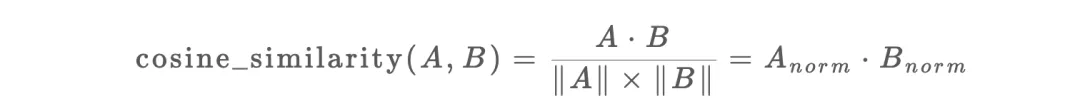由于借助 AI 工具学习编程已经变得非常容易了,因此之后的课程就不再默认进行视频讲解了,如果特别需要视频讲解也可以联系李老师预约讲解~讲义材料学习过程中遇到的问题也可以及时与李老师联系。
购买 RStata 名师讲堂会员即可参加该课程啦(之前的和未来的都可以参加)!
价格:2800/年 或者 4800/长期
购买会员可以从这里下单:https://rstata.duanshu.com/#/card/list/
名师讲堂会员权益:
- 参加平台上的其他 R 语言和 Stata 的课程;
- 以会员折扣价购买我们分享的数据资料(10 元/份);
* 如果发票可添加小编微信 r_stata2 (RStata 李老师)开具。如需数据资料,购买后可添加小编微信免费领取数据折扣卡。
更多关于 RStata 会员的更多信息可添加微信号 r_stata2 咨询:

课程主页(点击文末的阅读原文即可跳转):https://rstata.duanshu.com/#/brief/course/89d622f54a4d4229b77b157b52f1f72c
⚠️注意:如果不是走投无路了,非常不建议使用这种方法,运算量过大。
引言
知识溢出(Knowledge Spillover)是区域创新研究的核心概念,指一个地区的知识活动对其他地区创新产出产生的外部性影响。准确测度城市间的知识溢出,对于理解区域创新网络、制定创新政策具有重要意义。
传统的知识溢出测度方法主要依赖地理距离、专利申请引用等间接指标,但这些方法存在明显局限:
随着文本挖掘技术的发展,专利摘要文本相似度为直接测度知识溢出提供了新的可能。本文档介绍如何使用 TF-IDF(Term Frequency-Inverse Document Frequency) 方法计算专利文本相似度,并构建城市间知识溢出指标。
1. TF-IDF 的原理
为什么 TF-IDF 适合专利文本相似度计算?
2.1 自动降噪:过滤无意义高频词
专利摘要中包含大量通用表述(如"本发明涉及..."、"其特征在于..."),这些词在几乎所有专利中都会出现。TF-IDF 通过 IDF 权重自动降低这些"停用词"的贡献,突出真正有区分度的技术术语。
对比:单纯的词频(TF)或二进制向量(词是否出现)会将"的"和"深度学习"同等对待,显然不合理。
2.2 区分通用技术与专有技术
- 通用技术词(如"控制器"、"系统"):IDF 值低,对相似度贡献小
- 专有技术词(如"卷积神经网络"、"石墨烯"):IDF 值高,对相似度贡献大
这种加权方式恰好符合专利相似度判断的需求:关注技术内容的相似性,而非表述格式的相似性。
2.3 稀疏性友好:适合大规模计算
TF-IDF 向量通常是高维稀疏向量(数万维特征,但每个专利只有数百个非零值)。这种稀疏性使得:
- 存储效率高(可用
scipy.sparse 存储)
2.4 余弦相似度的自然适配
TF-IDF 向量经过 L2 归一化(每个向量的欧氏长度变为1)后,两个向量的点积就等于它们的余弦相似度:
这一性质使得相似度计算可以转化为高效的矩阵乘法操作,避免了逐一计算余弦相似度的高昂成本。
3. 与其他方法的对比
| | | |
|---|
| TF-IDF + 余弦相似度 | | | |
| Word2Vec/Doc2Vec | | | |
| BERT/Transformer | | | |
结论:对于数百万级专利对的知识溢出计算,TF-IDF 是在计算效率和准确度之间的最佳平衡点。
4. 论文中的谷歌专利向量方法
4.1 什么是谷歌专利文本向量?
谷歌专利文本向量(Google Patent Vectors) 是由 Google Patents 团队基于海量专利全文文本,利用机器学习模型生成的高维语义向量。
技术特点:
- 使用深度学习模型捕捉语义相似度(如同义词、上下位关系)
- 向量维度高(通常 512 或 1024 维),语义表示能力强
4.2 为什么原论文使用谷歌专利向量?
王慧扬等(2026)的论文选择谷歌专利向量,主要基于以下考虑:
- 专利摘要信息有限:与专利代理人访谈发现,专利摘要传达的技术信息十分有限,无法全面反映技术方案
- 全文文本获取困难:逐一获取数百万件专利的全文文本不具有可行性
- 模型训练成本高:生成高质量专利文本向量需要基于数以百万计专利语料训练的机器学习模型,对资金和技术要求高
- 谷歌已提供公开数据:Google Patents 团队已经完成了上述工作,并将专利文本向量公开供科学研究使用
- 已有研究验证有效性:Higham 等(2021)、De Rassenfosse 和 Palangkaraya(2023)等研究已使用谷歌专利向量并验证了其有效性
4.3 为什么本实现没有使用谷歌专利向量?
尽管谷歌专利向量在语义理解上具有优势,但本实现选择 TF-IDF 方法,主要基于以下原因:
| | | |
|---|
| 数据可得性 | | | |
| 数据覆盖范围 | | | |
| 方法透明度 | | | |
| 计算资源需求 | | | |
| 中文处理适应性 | | | |
| 方法简洁性 | | | |
核心原因总结:
- 数据匹配挑战:将中国专利号(如 CN107519921B)与 Google Patents 的专利 ID 进行匹配需要额外的工作,且覆盖率不确定
- 数据获取成本:谷歌专利向量数据量庞大(数 GB),下载和存储成本高
- 中国专利适应性:谷歌专利向量主要基于英文专利训练,对中文专利的语义表示效果有待验证
- 方法可复现性:TF-IDF 是完全自包含的统计方法,不依赖任何外部数据或专有模型,更利于学术研究的开放性和复现性
- 计算效率满足需求:对于城市间知识溢出这种大规模计算任务,TF-IDF 的效率优势更为明显
4.4 两种方法的结果对比
如果使用谷歌专利向量,相似度计算代码将类似:
# 假设已从 Google Patents API 获取向量patent_vectors = pd.read_csv("google_patent_vectors.csv")from sklearn.metrics.pairwise import cosine_similaritysimilarity = cosine_similarity([patent_vectors.iloc[i].values], [patent_vectors.iloc[j].values])[0][0]similarity = float(dtm_norm[i, :] @ dtm_norm[j, :].T)实证研究建议:
- 初步筛查/大规模计算:使用 TF-IDF(本实现方法)
- 精细分析/小样本研究:可尝试获取谷歌专利向量进行对比验证
- 方法创新方向:训练基于中文专利全文的专用词向量模型
注意:原论文使用谷歌专利向量是为了验证方法的有效性。如果研究者有条件获取中国专利的谷歌专利向量,可以进行对比分析,进一步增强研究的可信度。
指标来源与定义
本讲义的指标构建方法参考论文:
《创新知识溢出的测度与检验——基于机器学习生成专利文本相似度的证据》
城市间知识溢出指标定义
时间条件的经济学含义
论文特别强调:来源专利的公开时间必须早于接收专利的申请时间。
这一条件保证了知识溢出的时间逻辑:
- 创新知识先在特定城市产生并公开(publish_year)
- 其他城市的创新主体学习这些知识后,申请自己的专利(apply_year)
代码实现:
sp = df_text[(df_text["publish_year"] >= t - 3) & (df_text["publish_year"] <= t - 1)]tp = df_text[df_text["apply_year"] == t]
使用 reticulate 创建与管理 Python 虚拟环境
在 R 中通过 reticulate 包来调用 Python,最好的实践是为项目创建一个专属的 Python 虚拟环境,将所需依赖隔离到独立空间,避免与系统 Python(如 Anaconda)发生版本冲突。
重要说明(避免"已初始化"报错):reticulate 在 R 会话中只能绑定一次 Python——一旦某个 {python} 代码块运行,Python 解释器就被锁定,之后再调用 use_virtualenv() 会报错。因此,虚拟环境的激活必须在所有 {python} 代码块之前完成。本文档的解决方案是在 setup chunk 中通过 Sys.setenv(RETICULATE_PYTHON = ...) 提前锁定 Python 路径。
安装 reticulate(仅首次)
options(repos = c(CRAN = "https://mirrors.tuna.tsinghua.edu.cn/CRAN/"))if (!requireNamespace("reticulate", quietly = TRUE)) { install.packages("reticulate") message("reticulate 安装完成!") message("reticulate 已安装,版本:", packageVersion("reticulate"))在虚拟环境中安装 Python 包(仅首次)
本合同所需 Python 包:pandas、numpy、scipy、jieba、pickle(内置)。
py_pkgs <- c("pandas", "numpy", "scipy", "jieba")installed <- py_list_packages(".venv")$packageneed_install <- setdiff(py_pkgs, installed)if (length(need_install) > 0) { virtualenv_install(".venv", packages = need_install) message("已安装缺失的包:", paste(need_install, collapse = ", ")) message("所有 Python 包已就绪,无需安装")验证激活状态
数据准备
本项目的输入数据为 df_text_sim.csv,使用附件中的 数据准备.R 生成。
Python 完整代码实现
以下各节将完整展示使用 Python 计算城市间知识溢出指标的代码,并按照功能模块逐步讲解。所有 Python 代码在 reticulate 管理的虚拟环境中运行。
第0步:加载 Python 包与创建输出文件夹
在开始计算之前,我们需要导入必要的 Python 包,并创建用于保存中间结果的文件夹。
对应 R 代码中的 library(tidyverse) 等加载包的语句,Python 使用 import 语句。
完整代码
os.makedirs("res", exist_ok=True)print("===== 已创建 res 文件夹 =====\n")old_cache_files = ["dtm_norm.pkl", "df_text_idx.pkl"]for f in old_cache_files:首先导入需要的 Python 包:pandas 用于数据清洗,numpy 用于数值计算,scipy.sparse 用于稀疏矩阵计算,pickle 用于序列化中间结果。
接着创建 res/ 文件夹,所有中间结果都会保存在这里(pickle 格式),这样既便于断点续算,也能避免中间文件混乱。
最后,清理工作目录中可能存在的旧缓存文件(dtm_norm.pkl 和 df_text_idx.pkl),这些文件如果是之前计算遗留的,可能会导致错误。
第一步:读取数据
这一步读取预处理好的专利数据文件 df_text_sim.csv(由前面的 R chunk 从 RDS 转换而来)。这个文件应该包含以下字段:专利唯一标识(newipzlid)、申请年份(apply_year)、公开年份(publish_year)、申请人所在城市(city),以及专利摘要(摘要)。
读取后我们简单查看一下数据的维度、列名和前几行,确认数据格式符合预期。
完整代码
# ============================================================================# ============================================================================print("\n===== 第一步:读取 df_text_sim.csv =====")df_text = pd.read_csv("df_text_sim.csv")print(f" 数据:{len(df_text)} 行 × {len(df_text.columns)} 列")print(f" 列名:{', '.join(df_text.columns.tolist())}")使用 pd.read_csv() 读取 CSV 格式的数据文件。读取后打印数据维度和列名,确认数据加载成功,然后显示数据前几行,检查数据内容是否正确。
第二步:TF-IDF 计算与稀疏矩阵构建(含缓存机制)
这一步是整个流程的核心,我们需要完成以下任务:对专利摘要进行分词,计算每个词的 TF-IDF 值,然后构建稀疏矩阵并归一化(这样后续计算余弦相似度就可以通过简单的矩阵乘法实现)。
考虑到 TF-IDF 计算非常耗时,我们设计了缓存机制:计算结果会保存到 res/ 文件夹中(dtm_norm.pkl 和 df_text_idx.pkl)。下次运行时,如果缓存文件存在且有效,就直接加载,跳过重复计算。
完整代码
第三步:断点续算检查
在开始大规模计算之前,我们先检查一下 res/ 文件夹中是否已经存在部分结果。这样可以跳过已完成的部分,从断点继续计算。
这里使用了双维度保存策略:按年份保存(spillover_year_YYYY.pkl)和按来源城市+年份保存(spillover_source_城市_year_YYYY.pkl)。
完整代码
# ============================================================================# 第三步:断点续算 - 检测已完成的任务(双维度)# ============================================================================print("\n===== 第三步:断点续算检查 =====")year_pattern = os.path.join("res", "spillover_year_*.pkl")year_files = sorted(glob.glob(year_pattern)) basename = os.path.basename(f) m = re.search(r"spillover_year_(\d+)\.pkl", basename) years_done.append(int(m.group(1)))print(f" 已完成的年份:{', '.join(map(str, sorted(years_done)))}")source_pattern = os.path.join("res", "spillover_source_*.pkl")source_files = sorted(glob.glob(source_pattern))print(f" 已完成的来源城市文件:{len(source_files)} 个")使用 glob.glob() 列出 res/ 文件夹中匹配特定模式的文件,通过正则表达式匹配按年份保存的文件和按来源城市保存的文件,然后从文件名中提取年份或城市名称,最后打印已完成的任务,让用户了解计算进度。
第四步:主循环 - 计算城市间知识溢出指标
这是整个流程最核心的部分,我们需要计算每一年、每一个城市对的知识溢出指标。
具体逻辑是:遍历每一年,对每一年确定来源专利(t-3 到 t-1 年公开的专利)和目标专利(t 年申请的专利),然后遍历每个来源城市和目标城市组合,计算所有专利对的文本相似度,最后汇总得到城市间的知识溢出指标。
考虑到计算量巨大,我们设计了断点续算机制:如果某一年已经计算过(存在 res/spillover_year_YYYY.pkl),就跳过;每计算完一年,立即保存结果。这样即使中断运行,下次也可以从断点继续。
完整代码
第五步:合并所有结果
所有年份计算完成后,我们需要将分散在 res/ 文件夹中的中间文件合并为一个完整的结果文件。这里使用 glob.glob() 索引所有年份文件,然后逐个读取并合并。
完整代码
# ============================================================================# ============================================================================print("\n===== 第五步:合并所有结果 =====")year_pattern = os.path.join("res", "spillover_year_*.pkl")year_files = sorted(glob.glob(year_pattern))print(f" 找到 {len(year_files)} 个年份文件") spillover_df = pd.concat(all_results, ignore_index=True)# 最终合并结果保存到工作目录(CSV 格式便于查看) spillover_df.to_csv("城市间知识溢出指标_tidytext_python.csv", index=False)print(f" 合并完成:{len(spillover_df)} 条记录已保存到 ""城市间知识溢出指标_tidytext_python.csv") spillover_df = pd.DataFrame()print(f" 合并后数据维度:{spillover_df.shape}")使用 glob.glob() 列出所有匹配的年份文件,逐个读取文件并检查是否有有效数据,然后使用 pd.concat() 合并所有数据框,最后保存为 CSV 格式(城市间知识溢出指标_tidytext_python.csv),便于查看和后续分析。
第六步:汇总与统计
所有年份计算完成后,我们需要对合并后的结果进行汇总,计算每年、每个城市对的知识溢出指标,并生成统计报告。
具体来说,我们按 year、source_city、target_city 分组,每个城市对只保留一行(因为第四步已经计算了平均相似度),然后生成年度统计:每年的城市对数量、平均知识溢出、标准差。
完整代码
# ============================================================================ summary_stats.to_csv("知识溢出年度统计_tidytext_python.csv", index=False)print(" - 城市间知识溢出指标_tidytext_python.csv")print(" - 城市间知识溢出指标_tidytext_python_汇总.csv")print(" - 知识溢出年度统计_tidytext_python.csv")print("\n===== 年度统计 =====")print(summary_stats.to_string(index=False))print("\n===== Top 10 知识溢出城市对 =====") top10 = spillover_summary.nlargest(10, "knowledgespillover_ab")print(top10.to_string(index=False))这段代码主要做三件事:首先按年份、来源城市、目标城市分组汇总数据;然后生成年度统计(城市对数量、平均知识溢出、标准差);最后打印结果,包括年度统计表格和知识溢出最高的前10个城市对。
断点续算说明
代码末尾打印了断点续算的使用说明和指标定义,方便用户理解。
完整代码
# ============================================================================# ============================================================================print("\n===== 断点续算说明 =====")print("1. 双维度保存(中间文件使用 .pkl 格式):")print(" - 按年份:res/spillover_year_YYYY.pkl")print(" - 按来源城市+年份:res/spillover_source_城市_year_YYYY.pkl")print("2. 重新运行代码时自动跳过已有文件")print("3. 可随时中断(Ctrl+C),重新运行将从断点继续")print("4. 全部完成后自动合并为最终 CSV 文件")print("5. 最终结果显示在工作目录(CSV 格式),中间文件保存在 res/ 文件夹(PKL 格式)")print("\n===== 指标说明 =====")print("knowledgespillover_ab = Σᵢ Σⱼ similarity(pᵢ, qⱼ) / (n_a × n_b)")print(" pᵢ:城市a在 t-3 到 t-1 年公开的专利")print(" qⱼ:城市b在 t 年申请的专利")print(" 条件:来源专利公开时间 早于 接收专利申请时间")如何参加课程?
购买 RStata 名师讲堂会员即可参加该课程啦(之前的和未来的都可以参加)!
价格:2800/年 或者 4800/长期
购买会员可以从这里下单:https://rstata.duanshu.com/#/card/list/
名师讲堂会员权益:
- 参加平台上的其他 R 语言和 Stata 的课程;
- 以会员折扣价购买我们分享的数据资料(10 元/份);
* 如果发票可添加小编微信 r_stata2 (RStata 李老师)开具。如需数据资料,购买后可添加小编微信免费领取数据折扣卡。
更多关于 RStata 会员的更多信息可添加微信号 r_stata2 咨询:

课程主页(点击文末的阅读原文即可跳转):https://rstata.duanshu.com/#/brief/course/89d622f54a4d4229b77b157b52f1f72c