Python3之网络爬虫-----初识
- 2026-06-30 10:39:21
1、爬虫之 URL 简介
网络爬虫(web spider)是根据网页地址(URL) 爬取网页内容,网页地址即我们在网站中输入的网站链接;
URL:专业叫法是统一资源定位符(Uniform Resource Locator),它的一般格式如下
scheme://[userinfo@]host[:port][/path][?query][#fragment]
解释:
scheme(协议):例如 http, https, ftp, file等。指定使用的协议。
userinfo(用户信息):可选,包含用户名和密码(不推荐在URL中包含密码)。格式:username:password@。
host(主机):域名或IP地址。
port(端口):可选,如果省略则使用协议的默认端口。
path(路径):资源在服务器上的路径,以斜杠/开头。
query(查询字符串):可选,以?开头,用于传递参数,格式通常是key=value对,用&分隔。
fragment(片段标识符):可选,以#开头,用于指定资源内的一个片段(如HTML中的锚点)。
2、网页简介
在写爬虫代码之前我们需对网页有一定的了解;
在浏览器的地址输入 URL 地址,在网页处右键点击,找到检查,如下图:
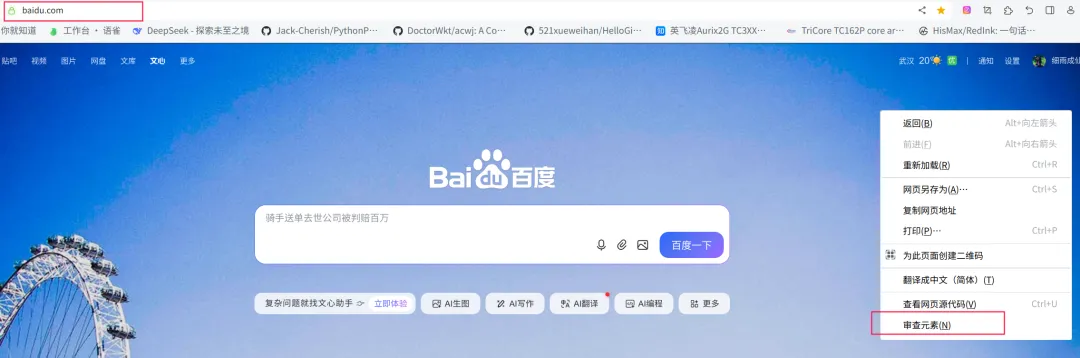
单击检查会出现一大堆代码,这些代码就做 HTML,爬虫就是爬取这些 HTML 内容;
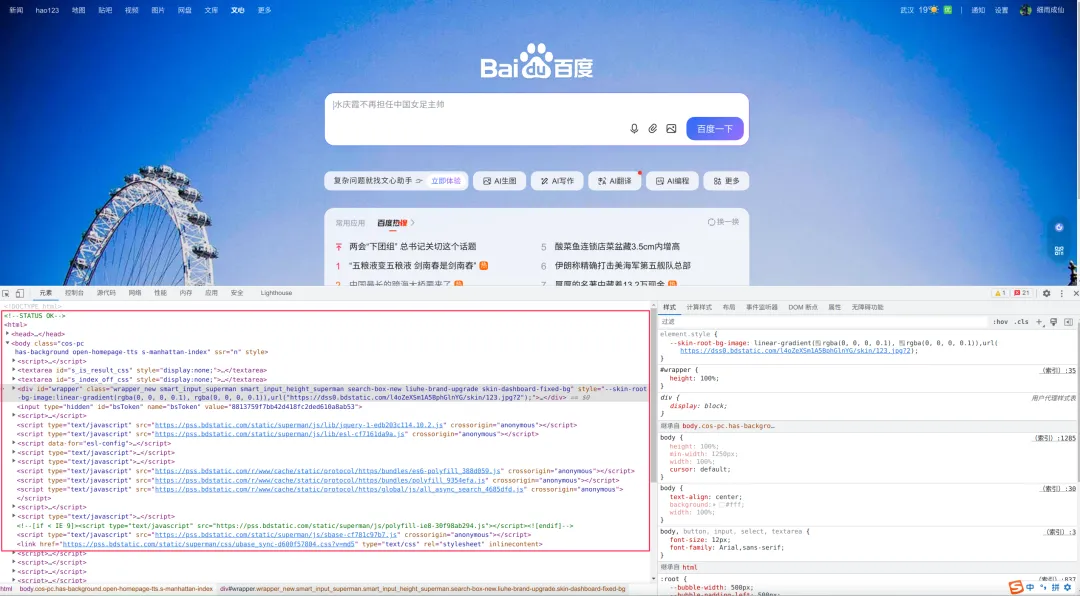
3、爬虫简单实例
在 Python3 中可以使用 urllib.request 进行爬取,urllib 是 Python3 自带的内置库;
一般会使用更强大的 requests 库;
3.1、requests 安装
可在命令窗口(cmd)中,使用如下指令按照
pip install requests
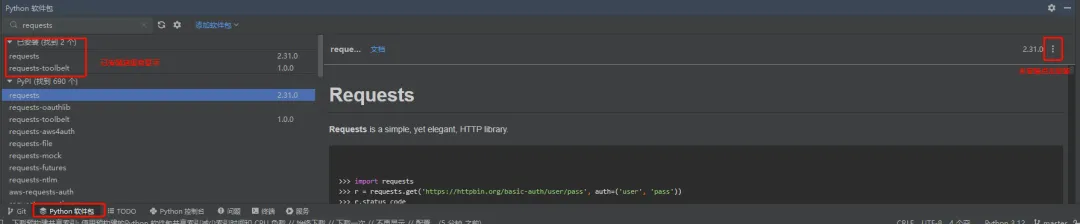
或在 PyCharm IDE 中安装相关软件包,如下图:
3.2、requests 库简介

requests 库官方说明文档:https://requests.readthedocs.io/en/latest/
3.3、代码示例
我们使用 requests.get()方法,向网页服务器发起 GET 请求,获取数据,代码如下:
import requestsif __name__ == '__main__':#目标网页URL地址baidu_url = "http://fanyi.baidu.com/"#发送GET请求获取网页内容req_data = requests.get(url = baidu_url)#设置响应编码为UTF-8,避免中文乱码req_data.encoding = 'utf-8'#打印网页HTML源代码print(req_data.text)
程序运行结果如下: