前面我们学完KNN、SVM,两款都是有监督学习算法,需要提前准备带标签的训练数据才能完成分类任务。
但在实际图像处理中,很多场景没有任何标签、无需提前训练,只需要机器自动根据特征相似度完成分组。
这就必须掌握传统机器学习的另一大核心算法:K-Means(K均值聚类)。
作为最经典的无监督聚类算法,K-Means 在 OpenCV 图像处理中最常用、最落地的场景就是:图像颜色量化。
简单说就是:用少量代表性颜色替代原图海量色彩,实现图像压缩、卡通化、色彩降噪。
今天带大家从零吃透 K-Means 原理、迭代逻辑、OpenCV 原生接口、参数详解,手把手实现多档位颜色量化实战,零基础直接落地!
一、什么是 K-Means 聚类?通俗大白话
K-Means全称 K均值聚类,是无监督机器学习算法的标杆,全程无需标签、无需人工标注,自动完成数据分组。
核心思想一句话:把相似的数据自动抱团,分成 K 组,组内相似度最高,组间差异最大。
对应到图像场景:
图片由无数像素组成,每个像素都有 BGR 三色数值(色彩特征),K-Means 会自动把颜色相近的像素归为一类,每一类用一个中心色替代。
这就是颜色量化的底层逻辑!
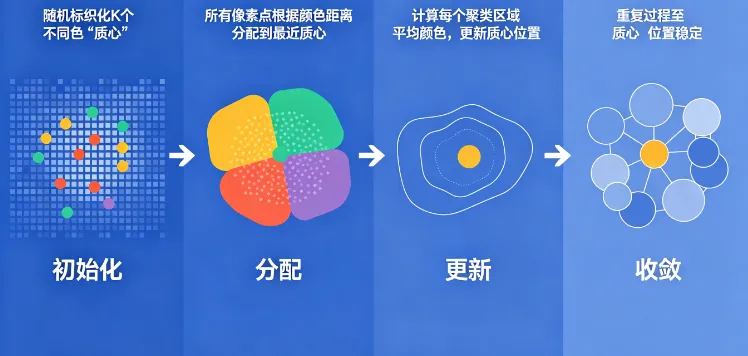
K-Means 四大迭代步骤(必懂)
•步骤1:初始化:随机选取 K 个聚类中心(代表K种核心颜色)
•步骤2:分配归类:计算所有像素与K个中心的欧式距离,就近归类
•步骤3:更新质心:重新计算每一类像素的色彩平均值,作为新聚类中心
•步骤4:迭代收敛:重复上述过程,直到质心不再变化或达到最大迭代次数
二、什么是图像颜色量化?
普通彩色图片色彩极其丰富,一张图可能包含上万种颜色,存在大量色彩冗余。
颜色量化:通过 K-Means 聚类,将原图海量色彩压缩为 K 种代表性颜色,在保留画面主体内容的前提下,大幅减少颜色数量。
落地价值:
•✅ 图像轻量化压缩,减小文件体积
•✅ 去除色彩噪点,画面更干净通透
•✅ 快速生成卡通、手绘、扁平风特效图
•✅ 简化色彩特征,辅助图像分割、目标检测预处理
三、OpenCV kmeans 核心函数参数详解
OpenCV 原生提供 cv2.kmeans()接口,无需手动实现迭代逻辑,开箱即用,参数适配图像处理场景。
pythoncv2.kmeans(data, K, bestLabels, criteria, attempts, flags) |
•data:输入数据,图像需转为(像素总数,3)浮点型数组(BGR三通道特征)
•K:聚类数量(最终保留的颜色数量),核心可调参数
•bestLabels:输出每个样本的聚类标签,默认填None
•criteria:迭代终止条件(最大迭代次数、精度阈值)
•attempts:重复聚类次数,多次运算取最优结果,避免局部最优解
•flags:质心初始化方式,默认KMEANS_RANDOM_CENTERS随机初始化
四、完整实战:K-Means 图像颜色量化(可直接运行)
实现原图色彩压缩,支持自定义K值,输出量化效果图,自带迭代优化、画质优化逻辑。
pythonimport cv2import numpy as np# 1、读取图像img = cv2.imread("test.jpg")h, w = img.shape[:2]# 2、数据预处理:重塑为(N,3)浮点型数据,适配K-Means输入# 每一行代表一个像素的BGR三个特征值data = img.reshape((-1, 3)).astype(np.float32)# 3、设置迭代终止条件# 满足最大迭代次数 或 精度达标,停止迭代criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 20, 0.1)# 4、K-Means聚类核心计算K = 8 # 保留8种核心颜色,可自行修改3/5/10/20compactness, labels, centers = cv2.kmeans(data,K,None,criteria,attempts=10,flags=cv2.KMEANS_RANDOM_CENTERS)# 5、还原图像:用聚类中心颜色替换所有像素centers = np.uint8(centers) # 转回图像整型数值result = centers[labels.flatten()]result = result.reshape((h, w, 3))# 6、展示与保存cv2.imshow("Original", img)cv2.imshow(f"KMeans Color Quantization K={K}", result)cv2.imwrite(f"quant_K{K}.jpg", result)cv2.waitKey(0)cv2.destroyAllWindows() |
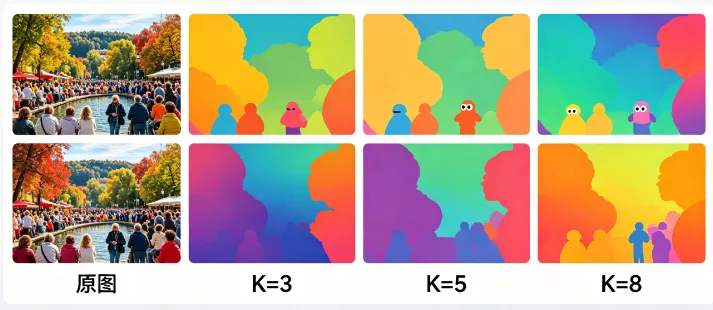
五、K值调优实战指南(直接抄作业)
K值是颜色量化的唯一核心参数,不同取值对应不同效果:
•K=3~5:极致扁平卡通风、极简色彩、强艺术特效,适合海报、手绘风格生成
•K=6~10:平衡画质与压缩率,画面干净无噪,保留主体层次,日常预处理首选
•K=15~30:高还原量化,几乎接近原图,仅去除冗余杂色,适合图像降噪优化
核心规律:K值越小,色彩越简约、压缩率越高、艺术感越强;K值越大,色彩越接近原图。
六、K-Means 核心输出参数解读
•compactness(紧凑度):所有像素到对应聚类中心的距离总和,数值越小,聚类效果越好
•labels(标签):每个像素对应的聚类类别索引,用于匹配中心色
•centers(聚类中心):K组BGR核心颜色值,就是量化后图像的全部色彩
七、K-Means 优缺点总结
✅ 优点
•无监督学习,无需标注数据,零训练成本
•算法轻量、速度快、适配所有尺寸图像
•完美实现图像色彩降噪、压缩、风格化处理
•逻辑简单、可控性强,仅需调K值即可适配不同场景
❌ 缺点
•K值需要人工设定,无法自动确定最优聚类数
•对初始质心敏感,偶尔出现局部最优解(可通过attempts优化)
•对色彩极其相近的细微纹理区分能力弱
八、新手高频避坑指南
•坑1:未转换浮点型数据K-Means 必须输入 float32 类型数据,整型图像直接运算会聚类失效
•坑2:数据维度错误图像必须重塑为(-1,3),不能保留二维图像结构,否则参数不匹配
•坑3:K值随意设置K=1会整图变成单色,K值过大失去压缩意义,根据场景合理取值
•坑4:忽略迭代条件迭代次数过少,聚类不收敛,量化画面色彩断层、失真严重
•坑5:不做多次尝试单次聚类容易受随机质心影响,attempts设置10次以上,保证最优效果
九、全文总结
KNN、SVM 是做分类,K-Means 是做聚类,三者构成了 OpenCV 传统机器学习的完整闭环。
如果说有监督算法是“照着答案学习”,那 K-Means 就是“自主总结规律”。
图像颜色量化是K-Means最经典、最落地的CV实战场景,既能实现图像压缩、色彩降噪,又能快速生成卡通艺术特效,兼具实用性和趣味性。
熟练掌握 K 值调参、迭代优化逻辑,足以应对90%的图像色彩预处理、风格化处理项目!
❤️ 点赞+在看,后台回复关键词【KMeans】,领取多档位批量量化代码+自动最优K值筛选工具+卡通化特效完整工程!
关注本号,持续更新 OpenCV 传统机器学习全套实战干货!
评论区打卡:KMeans颜色量化,吃透无监督聚类图像实战!

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
