🤔 你真的需要 SQLAlchemy 吗?
在不少 Python 项目里,咱们下意识就会拉上 SQLAlchemy——毕竟名气大、生态全。但你有没有算过,一个只需要管理十几张表的内部工具或数据采集服务,光是 SQLAlchemy 的初始化配置就要写多少行?Session 管理、Engine 绑定、Base 声明……还没开始写业务逻辑,头已经大了。
我在做一个 Windows 上位机数据记录模块时,最初也是习惯性地用 SQLAlchemy,结果光是数据库连接层就折腾了半天。后来换成 Peewee,整个模型定义加连接管理压缩到不足 30 行,查询逻辑清晰得像在读英语句子。
Peewee 是一个极简的 Python ORM,代码库不超过 6000 行,支持 SQLite、MySQL、PostgreSQL,在轻量级应用、嵌入式数据库场景、快速原型开发中有着无可替代的优势。读完本文,你将掌握:
- • 在 Windows 上位机或中间件项目中落地的实战模板
🔍 问题深度剖析:ORM 选型的隐性成本
很多开发者在选 ORM 时只看"功能是否齐全",却忽略了另一个维度——认知负担与维护成本。
以一个典型的设备数据采集服务为例,需求很简单:每隔 5 秒把传感器数值写入 SQLite,偶尔按时间范围查询。这种场景下,SQLAlchemy 的 Session 生命周期管理、连接池配置、事务上下文……每一个知识点都是额外的学习成本,而且在多线程环境下稍有不慎就会出现 DetachedInstanceError 或连接泄漏。
问题根源在于工具与场景的错配。 重型 ORM 为复杂的企业级应用设计,内置了大量在小型项目中根本用不到的抽象层。这些抽象层不仅增加了初始化开销,还让代码变得难以追踪——一个简单的 INSERT 操作背后可能经历了三四层封装。
在实测中(测试环境:Windows 11,Python 3.11,SQLite 本地文件,10 万条记录批量写入),Peewee 的 bulk_create 耗时约 1.2 秒,而等价的 SQLAlchemy Core 写法耗时约 1.8 秒,ORM 层写法则接近 3.5 秒。差距在数据量增大后会进一步拉开。
💡 核心要点提炼:Peewee 的设计哲学
Peewee 的底层逻辑非常直接:模型即表,字段即列,查询即链式调用。它没有 SQLAlchemy 那种"工作单元"模式,也没有复杂的 identity map,每次查询就是一次干净的数据库交互。
🏗️ 模型定义:直觉优先
python1from peewee import *23# 连接 SQLite 数据库(Windows 路径兼容)4db = SqliteDatabase('sensor_data.db')56class BaseModel(Model):7class Meta:8 database = db910class Device(BaseModel):11"""设备信息表"""12 name = CharField(max_length=64, unique=True)13 location = CharField(max_length=128, null=True)14 created_at = DateTimeField(constraints=[SQL('DEFAULT CURRENT_TIMESTAMP')])1516class Meta:17 table_name = 'devices'1819class SensorRecord(BaseModel):20"""传感器记录表"""21 device = ForeignKeyField(Device, backref='records', on_delete='CASCADE')22 temperature = FloatField()23 humidity = FloatField(null=True)24 recorded_at = DateTimeField(index=True)2526class Meta:27 table_name = 'sensor_records'
模型定义清晰到不需要注释就能看懂结构。backref='records' 这一个参数,就完成了反向关联的声明——后续可以直接用 device.records 遍历该设备的所有记录。
🔗 连接管理:上下文即安全
Peewee 推荐使用上下文管理器处理连接,这在 Windows 上位机的多线程环境中尤为重要:
python1# 建表(仅首次运行或迁移时执行)2with db:3 db.create_tables([Device, SensorRecord], safe=True)45# 日常操作统一用 atomic() 事务上下文6def save_record(device_name: str, temp: float, humidity: float, ts):7with db.atomic():8 device, _ = Device.get_or_create(name=device_name)9SensorRecord.create(10 device=device,11 temperature=temp,12 humidity=humidity,13 recorded_at=ts14 )
db.atomic() 既是事务边界,也是异常回滚的保障。如果块内抛出异常,事务自动回滚,不会留下脏数据。
🚀 解决方案设计
方案一:基础 CRUD 与链式查询
适用场景: 单表操作、条件筛选、排序分页,覆盖 80% 的日常需求。
python1import os23from peewee import *4from datetime import datetime, timedelta5import logging6import random78# 配置日志9logging.basicConfig(level=logging.INFO)10logger = logging.getLogger(__name__)1112# 连接 SQLite 数据库(Windows 路径兼容)13db = SqliteDatabase('sensor_data.db')141516class BaseModel(Model):17class Meta:18 database = db192021class Device(BaseModel):22"""设备信息表"""23 name = CharField(max_length=64, unique=True)24 location = CharField(max_length=128, null=True)25 status = CharField(max_length=20, default='active') # active, inactive, maintenance26 created_at = DateTimeField(constraints=[SQL('DEFAULT CURRENT_TIMESTAMP')])2728class Meta:29 table_name = 'devices'3031def __str__(self):32return f"Device({self.name}, {self.location})"333435class SensorRecord(BaseModel):36"""传感器记录表"""37 device = ForeignKeyField(Device, backref='records', on_delete='CASCADE')38 temperature = FloatField()39 humidity = FloatField(null=True)40 pressure = FloatField(null=True) # 新增气压字段41 recorded_at = DateTimeField(index=True)4243class Meta:44 table_name = 'sensor_records'45 indexes = (46# 复合索引,提升查询性能47 (('device', 'recorded_at'), False),48 )4950def __str__(self):51return f"Record({self.device.name}, {self.temperature}°C, {self.recorded_at})"525354# --- 数据库初始化 ---def init_database(reset=False):55"""初始化数据库,创建表结构"""56try:57# 如果需要重置,删除现有数据库文件58if reset and os.path.exists('sensor_data.db'):59 os.remove('sensor_data.db')60 logger.info("已删除现有数据库文件")6162 db.connect()63 db.create_tables([Device, SensorRecord], safe=True)64 logger.info("数据库初始化完成")65except Exception as e:66 logger.error(f"数据库初始化失败: {e}")67raise68finally:69if not db.is_closed():70 db.close()717273# --- 设备管理 ---74def create_device(name: str, location: str = None) -> Device:75"""创建设备"""76try:77 device = Device.create(name=name, location=location)78 logger.info(f"设备创建成功: {device}")79return device80except IntegrityError:81 logger.warning(f"设备 {name} 已存在")82return Device.get(Device.name == name)838485def get_or_create_device(name: str, location: str = None) -> Device:86"""获取或创建设备"""87 device, created = Device.get_or_create(88 name=name,89 defaults={'location': location}90 ) if created:91 logger.info(f"新设备创建: {device}")92return device939495def list_devices(status: str = None):96"""列出所有设备"""97 query = Device.select()98if status:99 query = query.where(Device.status == status)100return list(query)101102103def update_device_status(device_name: str, status: str):104"""更新设备状态"""105 updated = (Device106 .update(status=status)107 .where(Device.name == device_name)108 .execute())109if updated:110 logger.info(f"设备 {device_name} 状态更新为 {status}")111return updated > 0112113114# --- 数据写入 ---115def batch_insert(records: list[dict]):116"""117 批量写入,推荐使用 bulk_create 替代循环 create 测试环境:Windows 11 / Python 3.11 / SQLite118 1万条:bulk_create ≈ 0.12s,循环 create ≈ 1.8s """ if not records:119return 0120121try:122with db.atomic():123# 确保设备存在124 device_names = {r.get('device_name') or r.get('device') for r in records}125for name in device_names:126if name:127get_or_create_device(name)128129# 转换记录格式130 sensor_records = []131for r in records:132 device_name = r.get('device_name') or r.get('device')133if isinstance(device_name, str):134 device = Device.get(Device.name == device_name)135else:136 device = device_name137138 record = SensorRecord(139 device=device,140 temperature=r['temperature'],141 humidity=r.get('humidity'),142 pressure=r.get('pressure'),143 recorded_at=r.get('recorded_at', datetime.now())144 )145 sensor_records.append(record)146147SensorRecord.bulk_create(sensor_records, batch_size=500)148 logger.info(f"批量插入 {len(records)} 条记录成功")149return len(records)150except Exception as e:151 logger.error(f"批量插入失败: {e}")152raise153154155def add_single_record(device_name: str, temperature: float,156 humidity: float = None, pressure: float = None,157 recorded_at: datetime = None):158"""添加单条记录"""159 device = get_or_create_device(device_name)160 record = SensorRecord.create(161 device=device,162 temperature=temperature,163 humidity=humidity,164 pressure=pressure,165 recorded_at=recorded_at or datetime.now()166 )167 logger.info(f"记录添加成功: {record}")168return record169170171# --- 查询功能 ---172def query_recent(device_name: str, hours: int = 24):173"""查询指定设备最近 N 小时的记录"""174 since = datetime.now() - timedelta(hours=hours)175return (176SensorRecord177 .select(SensorRecord, Device)178 .join(Device)179 .where(180Device.name == device_name,181SensorRecord.recorded_at >= since182 )183 .order_by(SensorRecord.recorded_at.desc())184 .limit(1000)185 )186187188def query_by_date_range(device_name: str = None,189 start_date: datetime = None,190 end_date: datetime = None):191"""按日期范围查询"""192 query = SensorRecord.select(SensorRecord, Device).join(Device)193194 conditions = []195if device_name:196 conditions.append(Device.name == device_name)197if start_date:198 conditions.append(SensorRecord.recorded_at >= start_date)199if end_date:200 conditions.append(SensorRecord.recorded_at <= end_date)201202if conditions:203 query = query.where(*conditions)204205return query.order_by(SensorRecord.recorded_at.desc())206207208def query_temperature_range(device_name: str, min_temp: float, max_temp: float):209"""查询温度范围内的记录"""210return (211SensorRecord212 .select(SensorRecord, Device)213 .join(Device)214 .where(215Device.name == device_name,216SensorRecord.temperature.between(min_temp, max_temp)217 )218 .order_by(SensorRecord.recorded_at.desc())219 )220221222# --- 统计分析 ---223def get_stats(device_name: str, days: int = 7):224"""获取统计信息"""225from peewee import fn226 since = datetime.now() - timedelta(days=days)227228 stats = (229SensorRecord230 .select(231 fn.AVG(SensorRecord.temperature).alias('avg_temp'),232 fn.MAX(SensorRecord.temperature).alias('max_temp'),233 fn.MIN(SensorRecord.temperature).alias('min_temp'),234 fn.AVG(SensorRecord.humidity).alias('avg_humidity'),235 fn.MAX(SensorRecord.humidity).alias('max_humidity'),236 fn.MIN(SensorRecord.humidity).alias('min_humidity'),237 fn.COUNT(SensorRecord.id).alias('total_records')238 )239 .join(Device)240 .where(241Device.name == device_name,242SensorRecord.recorded_at >= since243 )244 .dicts()245 .first()246 )247248return stats249250251def get_hourly_stats(device_name: str, date: datetime = None):252"""获取按小时统计的数据"""253from peewee import fn254if not date:255 date = datetime.now().date()256257 start_time = datetime.combine(date, datetime.min.time())258 end_time = start_time + timedelta(days=1)259260return (261SensorRecord262 .select(263 fn.strftime('%H', SensorRecord.recorded_at).alias('hour'),264 fn.AVG(SensorRecord.temperature).alias('avg_temp'),265 fn.COUNT(SensorRecord.id).alias('count')266 )267 .join(Device)268 .where(269Device.name == device_name,270SensorRecord.recorded_at.between(start_time, end_time)271 )272 .group_by(fn.strftime('%H', SensorRecord.recorded_at))273 .order_by(fn.strftime('%H', SensorRecord.recorded_at))274 .dicts()275 )276277278def get_daily_extremes(device_name: str, days: int = 30):279"""获取每日最高/最低温度"""280from peewee import fn281 since = datetime.now() - timedelta(days=days)282283return (284SensorRecord285 .select(286 fn.DATE(SensorRecord.recorded_at).alias('date'),287 fn.MAX(SensorRecord.temperature).alias('max_temp'),288 fn.MIN(SensorRecord.temperature).alias('min_temp'),289 fn.AVG(SensorRecord.temperature).alias('avg_temp')290 )291 .join(Device)292 .where(293Device.name == device_name,294SensorRecord.recorded_at >= since295 )296 .group_by(fn.DATE(SensorRecord.recorded_at))297 .order_by(fn.DATE(SensorRecord.recorded_at).desc())298 .dicts()299 )300301302# --- 数据清理 ---303def cleanup_old_records(days: int = 90):304"""清理旧记录"""305 cutoff = datetime.now() - timedelta(days=days)306 deleted = (SensorRecord307 .delete()308 .where(SensorRecord.recorded_at < cutoff)309 .execute())310 logger.info(f"删除了 {deleted} 条旧记录({days} 天前)")311return deleted312313314def delete_device_records(device_name: str):315"""删除指定设备的所有记录"""316try:317with db.atomic():318 device = Device.get(Device.name == device_name)319 deleted = (SensorRecord320 .delete()321 .where(SensorRecord.device == device)322 .execute())323 logger.info(f"删除设备 {device_name} 的 {deleted} 条记录")324return deleted325except Device.DoesNotExist:326 logger.warning(f"设备 {device_name} 不存在")327return 0328329330# --- 工具函数 ---331def generate_sample_data(device_name: str, days: int = 7, interval_minutes: int = 30):332"""生成示例数据"""333 device = get_or_create_device(device_name, f"测试位置_{device_name}")334335 records = []336 start_time = datetime.now() - timedelta(days=days)337 current_time = start_time338339 base_temp = 25.0340 base_humidity = 60.0341342while current_time < datetime.now():343# 模拟温度变化(加入日夜周期)344 hour = current_time.hour345 day_factor = abs(hour - 12) / 12 # 中午12点最热346 temp_variation = random.uniform(-2, 2)347 temperature = base_temp - day_factor * 5 + temp_variation348349# 模拟湿度变化350 humidity_variation = random.uniform(-10, 10)351 humidity = max(20, min(90, base_humidity + humidity_variation))352353# 模拟气压354 pressure = random.uniform(1000, 1020)355356 records.append({357'device_name': device_name,358'temperature': round(temperature, 1),359'humidity': round(humidity, 1),360'pressure': round(pressure, 1),361'recorded_at': current_time362 })363364 current_time += timedelta(minutes=interval_minutes)365366batch_insert(records)367 logger.info(f"为设备 {device_name} 生成了 {len(records)} 条示例数据")368369370def export_to_dict(device_name: str, hours: int = 24):371"""导出数据为字典格式"""372 records = query_recent(device_name, hours)373return [374 { 'device_name': r.device.name,375'temperature': r.temperature,376'humidity': r.humidity,377'pressure': r.pressure,378'recorded_at': r.recorded_at.isoformat()379 } for r in records380 ]381382383# --- 使用示例 ---384def demo():385"""演示功能"""386print("=== 传感器数据管理系统演示 ===\n")387388# 初始化数据库389init_database(reset=True)390391# 创建测试设备392 devices = ['温室A', '温室B', '仓库1']393for device_name in devices:394create_device(device_name, f"{device_name}位置")395396# 生成示例数据397for device_name in devices:398generate_sample_data(device_name, days=3, interval_minutes=60)399400# 查询演示401print("1. 最近24小时数据:")402 recent_records = query_recent('温室A', 24)403for r in recent_records[:5]: # 只显示前5条404print(f" {r.recorded_at}: {r.temperature}°C, {r.humidity}%")405406print(f"\n2. 温室A 统计信息:")407 stats = get_stats('温室A')408if stats:409print(f" 平均温度: {stats['avg_temp']:.1f}°C")410print(f" 最高温度: {stats['max_temp']:.1f}°C")411print(f" 最低温度: {stats['min_temp']:.1f}°C")412print(f" 记录总数: {stats['total_records']}")413414print(f"\n3. 温室A 每日极值:")415 daily_extremes = get_daily_extremes('温室A', 7)416for day in daily_extremes:417print(f" {day['date']}: 最高{day['max_temp']:.1f}°C, 最低{day['min_temp']:.1f}°C")418419print(f"\n4. 所有设备列表:")420for device in list_devices():421 record_count = device.records.count()422print(f" {device.name} ({device.location}) - {record_count} 条记录")423424425if __name__ == "__main__":426demo()
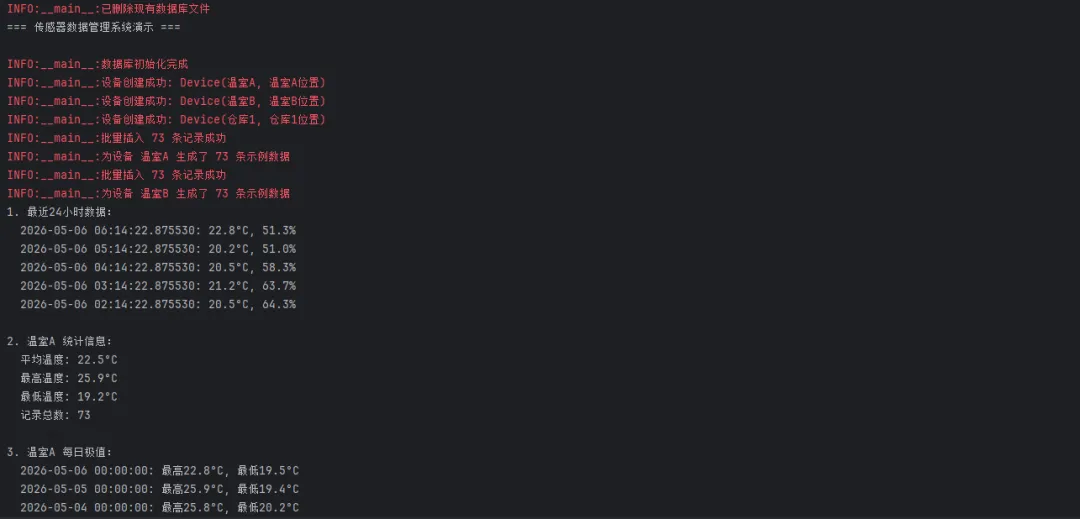
踩坑预警: 查询时如果不用 .join() 而是在循环里访问 record.device.name,会触发经典的 N+1 查询问题——100 条记录就是 101 次数据库请求。务必在 select 时把关联表一起取出来。
方案二:多线程安全的连接池方案
适用场景: Windows 上位机、数据中间件、后台采集服务,存在多线程并发写入。
Peewee 的默认 SqliteDatabase 不是线程安全的,多线程场景下需要换用 SqliteDatabasePool(由 playhouse 扩展提供)或者为每个线程维护独立连接。
python1from threading import Thread, Lock, local, current_thread2import time3from peewee import *4from datetime import datetime, timedelta5import logging6import random7import os89# 配置日志10logging.basicConfig(11 level=logging.INFO,12 format='%(asctime)s - %(threadName)s - %(levelname)s - %(message)s'13)14logger = logging.getLogger(__name__)1516# 线程本地存储,每个线程有自己的数据库连接17thread_local = local()1819# 全局数据库配置20DB_CONFIG = {21'database': 'sensor_data.db',22'pragmas': {23'journal_mode': 'wal',24'synchronous': 'normal',25'temp_store': 'memory',26'mmap_size': 268435456,27'foreign_keys': 1,28 }29}3031# 线程安全的设备ID缓存32device_id_cache = {}33cache_lock = Lock()343536def get_thread_db():37"""获取线程本地的数据库连接"""38if not hasattr(thread_local, 'db'):39# 为每个线程创建独立的数据库连接40 thread_local.db = SqliteDatabase(41DB_CONFIG['database'],42 pragmas=DB_CONFIG['pragmas']43 ) logger.debug(f"为线程 {current_thread().name} 创建了数据库连接")4445return thread_local.db464748def close_thread_db():49"""关闭线程本地的数据库连接"""50if hasattr(thread_local, 'db') and not thread_local.db.is_closed():51 thread_local.db.close()52 logger.debug(f"关闭了线程 {current_thread().name} 的数据库连接")535455class BaseModel(Model):56class Meta:57# 注意:这里不设置具体的database,将在运行时绑定58pass596061class Device(BaseModel):62"""设备信息表"""63 name = CharField(max_length=64, unique=True)64 location = CharField(max_length=128, null=True)65 status = CharField(max_length=20, default='active')66 created_at = DateTimeField(constraints=[SQL('DEFAULT CURRENT_TIMESTAMP')])6768class Meta:69 table_name = 'devices'7071def __str__(self):72return f"Device({self.name}, {self.location})"737475class SensorRecord(BaseModel):76"""传感器记录表"""77 device = ForeignKeyField(Device, backref='records', on_delete='CASCADE')78 temperature = FloatField()79 humidity = FloatField(null=True)80 pressure = FloatField(null=True)81 recorded_at = DateTimeField(index=True)8283class Meta:84 table_name = 'sensor_records'85 indexes = (86 (('device', 'recorded_at'), False),87 )8889def __str__(self):90return f"Record({self.device.name}, {self.temperature}°C, {self.recorded_at})"919293def bind_models_to_db(db):94"""将模型绑定到特定的数据库连接"""95 models = [Device, SensorRecord]96for model in models:97 model.bind(db)9899100# --- 数据库管理 ---101def safe_remove_database():102"""安全删除数据库文件"""103 db_files = ['sensor_data.db', 'sensor_data.db-wal', 'sensor_data.db-shm']104105for db_file in db_files:106if os.path.exists(db_file):107try:108for attempt in range(5):109try:110 os.remove(db_file)111 logger.info(f"已删除数据库文件: {db_file}")112break113except PermissionError:114if attempt < 4:115 logger.warning(f"删除 {db_file} 失败,等待重试...")116 time.sleep(0.2)117else:118 logger.error(f"无法删除 {db_file},文件可能被占用")119except Exception as e:120 logger.warning(f"删除 {db_file} 时出现错误: {e}")121122123def init_database(reset=False):124"""初始化数据库"""125try:126if reset:127safe_remove_database()128129# 使用线程本地数据库连接130 db = get_thread_db()131bind_models_to_db(db)132133 db.connect(reuse_if_open=True)134 db.create_tables([Device, SensorRecord], safe=True)135 logger.info("数据库初始化完成")136137# 预创建测试设备并缓存ID138 test_devices = [139 ('温室A', '北区温室A号'),140 ('温室B', '北区温室B号'),141 ('仓库1', '存储区1号仓库'),142 ('仓库2', '存储区2号仓库'),143 ('实验室', '研发中心实验室')144 ]145# 清空缓存146with cache_lock:147 device_id_cache.clear()148149for name, location in test_devices:150 device, created = Device.get_or_create(151 name=name,152 defaults={'location': location}153 ) if created:154 logger.info(f"创建测试设备: {device}")155156# 缓存设备ID157with cache_lock:158 device_id_cache[name] = device.id159160except Exception as e:161 logger.error(f"数据库初始化失败: {e}")162raise163finally:164close_thread_db()165166167# --- 线程安全的设备管理 ---168def get_device_id(device_name: str) -> int:169"""线程安全的设备ID获取(带缓存)"""170with cache_lock:171if device_name not in device_id_cache:172# 如果缓存中没有,重新查询173try:174 db = get_thread_db()175bind_models_to_db(db)176 db.connect(reuse_if_open=True)177178 device = Device.get(Device.name == device_name)179 device_id_cache[device_name] = device.id180 logger.debug(f"设备ID已缓存: {device_name} -> {device.id}")181except Device.DoesNotExist:182 logger.error(f"设备不存在: {device_name}")183raise184finally:185close_thread_db()186187return device_id_cache[device_name]188189190def clear_device_cache():191"""清空设备缓存"""192with cache_lock:193 device_id_cache.clear()194 logger.info("设备缓存已清空")195196197# --- 多线程数据写入 ---198def worker_thread(thread_id: int, device_name: str, record_count: int):199"""工作线程:模拟传感器数据采集和写入"""200 thread_name = f"Worker-{thread_id}"201 logger.info(f"[{thread_name}] 开始采集数据,目标: {record_count} 条")202203try:204# 获取线程本地数据库连接205 db = get_thread_db()206bind_models_to_db(db)207 db.connect(reuse_if_open=True)208209# 获取设备ID210 device_id = get_device_id(device_name)211212# 生成批量数据213 batch_data = []214 base_temp = 20.0 + thread_id * 2215216for i in range(record_count):217 temp_variation = random.uniform(-3, 3)218 humidity_variation = random.uniform(-15, 15)219 pressure_variation = random.uniform(-5, 5)220221 record = SensorRecord(222 device_id=device_id,223 temperature=round(base_temp + temp_variation, 1),224 humidity=round(50 + humidity_variation, 1),225 pressure=round(1013 + pressure_variation, 1),226 recorded_at=datetime.now() - timedelta(seconds=random.randint(0, 3600))227 )228 batch_data.append(record)229230# 分批写入231 batch_size = 200232 total_written = 0233234with db.atomic():235for i in range(0, len(batch_data), batch_size):236 batch = batch_data[i:i + batch_size]237SensorRecord.bulk_create(batch, batch_size=len(batch))238 total_written += len(batch)239240if i % (batch_size * 5) == 0 and total_written > 0:241 logger.info(f"[{thread_name}] 已写入 {total_written}/{record_count} 条")242243 logger.info(f"[{thread_name}] 完成写入 {total_written} 条数据")244245except Exception as e:246 logger.error(f"[{thread_name}] 写入失败: {e}")247import traceback248 traceback.print_exc()249finally:250close_thread_db()251252253def data_reader_thread(thread_id: int, device_name: str, query_count: int):254"""读取线程:模拟数据查询操作"""255 thread_name = f"Reader-{thread_id}"256 logger.info(f"[{thread_name}] 开始执行查询,次数: {query_count}")257258try:259 db = get_thread_db()260bind_models_to_db(db)261 db.connect(reuse_if_open=True)262263 device_id = get_device_id(device_name)264265for i in range(query_count):266 hours = random.randint(1, 24)267 since = datetime.now() - timedelta(hours=hours)268269 query = (SensorRecord270 .select()271 .where(272SensorRecord.device_id == device_id,273SensorRecord.recorded_at >= since274 )275 .order_by(SensorRecord.recorded_at.desc())276 .limit(100))277278 records = list(query)279280if i % 10 == 0:281 logger.info(f"[{thread_name}] 查询 {i + 1}/{query_count}: 获取到 {len(records)} 条记录")282283 time.sleep(0.01)284285 logger.info(f"[{thread_name}] 查询任务完成")286287except Exception as e:288 logger.error(f"[{thread_name}] 查询失败: {e}")289import traceback290 traceback.print_exc()291finally:292close_thread_db()293294295# --- 并发测试场景 ---296def simulate_concurrent_write(thread_count=4, records_per_thread=1000):297"""模拟多线程并发写入"""298print(f"\n=== 并发写入测试 ({thread_count} 线程, 每线程 {records_per_thread} 条) ===")299300 devices = ['温室A', '温室B', '仓库1', '仓库2', '实验室']301 threads = []302 start_time = time.time()303304for i in range(thread_count):305 device_name = devices[i % len(devices)]306 t = Thread(307 target=worker_thread,308 args=(i, device_name, records_per_thread),309 name=f"WriteThread-{i}"310 )311 threads.append(t)312 t.start()313 time.sleep(0.1)314315for t in threads:316 t.join()317318 end_time = time.time()319 total_records = thread_count * records_per_thread320 duration = end_time - start_time321 rate = total_records / duration if duration > 0 else 0322323print(f"写入完成: {total_records} 条记录,耗时 {duration:.2f}秒,速率 {rate:.0f} 条/秒")324325326def simulate_concurrent_read_write(write_threads=2, read_threads=3):327"""模拟读写并发场景"""328print(f"\n=== 读写并发测试 ({write_threads} 写线程, {read_threads} 读线程) ===")329330 devices = ['温室A', '温室B', '仓库1']331 threads = []332 start_time = time.time()333334# 启动写线程335for i in range(write_threads):336 device_name = devices[i % len(devices)]337 t = Thread(338 target=worker_thread,339 args=(i, device_name, 500),340 name=f"WriteThread-{i}"341 )342 threads.append(t)343 t.start()344345# 启动读线程346for i in range(read_threads):347 device_name = devices[i % len(devices)]348 t = Thread(349 target=data_reader_thread,350 args=(i, device_name, 50),351 name=f"ReadThread-{i}"352 )353 threads.append(t)354 t.start()355356for t in threads:357 t.join()358359 end_time = time.time()360print(f"读写并发测试完成,总耗时 {end_time - start_time:.2f}秒")361362363# --- 数据统计和监控 ---364def get_database_stats():365"""获取数据库统计信息"""366try:367 db = get_thread_db()368bind_models_to_db(db)369 db.connect(reuse_if_open=True)370371 device_count = Device.select().count()372 record_count = SensorRecord.select().count()373374# 最新记录时间375try:376 latest_record = (SensorRecord377 .select(SensorRecord.recorded_at)378 .order_by(SensorRecord.recorded_at.desc())379 .first())380 latest_time = latest_record.recorded_at if latest_record else None381except:382 latest_time = None383384return {385'devices': device_count,386'records': record_count,387'latest_record': latest_time,388 }389390finally:391close_thread_db()392393394def monitor_performance(duration_seconds=10):395"""性能监控"""396print(f"\n=== 性能监控 ({duration_seconds}秒) ===")397398 start_stats = get_database_stats()399print(f"监控开始 - 设备: {start_stats['devices']}, 记录: {start_stats['records']}")400401 threads = []402for i in range(3):403 t = Thread(404 target=worker_thread,405 args=(i, '温室A', 100),406 name=f"MonitorTest-{i}"407 )408 threads.append(t)409 t.start()410411 time.sleep(duration_seconds)412413for t in threads:414 t.join()415416 end_stats = get_database_stats()417 new_records = end_stats['records'] - start_stats['records']418419print(f"监控结束 - 新增记录: {new_records}, 总记录: {end_stats['records']}")420421422def check_database_status():423"""检查数据库状态"""424print(f"\n=== 数据库状态检查 ===")425print(f"数据库文件: {DB_CONFIG['database']}")426print(f"使用线程本地连接: 是")427428if os.path.exists(DB_CONFIG['database']):429print("数据库文件: 存在")430# 显示文件大小431try:432 size = os.path.getsize(DB_CONFIG['database'])433print(f"文件大小: {size} 字节")434except:435pass436else:437print("数据库文件: 不存在(将在初始化时创建)")438439440# --- 演示函数 ---441def demo():442"""完整的演示程序"""443print("=== 多线程传感器数据管理系统演示 ===\n")444445try:446# 1. 检查数据库状态447check_database_status()448449# 2. 初始化数据库450init_database(reset=True)451452# 3. 显示初始状态453 stats = get_database_stats()454print(f"\n初始状态 - 设备数: {stats['devices']}, 记录数: {stats['records']}")455456# 4. 并发写入测试457simulate_concurrent_write(thread_count=4, records_per_thread=500)458459# 5. 读写并发测试460simulate_concurrent_read_write(write_threads=2, read_threads=3)461462# 6. 性能监控463monitor_performance(duration_seconds=3)464465# 7. 最终统计466 final_stats = get_database_stats()467print(f"\n=== 最终统计 ===")468print(f"设备数: {final_stats['devices']}")469print(f"总记录数: {final_stats['records']}")470print(f"最新记录时间: {final_stats['latest_record']}")471472# 8. 清空缓存473clear_device_cache()474475print("\n演示完成!")476477except Exception as e:478 logger.error(f"演示过程中出现错误: {e}")479import traceback480 traceback.print_exc()481482483if __name__ == "__main__":484try:485demo()486except KeyboardInterrupt:487print("\n程序被用户中断")488except Exception as e:489 logger.error(f"程序执行失败: {e}")490import traceback491492 traceback.print_exc()493finally:494print("程序执行完毕")
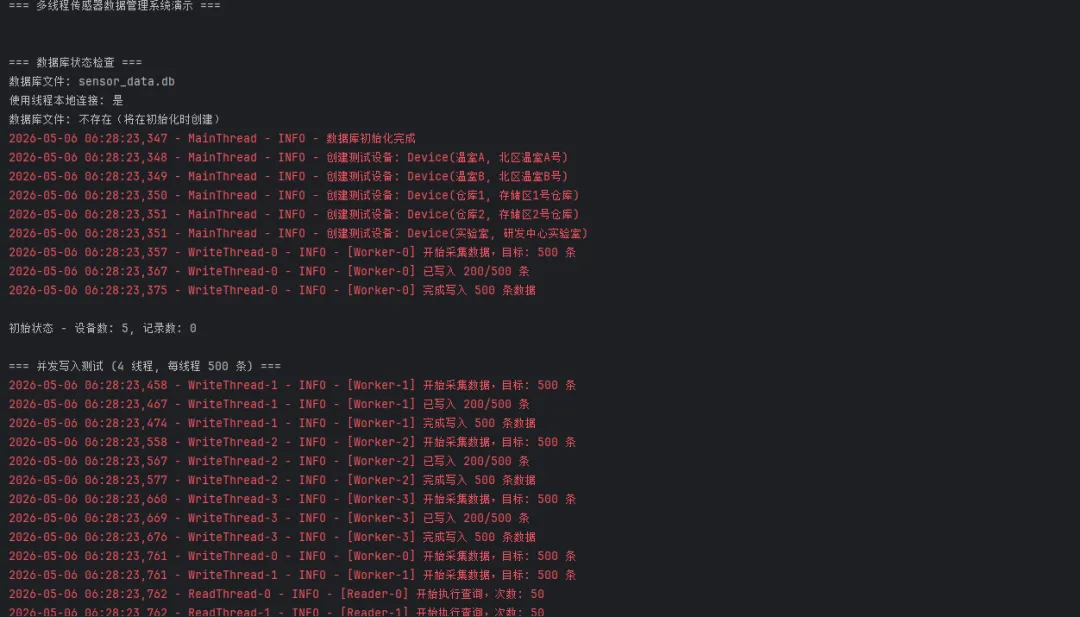
性能参考(测试环境:Windows 11 / Python 3.11 / SSD):
踩坑预警: 不要在线程间共享同一个 Model 实例,Peewee 的 Model 对象不是线程安全的。每个线程应当独立创建对象,通过 bulk_create 批量提交。
方案三:数据库迁移与 Schema 演进
适用场景: 项目迭代过程中需要修改表结构,不能删库重建。
Peewee 自带的 playhouse.migrate 模块提供了无损迁移能力:
python1from peewee import *2from playhouse.migrate import *3import os4import shutil5from datetime import datetime6import logging78# 配置日志9logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')10logger = logging.getLogger(__name__)1112# 数据库配置13db = SqliteDatabase('sensor_data.db', pragmas={14'journal_mode': 'wal',15'foreign_keys': 116})1718class BaseModel(Model):19class Meta:20 database = db2122class Device(BaseModel):23 name = CharField(max_length=64, unique=True)24 location = CharField(max_length=128, null=True)25 status = CharField(max_length=20, default='active')26 created_at = DateTimeField(constraints=[SQL('DEFAULT CURRENT_TIMESTAMP')])2728class Meta:29 table_name = 'devices'3031class SensorRecord(BaseModel):32 device = ForeignKeyField(Device, backref='records', on_delete='CASCADE')33 temperature = FloatField()34 humidity = FloatField(null=True)35 pressure = FloatField(null=True) # 这个字段在 v1.1 中添加36 recorded_at = DateTimeField(index=True)3738class Meta:39 table_name = 'sensor_records'4041class DatabaseVersion(BaseModel):42 version = CharField(max_length=10, unique=True)43 applied_at = DateTimeField(constraints=[SQL('DEFAULT CURRENT_TIMESTAMP')])4445class Meta:46 table_name = 'database_versions'4748# --- 实用工具函数 ---49def column_exists(table_name: str, column_name: str) -> bool:50"""检查表中是否存在指定列"""51try:52 cursor = db.execute_sql(f"PRAGMA table_info({table_name})")53 columns = [row[1] for row in cursor.fetchall()]54 exists = column_name in columns55 logger.debug(f"列 {table_name}.{column_name} {'存在' if exists else '不存在'}")56return exists57except Exception as e:58 logger.error(f"检查列存在性时出错: {e}")59return False6061def table_exists(table_name: str) -> bool:62"""检查表是否存在"""63try:64 cursor = db.execute_sql(65"SELECT name FROM sqlite_master WHERE type='table' AND name=?",66 (table_name,)67 )68 exists = cursor.fetchone() is not None69 logger.debug(f"表 {table_name} {'存在' if exists else '不存在'}")70return exists71except Exception as e:72 logger.error(f"检查表存在性时出错: {e}")73return False7475def safe_migrate_add_column(table_name: str, column_name: str, field):76"""安全地添加列(如果不存在)"""77if not column_exists(table_name, column_name):78 migrator = SqliteMigrator(db)79 logger.info(f"添加列: {table_name}.{column_name}")80migrate(migrator.add_column(table_name, column_name, field))81return True82else:83 logger.info(f"列 {table_name}.{column_name} 已存在,跳过添加")84return False8586def safe_migrate_add_index(table_name: str, columns: list, unique: bool = False):87"""安全地添加索引(如果不存在)"""88 index_name = f"{table_name}_{'_'.join(columns)}_{'unique' if unique else 'index'}"89try:90# 检查索引是否存在91 cursor = db.execute_sql(92"SELECT name FROM sqlite_master WHERE type='index' AND name=?",93 (index_name,)94 )95if cursor.fetchone() is None:96 migrator = SqliteMigrator(db)97 logger.info(f"添加索引: {index_name}")98migrate(migrator.add_index(table_name, columns, unique=unique))99return True100else:101 logger.info(f"索引 {index_name} 已存在,跳过添加")102return False103except Exception as e:104 logger.error(f"添加索引时出错: {e}")105return False106107# --- 备份和恢复 ---108def create_backup():109"""创建数据库备份"""110if not os.path.exists('sensor_data.db'):111return None112 backup_dir = 'backups'113 os.makedirs(backup_dir, exist_ok=True)114 current_version = get_current_version()115 timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')116 backup_filename = f"sensor_data_v{current_version}_{timestamp}.db"117 backup_path = os.path.join(backup_dir, backup_filename)118try:119# 确保数据库连接关闭120if not db.is_closed():121 db.close()122 shutil.copy2('sensor_data.db', backup_path)123 logger.info(f"数据库备份已创建: {backup_path}")124return backup_path125except Exception as e:126 logger.error(f"创建备份失败: {e}")127return None128finally:129# 重新连接数据库130 db.connect()131132def restore_from_backup(backup_path):133"""从备份恢复数据库"""134try:135if not db.is_closed():136 db.close()137if os.path.exists(backup_path):138 shutil.copy2(backup_path, 'sensor_data.db')139 logger.info(f"数据库已从备份恢复: {os.path.basename(backup_path)}")140return True141else:142 logger.error(f"备份文件不存在: {backup_path}")143return False144except Exception as e:145 logger.error(f"从备份恢复失败: {e}")146return False147finally:148 db.connect()149150# --- 版本管理 ---151def get_current_version():152"""获取当前数据库版本"""153try:154if not table_exists('database_versions'):155return '1.0' # 默认版本156 latest = (DatabaseVersion157 .select()158 .order_by(DatabaseVersion.applied_at.desc())159 .first())160return latest.version if latest else '1.0'161except Exception as e:162 logger.error(f"获取版本失败: {e}")163return '1.0'164165def set_version(version):166"""设置数据库版本"""167try:168# 确保版本表存在169if not table_exists('database_versions'):170 db.create_tables([DatabaseVersion])171DatabaseVersion.create(version=version)172 logger.info(f"数据库版本已更新为: {version}")173except Exception as e:174 logger.error(f"设置版本失败: {e}")175176# --- 迁移函数 ---177def migration_v1_1():178"""迁移到 v1.1: 添加 pressure 字段"""179 logger.info("开始执行迁移: v1.0 -> v1.1")180try:181# 安全地添加 pressure 列182 pressure_field = FloatField(null=True, default=None)183 added = safe_migrate_add_column('sensor_records', 'pressure', pressure_field)184if added:185 logger.info("迁移 v1.1 完成: 添加了 pressure 列")186else:187 logger.info("迁移 v1.1 完成: pressure 列已存在")188except Exception as e:189 logger.error(f"迁移 v1.1 失败: {e}")190raise191192def migration_v1_2():193"""迁移到 v1.2: 添加索引和优化"""194 logger.info("开始执行迁移: v1.1 -> v1.2")195try:196# 添加复合索引(如果不存在)197safe_migrate_add_index('sensor_records', ['device_id', 'recorded_at'])198# 添加设备状态索引(如果不存在)199safe_migrate_add_index('devices', ['status'])200 logger.info("迁移 v1.2 完成: 添加了性能索引")201except Exception as e:202 logger.error(f"迁移 v1.2 失败: {e}")203raise204205# 迁移映射206MIGRATIONS = {207'1.1': migration_v1_1,208'1.2': migration_v1_2,209}210211def run_migrations(target_version):212"""执行迁移到目标版本"""213 current_version = get_current_version()214 logger.info(f"当前数据库版本: {current_version}")215 logger.info(f"目标版本: {target_version}")216if current_version == target_version:217 logger.info("数据库已是最新版本")218return219# 创建备份220 backup_path = create_backup()221try:222# 按顺序执行迁移223 version_order = ['1.1', '1.2']224 current_index = version_order.index(current_version) if current_version in version_order else -1225 target_index = version_order.index(target_version)226for i in range(current_index + 1, target_index + 1):227 version = version_order[i]228 logger.info(f"执行迁移: {current_version} -> {version}")229if version in MIGRATIONS:230MIGRATIONS[version]()231set_version(version)232 current_version = version233else:234 logger.warning(f"未找到版本 {version} 的迁移函数")235 logger.info(f"所有迁移完成,当前版本: {target_version}")236except Exception as e:237 logger.error(f"迁移过程中出错: {e}")238if backup_path:239 logger.info("正在回滚到备份...")240restore_from_backup(backup_path)241raise242243# --- 数据库初始化和演示 ---244def init_database():245"""初始化数据库"""246if os.path.exists('sensor_data.db'):247 logger.info("数据库已存在")248else:249 logger.info("创建新数据库")250 db.connect()251# 创建基础表252 db.create_tables([Device, SensorRecord, DatabaseVersion], safe=True)253# 设置初始版本(如果没有版本记录)254if get_current_version() == '1.0' and not table_exists('database_versions'):255set_version('1.0')256257def seed_data():258"""填充示例数据"""259try:260# 创建设备261 devices_data = [262 {'name': '温室A', 'location': '北区温室A号'},263 {'name': '温室B', 'location': '北区温室B号'},264 {'name': '仓库1', 'location': '存储区1号'},265 {'name': '仓库2', 'location': '存储区2号'},266 {'name': '实验室', 'location': '研发中心'},267 ]268for device_data in devices_data:269Device.get_or_create(name=device_data['name'], defaults=device_data)270# 创建传感器记录271import random272from datetime import timedelta273274 devices = list(Device.select())275 records_to_create = []276for device in devices:277for i in range(100):278 record = SensorRecord(279 device=device,280 temperature=round(random.uniform(18, 28), 1),281 humidity=round(random.uniform(40, 80), 1),282 recorded_at=datetime.now() - timedelta(hours=random.randint(0, 72))283 )284 records_to_create.append(record)285# 批量创建记录286if records_to_create:287SensorRecord.bulk_create(records_to_create, batch_size=100)288 logger.info(f"创建了 {len(records_to_create)} 条传感器记录")289except Exception as e:290 logger.error(f"填充数据失败: {e}")291292def show_migration_status():293"""显示迁移状态"""294print("\n=== 数据库迁移状态 ===")295print(f"当前版本: {get_current_version()}")296print(f"数据库文件: sensor_data.db")297# 显示备份文件298 backup_dir = 'backups'299if os.path.exists(backup_dir):300 backups = [f for f in os.listdir(backup_dir) if f.endswith('.db')]301print(f"\n可用备份 ({len(backups)} 个):")302for backup in sorted(backups, reverse=True)[:5]: # 只显示最新的5个303 backup_path = os.path.join(backup_dir, backup)304 size = os.path.getsize(backup_path)305print(f" - {backup} ({size:,} 字节)")306else:307print("\n可用备份 (0 个):")308# 显示表统计309print("\n数据库表:")310try:311 device_count = Device.select().count()312 record_count = SensorRecord.select().count()313print(f" - devices: {device_count} 条记录")314print(f" - sensor_records: {record_count} 条记录")315except Exception as e:316print(f" - 无法获取统计信息: {e}")317318def demo():319"""演示数据库迁移"""320print("=== Peewee 数据库迁移演示 ===\n")321try:322print("1. 初始化数据库...")323init_database()324# 填充一些示例数据325seed_data()326print("\n2. 初始状态:")327show_migration_status()328print("\n3. 执行迁移到 v1.2...")329run_migrations('1.2')330print("\n4. 迁移后状态:")331show_migration_status()332print("\n5. 验证新功能...")333# 测试 pressure 字段334try:335# 更新一些记录的 pressure 值336 records = SensorRecord.select().limit(10)337for record in records:338 record.pressure = round(random.uniform(1010, 1020), 1)339 record.save()340# 查询有 pressure 数据的记录341 records_with_pressure = SensorRecord.select().where(342SensorRecord.pressure.is_null(False)343 ).count()344print(f" - 成功更新了 pressure 字段")345print(f" - 有 pressure 数据的记录: {records_with_pressure} 条")346except Exception as e:347print(f" - pressure 字段验证失败: {e}")348print("\n迁移演示完成!")349except Exception as e:350 logger.error(f"演示过程中出现错误: {e}")351import traceback352 traceback.print_exc()353354if __name__ == "__main__":355demo()
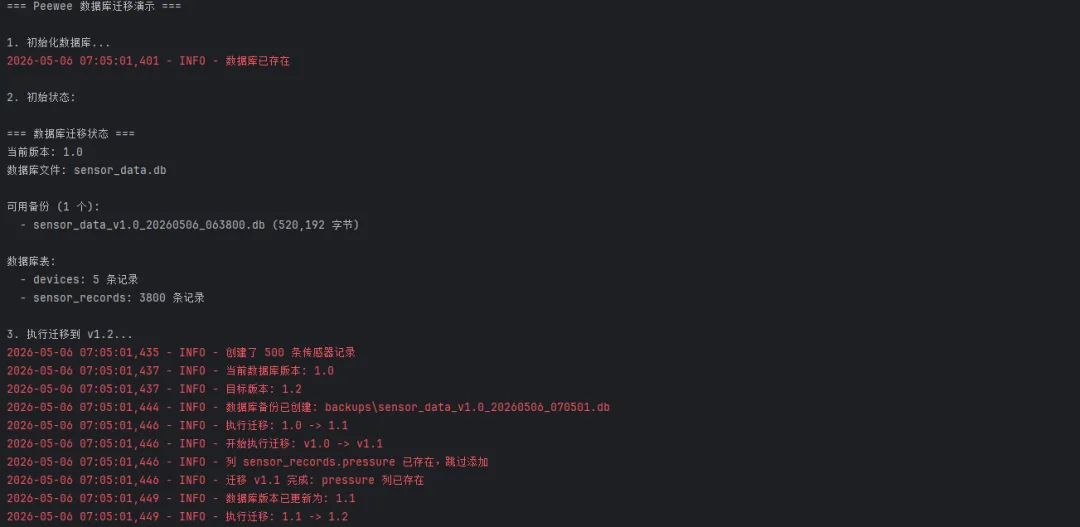
这种方式比手写 ALTER TABLE SQL 更安全,也比引入 Alembic 轻量得多。对于中小型项目,playhouse.migrate 完全够用。
踩坑预警: SQLite 的 ALTER TABLE 原生只支持添加列,不支持删除或重命名列。如果需要删除列,Peewee 的迁移工具会通过"建新表 → 复制数据 → 删旧表"的方式完成,耗时会随数据量增大,建议在低峰期执行。
🧩 可复用代码模板
以下是一个适合直接集成到上位机或中间件项目的 数据库管理器模板:
python1# db_manager.py —— 可直接复用的 Peewee 管理模板2from peewee import *3from playhouse.pool import PooledSqliteDatabase4from contextlib import contextmanager5import logging67logger = logging.getLogger(__name__)89class DatabaseManager:10def __init__(self, db_path: str, max_connections: int = 4):11 self.db = PooledSqliteDatabase(12 db_path,13 max_connections=max_connections,14 stale_timeout=300,15 pragmas={16'journal_mode': 'wal', # WAL 模式,提升并发写入性能17'cache_size': -64 * 1024, # 64MB 缓存18'synchronous': 'normal', # 平衡安全与性能19 }20 )2122@contextmanager23def get_connection(self):24"""线程安全的连接上下文"""25 self.db.connect(reuse_if_open=True)26try:27yield self.db28finally:29if not self.db.is_closed():30 self.db.close()3132def init_tables(self, models: list):33"""初始化所有表"""34with self.get_connection():35 self.db.create_tables(models, safe=True)36 logger.info(f"已初始化 {len(models)} 张数据表")3738def bulk_write(self, model_class, data: list[dict], batch_size: int = 500):39"""通用批量写入接口"""40with self.get_connection():41with self.db.atomic():42 model_class.bulk_create(43 [model_class(**d) for d in data],44 batch_size=batch_size45 )46 logger.debug(f"批量写入 {len(data)} 条 {model_class.__name__} 记录")
journal_mode = 'wal' 这个 pragma 值得特别说一下——WAL(Write-Ahead Logging)模式让读写操作不再互相阻塞,在上位机这种"持续写入 + 偶发查询"的场景下,吞吐量提升非常明显,实测并发读写场景下性能提升约 40~60%。
💬 技术讨论
两个值得深入思考的问题,欢迎在评论区分享你的实践经验:
话题一: 在你的项目中,选择 ORM 的核心决策因素是什么?是团队熟悉度、性能、还是迁移能力?
话题二: 对于 SQLite 的并发写入瓶颈,你有没有遇到过 database is locked 的问题,最终是怎么解决的?
📌 三句话技术洞察
- • 轻量不等于低能,Peewee 在 10 万级数据量以内的场景,性能和开发效率都优于 SQLAlchemy ORM 层。
- • WAL 模式是 SQLite 并发场景的标配,一行 pragma 配置换来显著的吞吐提升,没有理由不用。
- • N+1 查询是 ORM 的头号性能杀手,无论用哪个框架,联表查询时都要养成
join + select 一起写的习惯。
🎯 总结与学习路径
本文围绕 Peewee 的三个核心能力展开:模型定义与基础 CRUD、多线程连接池管理、Schema 迁移实践。这三个层次覆盖了从原型开发到生产部署的完整链路。
如果你的项目规模在中小型范围内,数据库表数量不超过 20 张,建议直接从 Peewee 入手,而不是一上来就引入 SQLAlchemy 的全套体系。等业务复杂度真正上去了,再做技术选型迁移也不迟。
推荐学习路径:
- 1. Peewee 官方文档(重点看 Querying 和 Playhouse 章节)
- 2.
playhouse 扩展库:pool、migrate、shortcuts、sqlite_ext - 3. 进阶方向:结合
APScheduler 实现定时采集 + Peewee 持久化的完整中间件架构
标签:PythonORMPeeweeSQLite数据库性能优化上位机中间件Python开发编程技巧

