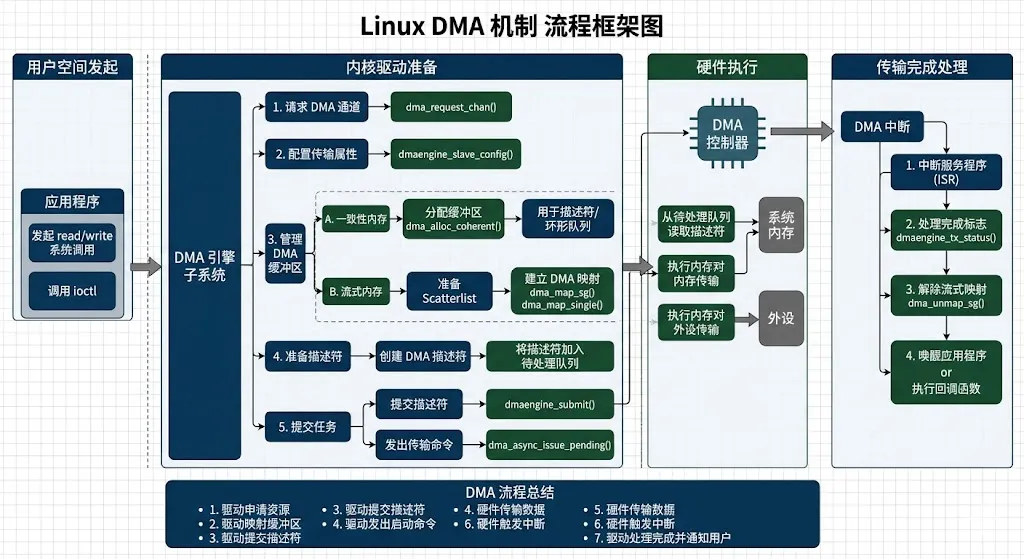
先看一个框架图,有疑问我们一起群里讨论或者评论去留言第一章:为什么 Linux 驱动离不开 DMA
1.1 CPU 搬运数据为什么越来越吃力
在早期 MCU 或低速外设时代,CPU 使用轮询或者中断方式读取寄存器,再逐字节搬运数据,是一种非常常见的设计。例如 UART 收到一个字节,CPU 进入中断,从 RX FIFO 中读取数据,再写入内存缓冲区。整个过程虽然效率不高,但由于数据量有限,CPU 完全可以承担这种数据拷贝工作。
但 Linux 所面对的场景已经完全不同。千兆网卡、NVMe SSD、4K 摄像头、PCIe FPGA、高速 ADC 等设备的数据吞吐量远远超过 CPU 逐字节搬运的能力。如果一个 10Gbps 网卡仍然依赖 CPU 搬运数据,那么 CPU 大部分时间都会陷入 memcpy、cache miss、总线等待以及频繁中断之中,系统调度能力会急剧下降。
DMA(Direct Memory Access,直接内存访问)的核心目标,就是把“数据搬运”这件事从 CPU 手中剥离出去。CPU 只负责配置 DMA 控制器,例如:源地址、目的地址、长度、触发方式等;而真正的数据传输则由 DMA 硬件自行完成。这样 CPU 不需要参与每个字节的搬运,仅在 DMA 完成时收到一次中断即可。
这也是 Linux 驱动性能优化中的核心思想之一:CPU 不负责“搬运”,CPU 只负责“调度”。现代 Linux 高性能驱动,例如网卡驱动、音频驱动、MMC 驱动、SPI 驱动,几乎都依赖 DMA 实现高吞吐低占用的数据交换。
1.2 PIO 与 DMA 的本质差异
很多开发者第一次接触 DMA 时,只是把它理解成“硬件自动拷贝”。但实际上,DMA 与 PIO(Programmed IO)在系统结构上是两种完全不同的数据流模型。
PIO 模式下,CPU 是数据通路的核心节点:
DMA 模式下,CPU 只负责控制:
这意味着在 DMA 模式下:
CPU 不需要参与每个数据字节搬运
中断数量显著减少
cache 污染降低
上下文切换次数减少
总线利用率提高
尤其在 Linux SMP 多核系统中,PIO 会导致大量软中断竞争、cache line 抖动以及总线争用,而 DMA 则能显著改善系统整体吞吐能力。
下面是一个典型的数据流对比图。
PIO模式:+--------+ 中断 +-----+| Device | ---------------> | CPU |+--------+ +-----+ | | memcpy v +-----------+ | Memory | +-----------+DMA模式:+--------+ DMA Request +-----------+| Device | ---------------->| DMA CTRL |+--------+ +-----------+ | | AXI/AHB v +-----------+ | Memory | +-----------+CPU仅负责配置DMA寄存器
从 Linux 内核视角看,DMA 的真正价值并不仅仅是“更快”,而是让 CPU 从 IO 密集型事务中解放出来,使系统具备更好的实时性与调度能力。
第二章:Linux DMA 子系统架构
2.1 Linux DMA Framework 分层结构
Linux 并不是简单地暴露 DMA 控制器寄存器给驱动使用,而是构建了一套完整的 DMA Framework。这样做的目的,是屏蔽不同 SoC DMA 控制器之间的差异,使驱动能够通过统一 API 完成 DMA 操作。
Linux DMA 子系统大致可以分为以下几层:
+--------------------------------+| Device Driver |+--------------------------------+| DMA Engine Framework |+--------------------------------+| DMA Controller Driver |+--------------------------------+| DMA Hardware |+--------------------------------+
驱动开发者通常只需要和 DMA Engine Framework 打交道,而不需要直接操作 DMA 控制器寄存器。Framework 会根据设备树、DMA channel、capability 等信息,自动匹配底层 DMA 控制器驱动,例如:
STM32 使用 STM32 DMA
RK3568 使用 PL330 DMA
i.MX 使用 SDMA
TI 使用 EDMA
但上层 SPI/UART/I2S 驱动代码几乎可以保持一致,Linux 中常见 DMA API:
struct dma_chan *dma_request_chan(struct device *dev, const char *name);void *dma_alloc_coherent(struct device *dev, size_t size, dma_addr_t *dma_handle, gfp_t flag);struct dma_async_tx_descriptor *dmaengine_prep_slave_single( struct dma_chan *chan, dma_addr_t buf, size_t len, enum dma_transfer_direction dir, unsigned long flags);
这些 API 本质上完成了:
DMA channel 分配
DMA buffer 映射
cache 同步
DMA transaction 构建
DMA 传输启动
DMA 完成通知
整个框架已经高度工程化。
2.2 DMA Channel 与 DMA Descriptor
很多初学者认为 DMA 就是“配置地址然后开始传输”,但 Linux DMA Engine 的核心其实是 Descriptor(描述符)机制,DMA Descriptor 本质上是一个任务描述结构,DMA 控制器会根据 Descriptor 自动执行传输动作,一个 Descriptor 通常包含:
- 源地址- 目的地址- 长度- burst长度- 传输方向- next descriptor- callback
Linux DMA Engine 会把这些描述符组织成链表,从而实现 scatter-gather、循环 DMA、链式 DMA 等高级功能。
例如网卡驱动中常见的 RX Ring:
Descriptor0 -> Descriptor1 -> Descriptor2 ^ | |_____________________________|
DMA 控制器不断循环处理这些 descriptor,网卡数据就会源源不断写入内存,而 CPU 只需处理完成后的 buffer,Linux 内核中的 descriptor 提交流程:
desc = dmaengine_prep_slave_single(chan, dma_handle, len, DMA_DEV_TO_MEM, DMA_PREP_INTERRUPT);if (!desc) return -ENOMEM;desc->callback = uart_dma_rx_done;dmaengine_submit(desc);dma_async_issue_pending(chan);
其中:
这个流程本质上类似“提交 IO 请求”。
第三章:DMA 内存与 Cache 一致性
3.1 为什么 DMA Buffer 不能随便 malloc
很多开发者第一次写 DMA 驱动时,会直接使用 kmalloc 申请内存,然后把地址给 DMA 控制器。但这样在 Linux 上非常容易出现数据错误。
原因在于:CPU Cache 与 DMA 是并行工作的,例如:
CPU 修改 buffer↓数据只写入 cache↓DMA 从 DDR 读取↓DMA读到旧数据或者:DMA 写入 DDR↓CPU 仍然读取旧 cache↓读到脏数据因此 Linux DMA 必须解决 cache coherence(一致性)问题。
Linux 提供了专用 DMA 内存接口:
void *dma_alloc_coherent(struct device *dev, size_t size, dma_addr_t *dma_handle, gfp_t gfp);
接口的特点主要有下面四个:
返回 CPU 虚拟地址
返回 DMA 物理地址
cache coherent
DMA 与 CPU 数据一致
典型的使用,比如uart的使用:,这里要使用连续申请的接口,否则容易数据一致性的错误
struct uart_dma { void *rx_buf; dma_addr_t rx_dma;};uart->rx_buf = dma_alloc_coherent(dev, 4096, &uart->rx_dma, GFP_KERNEL);DMA 控制器使用 rx_dma,CPU 使用 rx_buf,这是 Linux DMA 编程中最重要的规则之一。
3.2 Streaming DMA 与 Cache 同步
dma_alloc_coherent 虽然方便,但它通常对应 uncached 或 strongly-ordered 内存,CPU 访问性能并不高,所以Linux 还提供 Streaming DMA 模式,Streaming DMA 使用普通 cacheable 内存,但需要手动同步 cache:
dma_map_single()dma_unmap_single()dma_sync_single_for_cpu()dma_sync_single_for_device()例如:buf = kmalloc(2048, GFP_KERNEL);dma_addr = dma_map_single(dev, buf, 2048, DMA_TO_DEVICE);
DMA 启动前:CPU Cache -> DDR,DMA 完成后:DDR -> invalidate CPU Cache,否则数据一致性会彻底混乱,Linux 中大量高性能驱动,例如我们经常遇到的相关内容:
cache 同步流程图:
CPU写Buffer | v+------------+| CPU Cache |+------------+ | dma_map_single | v+------------+| DDR |+------------+ | v DMA EngineDMA 完成后:DMA写DDR | vdma_sync_for_cpu | vCPU重新读取DDR
这历史 Linux DMA 调试中最容易踩坑的地方
第四章:DMA 驱动源码深度解析
4.1 UART DMA 接收驱动实现
下面以 UART DMA 接收为例,分析 Linux 驱动如何实现高速串口接收,设备树:
uart7: serial@fe690000 { compatible = "rockchip,rk3568-uart"; dmas = <&dmac0 2>, <&dmac0 3>; dma-names = "tx", "rx";};
驱动初始化:
struct uart_dma { struct dma_chan *rx_chan; void *rx_buf; dma_addr_t rx_dma; struct completion rx_done;};
申请 DMA channel:
uart->rx_chan = dma_request_chan(dev, "rx");if (IS_ERR(uart->rx_chan)) { dev_err(dev, "request dma failed\n"); return PTR_ERR(uart->rx_chan);}
申请 DMA buffer:
uart->rx_buf = dma_alloc_coherent(dev, 4096, &uart->rx_dma, GFP_KERNEL);
配置 DMA transaction:
desc = dmaengine_prep_slave_single( uart->rx_chan, uart->rx_dma, 4096, DMA_DEV_TO_MEM, DMA_PREP_INTERRUPT);
设置完成回调:
desc->callback = uart_dma_rx_complete;desc->callback_param = uart;
启动 DMA:
cookie = dmaengine_submit(desc);if (dma_submit_error(cookie)) { dev_err(dev, "submit failed\n"); return -EINVAL;}dma_async_issue_pending(uart->rx_chan);
DMA 完成中断:
static void uart_dma_rx_complete(void *arg){ struct uart_dma *uart = arg; printk("rx done\n"); process_rx_data(uart->rx_buf); complete(&uart->rx_done);}
整个过程中:
CPU 不参与字节搬运
UART FIFO 自动触发 DMA
DMA 自动写入内存
CPU 仅处理完成回调
这是 Linux 高速串口驱动的标准架构。
4.2 DMA 环形缓冲区实现
在持续数据流场景下,例如:
一次 DMA 完成后再重新配置 DMA,会产生明显间隙。因此 Linux 常使用 cyclic DMA(循环 DMA),其核心结构:
+--------+--------+--------+--------+| BUF0 | BUF1 | BUF2 | BUF3 |+--------+--------+--------+--------+ ^ | |_________________________|
DMA 不断循环写入,Linux API:
desc = dmaengine_prep_dma_cyclic( chan, dma_addr, buf_len, period_len, DMA_DEV_TO_MEM, DMA_PREP_INTERRUPT);
其中:buf_len:整个 ring buffer,period_len:单次触发长度
例如:总buffer:4096,period:1024
DMA 每写完 1024 字节触发一次中断,这类似声卡中的 period buffer,完成回调:
staticvoiddma_rx_period_done(void *data){ struct uart_dma *uart = data; size_t pos; pos = dmaengine_tx_status( uart->rx_chan, uart->cookie, NULL); printk("current pos=%zu\n", pos);}
这种模式下:
DMA 永不停止
CPU 按 period 消费数据
延迟极低
吞吐极高
Linux ALSA 音频框架就是这种设计。
第五章:DMA 高性能优化机制
5.1 Scatter-Gather DMA
如果 DMA 每次只能处理一块连续内存,那么 CPU 仍然需要进行大量 buffer 拼接,因此现代 DMA 控制器基本都支持 Scatter-Gather,Scatter-Gather 本质:
多个离散buffer↓descriptor链表↓DMA自动连续处理
例如:BUF0 -> BUF1 -> BUF2 -> BUF3,DMA 自动读取 descriptor 链,Linux 中对应:
struct scatterlist sg[4];sg_init_table(sg, 4);sg_set_buf(&sg[0], buf0, 1024);sg_set_buf(&sg[1], buf1, 1024);sg_set_buf(&sg[2], buf2, 1024);sg_set_buf(&sg[3], buf3, 1024);
映射 SG:dma_map_sg(dev,sg, 4,DMA_FROM_DEVICE);
准备 DMA:
desc = dmaengine_prep_slave_sg(chan,sg,4,DMA_DEV_TO_MEM, DMA_PREP_INTERRUPT);
Scatter-Gather 能极大减少:
这是网卡零拷贝的重要基础。
5.2 DMA 与中断合并
高速设备如果每个 packet 都触发一次中断,会导致系统陷入 interrupt storm,100万包/s→100万次IRQ/s,CPU 会被中断彻底打爆,所以Linux 高性能驱动通常结合:
DMA
Interrupt Coalescing
NAPI
Polling
网卡的DMA流程:
DMA连续接收数据↓Ring Buffer积累packet↓达到阈值后触发一次IRQ↓NAPI poll批量收包
这就是 Linux 网络栈高性能的核心,典型驱动代码:
napi_schedule(&priv->napi);
poll函数:
static int xxx_poll(struct napi_struct *napi, int budget){ int work_done = 0; while (work_done < budget) { if (!packet_ready()) break; process_packet(); work_done++; } if (work_done < budget) { napi_complete_done(napi, work_done); enable_irq(); } return work_done;}
DMA 负责搬运,NAPI 负责批处理,两者结合后,Linux 才能实现百万 PPS 网络吞吐。
完整流程:
网卡收包 | vDMA写RingBuffer | v达到IRQ阈值 | v触发一次中断 | vNAPI Poll批量收包 | v协议栈处理
这也是 Linux 网络性能优化中的核心机制。
第六章:DMA 调试与实际工程问题
6.1 DMA 常见故障排查
DMA 驱动调试远比普通驱动困难,因为 DMA 问题一般不是“立刻崩溃”,一般是会有以下这些情况:
偶发数据错误
丢包
cache 脏数据
数据错位
半包
descriptor 卡死
DMA timeout
最常见的问题是 cache coherence,比如:CPU看到的数据正确但是DMA看到的数据错误,或者DMA写入完成,CPU仍然读取旧cache,这类问题通常需要:
dma_sync_single_for_cpu();dma_sync_single_for_device();
另一个常见问题是 DMA 地址错误。
很多开发者会直接:virt_to_phys(buf)这是错误的,Linux DMA 地址并不一定等于物理地址,因为IOMMU SMMU DMA offset bus address translation都可能存在,正确方式必须使用相关接口dma_map_single()或者dma_alloc_coherent(),否则 DMA 很容易直接写飞。
6.2 Linux DMA 性能调优实践
实际项目中,DMA 性能往往并不只取决于 DMA 本身,而是系统整体结构
DDR 带宽
AXI 仲裁
cache line 对齐
burst length
NUMA
IRQ affinity
buffer 大小
都会影响最终吞吐。
典型优化方向:
第一,buffer 对齐__aligned(64),避免 cache line 抖动。
第二,增大 burst,1beat → 4beat → 8beat → 16beat提高总线利用率。
第三,减少 IRQ,每4KB中断一次→每64KB中断一次
第四,使用 hugepage,减少 TLB miss。
第五,CPU 绑定,echo 2 > /proc/irq/88/smp_affinity避免 cache migration。
第六,NUMA 优化,DMA buffer 尽量靠近设备所在 NUMA node,在高端服务器中,这些优化甚至比 DMA 本身更重要。
下面是一个 Linux DMA 完整工作流程,大家可以简单了解下
+-------------+| Driver Init |+-------------+ | v申请DMA Channel | v申请DMA Buffer | v配置Descriptor | v启动DMA Engine | vDMA搬运数据 | vDMA完成中断 | vDriver Callback | v上层协议处理
Linux DMA 不仅仅是一个“硬件加速器”,它现在已经成为现代 Linux IO 子系统的核心的基础设施了,都是因为要考虑性能,所以都在让CPU去做单独的事情,DMA还有其他相关的都去单独的事情,从 UART、SPI、I2S、MMC,到 Ethernet、NVMe、GPU、AI Accelerator,所有高性能设备最终都离不开 DMA,所以理解 Linux DMA,其实就是理解 Linux IO 的底层运行机制。