Linux调优网络利用率
一、包传输和接收
在调优系统时,网络是比较复杂和关键的元素之一。大多数网络堆栈都是自组织的,但是有一些网 络元素会影响性能。要确定哪些网络元素正在影响系统性能并正确地对它们进行调优,你需要知道 当一个包被系统传输或接收时所遵循的流中涉及哪些网络元素,并了解对于那些可能成为瓶颈的流 有哪些调优选项可用。 #包传输 下面概述了网络传输的步骤。 1.数据被写入套接字socket(类似文件的对象),然后放入传输缓冲区。 2.内核将数据封装到协议数据单元(PDU)中。 3.pdu移动到每个设备传输队列中。 4.网络设备驱动程序将PDU从传输队列的头部复制到网卡。 5.NIC发送数据并在传输时引发中断。 #包接收 下面显示了网络接收的步骤。 1.网卡接收帧并使用DMA(Direct Memory Access,直接存储器访问)将帧复制到接收缓冲区。 2.NIC抛出一个硬中断。 3.内核处理硬中断,并调度软中断来处理数据包。 4.软中断被处理,并将数据包移动到IP层。 5.如果报文的目的地是本地,则PDU被解封装并放入套接字接收缓冲区。如果一个进程正在等待这 个套接字,它将处理来自接收缓冲区的数据。 由NIC引发的硬中断的内核管理防止了被称为livelock的现象。Livelock的基础是硬中断会抢占 一切,包括其他中断处理程序。如果数据包没有足够快地移出接收缓冲区,这可能会导致接收缓冲 区在沉重的接收负载期间被填满。 另一个潜在的瓶颈是NIC硬件缓冲区,也称为环形缓冲区。如果一个NIC丢弃了大量的数据包,这 个缓冲区可能会出现问题。使用ethtool命令检查每个网卡丢弃的数据包数量。要解决这个瓶颈, 可以降低输入流量或增加硬件缓冲队列的大小。 处理器如何处理中断也是一个系统瓶颈。如果产生中断的进程和中断本身不是由同一个处理器和核 心处理的,系统可能会面临延迟和处理器争用问题。 最后,应用程序接收队列中的瓶颈可以通过大量未复制到进程的数据包或UDP输入错误的增加来识 别。要解决这个问题,可以降低传入通信率或增加应用程序的套接字队列深度。
二、网络内核调优
网络缓冲区(或队列)由核心网络读和写缓冲区(用于UDP和TCP)、每个套接字TCP读和写缓冲区、 碎片缓冲区和用于网卡的DMA缓冲区组成。内核根据当前的网络利用率自动调整这些缓冲区的大 小,但在内核可调项指定的限制内。
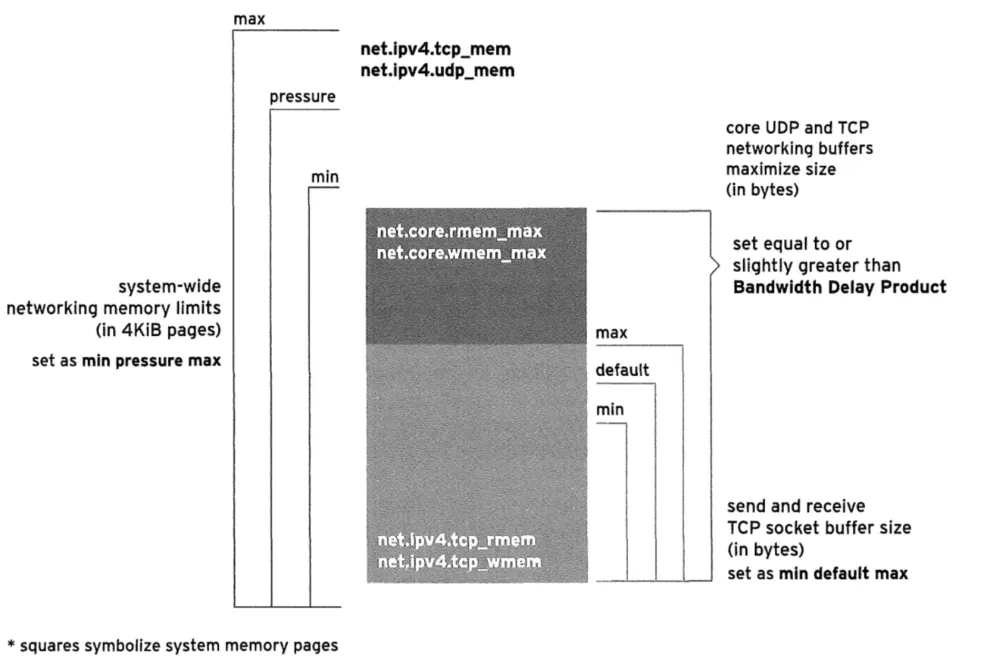
这些可调参数的默认值是在启动时根据可用内存量计算的。在x86_64机器上,将max设置为接近系 统内存量的值。然而,在x86系统上,这可能需要增加。可以使用一些sysctl可调参数来管理这些 缓冲区的大小。 可以使用一些sysctl可调参数来管理这些缓冲区的大小。 net.ipv4.tcp_mem,net.ipv4.udp_mem TCP和UDP的系统范围内存限制。这些设置由三个字段组成:min、pressure和max。 min是页面内存量,低于此值内核对TCP/UDP内存使用不感兴趣。 pressure:当TCP/UDP使用的内存数量超过这个页面数量时,内核将开始调节它的内存使用,直到 它再次降到min以下。 max:允许所有TCP/UDP套接字排队的最大内存量(以页为单位)。 注意:net.ipv4.tcp_mem和net.ipv4.udp_mem以页为单位,而不是字节。通过运行getconf PAGESIZE(通常为4096)来查看页面大小(以字节为单位)。 net.core.rmem_max,net.core.wmem_max 核心网络的最大套接字接收/发送(读/写)缓冲区。值以字节为单位。 net.ipv4.tcp_rmem,net.ipv4.tcp_wmem 值以字节为单位。套接字缓冲区从默认字节的大小(第二个值)开始,并根据需要在最小(第一个 值)和最大(第三个值)之间自动调整。 注意:net.ipv4.tcp_rmem的最大值和net.ipv4.tcp_wmem缓冲区不能超过核心网络值 (net.core.rmem_max和net.core.wmem_max)。在增加TCP最大读写设置时,请务必调整core networking值。
三、计算带宽延迟乘积(BDP)
使用一种称为带宽延迟乘积(BDP)的计算来验证缓冲区的大小是否正确。缓冲区大小是通过估计在 专用信息流的源和目的地之间的网络管道中可以容纳的数据量来计算的。网络管道的大小是管道的 容量(以字节/秒吞吐量为单位)乘以管道的长度(以秒为单位作为往返延迟)。 要计算最大吞吐量所需的缓冲区大小,请确定数据包从本地系统传输到远程系统所需的时间。这可 以用来计算在接收和确认第一个包之前可以发送的数据量。首先,计算出数据包的往返时间,即数 据包从本地机器发送到远程机器返回所需的时间。ping命令可以用来查询平均往返时间。
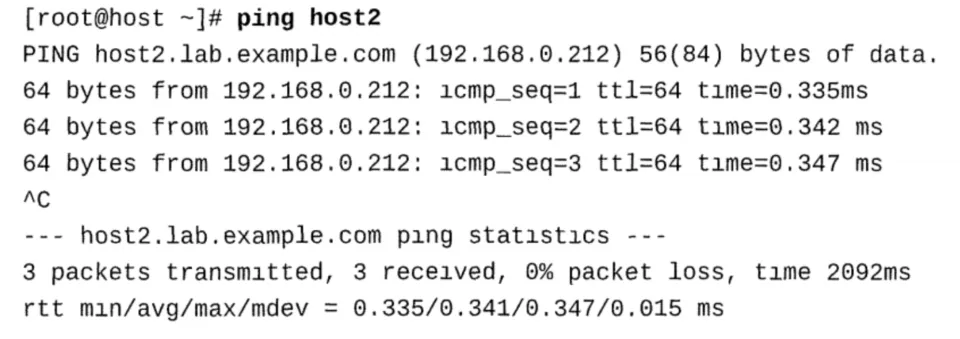
该示例显示了平均往返时间(ntt)为0.341 ms,或0.000341秒。网速(容量)为每秒1千兆:

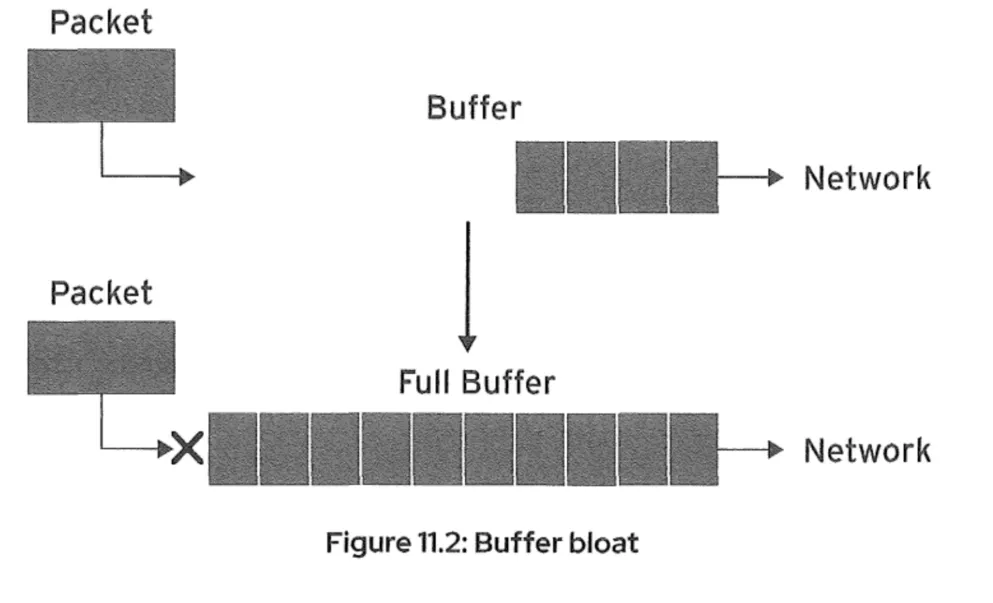
此示例的结果是带宽延迟乘积(BDP)为41.63 KiB。 如果BDP超过64 KiB, TCP连接可以利用窗口伸缩。TCP窗口是发送到远程系统的尚未确认的数据 量。如果未确认的数据增长到窗口大小,发送方将停止发送,直到之前的数据已确认。 默认情况下,窗口的最大限制为64 KiB。如果双方都支持,可以协商窗口缩放,允许窗口扩大。 如果sysct net.ipv4.tcp_window_scaling参数设置为1时,内核将尝试协商窗口缩放。如果 该值为0,将禁用窗口缩放。 注意:如果系统将同时处理多个连接,每个套接字缓冲区的大小只需足够大,以处理单个套接字的 BDP即可。 将TCP缓冲区大小设置得太大将导致缓冲区膨胀的现象。当数据包从缓冲区流出的速率低于数据包 发送到缓冲区的速率时,就会发生缓冲区膨胀。这可能严重影响发送少量数据的连接(如HTTP或 SSH)的网络速度和延迟。
四、开启巨型帧
每当一个包在网络上传输时,该包由报头和有效负载组成。典型的TCP/IP包报头包括以太网报 头、IP报头和TCP报头。所有这些头都包含在网络上使用的最大传输单元(MTU)中,即单个包可以 拥有的最大大小。例如,使用TCP时间戳的普通TCP连接使用52字节作为协议头。默认MTU为1500 字节,几乎占总容量的3.5%。 减少由于报头引起的开销的一种方法是将协议切换到开销更小的另一种协议。例如,从TCP切换到 UDP将减少报头从52字节到28字节(小于1.9%的开销,MTU为1500)。然而,这并不总是可行的。 另一种方法是增加MTU的大小。当MTU增加到以太标准1500字节以上时,产生的数据包称为巨帧. 巨型帧的使用不仅有利于每个包中包含的数据的百分比,而且还降低了NIC所需的处理。在所有涉 及它的传输的网络元素中,巨型帧必须被支持。当涉及到这么多不同的组织、供应商和网络基础设 施时,这个需求很难满足。这就是巨型帧的关键用例是存储区域网络的原因。与SAN相关的网络基 础设施通常是隔离的,因此可以很容易地在所有网络组件中启用巨型帧。巨型帧的其他用例包括服 务器集群、备份基础设施和高性能专用网络。 在配置系统使用巨帧和特定网卡之前,请确保网络中的所有网络设备(包括但不限于网卡、交换 机、路由器)都支持巨帧。超大帧的官方最大尺寸是9000字节,但有些设备支持更大的帧。 使用与前面提到的相同的52字节头,并假设MTU为9000字节 52 / 9000*100%= 0.58% 与之前3.5%的开销相比,这是一个显著的改进。可以使用nmcli命令修改MTU的大小。下面的示例 为ens3设置MTU为9000。 nmcli con modify ens3 802-3-ethernet.mtu 9000
五、网络性能调优
网络吞吐量取决于多个因素:使用的网卡、线缆类型、跳数、发送的数据包大小等等。虽然其中一 些是所使用硬件的属性,但其他属性也可能受到系统的影响。 需要改变的最激烈的设置之一是正在使用的网卡的连接速度。要查询当前设置,可以使用ethtool 工具: [LAB-G238-CICD1 root ~] # ethtool ens1f0 Settings for ens1f0: Supported ports: [ FIBRE ] Supported link modes: 25000baseCR/Full Supported pause frame use: Symmetric Receive-only Supports auto-negotiation: Yes Supported FEC modes: None RS BASER Advertised link modes: 25000baseCR/Full Advertised pause frame use: No Advertised auto-negotiation: Yes Advertised FEC modes: None RS BASER Speed: 25000Mb/s Duplex: Full Auto-negotiation: off Port: Direct Attach Copper PHYAD: 0 Transceiver: internal Supports Wake-on: d Wake-on: d Current message level: 0x00000007 (7)drv probe link Link detected: yes 自动协商是以太网网络的一个特性,网卡可以与下一跳通信以协商最高的速度。虽然自动协商通常 是可信的,但有时它不能正常工作。要管理自动协商,可以限制网卡发布的速度,或者完全关闭自 动协商并手动设置速度。 下面的示例使用ethtool命令和--change(或-s)选项手动设置以太网选项。要限制链接速度参 数,请使用带有所需速度位掩码的advertise选项。将ens3网络接口的发布速度限制为100mb/s 全双工和1000mb/s全双工: ethtools-s ens3 advertise 0x28 0x28的值是从ethtool(8)手册页面中获得的,其中包含100baseT Full (0x008)和1000baseT Full(0x020)的值。要关闭自动协商并设置固定的速度,可以在单个命令中使用autoneg、 speed和duplex选项,如下所示: [root@host-]# ethtool -s ens3 autoneg off speed 1000 duplex full 注意:通常,这些设置不适用于虚拟机,因为它们的网络链接速度取决于管理程序中的物理网卡。 使用ethtool设置的以太网选项不是持久的。在Red Hat Enterprise Linux 6中,要持久地配 置这些设置,需要在接口的/etc/sysconfig/network-scripts/ifcfg-*文件中添加 ETHTOOL_OPTS="OPTIONS": ETHTOOL_OPTS="-s ${DEVICE} autoneg off speed 1000 duplex full"Red Hat Enterprise Linux 7仍然支持,但弃用了在NetworkManager被禁用时 ETHTOOL_OPTS参数。使用NetworkManager(Red Hat Enterprise Linux 7和8),您可以持 久地使用802-3-ethernet.* 来定义配置文件的属性:

ethtool命令还可以报告和修改更高级的网络设备参数。例如,--show-offload(或-k)选项列出 了设备的特性和内核可以委托给设备的操作,例如包分段或校验和计算。使用--offload(或-K)选项来修改这些参数。为了持久,NetworkManager在ethtool.feature*配置文件的属性中将这 些参数分组。 #虚拟接口 ethtool命令可以在虚拟设备上使用。虚拟设备是模拟的以太网桥、交换机、路由器和网卡,只在 内存中运行。虚拟网卡连接到主机虚拟网桥,而不是物理主机网卡,由模拟的网络驱动程序(如 virtio)操作。查询vNIC将返回模拟的驱动程序响应。许多仿真默认为假的100Mbps或1000Mbps 速度,这不是速度限制。虚拟网络以内存速度运行,除非在虚拟段上配置了服务质量(QoS)限制。 #测量吞吐量 度量网络吞吐量有多种工具。在以太网网络中,qperf命令可以测量TCP、UDP、RDS、SCTP和SDP 套接字吞吐量和延迟。qperf命令还可以在RDMA和InfiniBand网络上执行测量。 qperf需要在两台机器上运行。一个(侦听器)不带任何选项地运行qperf。另一个(发送方)调用 qperf,第一个参数是第一个主机的名称,后面是测试选项。例如,要在demo和demo2服务器之间 运行TCP和UDP带宽测试,请在demo2上启动qperf监听器: [host2]# qperf 缺省情况下,服务器监听TCP端口19765,但是可以使用--listen_port选项设置。当qperf在 host2上监听时,在host1上启动测试: [host1]# qperf host2 tcp_bw udp_bw 大多数现代的网卡都可以用来从CPU中卸载一些操作。这通常包括处理校验和和碎片。可分别使用 ethtool-k device和ethtool -k device查询和设置这些卸载参数。 [LAB-G238-CICD1 root ~] # ethtool -k ens1f0 Features for ens1f0: rx-checksumming: on tx-checksumming: on tx-checksum-ipv4: on tx-checksum-ip-generic: off [fixed]tx-checksum-ipv6: on tx-checksum-fcoe-crc: off [fixed]tx-checksum-sctp: on scatter-gather: on tx-scatter-gather: on tx-scatter-gather-fraglist: off [fixed]tcp-segmentation-offload: on tx-tcp-segmentation: on tx-tcp-ecn-segmentation: on tx-tcp-mangleid-segmentation: off tx-tcp6-segmentation: on generic-segmentation-offload: on generic-receive-offload: on large-receive-offload: off [fixed]rx-vlan-offload: on tx-vlan-offload: on ntuple-filters: on receive-hashing: on highdma: on rx-vlan-filter: on [fixed]vlan-challenged: off [fixed]tx-lockless: off [fixed]netns-local: off [fixed]tx-gso-robust: off [fixed]tx-fcoe-segmentation: off [fixed]tx-gre-segmentation: on tx-gre-csum-segmentation: on tx-ipxip4-segmentation: on tx-ipxip6-segmentation: on 2.2网络team tx-udp_tnl-segmentation: on tx-udp_tnl-csum-segmentation: on tx-gso-partial: on tx-tunnel-remcsum-segmentation: off [fixed]tx-sctp-segmentation: off [fixed]tx-esp-segmentation: off [fixed]tx-udp-segmentation: on tx-gso-list: off [fixed]rx-udp-gro-forwarding: off rx-gro-list: off tls-hw-rx-offload: off [fixed]fcoe-mtu: off [fixed]tx-nocache-copy: off loopback: off [fixed]rx-fcs: off [fixed]rx-all: off [fixed]tx-vlan-stag-hw-insert: off [fixed]rx-vlan-stag-hw-parse: off [fixed]rx-vlan-stag-filter: off [fixed]l2-fwd-offload: off hw-tc-offload: on esp-hw-offload: off [fixed]esp-tx-csum-hw-offload: off [fixed]rx-udp_tunnel-port-offload: on tls-hw-tx-offload: off [fixed]rx-gro-hw: off [fixed]tls-hw-record: off [fixed]
六、网络team
网络team是一种将网卡逻辑连接在一起的方法,以支持故障转移或更高的吞吐量。team是一种新 的实现,它不影响Linux内核中的旧bonding驱动程序。它提供了另一种实现。网络team由于其模 块化设计,提供了更好的性能和更强的可扩展性。 Red Hat Enterprise Linux 8通过一个小型内核驱动程序和一个用户空间守护进程teamd实现 了网络teaming。内核有效地处理网络数据包,而teamd处理逻辑和接口处理。被称为runner的软 件实现负载平衡和主备,如roundrobin。以下runner是在teamd中可用的: 2.3配置接口team broadcast:一个简单的运行程序,从所有端口传输每个包。 Roundrobin:一种简单的运行程序,从每个端口以循环方式传输数据包。 Activebackup:这是一个故障转移运行程序,它监视链路变化并为数据传输选择一个活动端口。 Loadbalance:该运行器监视流量,并使用哈希函数在选择数据包传输的端口时试图达到完美的平 衡。 lacp:实现802.3ad链路聚合控制协议。可以使用与负载平衡运行器相同的传输端口选择可能性。 所有的网络交互都是通过一个team接口完成的,该接口由多个网口接口组成。当使用 NetworkManager控制team端口接口时,特别是在查找故障时,请记住以下几点: 1.启动team接口不会自动启动port接口。 2.启动一个port接口总是启动team接口。 3.停止team接口也会停止port接口。 4.没有port的team接口可以启动静态IP连接。 5.没有port的team在启动DHCP连接时等待port启动。 6.当一个带有载波(连线)的端口被添加时,一个DHCP连接等待port的team就完成了。 7.当没有载波(连线)的端口被添加时,DHCP连接等待port的team将继续等待。
七、配置接口team
#配置team接口 nmcli con add type team con-name CNAME ifname INAME team.OPTION OPTIONVALUE CNAME是用于引用连接的名称 INAME是接口名称 OPTION是runner或link-watchers。 team.runner的OPTIONVALUE是任何可用的runner(例如loadbalance)。 nmcli con add type team con-name team0 ifname team0 team.runer loadbalance 如果您正在配置与team的link-watchers,您至少需要用name属性配置link watcher。 nmcli con modify team0 team.link-watchers "name=ethertool"#配置ipv4地址 nmcli con modify team0 ipv4.address '1.2.3.4/24'nmcli con modify team0 ipv4.method manual 2.4持续team配置 #配置port nmcli con add type ethernet slave-type team con-name CNAME ifname INAME master TEAM nmcli con add type ethernet slave-type team con-name team0-port1 ifname ens3 master team0 nmcli con add type ethernet slave-type team con-name team0-port2 ifname ens4 master team0 #开启和关闭team和port nmcli con up team0 nmcli device disconnect ens3 #查看team状态 teamdctl team0 state
八、持续team配置
NetworkManager在/etc/sysconfig/network-scripts目录中为网络team创建配置文件,其方 式与其他接口相同。为每个接口、team和每个端口创建一个配置文件。 team接口的配置文件定义接口的IP设置。DEVICETYPE变量通知初始化脚本这是一个网络tean接 口。teamd的参数配置在TEAM_CONFIG变量中定义,注意这里是json的格式。
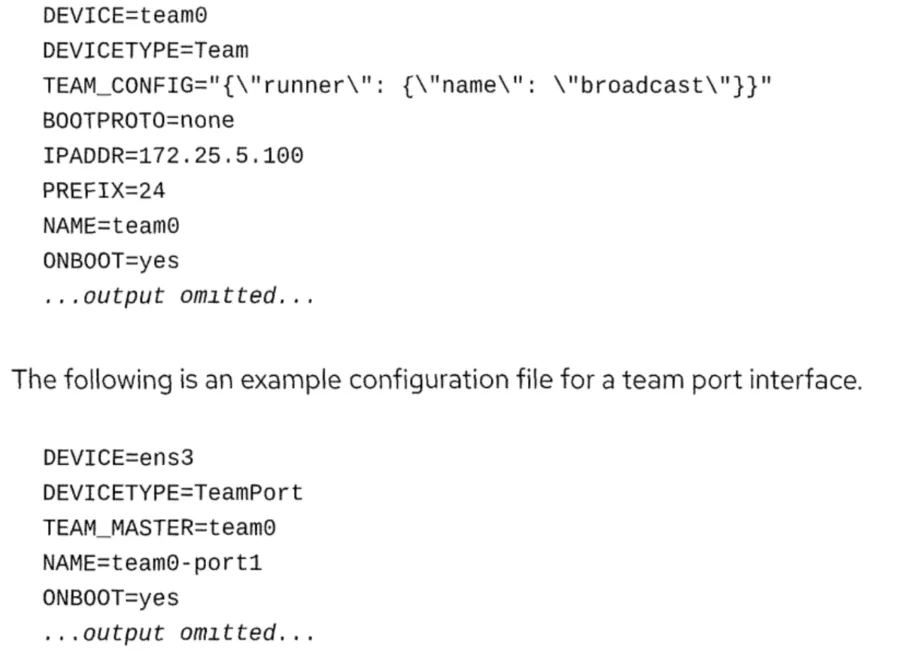
DEVICETYPE变量通知初始化脚本这是一个team端口接口。TEAM_MASTER变量定义了它是哪个 team设备的端口。
九、team接口排障
teamnl和teamdctl命令对于网络team的故障排除非常有用。这些命令只适用于已启动的网络 team。下面的示例展示了这些命令的一些典型用法。 显示team0界面的team端口: #teamnl team0 ports 显示当前team0的活跃接口 #teamnl team0 getoption activeport 为team0的活跃接口设置参数 #teamnl team0 setoption activeport 3 使用teamdctl查看team0接口的状态 #teamdctl team0 state 使用teamdctl查看team0的json格式配置 #teamdctl team0 config dump
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
