昨天写了《财务共享中心搭建记录及一些坑_应付审核篇》,写着写着感觉应该先写篇财务数据清洗,所以先把这篇提到前面来写了,下一篇应该还是按原顺序,继续写财务共享中心搭建记录的资金出纳篇。不论是做财务共享系统、业财一体化系统搭建,还是做财务自动化/智能化小工具,一般都是需要先做一道财务数据清洗的,数据如果是乱七八糟的,很难进行下一步的自动化。只不过做系统搭建的时候,大多是开发人员来解决这个问题,但如果是咱财务想自己利用大模型自己做智能化工具,那这个数据清洗就得自己解决。财务是个强数据化的行当,就我自己来说,在做自动化之前,一个月可能一半的时间都花在数据处理上。下载报表、调整格式、删除空行、处理乱码、统一日期格式、从银行流水的备注中提取有用信息为自动生成日记账做准备……这些活儿,看着不起眼,实际上烦得要死。数据清洗的目的就一个:把不同格式的数据统一,让后续的自动分析、自动统计、自动成表都能顺利。第一种:格式不统一
第二种:空值乱入
第三种:多余字符
数字前后有空格(“ 1234.56 ”)
文本里有换行符、制表符
金额字段里混了文字(“1234.56元”)
第四种:重复数据
第五种:逻辑错误
金额应该是正数,结果是负数
日期应该是当月,结果是去年
借贷不平
二、Python清洗
Python做数据清洗,常用的库有三个:pandas(数据处理)、numpy(数值计算)、re(正则表达式)。
一、读取数据
import pandas as pdimport numpy as npimport re# 读取Exceldf = pd.read_excel('费用明细.xlsx')# 读取CSV(注意编码)df = pd.read_csv('银行流水.csv', encoding='utf-8')# 读取指定sheetdf = pd.read_excel('报表.xlsx', sheet_name='Sheet1')# 看一眼数据长啥样print(df.head())print(df.info())
二、清洗操作
# 查看哪些列有空值print(df.isnull().sum())# 删除全为空的行df = df.dropna(how='all')# 删除指定列为空的行df = df.dropna(subset=['凭证号', '金额'])# 填充空值(比如金额为空就填0)df['金额'] = df['金额'].fillna(0)# 字符串列空值填“未知”df['摘要'] = df['摘要'].fillna('无摘要')
# 去除字符串前后空格df['科目名称'] = df['科目名称'].str.strip()# 去除所有空格(包括中间)df['科目编码'] = df['科目编码'].str.replace(' ', '')# 去除换行符df['摘要'] = df['摘要'].str.replace('\n', '').str.replace('\r', '')# 去除金额字段里的逗号和货币符号df['金额'] = df['金额'].astype(str).str.replace(',', '').str.replace('¥', '').str.replace('元', '')
# 把各种乱七八糟的日期转成标准格式df['日期'] = pd.to_datetime(df['日期'], errors='coerce')# 如果转换失败(errors='coerce'会变成NaT),可以单独处理# 比如有的日期是"2023.01.01",先替换点再转df['日期'] = df['日期'].astype(str).str.replace('.', '-')df['日期'] = pd.to_datetime(df['日期'], errors='coerce')# 提取年月df['月份'] = df['日期'].dt.to_period('M')
# 转成数值类型df['金额'] = pd.to_numeric(df['金额'], errors='coerce')# 金额为负的,可能是红字冲销,单独标记df['是否红字'] = df['金额'] < 0df['金额绝对值'] = df['金额'].abs()# 金额异常的(比如超过100万),单独拎出来看看df_异常金额 = df[df['金额'] > 1000000]
# 查看重复行print(df.duplicated().sum())# 删除完全重复的行df = df.drop_duplicates()# 根据指定列去重(比如凭证号)df = df.drop_duplicates(subset=['凭证号'], keep='first')# keep='first'保留第一条,'last'保留最后一条
# 筛选出需要的列df = df[['日期', '凭证号', '摘要', '科目编码', '借方金额', '贷方金额']]# 筛选符合条件的行df_费用 = df[df['科目名称'].str.contains('管理费用|销售费用|财务费用')]df_大额 = df[df['金额'] > 10000]df_某月 = df[df['月份'] == '2023-12']
# 清洗完的数据重新设置索引df = df.reset_index(drop=True)# 保存到新Exceldf.to_excel('费用明细_已清洗.xlsx', index=False)# 如果想保留格式,可以用ExcelWriterwith pd.ExcelWriter('费用明细_清洗报告.xlsx') as writer: df.to_excel(writer, sheet_name='清洗后数据', index=False) # 单独存一页异常数据 df[df['金额'].isnull()].to_excel(writer, sheet_name='金额异常', index=False)
四、举个栗子
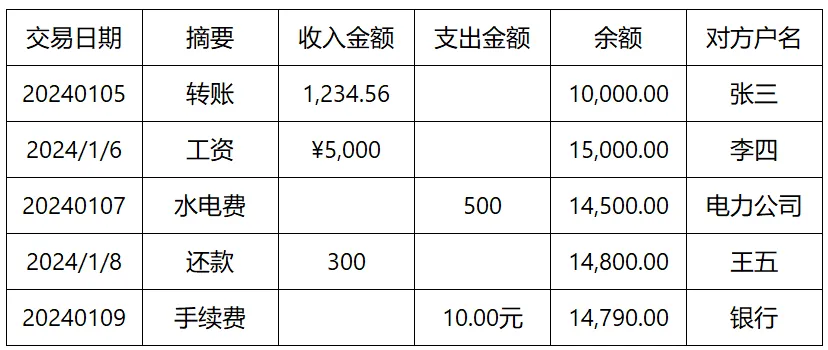
这是我从不同历史数据表格、不同账户里搜刮到的几条模拟账户流水:
很明显,不同的数据来源,很多信息的格式都不一样:
import pandas as pd# 读取数据df = pd.read_excel('银行流水_原始.xlsx')print("清洗前数据量:", len(df))# 1. 清洗日期df['交易日期'] = df['交易日期'].astype(str)df['交易日期'] = df['交易日期'].str.split(' ').str[0]df['交易日期'] = df['交易日期'].str.replace('/', '-')df.loc[df['交易日期'].str.len() == 8, '交易日期'] = \ df['交易日期'].str[:4] + '-' + df['交易日期'].str[4:6] + '-' + df['交易日期'].str[6:8]# 2. 清洗金额# 收入金额df['收入金额'] = df['收入金额'].fillna(0).astype(str)df['收入金额'] = df['收入金额'].str.replace('¥', '').str.replace('元', '').str.replace(',', '')df['收入金额'] = pd.to_numeric(df['收入金额'], errors='coerce').fillna(0)# 支出金额df['支出金额'] = df['支出金额'].fillna(0).astype(str)df['支出金额'] = df['支出金额'].str.replace('¥', '').str.replace('元', '').str.replace(',', '')df['支出金额'] = pd.to_numeric(df['支出金额'], errors='coerce').fillna(0)# 余额df['余额'] = df['余额'].fillna(0).astype(str)df['余额'] = df['余额'].str.replace('¥', '').str.replace('元', '').str.replace(',', '')df['余额'] = pd.to_numeric(df['余额'], errors='coerce').fillna(0)# 3. 根据摘要填写资金类别df['资金类别'] = '待确认'df.loc[df['摘要'].str.contains('工资', na=False), '资金类别'] = '管理费用'df.loc[df['摘要'].str.contains('水电', na=False), '资金类别'] = '管理费用'df.loc[df['摘要'].str.contains('还款', na=False), '资金类别'] = '其他应收款'df.loc[df['摘要'].str.contains('手续费', na=False), '资金类别'] = '财务费用'# 4. 判断借贷方向df['借贷方向'] = '平'df.loc[df['收入金额'] > 0, '借贷方向'] = '借'df.loc[df['支出金额'] > 0, '借贷方向'] = '贷'# 5. 处理空值df['对方户名'] = df['对方户名'].fillna('未知')df['摘要'] = df['摘要'].fillna('无摘要')# 6. 选择要保留的列最终数据 = df[['交易日期', '摘要', '收入金额', '支出金额', '余额', '对方户名', '借贷方向', '资金类别']]print("\n清洗后数据:")print(最终数据)# 7. 保存文件并设置金额格式with pd.ExcelWriter('银行流水_清洗后.xlsx', engine='openpyxl') as writer: 最终数据.to_excel(writer, index=False, sheet_name='银行流水') # 获取工作表 worksheet = writer.sheets['银行流水'] # 设置C、D、E列(收入、支出、余额)为两位小数格式 from openpyxl.styles import numbers for row in range(2, len(最终数据) + 2): # 从第2行开始(第1行是标题) # C列(收入金额) worksheet[f'C{row}'].number_format = numbers.FORMAT_NUMBER_00 # D列(支出金额) worksheet[f'D{row}'].number_format = numbers.FORMAT_NUMBER_00 # E列(余额) worksheet[f'E{row}'].number_format = numbers.FORMAT_NUMBER_00print("\n清洗完成!文件已保存为:银行流水_清洗后.xlsx")print("金额格式已设置为显示两位小数(0.00)")
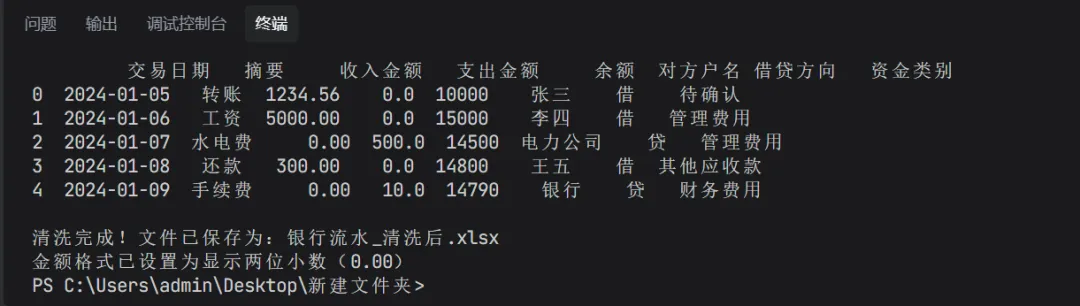
用Python代码跑一下,就可以统一格式并自动出具日记账所需要的类别,在编辑器里的调试结果长这样:
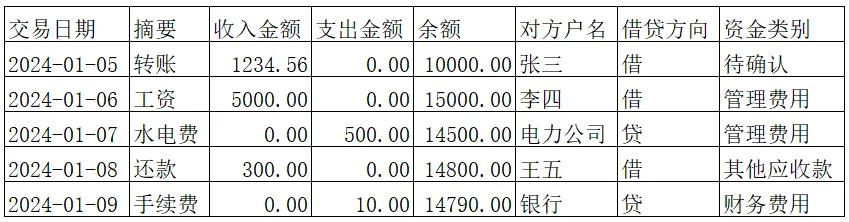
自动生成的新数据长这样:
上面这些代码看着简单,但如果不会写或者懒得写怎么办?
找个AI,告诉它你想干什么:
“我有一个Excel文件叫‘银行流水_原始.xlsx’,里面的日期格式乱七八糟,帮我统一成YYYY-MM-DD格式。金额都清洗成纯数字,保存时设置金额为两位小数。根据摘要自动归类:工资/水电→管理费用,还款→其他应收款,手续费→财务费用,转账→待确认;收入为借,支出为贷”
大概就会得到类似上面的代码,复制到编辑器里运行就行了。报错了就把报错信息贴回去让它继续改。
六、清洗工作的几个习惯
1、永远保留原始数据
别在原文件上改。复制一份,或者代码里读取原始文件,另存为“已清洗”版本。万一改错了,还能回去找。
2、每一步代码都要写注释
# 步骤1:读取原始数据# 步骤2:处理日期# 步骤3:清洗金额# 步骤4:去重# 步骤5:保存清洗结果
3、异常数据单独存
清洗过程中发现的数据问题——金额为负、日期异常、空值太多——别直接删,另存一个文件,方便排查。
4、每一步打印结果出来看看
print(f"原始数据量:{len(df)}")print(f"删除空行后:{len(df_after_dropna)}")print(f"去重后:{len(df_after_dedup)}")print(f"发现异常金额:{len(df_outlier)}笔")
有人可能想问,这些单纯的数据整理工作,VBA也可以做。
这话没错,但VBA只能处理纯Excel工作,如果想做从登录系统下载数据、到Excel自动整理、到系统自动录入(比如再回头把日记账数据录入到系统)的全流程自动化,VBA是做不到的,但Python自动化工具/大模型应用就可以做到,看你只是想节省一部分时间,还是整个事儿都想让电脑自己干。
大概就这些
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
