HN上281票,评论区全是"WTF":一个叫danveloper的开发者在24小时内写了8200行纯C代码,让397B参数的大模型在MacBook Pro上以4.4 tokens/秒稳定运行。没有Python,没有PyTorch,没有任何AI框架。
danveloper/flash-moe GitHub 项目
397B意味着什么
先建立一个直觉:
-
- GPT-3:1750亿参数(2020年,震惊世界)
-
- LLaMA 3.1 70B:700亿参数(需要多张A100)
-
- Flash-MoE模型(Qwen3.5-397B-A17B):3970亿参数
-
- 磁盘占用:209GB(4-bit量化)
-
这个模型通常需要企业级GPU集群才能运行。danveloper让它在一台48GB内存的MacBook Pro上跑起来了,每秒输出4.36个token,支持完整的tool calling功能。
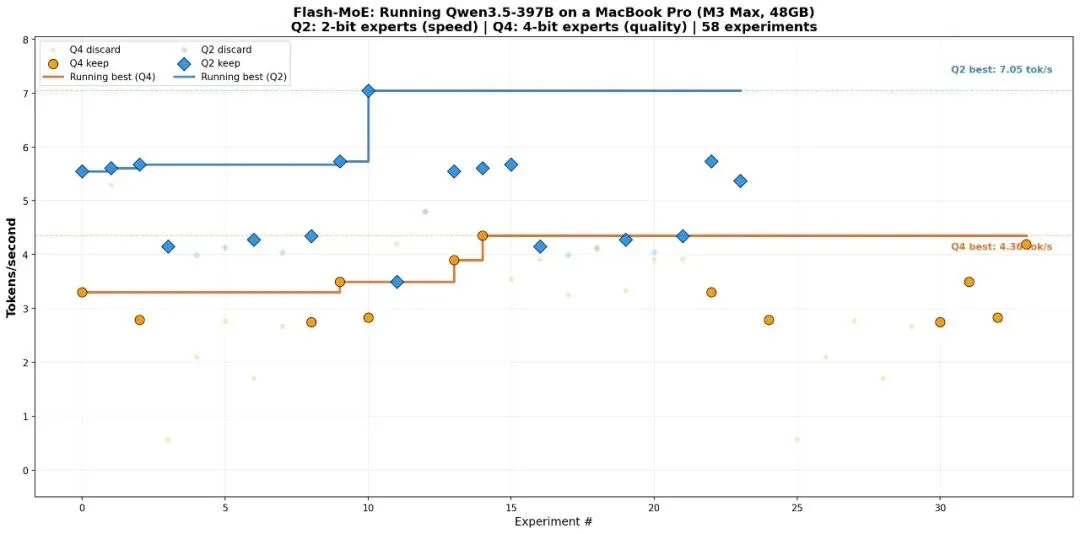
flash-moe 性能测试数据
核心技术:让硬盘成为"第二大脑"
MoE(Mixture of Experts,专家混合)架构是这一切成为可能的关键。Qwen3.5-397B-A17B虽有397B参数,但每个token只激活其中极少一部分。
Flash-MoE关键参数
-
- 总层数:60层(45层线性注意力 + 15层标准注意力)
-
- 每层专家数:512个
-
- 每个token激活:K=4个专家(+1个共享专家)
-
- 每次加载数据:约 6.75MB × 4 = 27MB
-
- MacBook SSD读取速度:17.5 GB/s
-
每生成一个token,程序只从硬盘读取4个"专家"的权重,约27MB数据。MacBook Pro的SSD每秒能读17.5GB,这个速度足以支撑推理。其余2000亿参数则静静躺在硬盘里,等待被激活。
这个思路来自Apple自己的研究论文《LLM in a Flash》(2023),但danveloper把它变成了真正可用的代码。
90+次实验换来的4.4 tokens/s
项目里有一个results.tsv记录了所有实验。以下是哪些方案有效,哪些失败了:
✅ 有效的优化
-
- FMA融合乘加内核:GPU计算快12%(把量化+乘法合并为一条GPU指令)
-
- 信任操作系统页面缓存:删掉自己写的LRU缓存后,速度反而提升38%
-
- BLAS加速线性注意力:CPU注意力计算快64%(0.78ms→0.28ms)
-
- 延迟执行GPU命令:CPU准备下一层时GPU同步计算,无等待
-
❌ 失败的优化(全部被放弃)
-
- LZ4压缩专家权重:速度反而降13%(解压开销 > 缓存节省)
-
- 预测专家路由:速度降18%(预测命中率只有25%,白白消耗带宽)
-
- mmap映射专家文件:速度降5倍(冷数据的每页错误开销太高)
-
- 自旋轮询GPU等待:速度降23%(CPU发热与GPU争抢资源)
-
一个有趣的发现:苹果Silicon上,SSD直接内存访问(DMA)和GPU共用同一内存控制器,两者无法真正并行——任何背景SSD读取都会让GPU速度下降73%。所以最终方案是串行流水线:GPU算完→SSD读→GPU算。看似低效,实际是硬件最优解。
速度与质量的权衡
| 配置 |
速度 |
质量 |
磁盘占用 |
| 4-bit + FMA内核 | 4.36 tok/s | 优秀(支持tool calling) | 209GB |
| 2-bit量化 | 5.74 tok/s | 尚可(JSON格式损坏) | 120GB |
| 2-bit峰值单token | 7.05 tok/s | 不适用(tool calling失效) | 120GB |
2-bit量化后速度可达5.74 tokens/秒,但JSON输出会出错,把英文引号"name"输出成\name\,导致tool calling完全不可用。4-bit才是生产配置。
AI+人类24小时协作完成
项目的README里有一句话值得记住:
"Read the paper — Full technical details, 90+ experiments, and the story of how an AI and a human built this in 24 hours."
这不是一个人写的。开发者和AI协作,一天之内完成了8200行C代码和1200行Metal着色器。项目包括:
-
- 完整的MoE推理引擎(infer.m,~7000行)
-
- 手写Metal GPU着色器(shaders.metal,~1200行)
-
- 交互式对话界面(支持tool calling)
-
- C语言BPE分词器(单头文件,449行)
-
我的判断
Flash-MoE揭示了一个被低估的趋势:消费级硬件的SSD带宽,正在成为AI推理的新战场。
过去两年,推理加速的主战场是GPU显存带宽(HBM3e,每秒TB级)。但MoE模型的稀疏激活特性改变了规则——你不需要把整个模型装进显存,只需要足够快的存储。苹果Silicon统一内存架构(CPU/GPU共用)+高速NVMe SSD,意外地成了本地MoE推理的理想平台。
4.4 tokens/秒不是很快,但对于一个本地离线模型来说完全够用。更重要的是,这证明了不需要数据中心,不需要每月$20的API费用,你可以在本机运行比GPT-4同级别的模型。
接下来12个月,预计会看到:M4 Pro/Max版本性能大幅提升(48GB→128GB内存选项);更多针对苹果Silicon优化的MoE模型出现;以及云服务商对本地推理崛起的防御性反应。
来源: GitHub danveloper/flash-moe(https://github.com/danveloper/flash-moe)| Hacker News #47476422(281票)
纯C代码,零框架依赖

