Python|SAM3-基于文本提示的智能图像分割
- 2026-07-04 00:50:55

科研图像处理

SAM3(Segment Anything Model 3) 是 Meta AI 在 SAM 与 SAM2 基础上进一步提出的通用视觉分割模型。
https://github.com/facebookresearch/sam3
SAM3不仅提高了人工交互的分割效果,而且将自然语言文本提示(Text Prompt)引入分割流程,实现了视觉–语言协同驱动的图像分割范式 [1]。
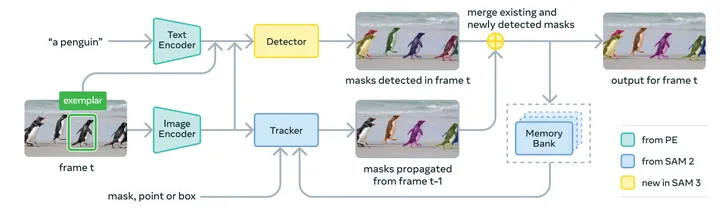
除了依赖人工选点、框,SAM3 还可以直接通过文本描述目标语义,模型可根据语义理解自动完成目标定位与精细分割。

之前的文章介绍了SAM2的安装和相关的应用:
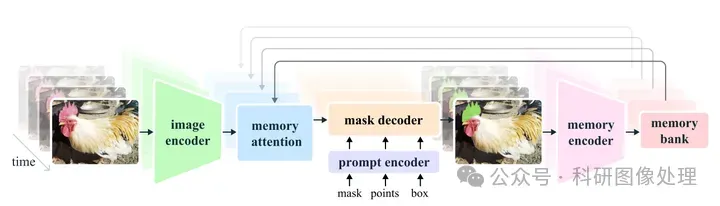

这篇文章会介绍SAM3的安装,以及怎么利用SAM3进行基于文本提示的图像分割。
一、SAM3安装
首先你需要在电脑上安装Anaconda,创建一个新的环境,激活该环境:
conda create -n sam3 python=3.12conda deactivateconda activate sam3
按照GPU dependency:
pip install torch==2.7.0 torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126Git clone SAM3的repository并安装:
git clone https://github.com/facebookresearch/sam3.gitcd sam3pip install -e ".[notebooks]"
另外需要安装:
pip install triton-windowspip install pandas
二、SAM3模型下载
SAM3的模型有两种下载方法:
1、modelscope下载
这种下载方法不需要申请权限,模型网址:
https://modelscope.cn/models/facebook/sam3
下载的方法:
pip install modelscopemodelscope download --model facebook/sam3
这种方法会将SAM3所有的模型文件,下载到一个model_modelScope文件夹中。
2、Hugging Face下载
SAM3官方的下载方式是在Hugging Face上下载:
https://huggingface.co/facebook/sam3
这种下载方法需要你注册Hugging Face账号,并且填写你的相关信息,用于获取下载SAM3模型的权限。
填写信息的时候,建议用Gmail或者Outlook邮箱。
Country如果填写China,会被Meta直接拒绝,需要填别的国家。
三、SAM3通过文本进行图像分割
1、加载SAM3模型
import osimport matplotlib.pyplot as pltimport numpy as npimport torchimport sam3from PIL import Imagefrom sam3 import build_sam3_image_modelfrom sam3.model.box_ops import box_xywh_to_cxcywhfrom sam3.model.sam3_image_processor import Sam3Processorfrom sam3.visualization_utils import draw_box_on_image, normalize_bbox, plot_resultssam3_root = os.path.join(os.path.dirname(sam3.__file__), "..")torch.backends.cuda.matmul.allow_tf32 = Truetorch.backends.cudnn.allow_tf32 = Truetorch.autocast("cuda", dtype=torch.bfloat16).__enter__()ckpt = r"G:\SAM\sam3\model_modelScope\sam3.pt" # <-- change to your local filemodel = build_sam3_image_model(checkpoint_path=ckpt,load_from_HF=False,device="cuda" if torch.cuda.is_available() else "cpu",eval_mode=True,)
这一步主要是加载SAM3模型的Checkpoint,文章中是通过modelscope下载的Checkpoint。
注意这里build_sam3_image_model,没有选择GitHub给的例子中的方法。
GitHub给的例子是通过:
bpe_path = f"{sam3_root}/assets/bpe_simple_vocab_16e6.txt.gz"model = build_sam3_image_model(bpe_path=bpe_path)
这个方法会从Hugging Face自动下载模型的Checkpoint。
2、导入图像
image_path = f"{sam3_root}/assets/images/mouse.jpg"image = Image.open(image_path)width, height = image.sizeprocessor = Sam3Processor(model, confidence_threshold=0.5)inference_state = processor.set_image(image)
3、输入文本Prompt
processor.reset_all_prompts(inference_state)inference_state = processor.set_text_prompt(state=inference_state, prompt="ears of each mouse")img0 = Image.open(image_path)plot_results(img0, inference_state)
这里我们选择分割小鼠的耳朵,得到分割结果:

如果输入文本是"tail of each mouse",可以分割得到小鼠的尾巴,并很好地和影子分开。

SAM3的GitHub也提供了一个交互版本的脚本:
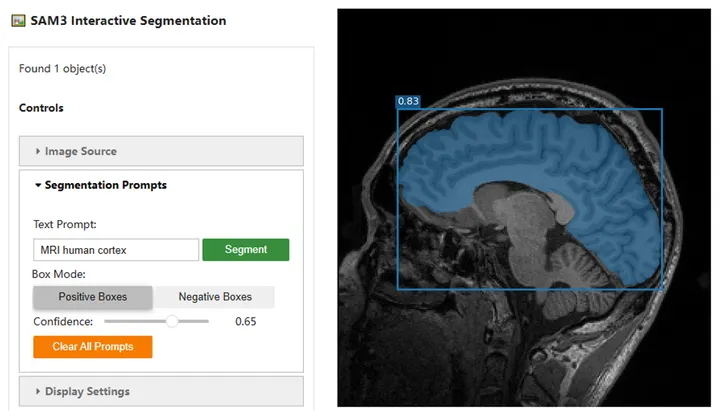
后面会介绍怎样利用SAM3进行视频中的物体分割与追踪,以及怎样结合大语言模型,使用SAM3 Agent对图像进行更为复杂的基于文本的分割。
希望对大家有帮助~
参考:https://arxiv.org/abs/2511.16719
往期推荐

点赞在看哦~

