大家好,今天分享一个非常实用的案例: 👉 如何用 Python + Pandas 实现一个“志愿填报录取系统”,并自动生成最终录取结果表(Excel版)
这个案例非常适合:
一、需求
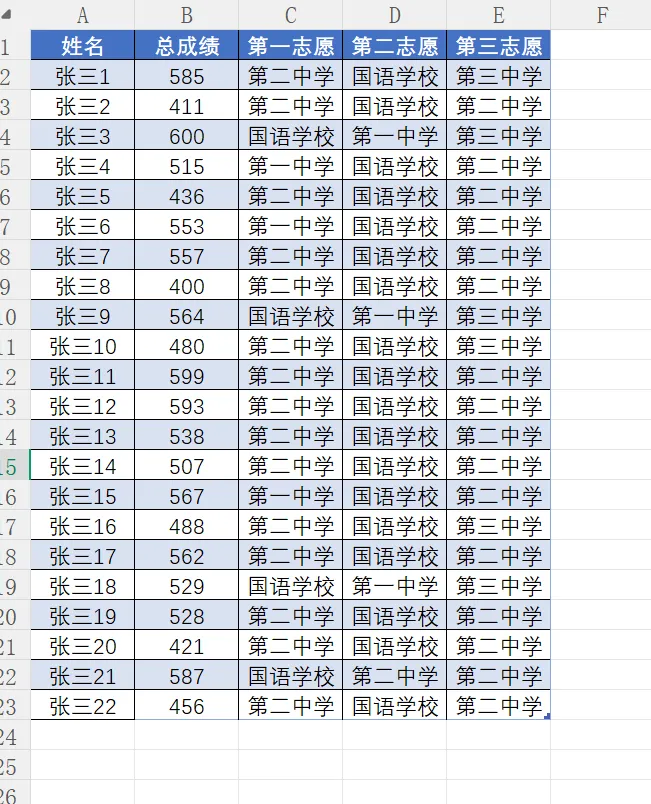
Excel 数据如下:
以及对应的学校录取分数线:
📌 目标: 实现一个“模拟录取系统”:
1️⃣ 按志愿顺序录取(1→2→3)
2️⃣ 满足分数线才录取
3️⃣ 最终按学校输出录取名单(Excel表格)
二、核心思路
整个流程可以拆成 4 步:
① 读取 Excel 数据
df = pd.read_excel("20260321data.xlsx")
② 定义分数线规则
score_line = {"第二中学": 560,"国语学校": 530,"第一中学": 517,"第四中学": 500,"第三中学": 460}
👉 这里有个关键点: “第二中学”存在两个批次(560 / 500)
所以我们用:
来区分批次逻辑(非常关键🔥)
③ 核心录取算法(重点)
defadmit(row): score = row["总成绩"]# 第一志愿优先if score >= 560and row["第一志愿"] == "第二中学":return"第二中学"if score >= 530and row["第一志愿"] == "国语学校":return"国语学校"if score >= 517and row["第一志愿"] == "第一中学":return"第一中学"if score >= 460and row["第一志愿"] == "第三中学":return"第三中学"# 第二志愿if score >= 530and row["第二志愿"] == "国语学校":return"国语学校"if score >= 517and row["第二志愿"] == "第一中学":return"第一中学"if score >= 500and row["第二志愿"] == "第二中学":return"第四中学"if score >= 460and row["第二志愿"] == "第三中学":return"第三中学"# 第三志愿if score >= 500and row["第三志愿"] == "第二中学":return"第四中学"if score >= 460and row["第三志愿"] == "第三中学":return"第三中学"return"未录取"
🔥 这段代码的本质
👉 模拟现实录取规则:
④ 批量计算录取结果
df["录取学校"] = df.apply(admit, axis=1)
三、生成最终录取表(核心亮点🔥)
目标效果:
实现全部源代码:
import pandas as pd# =============================# 1. 读取 Excel# =============================df = pd.read_excel("20260321data.xlsx")# =============================# 2. 分数线# =============================score_line = {"第二中学": 560,"国语学校": 530,"第一中学": 517,"第四中学": 500, # 关键:区分两个第二中学"第三中学": 460}# =============================# 3. 录取逻辑(关键🔥)# =============================defadmit(row): score = row["总成绩"]# 第一志愿if score >= 560and row["第一志愿"] == "第二中学":return"第二中学"if score >= 530and row["第一志愿"] == "国语学校":return"国语学校"if score >= 517and row["第一志愿"] == "第一中学":return"第一中学"if score >= 460and row["第一志愿"] == "第三中学":return"第三中学"# 第二志愿if score >= 530and row["第二志愿"] == "国语学校":return"国语学校"if score >= 517and row["第二志愿"] == "第一中学":return"第一中学"if score >= 500and row["第二志愿"] == "第二中学":return"第四中学"if score >= 460and row["第二志愿"] == "第三中学":return"第三中学"# 第三志愿if score >= 500and row["第三志愿"] == "第二中学":return"第四中学"if score >= 460and row["第三志愿"] == "第三中学":return"第三中学"return"未录取"df["录取学校"] = df.apply(admit, axis=1)# =============================# 4. 分组(核心🔥)# =============================result = df[df["录取学校"] != "未录取"]grouped = result.groupby("录取学校")["姓名"].apply(list)# =============================# 5. 转成“表格结构”# =============================final_df = pd.DataFrame(dict([(k, pd.Series(v)) for k, v in grouped.items()]))# =============================# 6. 输出# =============================print(final_df)# 保存Excelfinal_df.to_excel("最终录取结果.xlsx", index=False)
📌 关键技巧解析
✅ groupby + list
groupby("录取学校")["姓名"].apply(list)
👉 按学校聚合学生名单
✅ Series 转 DataFrame
pd.DataFrame(dict([(k, pd.Series(v)) for k, v in grouped.items()]))
👉 解决“每列长度不同”的问题(非常经典技巧)
四、导出 Excel
final_df.to_excel("最终录取结果.xlsx", index=False)
✔ 一键生成最终结果表
✔ 可直接交付使用
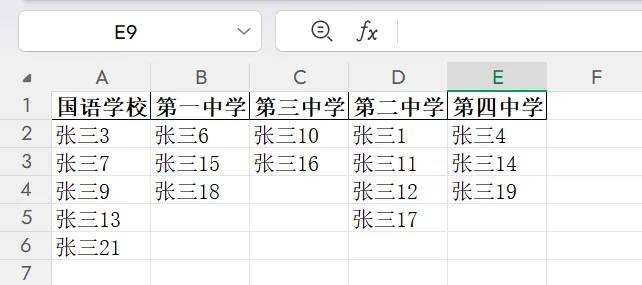
五、最终效果
你会得到一个非常清晰的录取结果:
这个案例你学到了:
✅ Pandas读取Excel ✅ apply实现复杂业务逻辑 ✅ groupby做数据聚合 ✅ DataFrame结构转换技巧
👉 本质能力:用代码还原真实业务规则
🎯 最后一句
很多人学 Python 卡在“不会做项目”, 其实像这种👇才是真正的实战:
👉 把现实规则 → 写成代码 → 自动化执行
获取和交流
需要本章或其他文章的源码和数据的同学,关注+三连,在对应文章下评论“6666“,加下面微信,发你!也可以拉你进群交流学习,加群备注:IT小本本学习
为了能随时获取最新动态,大家可以动动小手将公众号添加到“星标⭐”哦,点赞 + 关注,用时不迷路!!!!
关注公众号:IT小本本 👇