图解 Linux 文件系统:从 open() 到落盘,一次读懂
- 2026-07-01 15:02:33
Linux 文件系统深度解析:从 open() 到磁盘,一次读懂
作者:小康,C/C++编程博主
关键词:Linux、文件系统、VFS、inode、Page Cache、open()、ext4
前言
有一行代码,每个 C/C++ 程序员都写过:
int fd = open("config.json", O_RDONLY);一行调用,看起来轻描淡写。但你有没有想过,这背后到底发生了什么?
内核是怎么找到这个文件的?数据从磁盘到内存经过了哪几层?为什么第二次读同一个文件会快很多?
这篇文章,我们顺着 open() 这行代码,把 Linux 文件系统从上到下捋一遍。
一、先建立整体概念:Linux 文件系统分几层?
Linux 文件系统不是一个单一的东西,而是分层设计的。
最上层是你写的代码(open / read / write),最底层是磁盘上真实的 0 和 1。中间隔了好几层抽象。
从上到下分别是:
系统调用层: open()、read()、write()等,是用户空间进入内核的入口VFS(虚拟文件系统):Linux 的文件系统抽象层,让不同的文件系统(ext4、xfs、tmpfs…)对上层提供统一接口 具体文件系统:ext4、xfs、btrfs 等,实现真正的文件组织逻辑 Page Cache:内存中的磁盘数据缓存,读写先经过这里 块设备层:管理 I/O 调度,向下驱动磁盘 磁盘驱动 + 硬件:最终的物理存储
这是文章的主线,我们一层一层往下走。
先看完整的调用链路图:
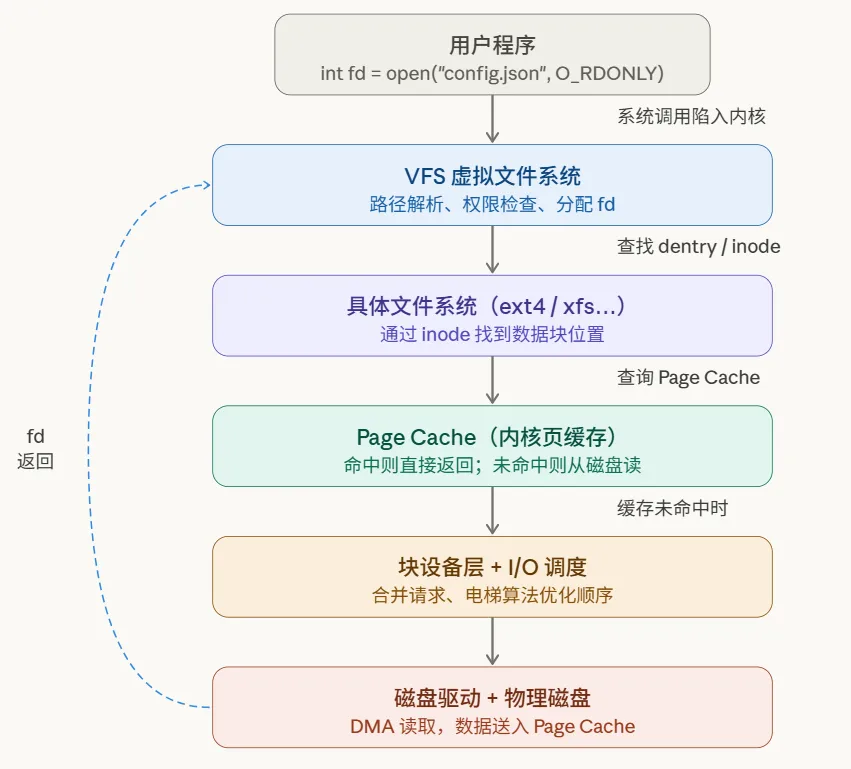
先看完整的调用链路图:这张图是全文的主线。下面我们顺着这条链路,逐层展开。
二、VFS:为什么 Linux 能同时支持几十种文件系统?
你在 Linux 上可以同时挂载 ext4 分区、xfs 分区、NTFS U盘、甚至内存里的 tmpfs,对你的程序来说,open() / read() / write() 的用法一模一样。
这是怎么做到的?
答案是 VFS(Virtual File System,虚拟文件系统)。
VFS 是 Linux 内核里的一层抽象,它定义了一套统一的"接口规范",所有具体文件系统(ext4、xfs…)都必须实现这套接口。你的代码只和 VFS 打交道,VFS 再去调用具体文件系统的实现。
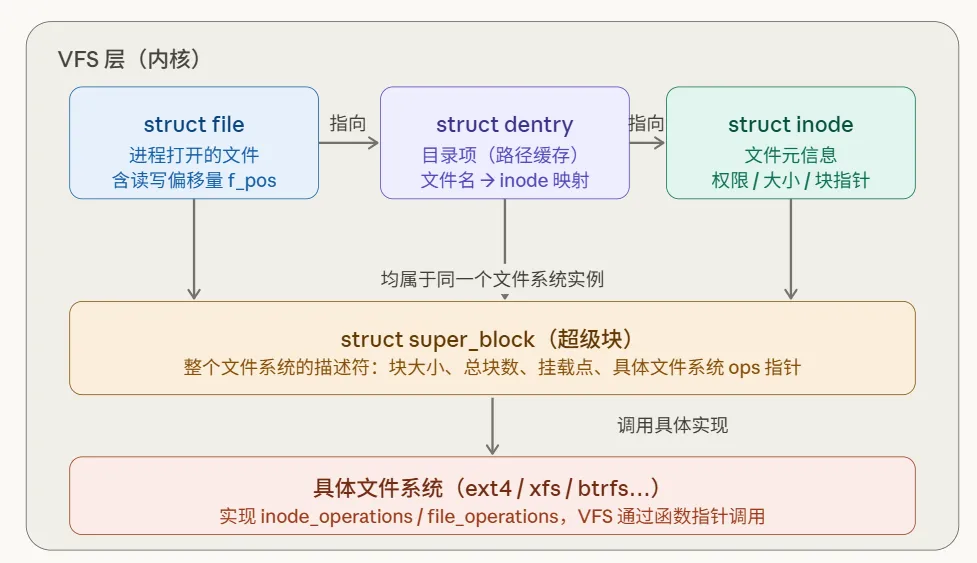
VFS 里有四个核心数据结构:
superblock:描述整个文件系统(挂载点、块大小等元信息)inode:描述一个文件(权限、大小、数据块位置……但不含文件名)dentry(目录项):把文件名映射到 inode,是路径解析的关键file:进程打开文件时创建的结构,持有当前读写偏移量
它们的关系如下图:
三、inode:文件的"身份证"
inode(index node)是 Linux 文件系统里最核心的概念,没有之一。
一个文件 = 一个 inode + 若干数据块。
inode 里存的是文件的"元信息",注意:inode 里不存文件名,文件名存在目录的 dentry 里。这也是为什么硬链接(hard link)可以让两个文件名指向同一份数据:它们共享同一个 inode。
inode 里存了什么:
inode { uid / gid // 属主 mode // 权限(rwxrwxrwx) size // 文件大小 atime/mtime/ctime // 访问/修改/变更时间 block[15] // 数据块指针(直接/间接/双重间接)}block[] 数组是 inode 找到实际数据的关键。前 12 个是直接块指针,第 13 个指向一级间接块(存放更多块指针),第 14 个是二级间接,第 15 个是三级间接——这样设计,一个文件理论上可以存储数 TB 的数据。
四、open() 内核路径:路径是怎么被解析的?
当你调用 open("/home/user/config.json", O_RDONLY) 时,内核要做这几件事:
第一步:路径解析(namei)
从根目录 / 开始,逐级解析路径分量:
先找 /(根 dentry),得到根 inode再找 home(查目录的数据块,找到 "home" 对应的 inode 号)再找 user,再找config.json每一级都优先查 dentry cache(dcache),命中则不用读磁盘
第二步:权限检查
找到 inode 后,检查当前进程的 uid/gid 是否有读权限。
第三步:分配 fd
通过检查,内核在进程的文件描述符表里找一个空槽,创建 struct file 对象,把它和 inode 关联,返回这个槽的下标——就是你拿到的 fd。
// 每个进程的 task_struct 里有:structfiles_struct {structfile *fd_array[NR_OPEN_DEFAULT];// fd 表// fd_array[0] = stdin// fd_array[1] = stdout// fd_array[2] = stderr// fd_array[3] = 你的 config.json};五、Page Cache:为什么第二次读文件快很多?
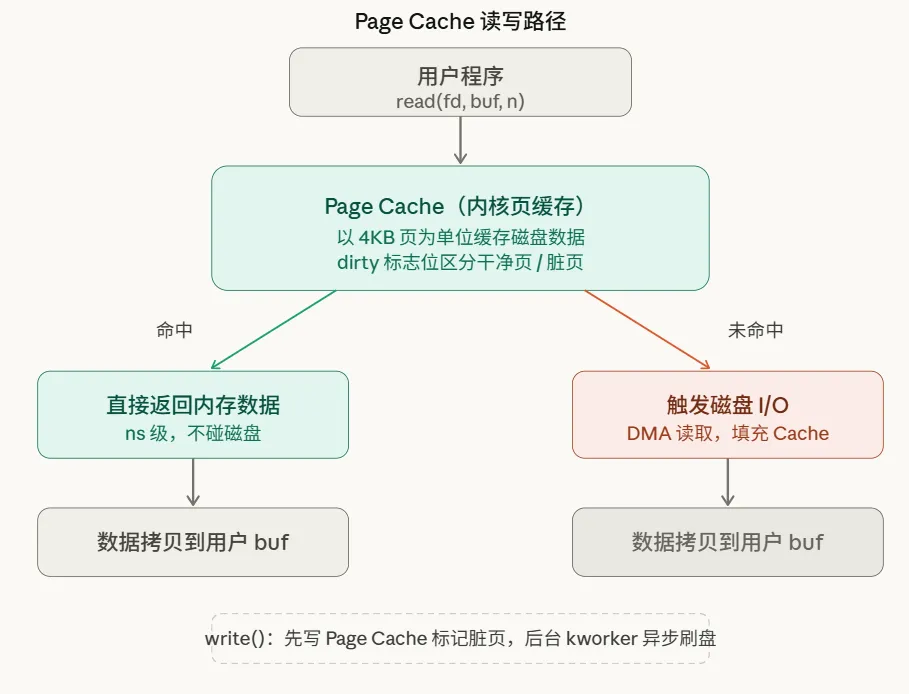
文件读写不会直接操作磁盘,而是先经过内核的 Page Cache(页缓存)。
Page Cache 是内核在内存里维护的磁盘数据缓存,以 4KB 的页(Page)为单位。
读文件时:
先查 Page Cache,命中直接返回(内存速度,ns 级) 未命中,从磁盘读数据填充 Page Cache,再返回(磁盘速度,ms 级)
写文件时(默认):
数据先写入 Page Cache,标记为"脏页"(dirty page) 内核后台 pdflush/kworker异步把脏页刷回磁盘如需立即落盘,调用 fsync(fd)
这就是为什么第二次 read() 同一个文件会快很多——数据还在 Page Cache 里,不用碰磁盘。
六、数据真正写到磁盘上是什么样的?
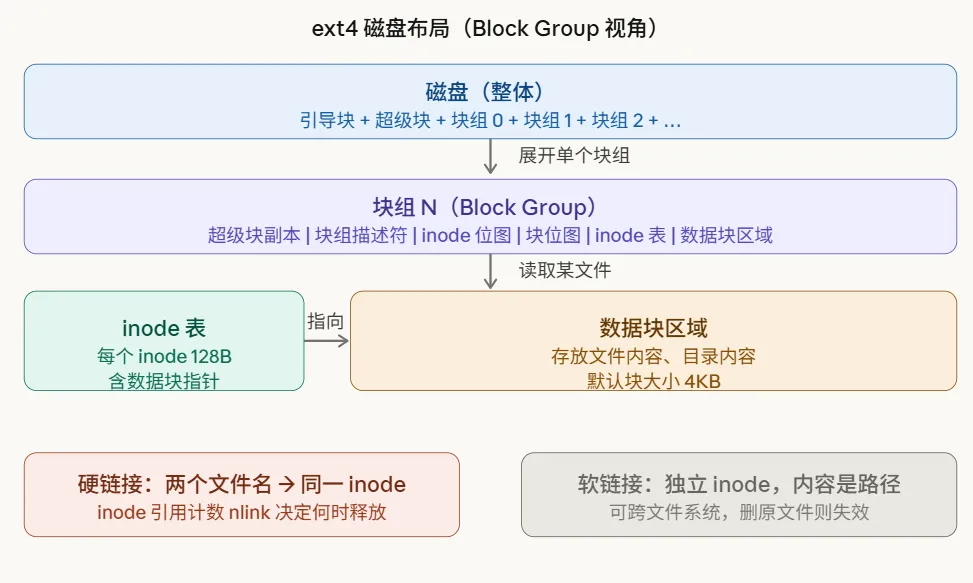
以 ext4 为例,磁盘被切分成若干块组(Block Group),每个块组包含:
超级块副本:文件系统的全局元信息 块组描述符:这个块组的 inode 表、数据块在哪里 inode 位图:哪些 inode 已被占用 数据块位图:哪些数据块已被占用 inode 表:存放所有 inode 的数组 数据块区域:真正的文件内容
七、几个有意思的细节
为什么删除文件后,磁盘空间没有立即释放?
删除文件(unlink)只是把目录里的 dentry 移除,inode 的引用计数(nlink)减一。只有 nlink == 0 且没有进程打开这个文件时,inode 才真正被释放,磁盘空间才归还。
所以,如果一个进程正在读一个文件,另一个进程删了它——文件的数据依然可以被读完,直到进程关闭 fd。
为什么 ls -i 可以看到 inode 号?
$ ls -i /etc/passwd1234567 /etc/passwdinode 号是 inode 在 inode 表里的索引,内核通过它直接定位到对应的 inode 结构体,O(1) 查找。
/proc 和 /sys 里的文件为什么没有磁盘上的实体?
它们是 procfs 和 sysfs,是挂载在内存里的"虚拟文件系统"。read() 它们时,内核不是从磁盘读数据,而是动态生成内容——比如读 /proc/meminfo 就是内核实时统计了一下内存使用情况后返回给你。这也是 VFS 抽象的威力:用户代码无需关心文件在不在磁盘上。
八、代码实战:一次完整的文件读取
#include<fcntl.h>#include<unistd.h>intmain(){// 1. open: 路径解析 → 权限检查 → 分配 fdint fd = open("/etc/hostname", O_RDONLY);char buf[64] = {0};// 2. read: 查 Page Cache → 命中直接返回 / 未命中则读磁盘ssize_t n = read(fd, buf, sizeof(buf) - 1);// 3. 数据已在 buf,inode 的 atime 被更新 write(STDOUT_FILENO, buf, n);// 4. close: struct file 引用计数 -1,fd 回收// Page Cache 里的数据不会被清除(留给下次使用) close(fd);return0;}注意 close(fd) 并不会让 Page Cache 的数据消失。只有内存紧张时,内核才会按照 LRU 策略把干净页驱逐出去。这就是为什么服务器跑一段时间后,free 命令看到的可用内存会变少——那些内存被 Page Cache 占着,但随时可以被回收,不是真的"不够用"。
九、高频面试题精析
Q:inode 里存不存文件名?
不存。文件名存在目录的数据块里(dentry),inode 只存元信息。这就是为什么 rename 操作在同一文件系统内极快——只需修改 dentry,不需要移动数据。
Q:硬链接和软链接有什么本质区别?
硬链接:两个目录项指向同一个 inode,删除一个不影响数据,nlink 减一,直到 0 才真正删除。软链接:独立的 inode,内容是目标路径字符串,删原文件后软链接失效(变成"悬挂链接")。
Q:为什么说 Page Cache 对性能影响极大?
内存访问延迟约 100ns,机械盘随机读约 10ms,相差 10 万倍。Page Cache 命中率高的程序,I/O 性能可以提升几个数量级。数据库调优中的"热数据全在内存"本质上就是充分利用 Page Cache。
Q:write() 返回之后数据一定落盘了吗?
不一定。默认情况下只是写入了 Page Cache(脏页),后台异步刷盘。要保证落盘,需要调用 fsync(fd) 或 fdatasync(fd)。数据库在 commit 时必须调 fsync,否则宕机可能丢数据。
结语
从 open() 到磁盘,我们走过了:
用户调用 → 系统调用 → VFS(dentry/inode/file)→ 具体文件系统 → Page Cache → 块设备层 → 磁盘每一层都是一层精心设计的抽象——VFS 让你的代码不关心底层是什么文件系统,Page Cache 让 I/O 性能飞起来,inode 让文件的元信息和内容解耦。
理解了这些,你才能真正读懂数据库为什么要配置 O_DIRECT,才能理解 Kafka 的 Page Cache 利用策略,才能在面试里把"文件系统"这道题答到面试官点头。
还在打基础?从这里开始
如果你读完这篇还觉得 C、C++、Linux 有些陌生,别急——我也开设了三门入门课程,从零带你打好地基,快速上手项目实战:
C 语言快速入门 :大一啃完谭浩强的书,还是不会写代码?我花1个月做了套'12天速成'的C语言课 C++ 快速入门 :12天,从C++小白到独立做项目!我把3年踩坑经验浓缩成了这门课 Linux 编程快速入门 :为什么你学了半年 Linux 编程,还是写不出一个像样的程序?
感兴趣可以了解一下。
基础扎实了?来做工业级项目
如果你已经有一定基础,想冲击更高的天花板,这些工业级 C++ 项目正是为你准备的:
| 线程池 | |
| 高性能日志库 MiniSpdlog | |
| 高性能内存池 | |
| 多线程下载工具 | |
| MySQL 连接池 | |
| 内存泄漏检测器 | |
| ReactorX | |
| 无锁栈 | |
| 工业级智能指针(shared_ptr) | |
| 高性能网络库 NetCore | |
| 高性能异步日志库 ZephyrLog | |
| 死锁检测工具 | |
| 高性能 HTTP 服务器 | |
| 协程库 CoroForge | |
| 高性能 HTTP 压测工具 | |
| Redis 核心模块实战 |
每个项目都是真实可用的工程代码,不是教学玩具。
详情点击 C++ 项目合集课程链接:为什么同样是"学过C++",有人面试碾压,有人开口就怂?差距在这18个C++硬核项目
对C++项目实战课程感兴趣的朋友,可以扫下方二维码添加小康微信(或微信搜索:jkfwdkf) 备注「 项目实战 」 项目可以打包购买,有优惠

觉得有收获,点赞、推荐和转发支持下哦~ 🙏
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Linux进程大赏:从“祖宗进程”到“打工进程”,看完秒懂进程的一生
- Linux系统磁盘-文件系统学习笔记
- Linux 磁盘与文件 I/O 深度笔记
- 我愿称之为:Python最伟大的网站(没有之一
- 【体系教程】Python支持下最新Noah-MP陆面模式站点、区域模拟及可视化分析
- 黄仁勋 :干嘛还学Python?未来最牛编程语言是英语?
- 初学Python练题:函数,编写一个点餐程序
- GEE(Python版本)全球样本+深度学习预测
- 2026开学特惠 | GEE(Python版本)深度学习与全球制图分析实战特训教学
- 《码上仿真:Abaqus Python API》Vol.4 Repository Abaqus 里的“超级字典”
