Python学习【174】:Hive vs MySQL:一篇讲透数据仓库与关系型数据库的核心区别(附 Docker 实战)
为什么说 Hive 是“Hadoop 的 SQL 翻译器”?外部表又是什么黑科技?很多大数据初学者常常困惑:Hive 和 MySQL 都是用来管理数据的,它们到底有什么不同?为什么有了 MySQL 还要用 Hive?本文将从本质定义、核心差异、以及最具 Hive 特色的 外部表(External Table) 入手,带你彻底理解 Hive 的设计哲学。最后,我们还会在上一篇文章搭建的 Docker Hive 环境中,亲手创建一个外部表来查询 CSV 文件,让你直观感受“零 ETL”的威力。Hive 是一个基于 Hadoop 的数据仓库工具,它本身并不是一个数据库。它的核心工作流程是:把用户写的类 SQL 语句(HiveQL)翻译成 MapReduce、Tez 或 Spark 任务,然后交给 Hadoop 集群去执行。因此,你可以把 Hive 理解为一个 “SQL 翻译器”。- 数据存储:所有数据都存放在 HDFS(Hadoop 分布式文件系统)上。
- 元数据管理:表的结构、列信息、分区信息等“元数据”存储在关系型数据库(如 MySQL、PostgreSQL)中。
- 执行引擎:将 HiveQL 转化为计算任务(早期是 MapReduce,现在多用 Tez 或 Spark)。
2.2 Hive vs MySQL:一张表看懂核心差异2.3 什么是外部表?为什么它是 Hive 的灵魂?外部表(External Table) 是 Hive 最有特色、最实用的特性之一。它允许你在不移动数据文件的情况下,直接让 Hive 管理它们。如果你想用 MySQL 分析一批 CSV 文件,你必须:- 使用 LOAD DATA INFILE 或编写程序把 CSV 导入到 MySQL 的存储引擎中。
- 导入完成后,CSV 文件就成了“备份”,数据实际存放在 MySQL 的数据目录下。
这个过程叫做 ETL。如果 CSV 文件很大(比如几十 GB),导入既耗时又占用额外磁盘空间。Hive 外部表的做法 - 你已经有 CSV 文件躺在 HDFS 或本地文件系统上。
- 在 Hive 中创建一个 外部表(EXTERNAL),只定义表结构,并指定文件存放的目录。
- 数据文件原封不动,Hive 只是在其元数据库中记录了“这个表的文件在哪个目录”。
- 当你查询外部表时,Hive 会直接去读取那些文件,并行处理,返回结果。
- 多格式支持:CSV、JSON、Parquet、ORC 等都能直接读。
- 分区自动发现:如果文件按 /logs/dt=2024-01-01/ 组织,Hive 可以自动识别分区。
- 共享数据:同一份文件可以被 Hive、Spark、Presto、甚至 pandas 同时读取,没有“私有格式”限制。
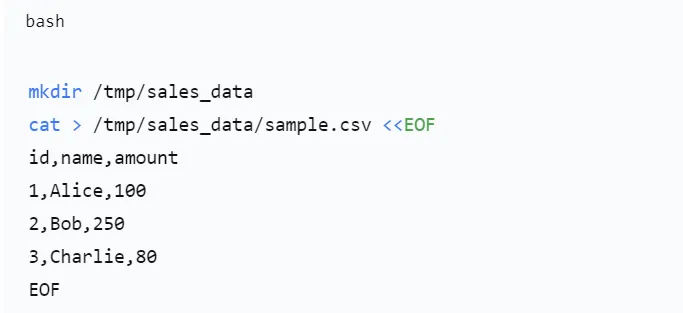
2.4 实战:在 Docker Hive 中创建外部表查询 CSV 文件沿用上一篇文章搭建的 bde2020/hive 环境,我们可以在容器内演示外部表。我们在容器内创建一个目录,并生成一个简单的 CSV:说明:LOCATION 必须是一个目录,Hive 会读取该目录下所有文件(支持多个文件)。ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' 表示 CSV 格式。STORED AS TEXTFILE 说明文件是纯文本。我们可以在容器外部(宿主机)往 /tmp/sales_data 目录下追加一个新文件(比如通过共享文件夹或 docker cp),然后再次查询,新数据会自动出现。例如:回到 Beeline 重新查询 SELECT * FROM sales;,你会看到新数据已经包含在内。然后退出 Beeline,在容器内检查 /tmp/sales_data/sample.csv 和 new.csv 是否仍然存在?—— 它们依然存在,因为 EXTERNAL 表只删除了元数据。Hive 不是数据库,而是一个数据仓库工具,它把 SQL 翻译成 Hadoop 计算任务,适合 PB 级数据的离线分析。MySQL 是传统关系型数据库,擅长小数据量、高并发、低延迟的在线事务。外部表是 Hive 的精髓:让数据留在原处,Hive 只提供表结构映射,实现“即席查询”和“多工具共享数据。通过 Docker,我们可以在单机上快速体验 Hive 外部表的强大能力。如果你正在处理海量日志、传感器数据或者需要构建企业级数据湖,Hive + 外部表会是你的得力工具。而 MySQL 则依然是网站后台、业务系统的中流砥柱。两者互补,而非替代。让我们保持学习的热情,2026年一马当先、马到成功!