Linux使用系统追踪工具分析性能
一、perf介绍
Linux性能计数器(PCL)是一个基于内核的子系统,它为收集和分析性能数据提供了一个框架。在 Red Hat Enterprise Linux 8中包含了PCL和PERF。PERF是一个功能强大的分析基础设施,它 提供了一套用户空间工具用来分析收集到的性能数据。 性能数据是测量的硬件和软件事件的集合。性能事件是特定条件的发生,比如处理器完成一组指令 时,或者应用程序出现页面错误时。计算机处理器使用一组性能计数器来计数性能事件。 PERF定义了一组常用的性能事件,并提供工具列出事件计数或记录在一份报告中供以后分析。
1、安装
在BaseOS软件仓库中就有perf,但是如果你想在一个机器上搜集数据,然后在另外一个机器上分 析数据,你就需要安装kernel-debuginfo和kernel-debuginfo-common软件,这两个软件必须 要指定和内核对应的版本
2、perf基本用法
perf List 列出特定计算机上可用的事件。这些事件根据系统的性能监控硬件和软件配置而不同。 perf stat 提供常见性能事件的总体统计信息,包括执行的指令和使用的时钟周期。选项允许选择事件,而不 是默认的度量事件。 perf record 将性能数据记录到文件中,供后期分析。 perf report 从perf record命令生成的文件中读取性能数据。 perf archive 使用"perf record"命令生成的性能数据文件中的目标文件创建存档,以便在另一台机器上分析这些信息。
3、pertstat
perf命令度量来自多个源的事件。例如,许多软件事件来自内核计数器,而典型的硬件事件来自 处理器的性能监视单元(PMU)。系统上的可用事件因处理器类型和模型的不同而不同。 task-clock:任务真正占用的处理器时间,单位为ms。CPUs utilized = task-clock / time elapsed,CPU的占用率。 context-switches:上下文的切换次数。 CPU-migrations:处理器迁移次数。Linux为了维持多个处理器的负载均衡,在特定条件下会将 某个任务从一个CPU迁移到另一个CPU。 1.5perfrecord和perfreport 1.6创建perf archive page-faults:缺页异常的次数。当应用程序请求的页面尚未建立、请求的页面不在内存中,或 者请求的页面虽然在内存中,但物理地址和虚拟地址的映射关系尚未建立时,都会触发一次缺页异 常。另外TLB不命中,页面访问权限不匹配等情况也会触发缺页异常。 cycles:消耗的处理器周期数。如果把被命令使用的cpu cycles看成是一个处理器的,那么它的 主频为2.486GHz。可以用cycles / task-clock算出。 instructions:执行了多少条指令。IPC为平均每个cpu cycle执行了多少条指令。 branches:遇到的分支指令数。 branch-misses:是预测错误的分支指令数。 可以使用-e参数查看特定的事件
4、perfrecord和perfreport
perf record命令记录一段时间内的一些示例。默认频率为每秒采集4000个示例。这些值可以从 命令行调整。抽样的好处是,当你收集到足够多的个体样本时,你将产生一个统计上有意义的结 果,从而减少测量误差。 perf record命令的输出默认保存当前目录下,名字叫做perf.data perf report能读取缺省的perf.data文件,--stdion参数会将结果输出到屏幕上 下面的perf record命令记录整个系统中上下文切换的采样事件,周期为10秒,报告输出将保存 在cs-syswide.data里面 perf record -o cs-syswide.data -e context-switches -a sleep 10 可以使用perf report -i cs-syswide.data --stdio来打印出报告,-i参数可以指定性能数 据文件
5、创建perf archive
perf archive命令读取缺省的perf.data文件,将他们打包并压缩到当前的目录下,这种打包压 缩后的性能数据文件你可以将他们拷贝到远端的主机上,解压后再进行分析。
二、systemcall和library call介绍
要评估程序的性能,你必须度量程序执行的任务以及执行每个任务所需的时间。程序用它们的程序 代码来完成任务。如果一个程序调用内核提供的函数,那么执行时间是在内核内部进行的。 library提供的函数会导致程序在内核之外花费时间。从程序中调用"内核提供的函数是系统调 用",而由"库提供的函数称为库调用"。系统调用处理由Linux内核提供的函数。系统调用总是特定于操作系统。当执行一个系统调用时, 程序时间花费在被调用的内核内部函数上。在内核中花费的程序执行时间称为系统时间(system time)。例如,"open"是一个打开文件的典型系统调用。库调用是由程序库提供的调用。程序库可以在程序之间共享,以降低所需功能的冗余。有些库抽象 了特定于操作系统的系统调用。这允许在不同的操作系统之间移植软件,因为只需要调整所需的库 来与目标操作系统一起工作。一个广泛使用的库示例是glibc,即GNU C-Library。这个库允许程 序员在Linux上用C编程语言编写和编译代码。花费在库函数上的程序执行时间称为用户时间 (user time)。 Red Hat Enterprise Linux 8包含了ltrace命令来跟踪库调用。该命令支持跟踪禁用位置独立 可执行文件(PIE)选项编译的二进制文件。要检查二进制文件是否使用此选项编译,请使用file命 令。file命令返回ELF 64-bit LSB可执行文件作为禁用PIE选项编译的二进制文件的输出。
1、追踪system call系统调用
strace(system trace)实用程序显示进程进行的系统调用的信息。这个命令帮助标识出程序使 用内核函数花费了多长时间。 strace命令可以使用"另一个命令"作为参数。它将运行提供的命令,显示程序所做的每个系统调用。例如,要查看运行uname时执行的系统调用,可以使用strace启动命令: #strace uname 除此之外你还可以使用strace加上process id来追踪系统调用 #strace -p 3124 出于性能调优的目的,有时只显示计数而不是详细的函数调用信息会更有帮助。这样会产生一个总 结报告,并显示执行系统调用的频率,以及在程序执行期间花费了多少时间。使用-c参数只显示计 数。 #stace -c uname 当与-f参数一起使用时,strace跟踪并配置fork()系统调用创建的子进程。默认情况下,不追踪 子进程的信息。下面的strace命令显示系统调用和fork的子进程: 3.1Systemtap介绍 3.2安装systemtap主机系统 #strace -fc elinks -dump http://classroom.example.com/pub #elinks是纯文本界面的浏览器,-dump:将HTML文档以纯文本的方式打印到标准输出设备; 有时,strace的输出很长。使用-e表达式开关,可以过滤strace的输出,使其只显示特定的系统 调用。例如,要只显示使用uname的open系统调用的计数,执行以下命令: #strace -e open -c uname
三、Systemtap介绍
SystemTap是一个跟踪和探测工具,用于动态分析正在运行的内核的活动。SystemTap提供了一个 基础设施来监视系统性能并查明性能问题的根本原因。SystemTap脚本通过使用Linux内核中的 kprobes工具指定在哪里附加探针以及在执行探针时收集什么数据。 SystemTap脚本背后的基本思想是给事件命名并为它们提供处理程序(handlers)。每当指定的事 件发生时,内核就会像快速子程序一样运行处理程序(handlers),然后恢复正常处理。事件的种 类有很多,例如进入或退出一个函数、计时器过期或整个SystemTap会话开始或停止。处理程序 (handlers)是一系列脚本语言语句,它们指定当事件发生时要做的工作。这项工作通常包括从事 件上下文提取数据、将数据存储到内部变量或打印结果。 正常情况下,SystemTap脚本只能在安装了SystemTap的系统上运行。这可能意味着在要分析的每 个系统上安装完整的SystemTap编译器、内核头文件、源代码和debuginfo内核包。在许多情况 下,在生产系统上提供编译工具是不可行的,也不安全,而且这些工具通常被公司政策所禁止。相 反,SystemTap提供了一种称为cross-instrumentation(跨仪器)的功能。 cross-instrumentation是在主机系统上从SystemTap脚本生成SystemTap检测内核模块的过 程,该模块将在目标系统上使用。通常,主机系统是一个非生产系统,配置了生成仪表模块所需的 编译器工具。主机系统可以安装多个内核版本和相关的内核信息包,以匹配将运行检测模块的所有 目标系统的内核版本。
1、安装systemtap主机系统
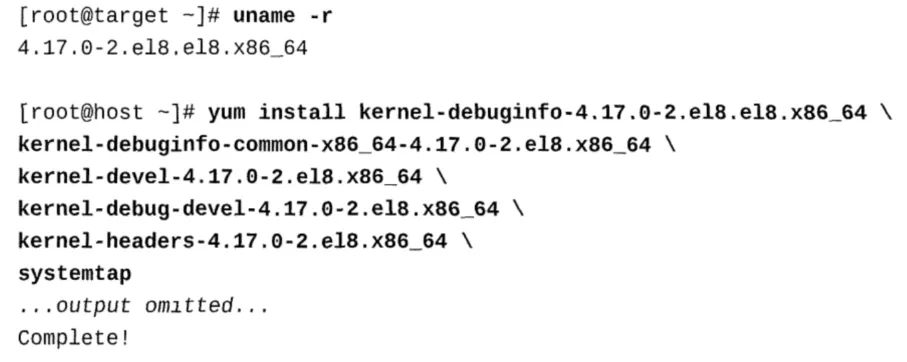
为了准备SystemTap,你需要安装SystemTap包和与内核相匹配的kernel-devel、kerneldebuginfo和kernel-debuginfo-common-arch软件包。如果你想使用SystemTap主机系统为多 个目标内核编译工具,你需要为每个内核版本安装其相应的devel和debuginfo包。所有主机内核 版本和包集必须是匹配的架构。 #不要安装kernel-debug包,因为这不是SystemTap使用的内核,而且它不会加载所需的调试符 号。相反,kernel-debug是一个为开发诊断用途启用调试代码的内核。 SystemTap主机系统需要内核源代码、调试符号、编译器和其他支持包。通常,这些包不会安装在 生产系统上。生产系统通常已经启用了BaseOS和Appstream存储库。如果你想安装需要的 kernel-debuginfo包,可以使用对应的命令开启对应的软件仓库。
2、使用stap-prep安装systemtap
安装systemtap软件的同时也会安装编译器、头文件和调试包,但不会安装debuginfo包。使用 stap-prep来定位和安装任何需要的任何匹配的内核头信息和调试信息。 #yum -y install systemtap 安装systemtap相当于安装了所需的gcc编译器、库和头文件,以及内核源代码和头文件。通过使 用uname-r查询正在运行的内核版本,验证内核源代码和头包与正在运行的内核版本匹配。 使用stap-prep命令定位和安装剩余的内核包。验证以前安装的内核包和这些剩余的内核包是相同 的内核版本。 #stap-prep #手工安装 当向SystemTap主机系统添加额外的内核包集时,你将手动安装。你应该验证每个内核、头文件、 devel和debuginfo集都是匹配的内核发行版。当SystemTap编译实现模块时,如果版本和运行在 host上的内核不同,如果无法定位该版本的符号、头和源代码,systemTap将出错并退出。在下 面的示例中,将检查目标系统的内核版本,以确定要安装在主机系统上的内核包集。
3、使用systemtap
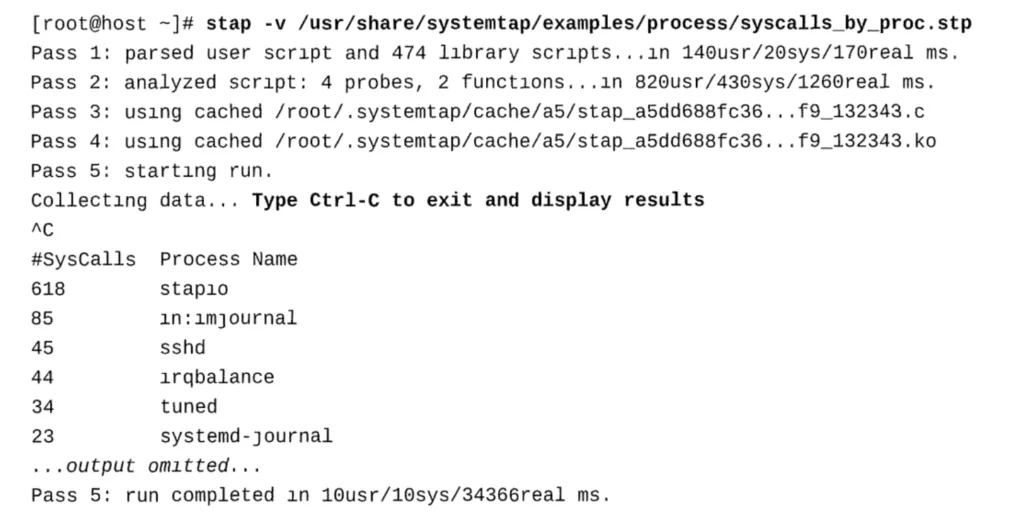
SystemTap主机中的stap命令是SystemTap工具的前端,用于在主机系统上解释、编译和运行 SystemTap脚本。当脚本第一次编译时,systemtap会在用户的家目录里面的.Systemtap目录中 缓存一个已编译对象。如果检测到源脚本未被修改,则stap将在后续运行中使用缓存的对象。 stap命令处理SystemTap脚本分为5个pass: Pass 1 - parse:这个阶段主要是检查输入脚本是否存在语法错误,例如大括号是否匹配,变量 定义是否规范等 Pass 2 - elaborate:这个阶段主要是对输入脚本中定义的探测点或者用到的函数展开,不但需 要综合SystemTap的预定义脚本库,还需要分析内核或者内核模块的调试信息 Pass 3 -translate: 在这个阶段,将展开后的脚本转换成C文件。前三个阶段的功能类似于编 译器,将.stp文件编译成为完整的.c文件,因此又被合起来称为转换器(translator)Pass 4 - build:在这个阶段,将C源文件编译成内核模块,在这过程中还会用到SystemTap的 运行时库函数。 Pass 5 - run:这个阶段,将编译好的内核模块插入内核,开始进行数据收集和传输。 使用-v参数将会列出它执行的每个pass
4、编译可移植内核模块
SystemTap生成通用唯一标识符来命名所创建的内核模块。当创建模块分发给目标系统使用时,模 块可以被赋予有用的名称。因为实现模块之前是编译的,并且在正确分布和放置在目标系统上时是 只读的,所以没有特权的用户能够加载和运行这些模块。正如前面所讨论的,模块是针对特定的内 核版本编译的,并且只能在具有相同内核版本的目标系统上运行才能正确运行。 下面示例使用stap命令处 理/usr/share/systemtap/examples/process/syscalls_by_proc.stp脚本并且在当前目录 创建syscalls_by_proc模块 stap-p 4 -v-m syscalls_by_proc /usr/share/systemtap/examples/process/syscalls_by_proc.stp -p 4参数处理pass 4 -v参数允许用户看到正在处理的pass -m syscalls_by_proc参数命名syscalls_by_proc.ko模块并且将它生成在当前目录里面。 内核模块名字只能使用小写字母,大写字母,数字和下划线。
5、非特权用户使用systemtap
staprun命令是SystemTap的后端工具,用于运行由前端stap命令创建并分发到目标系统的内核 模块。stap和staprun命令需要提高系统特权。要运行SystemTap模块,必须将非特权用户添加 到stapusr或stapdev组中。下面列出了相关的组权限: stapusr组成员:只能使用staprun命令,不能编译systemtap模块,可以运行任何被系统管理员 放在/lib/modules/$(uname-r)/systemtap目录中的模块,也可以写和加载低权限脚本模块,这些模块通常都被限制在操作它们自己的进程范围内。 stapdev组成员:可以像root一样编写和加载脚本模块,而不需要特殊的安全约束。成员可以使 用stap或staprun命令来运行SystemTap模块。如果用户同时也是stapusr组成员,他们可以使 用staprun命令从任何目录加载模块。

Red Hat建议限制特权SystemTap访问,因为特权访问允许将内核模块编译和加载到运行的内核 中。
四、eBPF介绍和BCC介绍
1、eBPF
Extended Berkeley Packet Filter (eBPF)是一个在内核内部的虚拟机,它在一个安全的、 受限制的环境中运行自己的字节码。它最初设计用于捕获和过滤网络数据包,利用现代硬件的优势 现在已经对该技术进行了扩展,并提供了一种安全的方式来扩展内核功能。eBPF是从用户空间启 用的,受限于它所使用的内存数量,并且对设备的访问受限。 eBPF的工作原理是将程序附加到各种内核点,如kprobes、跟踪点和perf事件。有许多性能分析 工具利用了扩展的内核功能,不仅允许过滤数据包。这些增强允许在Linux上执行定制的分析程 序,用于动态跟踪、静态跟踪和分析事件。 你可以编写自己的eBPF程序,或者使用可用的前端应用程序之一中可用的现有程序。BPF跟踪的一 个流行前端应用程序是BPF compiler collection(BCC)eBPF的概念最早源自于BSD操作系统中的BPF(Berkeley Packet Filter),1992伯克利实验 室的一篇论文 “The BSD Packet Filter: A New Architecture for User-level Packet Capture”。这篇论文描述了,BPF是如何更加高效灵活地从操作系统内核中抓取网络数据包的。 我们很熟悉的tcpdump工具,它就是利用了BPF的技术来抓取Unix操作系统节点上的网络包。 Linux系统中也沿用了BPF的技术。 在BPF实现的基础上,Linux在2014年内核3.18的版本上实现了eBPF,全名是Extended BPF,也 就是BPF的扩展。这个扩展主要做了下面这些改进。首先,对虚拟机做了增强,扩展了寄存器和指 令集的定义,提高了虚拟机的性能,并且可以处理更加复杂的程序。其次,增加了eBPF maps,这 是一种存储类型,可以保存状态信息,从一个 BPF 事件的处理函数传递给另一个,或者保存一些 统计信息,从内核态传递给用户态程序。最后,eBPF可以处理更多的内核事件,不再只局限在网 络事件上。你可以这样来理解,eBPF的程序可以在更多内核代码hook点上注册了,比如 tracepoints、kprobes等。
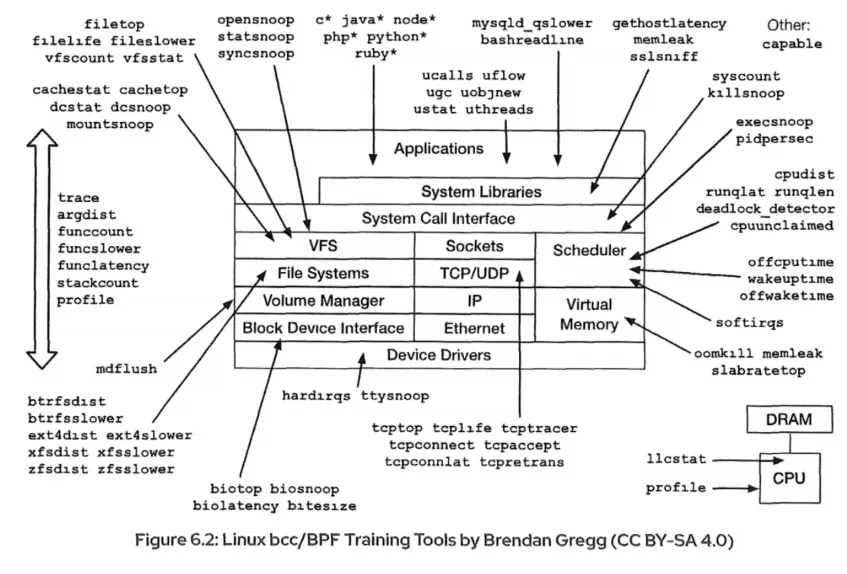
2、BCC
#介绍 编写eBPF程序需要从内核源代码编译并链接到eBPF库。这对于内核开发人员来说很好,但是对于 其他人来说,比如那些在生产系统上工作的人,拥有现有的程序可能是更理想的方法。BCC包含编 写程序所需的组件,还提供了示例程序和用于调试和诊断性能问题的现有工具。 #BCC安装 yum-y install bcc-tools 安装完bcc-tools之后,你可以查看工具和文档,分别在/usr/share/bcc/tools 和/usr/share/bcc/tools/doc目录下,你也可以使用man命令查看BCC tools的man pages。
3、使用BCC工具
1、追踪新进程 execsnoop工具追踪新的进程,例如,execsnoop追踪execve()系统调用并且展示参数和返回值 的细节。它抓取fork->exec序列中新的进程。应用fork()新进程但是不exec(),比如worker进 程是不包含在execsnoop的输出里面的,因为它不在forc->exec序列里面。 #列说明 PCOMM—父进程的命令名称。 PID—进程ID。 PPID—父进程ID。 RET—返回值。 ARGS—带参数的文件名。 2、追踪open()系统调用 opensnoop工具追踪open()系统调用,列出进程的名字和路径名字细节。opensnoop是一个在应 用启动期间非常有用的发现配置文件和日志文件的工具。 列说明: PCOMM—父进程的命令名称。 PID—进程ID。 FD—文件描述符。 ERR—系统错误数量。 PATH—路径。 3、追踪XFS操作 xfsslower工具显示了xfs文件系统的读,写,打开,文件同步,默认查看慢于10ms的进程。 4、追踪块设备延迟和IO biolatency工具跟踪块设备I/O(磁盘I/O),记录I/O时延(时间)的分布。按下Ctrl+C键结束跟 踪,生成直方图并显示在终端上。第一列单位为微秒。 biosnoop工具追踪块设备的IO。 5、追踪缓存命中和miss 命中率越高,表示使用缓存带来的收益越高,应用程序的性能也就越好。 缓存是现在所有高并发系统必需的核心模块,主要作用就是把经常访问的数据(也就是热点数 据),提前读入到内存中。这样,下次访问时就可以直接从内存读取数据,而不需要经过硬盘,从 而加快应用程序的响应速度。 cachestat工具跟踪内核页缓存函数,并以每秒的速度打印摘要。cachestat输出对于一般的工作 负载和识别操作使用中的模式非常有用。 HITS:缓存命中次数; MISSES:缓存未命中次数; DIRTIES:加入缓存脏页数; RATIO:缓存命中率; BUFFERS_MB:buffers大小,单位:MB; CACHED_MB:cache大小,单位:MB; 6、追踪主机名解析延迟 gethostlatency工具跟踪getaddrinfo()和gethostbyname()函数的主机名查找调用。它以毫 秒为单位显示调用的延迟(持续时间)和主机字符串。这个工具可以通过识别哪个远程主机名查找速 度慢以及慢了多少来识别DNS延迟。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
