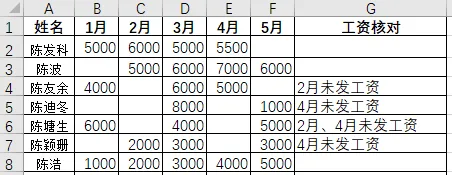
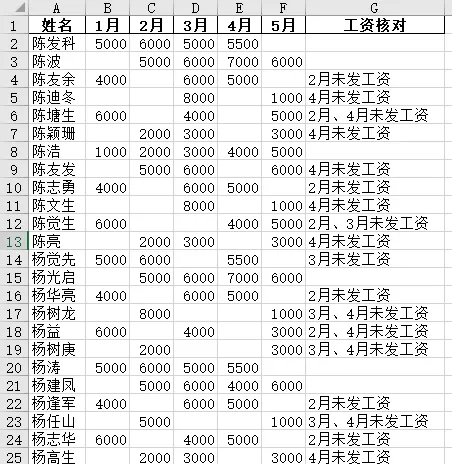
动态识别连续单元格区域是一个经常遇到的问题。我最近就遇到一个这样的问题:一份按月份发放工资的汇总表,没有发工资的月份对应的单元格为空。需求是判断从第一次到最后一次发工资之间哪些月份是空的,并在最后一列标注“某月、某月未发工资"。如下表第三行数据,从第一个月到最后一个月,只有2月份没有发放工资,你需要在后面指定单元格标注"2月未发工资”。解决这个问题,最为关键的一步就是第一个月和最后一个月并不是固定的,需要动态调整。今天我就分享一段可以自动完成这个任务的Python代码。它不仅能够自动识别并汇总连续区域未填写工资的月份,还能够直接生成核对清单。import pandas as pddef strip_list(series): s = series.replace("",pd.NA) first_valid = s.first_valid_index() last_valid = s.last_valid_index() first = s.index.get_loc(first_valid) last = s.index.get_loc(last_valid) num_list = [] for i in range(first,last+1): if pd.isna(s.iloc[i]): num_list.append(str(s.index[i])) if num_list: text = "、".join(num_list) + "未发工资" return text else: return Nonepath = r"d:\统计连续区域中的空单元格.xlsx"df = pd.read_excel(path,usecols=[0,1,2,3,4,5])df["工资核对"] = ""for r,row in df.iterrows(): df.at[r,"工资核对"] = strip_list(row[1:])df.to_excel(r"d:\统计连续区域中的空单元格_1.xlsx",index=False)
s = series.replace("",pd.NA)
series.replace("",pd.NA)可以把空字符串转化为pandas可以识别的空值。空字符串可能是"",也可能是NaN,这句代码可将所有空字符串统一替换为pd.NA。 first_valid = s.first_valid_index() last_valid = s.last_valid_index()
s.first_valid_index():从左边开始查找,返回第一个非空的列标签,如:2月。s.last_valid_index():从右边开始查找,返回最后一个非空的列标签,如4月。这样就可以实现从2月到4月之间查找空档。 first = s.index.get_loc(first_valid) last = s.index.get_loc(last_valid)
因为后续需要使用range来进行数据的循环遍历,必须使用数字位置,s.index是列标签列表,.get_loc可以将标签转换为位置数字(索引从0开始)。num_list = []for i in range(first,last+1): if pd.isna(s.iloc[i]): num_list.append(str(s.index[i]))
pd.isna():判断是否为空值。如果是空值就把对应的列标签转换为字符串后加入列表。if num_list: text = "、".join(num_list) + "未发工资" return textelse: return None
如果num_list列表不为空,就用“、”连接所有月份,再拼接“未发工资”。如果没有漏发月份,就返回None。path = r"d:\统计连续区域中的空单元格.xlsx"df = pd.read_excel(path,usecols=[0,1,2,3,4,5])
在这里[0,1,2,3,4,5]列表表示仅读取了前6列。df["工资核对"] = ""for r,row in df.iterrows(): df.at[r,"工资核对"] = strip_list_pd(row[1:])
首先新增一列“工资核对”,再通过for循环遍历df.iterrows(),返回每一行的索引和行数据,再调用自定义函数进行数据处理并赋值。df.to_excel(r"d:\统计连续区域中的空单元格_1.xlsx",index=False)
index=False:不保存行索引,避免多出一列没有用的数字序号。这段代码虽然只有25行,却能动态处理连续区间空档,不需要你重复、繁琐的核对,无论你的工资表有几百行还是几千行,都能轻松解决,有需要的小伙伴赶紧对手试试吧。如果你觉得有用的话,记得点赞、收藏并转发给更多需要的同事哦!

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
