1.1 一般性理论之生日问题【概率论Python实践】
- 2026-06-14 23:43:07
1.1 一般性理论之生日问题【概率论Python实践】
1.1.1 陈述问题
假设客人的出生日期都是相互独立的,并且每个人都等可能的出生在一年中的任何一天(2月29日除外),那么房间里有多少人才能保证其中至少两个人的生日在同一天的概率不小于50%?
1.1.2 解决问题
最常用的方法是考察一些极端情况,并试着找出与答案有关的信息。对我们来说最坏的情况是所有人的生日都不相同我们假设一年只有365天当有第366个人出席就一定会出现“至少两个人生日在同一天”的情况,这也是著名的鸽巢原理。另一种极端的情况是,只有一个人出席聚会,那么显然答案是在2和365中的某个数。再更深入的思考一下,如果其中有183个人的生日互不相同,那么对于第184个人来说,他与前面183个人生日相同的概率至少为50%,只需短短几步就能大大缩小答案范围,但2~184仍是个相当大的范围,但答案会更接近2一些。
狄利克雷鸽巢原理:设是一组集合,并且中至少有个元素,那么至少有一个包含了不少于两个元素。
下面再看一个例子,通过巧妙的证明,进一步理解该原理的用法。
证明:设是的任意一个包含个元素的子集,那么S中至少包含两个元素a和b,并且a可以整除b。
解:我们可以把每一个元素 写作,其中s_0是奇数,集合有个奇数,集合中有个元素,根据鸽巢原理可知,S中至少有两个元素a,b具有相同奇数的部分。设,并把它们记作和,因为,所以,从而有,证明a可以整除b。
诀窍在于要意识到把数写成写成2的方幂与一个奇数的乘积,进而通过鸽巢原理推出一定有两个奇数时相等的。
在概率论中,计算对立事件(A不发生的概率)的概率有时比直接计算事件A概率容易的多,A和非A是互斥事件,两者概率之和一定等于1。
不妨设一共有n个人出席聚会,,对第一个人来说“所有人生日互不相同”的概率为1,我们把1改成365/365。第二个人进入时,为保证两人生日不在同一天,此时“所有人生日互不相同”的概率为。同理,第三,...第n个人进入时,“所有人生日互不相同”的概率为。使用连乘符号或者阶乘符号,这个结果可以改写为:
由于上述乘积是“n个人中,任意两个人生日互不相同”的概率,想解决该问题我们必须找到能使这个乘积小于1/2的最小的n,就意味着“至少两个人的生日在同一天的概率不小于50%”。
#本文的目的之一是强调编程能力,因此这里给出一个简单的Python程序import numpy as npimport matplotlib.pyplot as pltimport matplotlibmatplotlib.rc('font', family='YouYuan')def collision_probability(n, days=365): if n <= 0: return 0.0 if n > days: return 1.0 p_distinct = np.prod([(days - k) / days for k in range(n)]) return 1.0 - p_distinctdef plot_birthday_probability(max_n=50, days=365): xs = np.arange(1, max_n + 1) ys = [collision_probability(n, days) for n in xs] plt.figure(figsize=(10, 6)) plt.plot(xs, ys, marker='o', markersize=4, label='至少两人同生日概率') plt.axhline(0.5, color='red', linestyle='--', label='50%概率线') plt.xlabel('人数 n') plt.ylabel('概率') plt.title('生日问题:至少两个人的生日在同一天的概率不小于50%') plt.ylim(0, 1.05) plt.xlim(1, max_n) plt.legend() plt.show()if __name__ == '__main__': plot_birthday_probability(max_n=100)
1.1.3 对问题和答案的推广:效率
虽然我们解决了生日问题,但从实用性角度来看,这个结果并不令人满意。在当代数学中,只知道求某个量的算法是不够的,我们想要的更多!我们希望得到高效且便于使用的算法,最好能得到一个不错的闭形解,这样就能看出答案是如何随参数的改变而发生变化的,就这一点而言,前面的答案相当失败。
这里将证明如何用一些简单的代数知识来推导下面这个著名的表达式:如果出席聚会的每个人都等可能的出生在D天中的任何一天那么大概需要个人才使得“至少两个人生日在同一天”的概率达到50%。
下面给出需要用到的微积分知识:
1. (泰勒级数展开,并去掉误差项) 2.
首先把改写成,会发现是(所有人生日都不相同的概率):
公式左右取对数:
假定n远小于365,所以将公式右侧泰勒级数展开,并去掉误差项后就得到:
利用第二条微积分知识,可以对这里进行求和,得到:
由于我们想要得到的概率是50%,所以令,即:
又因为,于是:
沿上述思路去论证,若一年有D天,那么问题的答案就是
在生日问题中,我们还可以用一个更好的估计 代替 ,那么问题的答案就是
通过几次简单的近似计算,我们得到了与23非常接近的结果22.9944,完全回避了大量的乘积计算!
import mathimport numpy as npimport matplotlib.pyplot as pltdef minimal_n_for_D(D, threshold=0.5): if D <= 1: return 2 logP = 0.0 # log of probability that all birthdays are distinct # iterate n = 1,2,... for n in range(1, int(D) + 2): k = n - 1 if k >= D: return n # pigeonhole -> certainty logP += math.log(1.0 - (k / D)) p_collision = 1.0 - math.exp(logP) if p_collision >= threshold: return n return int(D) + 1def estimate_n(D): return math.ceil(math.sqrt(D * 2.0 * math.log(2)))def refined_estimate_n(D): # 加上 0.5 的改进近似(教材中常见修正) return math.ceil(0.5 + math.sqrt(D * 2.0 * math.log(2)))def compute_for_D_values(D_values): true_ns = [] est_ns = [] ref_ns = [] rel_err_est = [] for D in D_values: n_true = minimal_n_for_D(D) n_est = estimate_n(D) n_ref = refined_estimate_n(D) true_ns.append(n_true) est_ns.append(n_est) ref_ns.append(n_ref) rel_err_est.append((n_est - n_true) / n_true) return np.array(true_ns), np.array(est_ns), np.array(ref_ns), np.array(rel_err_est)def plot_results(D_values, true_ns, est_ns, ref_ns, save_path="birthday_est_vs_true.png"): plt.figure(figsize=(10,6)) plt.plot(D_values, true_ns, marker='o', markersize=3, label='真实最小 n (概率 ≥ 0.5)') plt.plot(D_values, est_ns, marker='x', markersize=3, linestyle='--', label='估算') plt.plot(D_values, ref_ns, marker='s', markersize=3, linestyle=':', label='改进估算') plt.xlabel('一年天数 D') plt.ylabel('人数 n') plt.title('生日问题:真实与估算随一年天数D的变化') plt.grid(True, which='both', ls='--', alpha=0.4) plt.legend() plt.tight_layout() plt.savefig(save_path, dpi=150) plt.show()if __name__ == "__main__": # 取对数间隔的 D 值(从 10 到 1e6),去重并排序 D_values = np.unique(np.round(np.logspace(math.log10(10), 6, num=200)).astype(int)) true_ns, est_ns, ref_ns, rel_err_est = compute_for_D_values(D_values) # 简要统计:估算的最大/平均相对误差 max_rel_err = np.max(np.abs(rel_err_est)) mean_rel_err = np.mean(rel_err_est) print(f"采样点数量: {len(D_values)}") print(f"估算 (√(2 ln2 · D)) 相对误差: 平均 {mean_rel_err:.4f}, 最大 {max_rel_err:.4f}") # 绘图并保存 plot_results(D_values, true_ns, est_ns, ref_ns) # # 可选:把结果导出为 CSV 供进一步分析 # try: # import csv # out_csv = "birthday_n_vs_D.csv" # with open(out_csv, "w", newline="", encoding="utf-8") as f: # writer = csv.writer(f) # writer.writerow(["D", "n_true", "n_est", "n_refined", "rel_err_est"]) # for D, t, e, r, err in zip(D_values, true_ns, est_ns, ref_ns, rel_err_est): # writer.writerow([D, t, e, r, err]) # print(f"结果已保存: {out_csv},图像: birthday_est_vs_true.png") # except Exception as ex: # print("导出 CSV 失败:", ex)采样点数量: 198相对误差: 平均 -0.0121, 最大 0.2000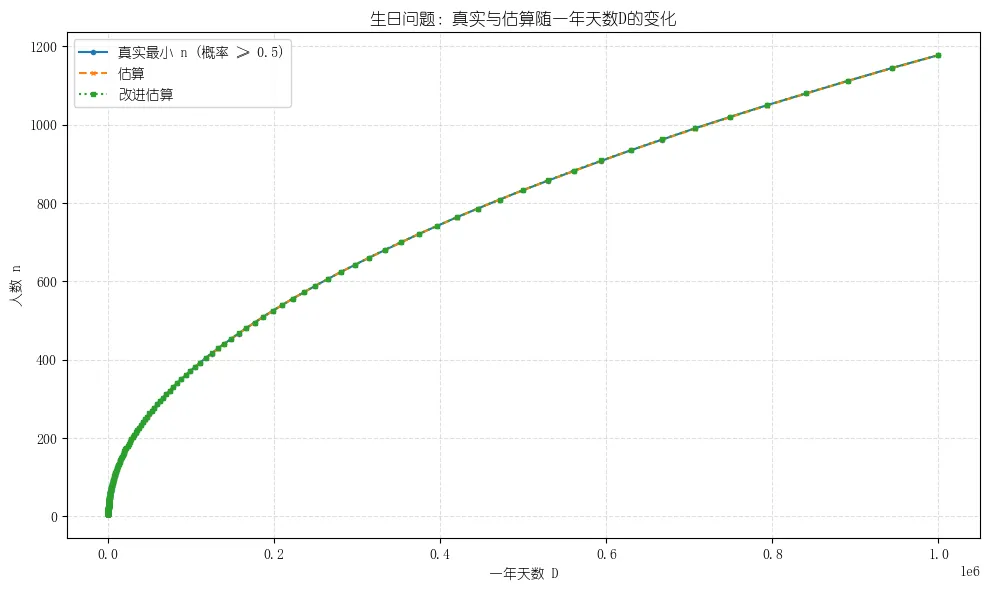

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 第二篇:Python OCR表格识别|从95%翻车到99%精准,批量提取图片表格数据
- 基于Python高校学生选课系统的设计与实现
- 出发点机器人编程|Python入门攻略!
- 一周Python期末速成|大学生救急版
- Cython:Python 加速工具
- 【程序人生】Python批量添加图片水印
- ABP Studio 现已支持 Linux!
- Block 捐赠给 Linux 基金会的 AI Agent,正在重新定义"通用助手"
- 抛弃 X11 架构枷锁,Linux 桌面图形栈集中落地底层修复——Firefox、Mesa和Wayland密集更新
- Linux声音问题攻略(上)——PulseAudio/PipeWire怎么回事
