你有没有想过,让ChatGPT只基于你自己的文档来回答?喂进去你三年的日记,它就变成一个了解你的私人助手。听起来很复杂?其实50行Python代码就能搞定。今天老于手把手教你,从零搭一个AI知识库,代码全给,跟着敲就能跑通。- Python 3.9以上(Mac自带,Windows去官网下)
pip install chromadb sentence-transformers openai
sentence-transformers:把文字转成数字(向量),方便比对含义。openai:调大模型的SDK,我们用DeepSeek的接口,便宜到几乎免费。pip install chromadb sentence-transformers openai -i https://pypi.tuna.tsinghua.edu.cn/simple
新建一个文件夹,里面放你要喂给AI的文档。先用几条文本测试,后面再接真实文件。# 你的知识库,换成你自己的文档内容knowledge_base = ["公司年假制度:入职满1年享5天年假,满3年享10天,满10年享15天。年假不可跨年累积。","报销流程:登录OA系统→财务→报销申请→上传发票→直属领导审批→财务打款。审批周期3个工作日。","产品定价:基础版299元/月,专业版599元/月,企业版按需报价。年付打8折。","技术栈:后端用Go语言,前端React,数据库PostgreSQL,部署在阿里云华东区。","客户常见问题:密码重置在登录页点忘记密码,支持手机号和邮箱两种方式。",]
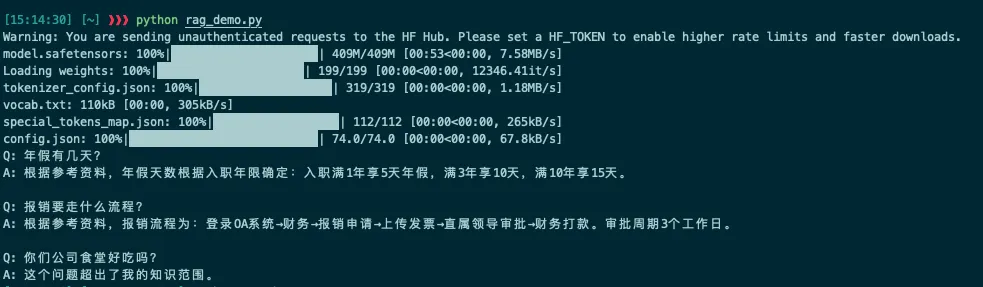
import chromadbfrom sentence_transformers import SentenceTransformerfrom openai import OpenAI# 向量化模型(中文用这个,英文用all-MiniLM-L6-v2)embed_model = SentenceTransformer('shibing624/text2vec-base-chinese')# 向量数据库chroma_client = chromadb.Client()collection = chroma_client.create_collection("my_knowledge")# 知识库knowledge_base = [ "公司年假制度:入职满1年享5天年假,满3年享10天,满10年享15天。年假不可跨年累积。", "报销流程:登录OA系统→财务→报销申请→上传发票→直属领导审批→财务打款。审批周期3个工作日。", "产品定价:基础版299元/月,专业版599元/月,企业版按需报价。年付打8折。", "技术栈:后端用Go语言,前端React,数据库PostgreSQL,部署在阿里云华东区。", "客户常见问题:密码重置在登录页点忘记密码,支持手机号和邮箱两种方式。",]# 把文档转成向量存进去embeddings = embed_model.encode(knowledge_base).tolist()collection.add( documents=knowledge_base, embeddings=embeddings, ids=[f"doc_{i}" for i in range(len(knowledge_base))])# DeepSeek API(去 platform.deepseek.com 注册,免费送额度)llm = OpenAI( api_key="api_key", base_url="https://api.deepseek.com")def ask(question): # 先检索:找到最相关的文档 q_embedding = embed_model.encode([question]).tolist() results = collection.query(query_embeddings=q_embedding, n_results=3) context = "\n".join(results['documents'][0]) # 再回答:把文档和问题一起交给大模型 prompt = f"""你是一个专业的知识库助手。只基于以下参考资料回答问题。如果资料里没有相关信息,请直接说"这个问题超出了我的知识范围"。不要编造信息。参考资料:{context}用户问题:{question}""" response = llm.chat.completions.create( model="deepseek-chat", messages=[{"role": "user", "content": prompt}] ) return response.choices[0].message.content# 测试!print("Q: 年假有几天?")print("A:", ask("年假有几天?"))print()print("Q: 报销要走什么流程?")print("A:", ask("报销要走什么流程?"))print()print("Q: 你们公司食堂好吃吗?")print("A:", ask("你们公司食堂好吃吗?"))
- "年假有几天?"→ 准确回答入职年限和天数对应关系
- "食堂好吃吗?"→ 老老实实说"这个问题超出了我的知识范围"
pip install pymupdfimport fitz # pymupdfdefread_pdf(path): doc = fitz.open(path)return"\n".join([page.get_text() for page in doc])
defread_markdown(path):withopen(path, 'r', encoding='utf-8') as f:return f.read()
defread_txt(path):withopen(path, 'r', encoding='utf-8') as f:return f.read()
defsplit_text(text, chunk_size=300, overlap=50):"""按字数切片,每段300字,前后重叠50字""" chunks = [] start = 0while start < len(text): end = start + chunk_size chunks.append(text[start:end]) start = end - overlapreturn chunks
然后把 `knowledge_base` 换成切好的文档片段就行:text = read_pdf("你的文档.pdf")knowledge_base = split_text(text)
sentence-transformers默认的all-MiniLM-L6-v2是英文模型,中文效果很差。一定要换成 `shibing624/text2vec-base-chinese`,我上面代码已经换了。一段话超过500字,大模型容易抓不住重点。建议200-400字切一片,我代码里默认300字。一段话不到50字,语义不完整,检索到了也没用。overlap参数就是解决这个问题的——前后两片重叠50字,保证上下文不断裂。去 platform.deepseek.com 注册,创建API Key,免费额度够你测试几百次。注意key是sk-开头的字符串,别复制多了空格。sentence-transformers第一次要下载模型(约400MB),后面就秒开。下载卡住的话:import osos.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
-接网页:用requests+BeautifulSoup抓网页内容,喂进去-接微信聊天记录:导出聊天记录txt,做成私人记忆库-搭个Web界面:用Gradio三行代码做成网页版,分享给同事用-多文档管理:给每个文档加metadata,支持按文件名过滤检索这些进阶玩法后面几期会专门讲,评论区告诉我你最想接什么,我优先写。我是老于,专注分享好用的AI工具和黑科技。关注见微见深,高效摸鱼,下篇见。