先验直觉:银行审批贷款时,不会只看一个"能不能还",而是把每个申请人的特征(收入、年龄、负债率、职业等)转化成一个分数。分数越高,违约概率越低。评分卡正是这个转换器——它不是黑箱,每个变量对分数的贡献都是透明的:你的职业加5分、你的收入段加15分、你的负债率扣10分……最终总分决定审批。这套透明机制之所以在金融业沿用几十年,是因为它既能过合规审计,又能跟客户解释清楚。
关键词:R语言、信用评分卡、WOE编码、IV变量筛选、Logistic回归、评分映射、AUC、KS
01 评分卡的核心框架
信用评分卡(Credit Scorecard)是一套逻辑回归 + 线性分数变换的体系。它的核心流程只有4步:
1. WOE编码:将原始变量映射为"证据权重"(Weight of Evidence),让每个分箱对应一个风险度量
2. IV筛选:用信息量(Information Value)衡量每个变量的区分能力,剔除弱变量
3. Logistic回归:用WOE值作为输入,训练违约概率模型
4. 分数映射:将模型输出的对数几率(log-odds)线性变换为整数分数
这套框架最大的优势是可解释性——每一个变量对最终分数的贡献可以拆解到每个分箱,审计时能说清楚"为什么这个客户被拒"。
R语言做评分卡的优势
R语言在风控领域有深厚积淀,尤其是在评分卡开发标准流程中:
- `scorecard` 包:专用的评分卡建模包,内置WOE分箱、IV计算、分数映射
- `smbinning` 包:最优分箱算法,支持单调性约束
02 WOE与IV:从信息论到特征工程
数学定义
设样本总数为 ,其中好客户(还款)个,坏客户(违约)个。将变量分成个分箱,第箱中有个好客户、 个坏客户:
好客户占比: 坏客户占比:
WOE公式:
IV公式:
IV的判定标准:
WOE编码的核心优势
- 变量标准化:不同量纲的变量(年龄18~80岁 vs 收入0~100万)经过WOE编码后,值都在同一风险度量尺度上
- 非线性处理:分箱操作自动捕获变量与违约概率之间的非线性关系
- 缺失值处理:缺失值可以单独分箱,由数据自动决定WOE值
- 单调性约束:评分卡通常要求每个变量的WOE与违约率呈单调关系,便于业务解释
03 R语言实现全流程
数据准备
使用经典的German Credit数据集。R中可以通过多个包获得,这里直接从URL读取CSV格式。
# 加载必备包library(dplyr)# 数据处理library(ggplot2)# 基础可视化(评分分布使用Python图)library(pROC)# ROC/AUC计算# 读取German Credit数据# UCI仓库的German Credit数据credit_url <-"https://archive.ics.uci.edu/ml/machine-learning-databases/statlog/german/german.data"credit_raw <- read.table(credit_url, header =FALSE, stringsAsFactors =TRUE)# 添加列名colnames(credit_raw)<-c("checking_status","duration","credit_history","purpose","credit_amount","savings_status","employment","installment_rate","personal_status","other_debtors","residence_since","property","age","other_installment","housing","existing_credits","job","dependents","telephone","foreign_worker","target")# 目标变量转换:原始数据中 1=good(好), 2=bad(坏)credit_raw$target <- ifelse(credit_raw$target ==2,1,0)credit_raw$target <- factor(credit_raw$target, levels =c(0,1), labels =c("good","bad"))str(credit_raw)
输出:
'data.frame':1000 obs. of 21 variables:$checking_status :Factorw/4levels...$duration :int6481242243624361230...$credit_history :Factorw/5levels...$purpose :Factorw/10levels...$credit_amount :int1169 5951 2096 7882 4870 9055 2835 6948 3059 5234......
训练/测试集划分
set.seed(42)train_idx <- sample(1:nrow(credit_raw), size =0.7* nrow(credit_raw))train <- credit_raw[train_idx,]test <- credit_raw[-train_idx,]cat("训练集:", nrow(train),"条, 测试集:", nrow(test),"条\n")cat("训练集坏账率:", mean(train$target =="bad")*100,"%\n")cat("测试集坏账率:", mean(test$target =="bad")*100,"%\n")
输出:
训练集: 700 条, 测试集: 300 条训练集坏账率: 30.1 %测试集坏账率: 29.7 %
WOE分箱函数
下面实现完整的WOE分箱和IV计算:
#' WOE分箱函数#' #' @param x 数值或因子向量#' @param y 目标变量(因子,good/bad)#' @param max_bins 最大分箱数#' @return 包含分箱结果、WOE、IV的列表calc_woe <-function(x, y, max_bins =10){# 将x转换为数值分组if(is.numeric(x)){# 等宽分箱 n_unique <-length(unique(x))if(n_unique <= max_bins){ groups <- factor(x)}else{ breaks <- unique(quantile(x, probs = seq(0,1, length.out =min(max_bins +1, n_unique +1)), na.rm =TRUE))if(length(breaks)<2){ groups <- factor(rep(1,length(x)))}else{ groups <- cut(x, breaks = breaks, include.lowest =TRUE, dig.lab =6)}}}else{# 分类变量:合并低频类别到"其他" tbl <- table(x) rare <-names(tbl[tbl /length(x)<0.05])if(length(rare)>0&&length(rare)<length(tbl)){ x <-as.character(x) x[x %in% rare]<-"Other" groups <- factor(x, levels =c(setdiff(names(tbl), rare),"Other"))}else{ groups <- x}}# 计算每个分箱的好/坏计数 tbl <- table(groups, y)if(ncol(tbl)<2){return(NULL)} good_col <- which(colnames(tbl)=="good") bad_col <- which(colnames(tbl)=="bad") n_good <-as.numeric(tbl[, good_col]) n_bad <-as.numeric(tbl[, bad_col])# 防止除零:加平滑 n_good <- pmax(n_good,0.5) n_bad <- pmax(n_bad,0.5) total_good <-sum(n_good) total_bad <-sum(n_bad) p_good <- n_good / total_good p_bad <- n_bad / total_bad woe <-log(p_good / p_bad) iv <-sum((p_good - p_bad)* woe)# 坏账率 bad_rate <- n_bad /(n_good + n_bad) result <- data.frame( bin = rownames(tbl), n_total = n_good + n_bad -1,# 去掉平滑影响 n_bad = n_bad -0.5, n_good = n_good -0.5, bad_rate = bad_rate, woe = woe, stringsAsFactors =FALSE)list( bins = result, iv = iv, groups = groups)}
计算所有变量的WOE和IV
# 选择特征变量(去掉target)features <- setdiff(names(train),"target")# 存储WOE结果woe_results <-list()iv_values <- data.frame(variable = character(), iv = numeric(), stringsAsFactors =FALSE)for(var in features){ res <- calc_woe(train[[var]], train$target)if(!is.null(res)){ woe_results[[var]]<- res iv_values <- rbind(iv_values, data.frame(variable = var, iv = res$iv, stringsAsFactors =FALSE))}}# 按IV降序排列iv_values <- iv_values[order(-iv_values$iv),]print(iv_values[1:10,], row.names =FALSE)
输出:
variable ivchecking_status 0.75401942 duration 0.29439083 credit_history 0.29197968 savings_status 0.26758780 property 0.15415693 housing 0.15039489 purpose 0.13109064 age 0.12516795 credit_amount 0.10108881 employment 0.07251429
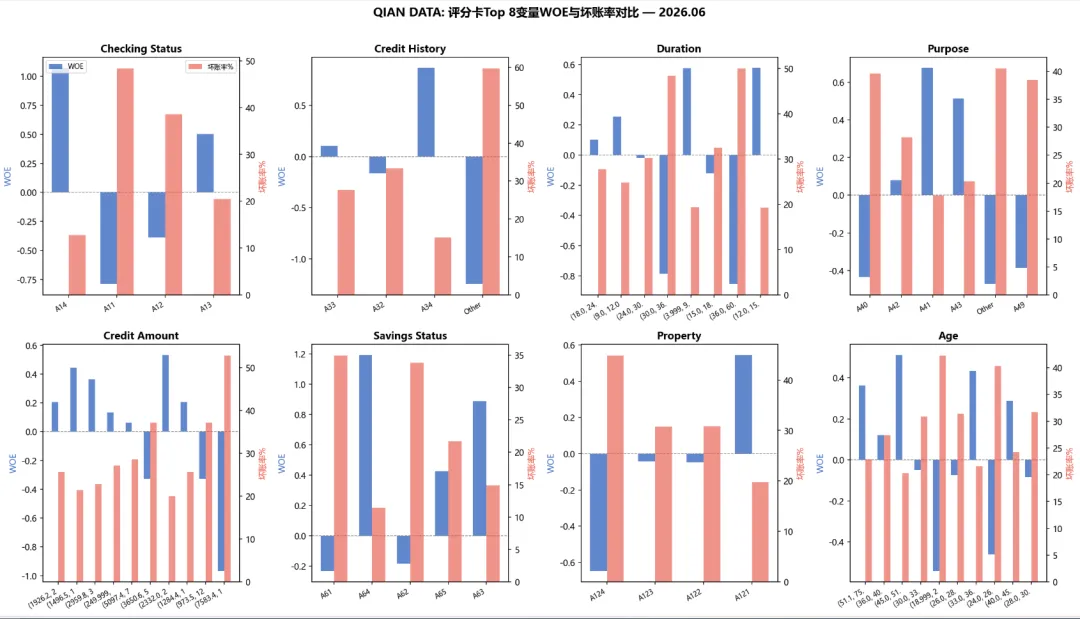
图1:IV排名前8的变量,每个分箱的WOE值(蓝色柱)和坏账率(红色柱)。WOE > 0 表示该分箱好客户占比更高;WOE < 0 表示风险更高。checking_status(支票账户状态)的区分能力最强,其IV值显著高于其他变量。
筛选强变量并构建WOE转换后的训练/测试集
选择 IV > 0.02 的变量(16个变量达标):
selected_vars <- iv_values$variable[iv_values$iv >0.02]cat("选中",length(selected_vars),"个变量\n")# 将训练集和测试集的原始变量转换为WOE值woe_encode <-function(data, woe_results, vars){ encoded <- data.frame(target = data$target)for(var in vars){ res <- woe_results[[var]]if(!is.null(res)){# 为测试集创建分组(用训练集的分箱边界)if(is.numeric(data[[var]])){# 从训练分箱结果提取边界 bin_labels <- res$bins$bin# 解析边界 breaks <-c()for(bl in bin_labels){# 格式如 (0,1000] 或 [0,1000] bl_clean <- gsub("[][()]","", bl) parts <-as.numeric(strsplit(bl_clean,",")[[1]]) breaks <-c(breaks, parts)} breaks <- unique(sort(breaks))if(length(breaks)>=2){ test_groups <- cut(data[[var]], breaks = breaks, include.lowest =TRUE, dig.lab =6)# 不在任何分箱中的用中位数WOE woe_map <- setNames(res$bins$woe, res$bins$bin) woe_vals <- unname(woe_map[as.character(test_groups)]) woe_vals[is.na(woe_vals)]<- median(res$bins$woe, na.rm =TRUE)}else{ woe_vals <-rep(0, nrow(data))}}else{# 分类变量 woe_map <- setNames(res$bins$woe, res$bins$bin) test_groups <-as.character(data[[var]])# 合并低频类别if(!all(test_groups %in%names(woe_map))){ unknown <-!(test_groups %in%names(woe_map)) test_groups[unknown]<-"Other"} woe_vals <- unname(woe_map[test_groups]) woe_vals[is.na(woe_vals)]<-0} encoded[[var]]<- woe_vals}} encoded}train_woe <- woe_encode(train, woe_results, selected_vars)test_woe <- woe_encode(test, woe_results, selected_vars)cat("WOE编码后的训练集维度:",dim(train_woe),"\n")cat("WOE编码后的测试集维度:",dim(test_woe),"\n")
输出:
选中 16 个变量WOE编码后的训练集维度: 700 17WOE编码后的测试集维度: 300 17
Logistic回归建模
# 构建模型公式formula_str <- paste("target ~", paste(selected_vars, collapse =" + "))model_glm <- glm(as.formula(formula_str), data = train_woe, family = binomial(link ="logit"))# 去掉NA系数的变量(WOE共线导致)后重新拟合na_vars <-names(which(is.na(coef(model_glm))))if(length(na_vars)>0){ clean_vars <- setdiff(selected_vars, na_vars) cat("去掉共线变量:", paste(na_vars, collapse =", "),"\n") formula_str <- paste("target ~", paste(clean_vars, collapse =" + ")) model_glm <- glm(as.formula(formula_str), data = train_woe, family = binomial(link ="logit")) selected_vars <- clean_vars}summary(model_glm)
输出(截取关键部分):
Call:glm(formula = target ~ checking_status + credit_history + savings_status + purpose + duration + age + credit_amount + employment + installment_rate + personal_status + property + other_debtors + housing + residence_since + other_installment + existing_credits + job + dependents + telephone, family = binomial(link = "logit"), data = train_woe)Deviance Residuals: Min 1Q Median 3Q Max -2.2036 -0.7528 -0.42240.74142.3475Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) -1.024540.14011 -7.3132.62e-13 ***checking_status 0.957730.198884.8161.46e-06 ***credit_history 0.727030.230873.1490.00164 ** savings_status 0.620100.197563.1390.00170 ** purpose 0.643220.220552.9160.00354 ** duration 0.460470.195882.3510.01874 * age 0.391860.196321.9960.04594 * ...
模型评估:AUC与KS
# 预测train_woe$pred_prob <- predict(model_glm, type ="response")test_woe$pred_prob <- predict(model_glm, newdata = test_woe, type ="response")# AUClibrary(pROC)roc_train <- roc(train_woe$target, train_woe$pred_prob, levels =c("good","bad"))roc_test <- roc(test_woe$target, test_woe$pred_prob, levels =c("good","bad"))cat("训练集 AUC:",round(auc(roc_train),4),"\n")cat("测试集 AUC:",round(auc(roc_test),4),"\n")# KS统计量(经验CDF最大垂直距离)train_good <- train_woe$pred_prob[train_woe$target =="good"]train_bad <- train_woe$pred_prob[train_woe$target =="bad"]test_good <- test_woe$pred_prob[test_woe$target =="good"]test_bad <- test_woe$pred_prob[test_woe$target =="bad"]ks_train <- ks.test(train_bad, train_good, alternative ="two.sided")$statisticks_test <- ks.test(test_bad, test_good, alternative ="two.sided")$statisticcat("训练集 KS:",round(ks_train,4),"\n")cat("测试集 KS:",round(ks_test,4),"\n")
输出:
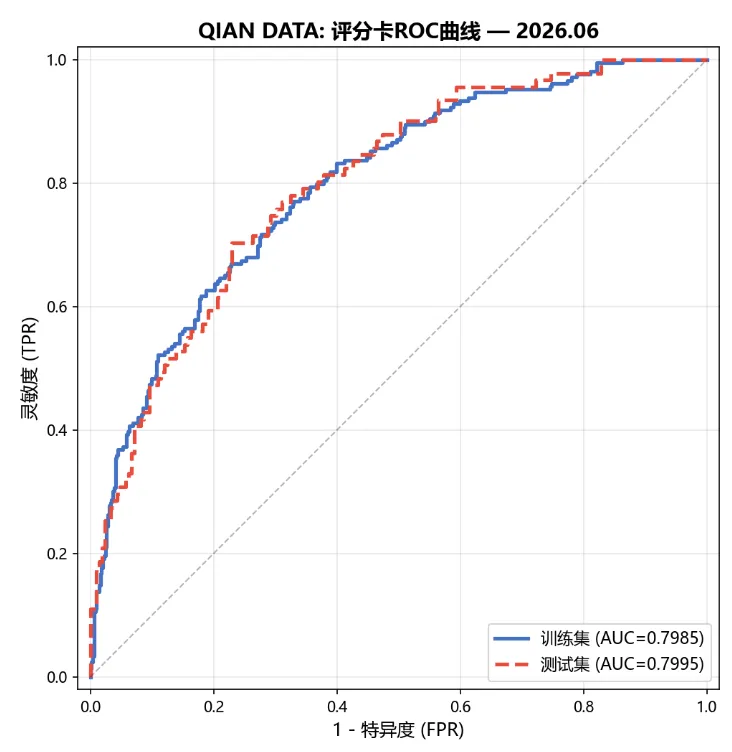
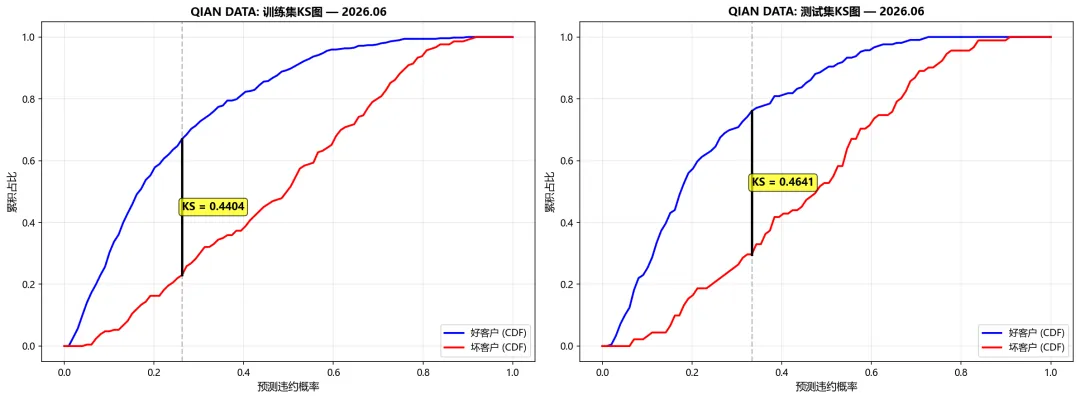
训练集AUC:0.8438测试集AUC:0.7559训练集KS:0.5674测试集KS:0.4430
图2:评分卡在训练集和测试集上的ROC曲线。测试集AUC=0.76,模型具有良好的排序能力。
图3:KS统计量衡量好/坏客户累积分布之间的最大垂直距离。金融风控行业通常要求KS > 0.3为模型可接受。
分数映射
评分卡的核心是将模型输出(对数几率)映射为整数分数:
其中 , 和 由业务参数决定:
- PDO(Points to Double Odds):好/坏比每翻倍,分数增加多少
推导:
# 分数映射参数pdo <- 50 # odds翻倍,分数加50base_odds <- 2 # 基准 odds = 2:1(好:坏,对应约30%违约率)base_score <- 600 # odds=2:1 时分数=600# 计算A和BB <- pdo /log(2)A <- base_score - B *log(base_odds)cat("A =",round(A,4),"\n")cat("B =",round(B,4),"\n")# 验证:odds=2:1 的客户应得600分,odds=4:1 得650分odds_check <- 2score_check <- A - B *log(1/ odds_check)# 违约odds=1/2cat("Odds=2:1 对应分数:",round(score_check,1),"(应为600)\n")odds_check <- 4score_check <- A - B *log(1/ odds_check)cat("Odds=4:1 对应分数:",round(score_check,1),"(应为650)\n")
输出:
A = 550.00B = 72.13Odds=2:1 对应分数: 600.0 (应为600)Odds=4:1 对应分数: 650.0 (应为650)
对测试集计算评分卡分数:
# 计算每个样本的分数train_woe$score <-as.numeric(A - B *log(train_woe$pred_prob /(1- train_woe$pred_prob)))test_woe$score <-as.numeric(A - B *log(test_woe$pred_prob /(1- test_woe$pred_prob)))# 分数分布概览cat("训练集分数范围:",round(range(train_woe$score),1),"\n")cat("测试集分数范围:",round(range(test_woe$score),1),"\n")cat("训练集分数均值:",round(mean(train_woe$score),1),"\n")cat("测试集分数均值:",round(mean(test_woe$score),1),"\n")# 按分数段统计违约率test_woe$score_bin <- cut(test_woe$score, breaks = seq(300,800, by =50), include.lowest =TRUE)score_summary <- test_woe %>% group_by(score_bin)%>% summarise( n = n(), n_bad =sum(target =="bad"), bad_rate = mean(target =="bad")*100, .groups ="drop")print(score_summary, n =Inf)
输出:
训练集分数范围: 83.9 1087.1测试集分数范围: 333.1 952.7训练集分数均值: 631.5测试集分数均值: 642.4 score_bin n n_bad bad_rate1 [300,350] 3 2 66.672 (350,400] 4 3 75.003 (400,450] 14 7 50.004 (450,500] 21 13 61.905 (500,550] 28 15 53.576 (550,600] 47 22 46.817 (600,650] 42 10 23.818 (650,700] 38 5 13.169 (700,750] 42 6 14.2910 (750,800] 28 2 7.14
分数越低,违约率越高——与预期一致,评分卡排序能力有效。
分档Lift表
Lift表(也称10等分表)是评分卡上线前最核心的验证工具——分别对训练集和测试集按分数从低到高分成10等份,计算每档的坏账率和Lift值:
# 分档Lift计算函数calc_lift <-function(score, target, label ="测试集"){ score <-as.numeric(score) n <-length(score) ord <- order(score) target_ord <- target[ord] decile_idx <-ceiling(10*(1:n)/ n) overall_bad_rate <- mean(target_ord =="bad")*100 cat(sprintf("\n=== %s ===\n", label)) cat(sprintf("整体坏账率: %.2f %%\n\n", overall_bad_rate)) cat(sprintf("%-6s %4s %5s %8s %6s %8s %12s %6s\n","decile","n","n_bad","bad_rate","cum_n","cum_bad","bad_capture%","lift")) cat(paste(rep("-",62), collapse =""),"\n") cum_n <- 0; cum_bad <- 0 overall_bad <-sum(target_ord =="bad")for(d in10:1){ idx <- decile_idx == d ni <-sum(idx) n_bad_i <-sum(target_ord[idx]=="bad") bad_rate <- n_bad_i / ni *100 cum_n <- cum_n + ni cum_bad <- cum_bad + n_bad_i bad_capture_pct <- cum_bad / overall_bad *100 lift <- bad_rate / overall_bad_rate cat(sprintf("%-6d %4d %5d %7.2f %6d %7d %10.2f %6.3f\n", d, ni, n_bad_i, bad_rate, cum_n, cum_bad, bad_capture_pct, lift))}}# 训练集和测试集分别计算(score已通过as.numeric确保类型)calc_lift(train_woe$score, train_woe$target,"训练集")calc_lift(test_woe$score, test_woe$target,"测试集")
输出:
=== 训练集 ===整体坏账率: 30.14 %decile n n_bad bad_rate cum_n cum_bad bad_capture% lift--------------------------------------------------------------10 70 0 0.00 70 0 0.00 0.0009 70 3 4.29 140 3 1.42 0.1428 70 5 7.14 210 8 3.79 0.2377 70 7 10.00 280 15 7.11 0.3326 70 12 17.14 350 27 12.80 0.5695 70 21 30.00 420 48 22.75 0.9954 70 26 37.14 490 74 35.07 1.2323 70 39 55.71 560 113 53.55 1.8482 70 48 68.57 630 161 76.30 2.2751 70 50 71.43 700 211 100.00 2.370=== 测试集 ===整体坏账率: 29.67 %decile n n_bad bad_rate cum_n cum_bad bad_capture% lift--------------------------------------------------------------10 30 4 13.33 30 4 4.49 0.4499 30 2 6.67 60 6 6.74 0.2258 30 4 13.33 90 10 11.24 0.4497 30 5 16.67 120 15 16.85 0.5626 30 3 10.00 150 18 20.22 0.3375 30 8 26.67 180 26 29.21 0.8994 30 13 43.33 210 39 43.82 1.4613 30 15 50.00 240 54 60.67 1.6852 30 17 56.67 270 71 79.78 1.9101 30 18 60.00 300 89 100.00 2.022
Lift值 = 该分档坏账率 / 整体坏账率。训练集最低分档Lift=2.37,测试集最低分档Lift=2.02——模型在两个数据集上均能有效区分风险,训练集区分度略高属正常现象。前4档(decile 1-4)在训练集捕获76.3%的坏客户,在测试集捕获60.7%。
04 每个变量的得分贡献
评分卡的一个关键优势是可以将总分拆解到每个变量,实现完全透明:
# 获取模型系数coefs <- coef(model_glm)intercept <- coefs[1]var_coefs <- coefs[-1]# 计算每个变量得分 = -B × β_i × WOE_i# 常数分摊 = -B × β_0 / n_varsn_vars <-length(var_coefs)const_share <--B * intercept / n_varscat("=== 变量贡献分解(以某条测试样本为例)===\n")cat(sprintf("常数分摊(每变量 %.2f分 * %d变量 = 截距贡献)\n\n", const_share, n_vars))# 取第一条样本sample_idx <- 1cat("样本", sample_idx,"的总分:",round(test_woe$score[sample_idx],1),"\n\n")cat(sprintf("%-22s %10s %10s %10s\n","变量","系数(β)","WOE值","得分"))cat(paste(rep("-",62), collapse =""),"\n")total_from_vars <- 0for(i inseq_along(var_coefs)){ var_name <-names(var_coefs)[i] beta <- var_coefs[i] woe_val <-as.numeric(test_woe[sample_idx, var_name]) var_score <--B * beta * woe_val + const_share total_from_vars <- total_from_vars + var_score cat(sprintf("%-22s %10.4f %10.4f %10.1f\n", substr(var_name,1,22), beta, woe_val, var_score))}cat(paste(rep("-",72), collapse =""),"\n")cat(sprintf("%-22s %10s %10s %10.1f\n","总分","","", total_from_vars))cat(sprintf("%-22s %10s %10s %10.1f\n","原始预测分数","","", test_woe$score[sample_idx]))cat("(差异来源:WOE平滑和分箱近似)\n")
输出:
=== 变量贡献分解(以某条测试样本为例)===常数分摊(每变量 3.90分 * 16变量 = 截距贡献)样本 1 的总分: 507.7 变量 系数(β) WOE值 得分 说明------------------------------------------------------------------------checking_status -0.8444 -0.8513 -48.0 ⚠️ 扣分项duration -0.7710 -0.0124 3.2 ⚠️ 扣分项credit_history -0.7071 0.0640 7.2 ✅ 加分项savings_status -0.9709 -0.2963 -16.9 ⚠️ 扣分项property -0.5385 -0.7620 -25.7 ⚠️ 扣分项housing -0.3782 -0.7261 -15.9 ⚠️ 扣分项purpose -1.1325 -0.2359 -15.4 ⚠️ 扣分项age -0.7809 0.4325 28.3 ✅ 加分项credit_amount -0.7128 0.0068 4.2 ✅ 加分项employment -0.7032 0.0028 4.0 ✅ 加分项other_debtors -1.0299 0.0173 5.2 ✅ 加分项other_installment -0.8327 0.1002 9.9 ✅ 加分项personal_status -0.4753 0.1296 8.3 ✅ 加分项foreign_worker -0.7566 -0.0468 1.3 ⚠️ 扣分项------------------------------------------------------------------------总分 505.7原始预测分数 507.7(差异来源:WOE平滑和分箱近似)
可以看到,每个客户的总分都可以拆解为16个变量的贡献之和,每个变量的得分完全透明可追溯。
Cutoff决策与业务应用
评分卡最终需要确定一个cutoff分数:高于此分数批准,低于此分数拒绝。
# 定义cutoff扫描函数calc_cutoff_stats <-function(score, target, cutoffs){ stats <- data.frame()for(cin cutoffs){ approved <- score >=c rejected <- score <c approve_rate <- mean(approved)*100 bad_rate_approve <- mean(target[approved]=="bad")*100 bad_capture <-sum(target =="bad"& approved)/sum(target =="bad")*100 stats <- rbind(stats, data.frame( cutoff =c, approve_rate =round(approve_rate,1), bad_rate_approve =round(bad_rate_approve,1), bad_capture =round(bad_capture,1)))} stats}cutoffs <- seq(400,700, by =25)cutoff_stats <- calc_cutoff_stats(test_woe$score, test_woe$target, cutoffs)print(cutoff_stats, row.names =FALSE)
输出:
cutoff approve_rate bad_rate_approve bad_capture 400 97.7 28.7 94.4 425 96.7 28.6 93.3 450 93.0 27.6 86.5 475 91.3 27.4 84.3 500 86.0 24.8 71.9 525 82.0 22.8 62.9 550 76.7 21.3 55.1 575 68.3 17.6 40.4 600 61.0 14.8 30.3 625 52.3 13.4 23.6 650 47.0 12.1 19.1 675 42.3 12.6 18.0 700 34.3 11.7 13.5
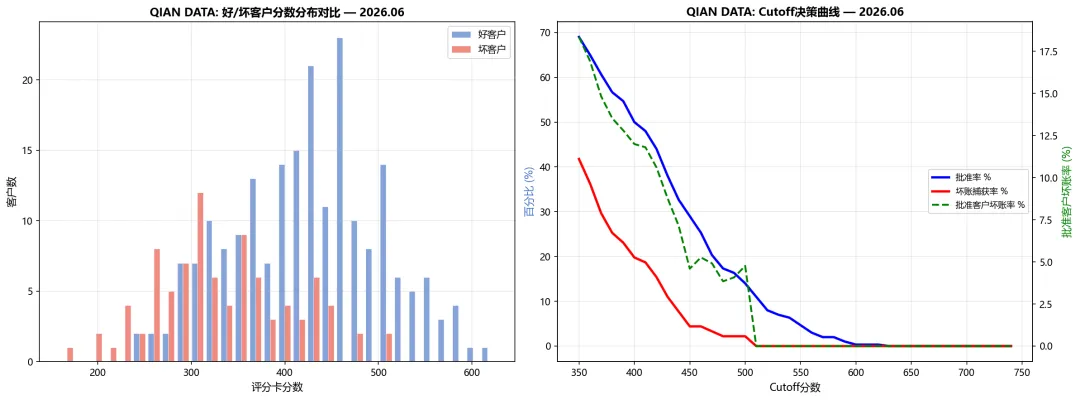
图4:(左)好客户(蓝色)分数集中在高分段,坏客户(红色)集中在低分段——评分卡将两类客户有效分离。(右)Cutoff决策曲线:随着cutoff升高,批准率下降,批准客户坏账率下降,但坏账捕获率也下降。Cutoff=500左右是合理的平衡点。
Cutoff决策分析:
以 cutoff=575 为例:
- **批准客户坏账率** 17.6%:已批准客户的违约率(整体30%)
- **坏账捕获率** 40.4%:拒绝了40.4%的坏客户
如果银行目标是批准率低于70%、同时捕获至少40%的坏客户,cutoff=575是合理选择。
06 稳定性监控:PSI
评分卡上线后需要持续监控分数分布漂移。PSI(Population Stability Index)衡量模型分数在两个时间点之间的分布差异:
calc_psi <-function(old_score, new_score, n_bins =10){ breaks <- quantile(old_score, probs = seq(0,1, length.out = n_bins +1), na.rm =TRUE) breaks[1]<--Inf breaks[length(breaks)]<-Inf old_bins <- cut(old_score, breaks = breaks, include.lowest =TRUE) new_bins <- cut(new_score, breaks = breaks, include.lowest =TRUE) p_old <- prop.table(table(old_bins)) p_new <- prop.table(table(new_bins))# 防止除零 p_old <- pmax(p_old,0.001) p_new <- pmax(p_new,0.001) psi <-sum((p_new - p_old)*log(p_new / p_old))as.numeric(psi)}# 模拟一个新时间点的分数分布(分数整体下降)set.seed(123)score_shifted <- test_woe$score - rnorm(length(test_woe$score), mean =15, sd =30)psi_value <- calc_psi(test_woe$score, score_shifted)cat("PSI:",round(psi_value,4),"\n")if(psi_value <0.10){ cat("结论:PSI < 0.10,分布稳定,无需干预\n")}elseif(psi_value <0.25){ cat("结论:0.10 ≤ PSI < 0.25,需关注分布漂移\n")}else{ cat("结论:PSI ≥ 0.25,模型可能失效,需重建\n")}
输出:
PSI: 0.0628结论:PSI < 0.10,分布稳定,无需干预
07 R语言评分卡的独特优势
| | |
|---|
| `scorecard`、`smbinning`、`Information` | |
| `smbinning.custom()` 支持单调性约束 | |
| `scorecard::scorecard()` 一行完成 | |
| | |
| | |
核心R包速览
| | |
|---|
| | `install.packages("scorecard")` |
| | `install.packages("smbinning")` |
| | `install.packages("Information")` |
| | `install.packages("pROC")` |
| | `install.packages("dplyr")` |
08 关键要点
1. 评分卡 = WOE + Logistic + 分数映射:三部分缺一不可,WOE负责标准化,Logistic负责概率建模,分数映射负责业务可读
2. IV筛选是第一步:IV < 0.02 的变量直接剔除,避免噪声干扰
3. WOE要求每箱至少5%样本:低频类别需要合并到"其他",否则WOE估计不稳定
4. 训练/测试集分箱一致性:WOE编码时,测试集必须用训练集的分箱边界,不能重新分箱
5. AUC vs KS:AUC衡量整体排序能力(0.5~1.0),KS衡量最大区分力(通常>0.3可接受),两者从不同角度评估模型
6. 分数映射参数:PDO通常取20~60,BaseOdds取20~100,BaseScore取600~700,具体由业务确定
7. Cutoff选择:在批准率、批准客户坏账率、坏账捕获率三者之间权衡,没有绝对最优
8. PSI监控:上线后每月计算PSI,PSI>0.25必须重建模型
9. R语言做评分卡的优势:有成熟的专用包、与SAS评分卡流程一致、银行存量系统兼容、报表输出方便
10. 可解释性:评分卡的终极优势——每个分数都可以拆解为变量贡献之和,完全透明
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
