输出:IP地址、子网掩码、网络地址、可用主机数、广播地址、所属网段(excel格式)①在不含中文名的任意路径,新建一个文件夹,命名如study②打开vscode,点击Open Folder,选择刚刚新建的文件夹,点击信任此文件夹。点击+号右侧下拉菜单,选择Command Prompt,关闭之前的PowerShell。在下方终端输入:python -m venv venv 左侧文件区会新增一个venv文件夹装局部依赖环境。
然后继续输入venv\Scripts\activate (上一篇文章这一步遗漏,此处补上)
在左侧文件夹名称旁边,新建py文件。
二、根据需求搜索代码并试验。
① deepseek等,输入需求“写一个判断n个IP地址是否在同一网段的判断程序。要求,输入为excel,输入内容为IP地址 子网掩码 两种方式。输出为excel,输入基础上加上 AND运算结果 所属网段的可用数量,网络地址、广播地址。python实现,把代码,以及excel格式给我。“得到一段代码。
②将代码复制进入刚才的py文件,根据代码开头的import的库名,在终端输入 pip install 库名 ,来安装库。系统自带的库可不安装。
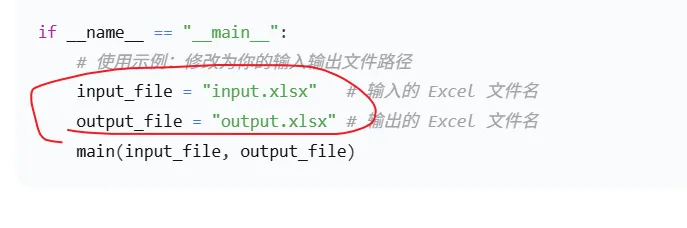
③修改输入输出文件名称,在py文件所在文件夹创建输入excel文件。
④点击右上角运行按钮。
⑤第一次运行会出现此报错,无法加载文件 ...\Scripts\Activate.ps1,因为在此系统上禁止运行脚本。
以管理员身份打开 PowerShell:在 Windows 搜索栏输入 PowerShell,右键点击“Windows PowerShell”,选择“以管理员身份运行”。
执行修改命令:在弹出的窗口中输入以下命令并回车。
Set-ExecutionPolicy RemoteSigned -Scope CurrentUser
⑥再次点击运行,根据结果让AI继续修改代码,直至代码符合需求。
三、代码打包
①在终端安装pyinstaller库
pip install pyinstaller
②继续在终端输入
pyinstaller --onefile--console--name IPSubnetTool IPcul.py
③打包完成后,在 dist 文件夹中找到 IPSubnetTool.exe。
④使用方法:将IPSubnetTool.exe和input.excel文件复制到另外的文件夹,运行exe即可。
四、附生成的源码
import pandas as pdimport ipaddressimport refrom openpyxl.styles import Alignmentdef mask_int_to_dotted(prefix_len): """将前缀长度(0-32)转换为点分十进制掩码字符串""" mask_int = (0xffffffff << (32 - prefix_len)) & 0xffffffff return f"{(mask_int >> 24) & 0xff}.{(mask_int >> 16) & 0xff}.{(mask_int >> 8) & 0xff}.{mask_int & 0xff}"def parse_ip_mask(ip_str, mask_str): """ 从IP地址字符串和掩码字符串解析出前缀长度和点分十进制掩码。 返回 (ip_str, prefix_len, dotted_mask) 或抛出异常。 """ ip_str = str(ip_str).strip() mask_str = str(mask_str).strip() # 掩码可能是点分十进制或数字 if re.match(r'^\d+\.\d+\.\d+\.\d+$', mask_str): mask = ipaddress.IPv4Address(mask_str) prefix_len = bin(int(mask))[2:].count('1') dotted_mask = mask_str # 使用输入的点分格式 else: # 掩码为数字(CIDR前缀长度) prefix_len = int(mask_str) dotted_mask = mask_int_to_dotted(prefix_len) # 验证 IP + 前缀长度是否合法 net = ipaddress.ip_network(f"{ip_str}/{prefix_len}", strict=False) return ip_str, prefix_len, dotted_maskdef network_info(ip_str, prefix_len): """返回 (网络地址, 可用主机数, 广播地址)""" net = ipaddress.ip_network(f"{ip_str}/{prefix_len}", strict=False) host_bits = 32 - prefix_len if host_bits >= 2: usable = (1 << host_bits) - 2 elif host_bits == 1: # /31 点对点,RFC 3021 usable = 2 else: # /32 主机路由 usable = 1 broadcast = str(net.broadcast_address) return str(net.network_address), usable, broadcastdef detect_ip_mask_columns(df): """ 自动识别IP列和掩码列(假设输入只有两列,或者包含相关关键词)。 返回 (ip_col, mask_col) """ ip_keywords = ['ip', '地址', 'ip地址'] mask_keywords = ['掩码', 'mask', '子网掩码'] ip_col = None mask_col = None for col in df.columns: low = col.lower() if any(kw in low for kw in ip_keywords): ip_col = col if any(kw in low for kw in mask_keywords): mask_col = col # 如果未找到,尝试按位置:第一列为IP,第二列为掩码 if ip_col is None and len(df.columns) >= 1: ip_col = df.columns[0] if mask_col is None and len(df.columns) >= 2: mask_col = df.columns[1] if ip_col is None or mask_col is None: raise ValueError("无法识别IP列或掩码列,请确保列名包含'IP'/'地址'和'掩码'/'mask',或者前两列分别为IP和掩码") return ip_col, mask_coldef main(input_excel, output_excel): # 读取 Excel df = pd.read_excel(input_excel, dtype=str) if df.empty: print("输入文件为空") return # 识别列 ip_col, mask_col = detect_ip_mask_columns(df) # 存储计算结果 ip_list = [] standard_mask_list = [] # 格式 "点分十进制/前缀" net_addrs = [] usable_hosts = [] broadcast_addrs = [] prefix_list = [] # 用于分组 errors = [] for idx, row in df.iterrows(): try: ip_str = row[ip_col] mask_str = row[mask_col] ip_clean, prefix, dotted_mask = parse_ip_mask(ip_str, mask_str) ip_list.append(ip_clean) prefix_list.append(prefix) standard_mask = f"{dotted_mask}/{prefix}" standard_mask_list.append(standard_mask) net_addr, usable, broadcast = network_info(ip_clean, prefix) net_addrs.append(net_addr) usable_hosts.append(usable) broadcast_addrs.append(broadcast) except Exception as e: ip_list.append(str(row[ip_col]) if pd.notna(row[ip_col]) else "") standard_mask_list.append("") net_addrs.append("Error") usable_hosts.append(str(e)) broadcast_addrs.append("") prefix_list.append(None) errors.append((idx, str(e))) # 分配所属网段(基于网络地址和前缀长度) group_map = {} next_id = 1 group_assignments = [] for net_addr, prefix in zip(net_addrs, prefix_list): if net_addr == "Error" or prefix is None: group_assignments.append("") continue key = (net_addr, prefix) if key not in group_map: group_map[key] = next_id next_id += 1 group_assignments.append(f"网段{group_map[key]}") # 构建输出 DataFrame output_df = pd.DataFrame({ 'IP地址': ip_list, '子网掩码': standard_mask_list, '网络地址': net_addrs, '可用主机数': usable_hosts, '广播地址': broadcast_addrs, '所属网段': group_assignments }) # 输出 Excel 并设置格式 with pd.ExcelWriter(output_excel, engine='openpyxl') as writer: output_df.to_excel(writer, sheet_name='Sheet1', index=False) worksheet = writer.sheets['Sheet1'] # 找到“子网掩码”列的列号(从1开始) mask_col_idx = None for i, col_name in enumerate(output_df.columns, start=1): if col_name == '子网掩码': mask_col_idx = i break # 设置列宽:子网掩码列宽30,其他列宽20 for col in worksheet.columns: col_letter = col[0].column_letter if col[0].column == mask_col_idx: worksheet.column_dimensions[col_letter].width = 30 else: worksheet.column_dimensions[col_letter].width = 20 # 设置所有单元格水平垂直居中 for row in worksheet.iter_rows(): for cell in row: cell.alignment = Alignment(horizontal='center', vertical='center') print(f"处理完成,结果已保存至:{output_excel}") if errors: print("以下行处理出错:") for idx, err in errors: print(f" 行 {idx+2}: {err}")if __name__ == "__main__": input_file = "IPinput.xlsx" # 输入文件路径 output_file = "IPoutput.xlsx" # 输出文件路径 main(input_file, output_file)
附输入excel表格形式

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
