValueError("请设置环境变量 SILICONFLOW_API_KEY")# 对话模型客户端chat_client = OpenAI(base_url="https://api.deepseek.com", api_key=deepseek_key)# Embedding 模型客户端embedding_client = OpenAI(base_url="https://api.siliconflow.cn/v1", api_key=siliconflow_key)
- DeepSeek :用于对话生成(便宜,¥1/百万 tokens)- 硅基流动 :用于文本向量化(DeepSeek 不提供 embedding 服务) export DEEPSEEK_API_KEY="your_key_here" export SILICONFLOW_API_KEY="your_key_here"
我们模拟一个"公司知识库",包含几篇内部文档。在实际场景中,这些可以是 PDF、Word、Markdown 等任何格式,这里为了演示方便直接用字符串:documents = [ { "id": "doc1", "title": "请假制度", "content": """公司请假制度(2024年修订版)一、年假规定1. 入职满1年不满10年的员工,每年享有5天带薪年假。2. 入职满10年不满20年的员工,每年享有10天带薪年假。3. 入职满20年以上的员工,每年享有15天带薪年假。4. 年假需提前3个工作日在OA系统中提交申请,直属上级审批通过后生效。5. 年假可以分次使用,但每次不少于半天。6. 当年未使用的年假可以顺延至次年第一季度,逾期作废。二、病假规定1. 病假需提供正规医院出具的诊断证明和病假条。2. 3天以内的病假由直属上级审批。3. 3天以上的病假需由部门总监审批。4. 病假期间工资按基本工资的80%发放。5. 连续病假超过30天的,按公司长期病假政策处理。三、事假规定1. 事假为无薪假期,按日扣除工资。2. 事假每次不超过3天,需提前2个工作日申请。3. 全年事假累计不超过15天。4. 事假审批流程与病假相同。""" }, { "id": "doc2", "title": "报销制度", "content": """公司费用报销制度一、差旅报销标准1. 交通费:飞机经济舱、高铁二等座实报实销...2. 住宿费:一线城市(北上广深)每晚不超过500元...(完整内容见代码仓库)""" }, { "id": "doc3", "title": "技术规范", "content": """前端技术开发规范一、技术栈要求1. 框架统一使用 React 18+...2. 状态管理使用 Zustand...(完整内容见代码仓库)""" }, { "id": "doc4", "title": "新人入职指南", "content": """新员工入职指南一、入职第一天1. 上午 9:00 到前台报到...(完整内容见代码仓库)""" }, { "id": "doc5", "title": "绩效考核制度", "content": """绩效考核管理办法一、考核周期1. 公司采用季度考核制...(完整内容见代码仓库)""" }]
这些文档涵盖了请假、报销、技术规范、入职和绩效——一个典型的公司知识库完整代码见文末或Githubhttps://github.com/qqzhangyanhua/aboutAgent.gitV1 的思路极其直白:把文档切块 → 转向量 → 存进去 → 用户提问时搜最相似的块 → 塞进 prompt 里让大模型回答。def simple_chunk(text, chunk_size=200): """按固定大小切块""" chunks = [] for i in range(0, len(text), chunk_size): chunk = text[i:i + chunk_size].strip() if chunk: chunks.append(chunk) return chunks
用硅基流动的 Embedding 接口把文字变成向量,然后存进 ChromaDB:import chromadbchroma_client = chromadb.Client()collection = chroma_client.create_collection(name="company_docs_v1")def get_embedding(text): """调用硅基流动 Embedding 接口""" response = embedding_client.embeddings.create( model="netease-youdao/bce-embedding-base_v1", input=text ) return response.data[0].embeddingdef build_index_v1(documents): """V1:简单切块 + 入库""" print("正在建立索引...") for doc in documents: chunks = simple_chunk(doc["content"], chunk_size=200) for i, chunk in enumerate(chunks): chunk_id = f"{doc['id']}_chunk_{i}" embedding = get_embedding(chunk) collection.add( ids=[chunk_id], embeddings=[embedding], documents=[chunk], metadatas=[{"source": doc["title"]}] ) print(f" ✅ {doc['title']}:切成 {len(chunks)} 块") print(f"索引建立完成,共 {collection.count()} 个文档块")
def search_v1(query, top_k=3): """在向量库中搜索最相关的文档块""" query_embedding = get_embedding(query) results = collection.query( query_embeddings=[query_embedding], n_results=top_k ) return results["documents"][0], results["metadatas"][0]def rag_query_v1(question): """V1 完整的 RAG 问答流程""" print(f"\n{'='*60}") print(f" V1 朴素 RAG") print(f" 问题: {question}") print(f"{'='*60}") # 第一步:检索 chunks, metadatas = search_v1(question, top_k=3) print(f"\n📚 检索到 {len(chunks)} 段相关内容:") for i, (chunk, meta) in enumerate(zip(chunks, metadatas)): print(f"\n [{i+1}] 来源:{meta['source']}") print(f" {chunk[:80]}...") # 第二步:把检索到的内容塞进 prompt context = "\n\n---\n\n".join(chunks) prompt = f"""请根据以下参考资料回答用户的问题。如果参考资料中没有相关信息,请如实告知。参考资料:{context}用户问题:{question}请直接回答,不要编造参考资料中没有的信息。""" # 第三步:让大模型生成回答 response = chat_client.chat.completions.create( model="deepseek-chat", messages=[{"role": "user", "content": prompt}] ) answer = response.choices[0].message.content print(f"\n✅ 回答:\n{answer}") return answer
# 先建索引(只需要跑一次)build_index_v1(documents)# 测试几个问题rag_query_v1("入职满5年有几天年假?")rag_query_v1("出差住酒店的报销标准是多少?")rag_query_v1("前端项目用什么构建工具?")
V1 跑起来了!但仔细看输出,有几个不太对劲的地方:- 切块太粗暴 ——按 200 字硬切,可能把一句话从中间劈开。
具体有多糟?看一下"请假制度"这篇文档的实际切块结果:块1: "公司请假制度(2024年修订版)一、年假规定 1. 入职满1年不满10年的 员工...4. 年假需提前3个工作日在OA系统中提交申" ← 注意这里块2: "请,直属上级审批通过后生效。5. 年假可以分次使用..." ← 断裂了!
"年假需提前3个工作日在OA系统中提交申 请 "被劈成了两半。如果用户问"年假怎么申请",块 2 的开头是"请,直属上级审批通过后生效"——缺了前半句,大模型根本看不懂这在说什么。- 检索结果没有过滤 ——召回的第三段"新人入职指南"跟年假问题根本无关,白白浪费 token。
- 没有重排序 ——向量搜索找到的"最相似"不一定是"最相关",有时候需要精排一下。
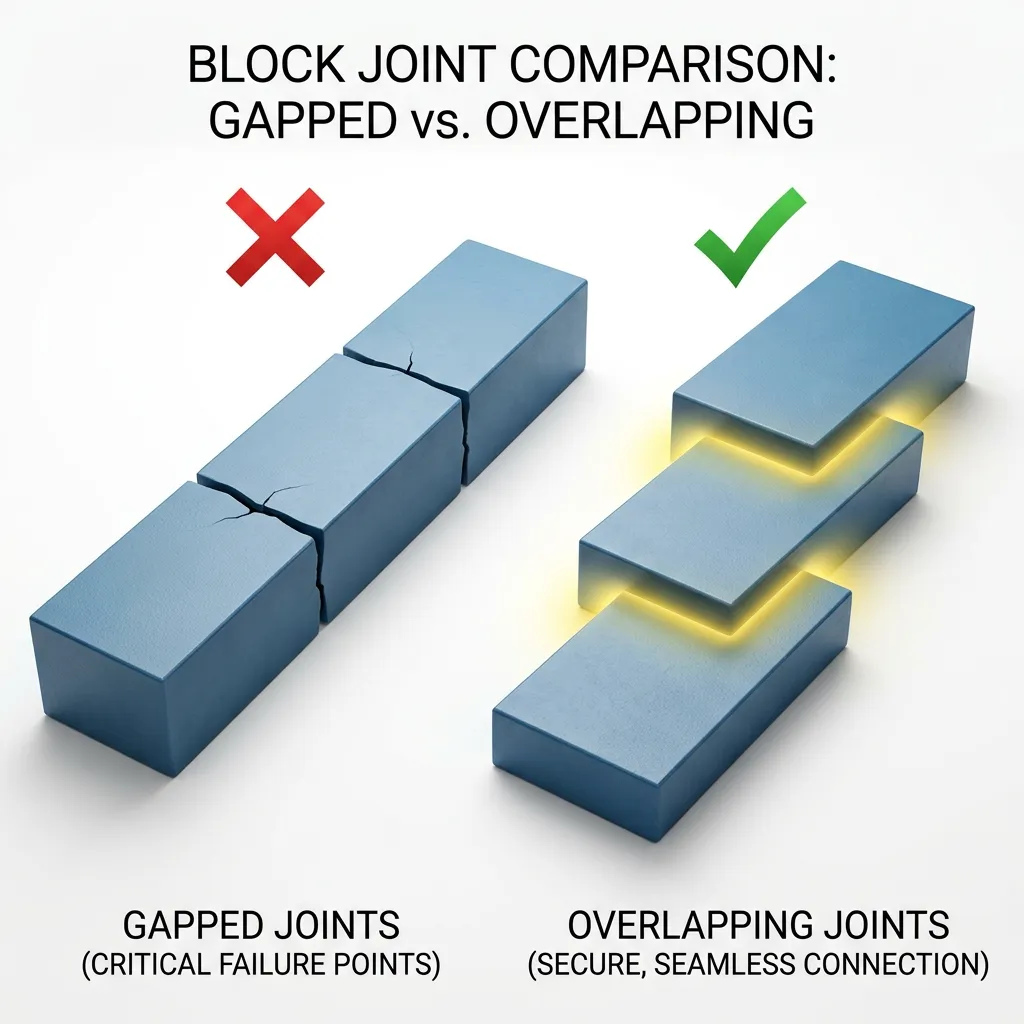
V1 的硬切问题怎么解决?很自然的想法——让相邻的块之间有一段重叠。一句话即使被切开了,在重叠区里还能保住完整的上下文。def overlap_chunk(text, chunk_size=200, overlap=50): """带重叠的分块:相邻块之间有 overlap 个字符的重叠""" chunks = [] start = 0 while start < len(text): end = start + chunk_size chunk = text[start:end].strip() if chunk: chunks.append(chunk) start += chunk_size - overlap # 关键:每次只前进 (chunk_size - overlap) return chunks
- `chunk_size` :中文场景下 200-500 字 是常见范围。太小(比如 50 字)会丢失上下文,大模型看到一个孤零零的半句话什么都推不出来;太大(比如 2000 字)会导致检索精度下降,而且浪费 token。- `overlap` :一般取 chunk_size 的 10%-25% 。本文的 50/200 = 25% 是比较激进的重叠率,好处是不容易断句,代价是索引体积会膨胀约 33%。- 没有"标准答案",取决于你的文档类型。建议先用默认值跑通,再根据实际检索效果微调——如果总是搜不到,先检查切块是不是太小了。V1 召回的结果里混入了不相关的内容。解决办法:给相似度设一个阈值,低于阈值的直接扔掉。首先,建 collection 的时候换成余弦相似度:collection_v2 = chroma_client.create_collection( name="company_docs_v2", metadata={"hnsw:space": "cosine"} # 使用余弦相似度)
L2 距离(欧氏距离)对向量的"长度"敏感——同一段话如果多写几个字,L2 距离就会变大,但语义其实没变。余弦相似度只看向量的"方向"不看"长度",更适合比较文本语义。简单记: 文本检索用余弦,图像检索用 L2 ,一般不会错。def build_index_v2(documents): """V2:重叠切块 + 入库""" print("正在建立 V2 索引...") for doc in documents: chunks = overlap_chunk(doc["content"], chunk_size=200, overlap=50) for i, chunk in enumerate(chunks): chunk_id = f"{doc['id']}_v2_chunk_{i}" embedding = get_embedding(chunk) collection_v2.add( ids=[chunk_id], embeddings=[embedding], documents=[chunk], metadatas=[{"source": doc["title"]}] ) print(f" ✅ {doc['title']}:切成 {len(chunks)} 块(带重叠)") print(f"V2 索引建立完成,共 {collection_v2.count()} 个文档块")def search_v2(query, top_k=5, threshold=0.6): """带相似度过滤的检索""" query_embedding = get_embedding(query) results = collection_v2.query( query_embeddings=[query_embedding], n_results=top_k, include=["documents", "metadatas", "distances"] ) filtered_chunks = [] filtered_metas = [] for doc, meta, distance in zip( results["documents"][0], results["metadatas"][0], results["distances"][0] ): similarity = 1 - distance # ChromaDB 余弦距离转相似度 if similarity >= threshold: filtered_chunks.append(doc) filtered_metas.append({**meta, "similarity": round(similarity, 3)}) return filtered_chunks, filtered_metas
阈值怎么选? 没有理论最优值,需要根据实际数据调优。以下是经验参考(不同 embedding 模型可能有差异):- 0.3-0.5 :沾点边,可能有用也可能是噪音实际项目建议先设 0.4,跑一批测试问题,看 漏检 (该召回没召回)和 误检 (不该召回的混进来了)的比例再调整。宁可阈值低一点多召回几段(浪费点 token),也别设太高把关键信息过滤掉了。def rag_query_v2(question): """V2 改进版 RAG:重叠分块 + 相似度过滤""" print(f"\n{'='*60}") print(f" V2 改进版 RAG") print(f" 问题: {question}") print(f"{'='*60}") chunks, metadatas = search_v2(question, top_k=5, threshold=0.3) if not chunks: print("\n❌ 未找到足够相关的文档内容") return "抱歉,知识库中没有找到与您的问题相关的内容。" print(f"\n📚 检索到 {len(chunks)} 段相关内容(已过滤低相关度):") for i, (chunk, meta) in enumerate(zip(chunks, metadatas)): print(f"\n [{i+1}] 来源:{meta['source']}(相似度:{meta['similarity']})") print(f" {chunk[:80]}...") context = "\n\n---\n\n".join(chunks) prompt = f"""请根据以下参考资料回答用户的问题。要求:1. 只基于参考资料中的信息回答,不要编造2. 如果参考资料不足以回答问题,如实告知3. 回答要准确、简洁、有条理参考资料:{context}用户问题:{question}""" response = chat_client.chat.completions.create( model="deepseek-chat", messages=[{"role": "user", "content": prompt}] ) answer = response.choices[0].message.content print(f"\n✅ 回答:\n{answer}") return answer
build_index_v2(documents)rag_query_v2("病假工资怎么算?超过30天怎么办?")
- 分块重叠后,"病假工资80%"和"超过30天"这两个信息点不再被切断
- 相似度过滤后,不相关的"新人入职指南"没有再混进来
不过还有个小毛病:向量搜索的排序不是完美的。有时候相似度 0.45 的那段(事假规定)排在前面,真正相关的反而靠后。接下来 V3 用 Rerank 来收拾这个问题。向量搜索是"粗筛"——速度快但不够精准,就像你在图书馆电脑上搜,搜出来一堆沾边的。Rerank 是"精排"——拿到粗筛结果后,用一个更强的模型挨个看"这段内容到底跟用户的问题有多大关系",然后重新排个序。V2 流程: 用户提问 → 向量搜索(粗筛) → 塞进 promptV3 流程: 用户提问 → 向量搜索(粗筛) → Rerank(精排) → 取 top N → 塞进 prompt实际项目中 Rerank 通常用专门的模型(比如 Cohere Rerank、BGE-Reranker),但这里我们用大模型来模拟这个过程,让你理解原理:Rerank 的代价: 多一次 LLM 调用,意味着多花一份钱、多等一份时间。对于简单问题(答案就在某一段里),V2 已经够用;只有当问题复杂(跨文档、涉及推理、需要综合多段信息)或对准确率要求极高(医疗、法律、财务)时,Rerank 的投入才划算。def rerank_with_llm(query, chunks, top_n=3): """用大模型对检索结果做重排序""" if len(chunks) <= top_n: return list(range(len(chunks))) chunks_text = "" for i, chunk in enumerate(chunks): chunks_text += f"\n[段落{i+1}]\n{chunk[:150]}...\n" prompt = f"""你是一个文档相关性评估专家。用户的问题是:"{query}"以下是从知识库中检索到的多个段落,请根据与用户问题的相关性进行排序。{chunks_text}请按相关性从高到低排列段落编号,只输出编号列表,格式如:1,3,2,5,4不要输出任何解释,只输出逗号分隔的编号。""" response = chat_client.chat.completions.create( model="deepseek-chat", messages=[{"role": "user", "content": prompt}], temperature=0 ) try: order_str = response.choices[0].message.content.strip() order = [int(x.strip()) - 1 for x in order_str.split(",")] return order[:top_n] except: return list(range(top_n))def rag_query_v3(question): """V3 完整版 RAG:重叠分块 + 相似度过滤 + Rerank""" print(f"\n{'='*60}") print(f" V3 Rerank 版 RAG") print(f" 问题: {question}") print(f"{'='*60}") # 第一步:粗筛——向量检索,多召回一些 chunks, metadatas = search_v2(question, top_k=6, threshold=0.25) if not chunks: return "抱歉,知识库中没有找到相关内容。" print(f"\n📚 粗筛:向量检索召回 {len(chunks)} 段") for i, (chunk, meta) in enumerate(zip(chunks, metadatas)): print(f" [{i+1}] {meta['source']}(相似度:{meta['similarity']})- {chunk[:50]}...") # 第二步:精排——Rerank 重排序 print(f"\n🔄 精排:Rerank 重排序中...") reranked_indices = rerank_with_llm(question, chunks, top_n=3) reranked_chunks = [chunks[i] for i in reranked_indices] reranked_metas = [metadatas[i] for i in reranked_indices] print(f"\n📚 精排后 Top {len(reranked_chunks)} 段:") for i, (chunk, meta) in enumerate(zip(reranked_chunks, reranked_metas)): print(f" [{i+1}] {meta['source']}(相似度:{meta['similarity']})- {chunk[:50]}...") # 第三步:生成回答 context = "\n\n---\n\n".join(reranked_chunks) prompt = f"""请根据以下参考资料回答用户的问题。要求:1. 严格基于参考资料回答,不编造信息2. 如果信息不足,如实告知3. 如果涉及数字、金额、时间等关键信息,务必准确引用4. 回答要结构清晰,重点突出参考资料:{context}用户问题:{question}""" response = chat_client.chat.completions.create( model="deepseek-chat", messages=[{"role": "user", "content": prompt}] ) answer = response.choices[0].message.content print(f"\n✅ 回答:\n{answer}") return answer
ragqueryv3( "我是新入职的员工,试用期工资打几折?转正后怎么评定绩效?拿到S评分有什么奖励?" )
这个问题横跨两篇文档(新人入职指南 + 绩效考核制度),V3 先粗筛拿到了 6 段候选,然后 Rerank 把最靠谱的 3 段捞出来,"请假制度"和"报销制度"这俩不沾边的就被淘汰了。- 内部 Demo、快速验证 → V1 (先跑通再说)
- 涉及金额、合规、医疗等不容出错的场景 → V3 (多花一份钱买一份保险)
https://github.com/qqzhangyanhua/aboutAgent.git 【Github地址】跑通这三个版本,RAG 的核心套路你就摸清了。想继续折腾的话,几个方向可以挖:- 分块策略还能更聪明 — 本文按字数切已经够用了,但实际项目里可以按段落切、按标题切,甚至用语义分块(让模型自己判断该在哪里切)。分块这一步做好了,后面怎么调都事半功倍。
- Rerank 换专业选手 — 用大模型做 Rerank 是为了演示原理,生产上建议用专门的 Reranker(Cohere Rerank、BGE-Reranker 之类),速度快 10 倍以上,成本低一个数量级,效果还更好。
- 上混合检索 — 纯向量检索有个死穴:对关键词和数字不敏感。搜"5天年假"可能搜不到那个"5"。加上 BM25 关键词检索做混合搜索,取长补短,这个问题就解决了。
- 接真实文档 — PDF、Word、网页怎么解析?推荐 `unstructured` 或 `LlamaIndex` 的 Document Loader,格式转换这种脏活它们干得挺好。
- 加对话记忆 — 现在每次提问都是独立的。加上对话历史管理,用户就可以追问"那事假呢?"而不用把前面的上下文再说一遍。
踩坑提醒: 很多人跑通 Demo 后直接上生产,最常翻车的不是模型不行,而是 分块没做好 。如果你发现回答不准确,别急着换模型或调 prompt——先回去看看你的切块结果,八成问题出在那里。回头看这三个版本,核心思路就一句话: 先搜再答 。V1 解决"能不能搜到",V2 解决"搜得准不准",V3 解决"排得对不对"。仔细想想,这跟你自己查资料其实一模一样——先搜一堆结果出来(V1),扫一眼标题把不靠谱的划掉(V2),最后点进去仔细读读哪个最对路(V3)。RAG 不过是把这套操作给自动化了而已。上篇文章我们造了个"会用工具的 AI",这篇造了个"会查资料的 AI"。下一篇,我们把这俩合体——让智能体 自己决定什么时候该查资料、查哪个知识库、查完不满意再换个姿势查 。那就是 Agentic RAG,也是这个系列的终章。https://github.com/qqzhangyanhua/aboutAgent.git 【Github地址】





 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
