这篇文章带你彻底搞懂 Python 装饰器——从函数是一等公民出发,逐步推导出装饰器的本质,再到带参数的装饰器、多个装饰器叠加,最后看真实项目里的应用场景。
前言
在上一篇里,你已经见过装饰器了:@classmethod、@staticmethod、@property。
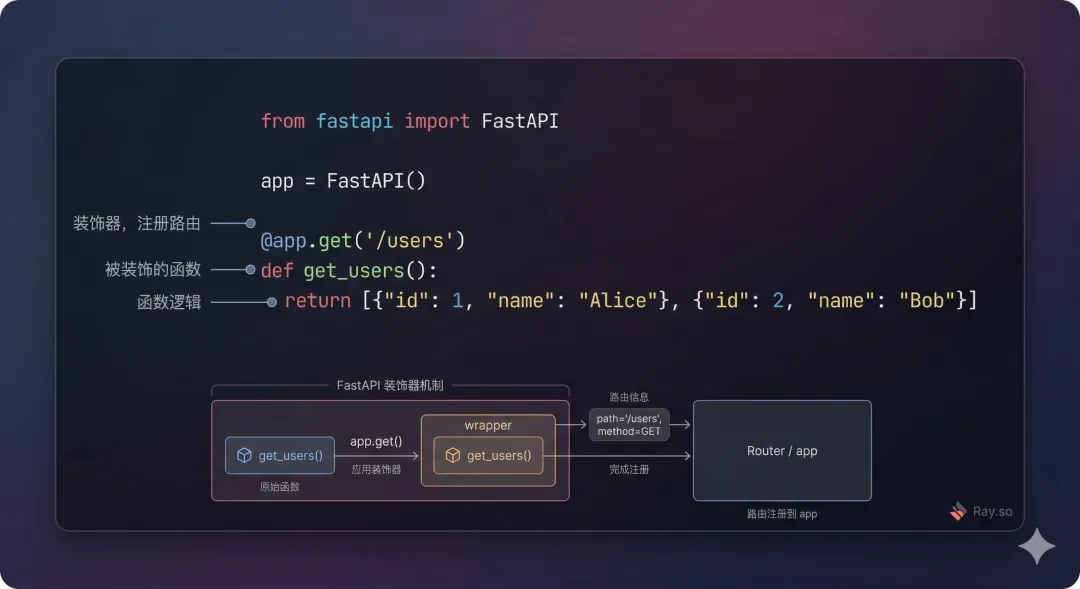
在 FastAPI 里,路由是这样写的:
@app.get("/users")
def get_users():
return [{"name": "Alice"}]
在 Flask 里:
@app.route("/")
def index():
return "Hello World"
这个 @ 符号,就是装饰器语法。它是 Python 里最有特色的特性之一,理解了它,框架代码就不再神秘。
这篇文章覆盖:
一、理解前提:函数是一等公民
装饰器的基础是"函数可以作为值传递"。前端开发者对这个概念一定不陌生:
# Python 里,函数可以赋值给变量
def greet(name):
return f"你好,{name}!"
say_hello = greet # 函数赋值给变量(没有括号!)
print(say_hello("Alice")) # 你好,Alice!
# 函数可以作为参数传入另一个函数
def apply(func, value):
return func(value)
result = apply(greet, "Bob")
print(result) # 你好,Bob!
# 函数可以作为返回值
def make_multiplier(n):
def multiplier(x):
return x * n
return multiplier # 返回一个函数
double = make_multiplier(2)
triple = make_multiplier(3)
print(double(5)) # 10
print(triple(5)) # 15
对比 JS:
// JS 里完全相同的概念
const greet = (name) => `你好,${name}!`
const sayHello = greet
const makeMultiplier = (n) => (x) => x * n
const double = makeMultiplier(2)
这些你都会,所以装饰器对你来说只是新语法,不是新概念。
二、装饰器的本质
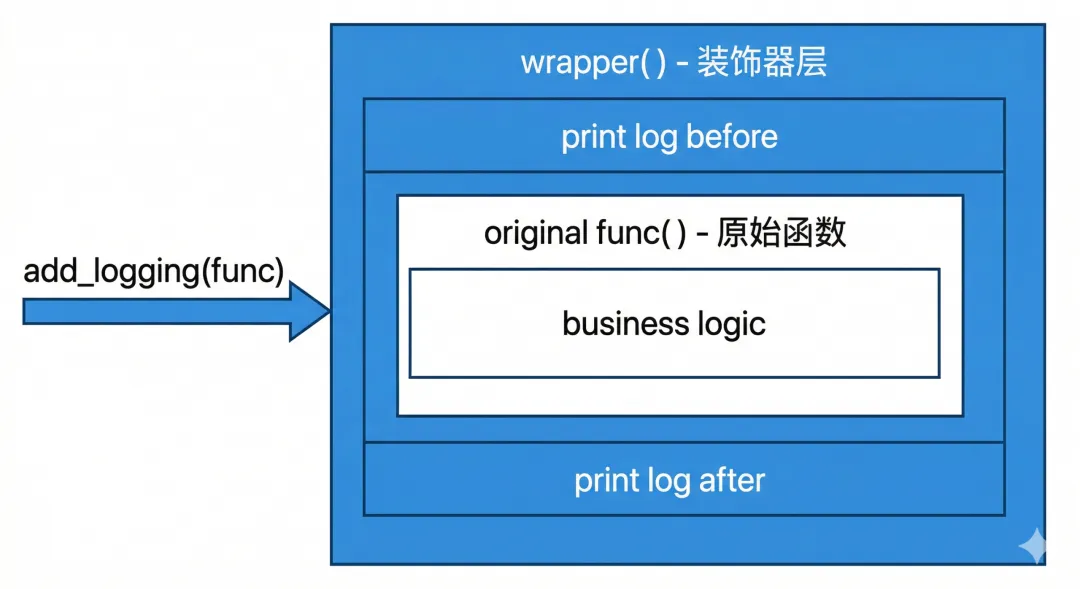
装饰器就是一个函数,它接收一个函数作为参数,返回一个新函数。
先看不用 @ 语法的原始写法:
# 场景:给函数执行前后加上日志
def my_function():
print("执行了业务逻辑")
# 手动"装饰":用 wrapper 函数包裹原函数
def add_logging(func):
def wrapper():
print(f"[日志] 开始执行:{func.__name__}")
func() # 调用原函数
print(f"[日志] 执行完毕:{func.__name__}")
return wrapper # 返回包裹后的新函数
# 把原函数替换成包裹后的版本
my_function = add_logging(my_function)
my_function()
# [日志] 开始执行:my_function
# 执行了业务逻辑
# [日志] 执行完毕:my_function
这就是装饰器的全部秘密:用一个新函数把原函数包起来,在调用原函数前后插入额外逻辑,然后返回这个新函数。
三、@ 语法糖
每次都写 my_function = add_logging(my_function) 太繁琐了,Python 提供了 @ 语法糖:
def add_logging(func):
def wrapper():
print(f"[日志] 开始执行:{func.__name__}")
func()
print(f"[日志] 执行完毕:{func.__name__}")
return wrapper
# @ 语法糖:等价于 my_function = add_logging(my_function)
@add_logging
def my_function():
print("执行了业务逻辑")
my_function()
@add_logging 就是 my_function = add_logging(my_function) 的语法糖,完全等价,但更简洁优雅。
四、处理有参数的函数
上面的 wrapper 只能装饰无参数的函数。要装饰任意函数,需要用 *args, **kwargs 透传参数:
def add_logging(func):
def wrapper(*args, **kwargs): # 接收任意参数
print(f"[日志] 调用 {func.__name__},参数:{args}, {kwargs}")
result = func(*args, **kwargs) # 原样传给原函数
print(f"[日志] 返回值:{result}")
return result # 别忘了返回原函数的返回值!
return wrapper
@add_logging
def add(a, b):
return a + b
@add_logging
def greet(name, greeting="你好"):
return f"{greeting},{name}!"
add(3, 5)
# [日志] 调用 add,参数:(3, 5), {}
# [日志] 返回值:8
greet("Alice", greeting="早上好")
# [日志] 调用 greet,参数:('Alice',), {'greeting': '早上好'}
# [日志] 返回值:早上好,Alice!
这是装饰器的标准模板,记住它:
import functools
def my_decorator(func):
@functools.wraps(func) # 保留原函数的名称和文档(重要!)
def wrapper(*args, **kwargs):
# 执行前的逻辑
result = func(*args, **kwargs)
# 执行后的逻辑
return result
return wrapper
💡 为什么要加 @functools.wraps(func)?没有它,装饰后的函数 __name__ 会变成 "wrapper" 而不是原函数名,调试和文档都会出问题。这是装饰器的最佳实践,务必加上。
五、实战装饰器
5.1 计时装饰器
import time
import functools
def timer(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
start = time.time()
result = func(*args, **kwargs)
elapsed = time.time() - start
print(f"⏱ {func.__name__} 耗时 {elapsed:.4f} 秒")
return result
return wrapper
@timer
def slow_function():
time.sleep(1.5)
return "完成"
slow_function()
# ⏱ slow_function 耗时 1.5023 秒
5.2 权限校验装饰器
import functools
# 模拟当前用户
current_user = {"name": "Alice", "role": "user"}
def require_admin(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
if current_user.get("role") != "admin":
print(f"❌ 权限不足:{current_user['name']} 无法执行此操作")
return None
return func(*args, **kwargs)
return wrapper
@require_admin
def delete_all_users():
print("🗑 已删除所有用户")
delete_all_users() # ❌ 权限不足:Alice 无法执行此操作
# 切换为管理员
current_user["role"] = "admin"
delete_all_users() # 🗑 已删除所有用户
5.3 重试装饰器
import functools
import time
def retry(max_attempts=3, delay=1.0):
"""带参数的装饰器:失败时自动重试"""
def decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
for attempt in range(1, max_attempts + 1):
try:
return func(*args, **kwargs)
except Exception as e:
if attempt == max_attempts:
print(f"❌ 已重试 {max_attempts} 次,仍然失败:{e}")
raise
print(f"⚠ 第 {attempt} 次失败,{delay}s 后重试...")
time.sleep(delay)
return wrapper
return decorator
六、带参数的装饰器
上面的 @retry(max_attempts=3) 就是带参数的装饰器,它需要多包一层:
# 带参数装饰器的结构:三层嵌套
def decorator_with_args(参数): # 第一层:接收装饰器参数
def decorator(func): # 第二层:接收被装饰的函数
@functools.wraps(func)
def wrapper(*args, **kwargs): # 第三层:实际执行逻辑
# 可以使用外层的"参数"
return func(*args, **kwargs)
return wrapper
return decorator
# 使用方式
@decorator_with_args(参数值)
def my_function():
pass
完整示例——缓存装饰器:
import functools
def cache(max_size=128):
"""简单的 LRU 缓存装饰器"""
def decorator(func):
_cache = {}
@functools.wraps(func)
def wrapper(*args):
if args not in _cache:
if len(_cache) >= max_size:
# 删除最早的缓存项
oldest = next(iter(_cache))
del _cache[oldest]
_cache[args] = func(*args)
print(f"💾 缓存未命中,计算并存储:{args}")
else:
print(f"⚡ 缓存命中:{args}")
return _cache[args]
return wrapper
return decorator
@cache(max_size=10)
def fibonacci(n):
if n <= 1:
return n
return fibonacci(n - 1) + fibonacci(n - 2)
fibonacci(5)
# 💾 缓存未命中,计算并存储:(0,)
# 💾 缓存未命中,计算并存储:(1,)
# ...(后续调用命中缓存)
💡 Python 内置了 functools.lru_cache 和 functools.cache,实际项目直接用这个,不需要自己写。
七、多个装饰器叠加
@add_logging
@timer
def process_data(data):
time.sleep(0.5)
return f"处理完成:{data}"
# 执行顺序:从下往上装饰,从上往下执行
# 等价于:process_data = add_logging(timer(process_data))
记住口诀:从下往上包裹(装饰),从上往下执行(调用)。
八、类装饰器
装饰器不只是函数,类也可以做装饰器:
class CountCalls:
"""统计函数被调用次数的类装饰器"""
def __init__(self, func):
functools.update_wrapper(self, func)
self.func = func
self.count = 0
def __call__(self, *args, **kwargs):
self.count += 1
print(f"{self.func.__name__} 被调用了第 {self.count} 次")
return self.func(*args, **kwargs)
@CountCalls
def say_hello(name):
print(f"你好,{name}!")
say_hello("Alice") # say_hello 被调用了第 1 次 \n 你好,Alice!
say_hello("Bob") # say_hello 被调用了第 2 次 \n 你好,Bob!
print(say_hello.count) # 2
小结
| |
|---|
| |
@ | @dec |
| wrapper(*args, **kwargs) |
| 三层嵌套:参数层 → 装饰器层 → wrapper 层 |
| |
最常用的内置装饰器:
- @functools.lru_cache:函数结果缓存
- @dataclasses.dataclass:自动生成 __init__、__repr__ 等(强烈推荐学!)
3 个必记要点:
- 标准模板里的 *args, **kwargs 确保能装饰任意函数,不能省略
- @functools.wraps(func) 保留原函数元信息,务必加
下篇预告
第 11 篇:Python 模块与包:项目结构怎么组织才规范?
单文件写多了就要拆模块,下一篇讲 Python 的 import 系统和项目目录规范——对比前端的 import/export,你会发现既熟悉又有很多坑。