一、单选题(每题2分,共30分)
|
题号
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
15
|
|
答案
|
B
|
A
|
C
|
A
|
B
|
B
|
B
|
A
|
C
|
C
|
A
|
A
|
B
|
B
|
C
|
1、以下(
)没有涉及Python语言的面向对象特性⽀持。
A.
Python中构造⼀个 class
B.
Python中调用 printf函数
C.
Python中调用用户定义的类成员函数
D.
Python中构造来源于同⼀基类的多个派⽣类解析:调用 printf 函数并没有涉及到类或者对象的概念,因此不属于面向对象特性的一部分。
2、关于Python中面向对象的类的继承
,下面说法错误的是 (
)
A.子类可以通过继承不能访问到⽗类的所有属性
B.多个子类可以继承同⼀个父类
C.子类和子类产⽣的对象都可以通过句点的⽅式拿到⽗类
D.
python中支持多继承
解析:
A选项描述不正确,子类可以通过继承访问到父类的公有属性,但不能访问到私有属性。
B和D选项描述正确。
C选项描述正确,子类对象可以通过句点方式访问父类的公有属性。
3、有6个元素
,按照 6,5,4,3,2,
1 的顺序进入栈S,下列(
)的出栈序列是不能出现的( )。
A.
5,4,3,6, 1,2
B.
4,5,3, 1,2,6
C.
3,4,6,5,2, 1
D.
2,3,4, 1,5,6
解析:
栈的操作是先进后出(FILO),出栈序列需要满足这个规则。
选项A、B和D都可以实现。
选项C无法实现,因为3出栈后不可能有4和6出栈。
4、采用如下代码实现检查输⼊的字符串括号是否匹配
,横线上应填入的代码为(
)。

s.push(symbol)
s.pop(symbol)
s.push(index)
D.
s.pop(index)
解析:
当遇到开括号时,应该将开括号压入栈中,以便后续匹配闭括号。
正确的代码是 s.push(symbol)。
5、下⾯代码判断队列的第⼀个元素是否等于a,并删除该元素
,横向上应填写( )。

not
q.empty() and q.queue[0] != a:
not
q.empty() and q.queue[0] == a:
C.
q.empty() and q.queue[0] == a:
D.
q.empty() and q.queue[0] != a:
解析:
判断队列的第一个元素是否等于 a,并删除该元素,应填写 not
q.empty() and q.queue[0] == a。
6、假设字母表{a,b,c,d,e}在字符串出现的频率分别为10%,15%,30%,16%,29%。若使⽤哈夫曼编码⽅
式对字母进⾏⼆进制编码 ,则字符 abcdef分别对应的⼀组哈夫曼编码的长度分别为(
)。
A.
4, 4, 1, 3, 2
B.
3, 3, 2, 2, 2
C.
3, 3, 1, 2, 1
D.
4, 4, 1, 2, 2
解 析:求哈夫曼编码需要先构建哈夫曼树,构建方法:①
从频率表中取出最小的两个元素,构建出新元素,②
将新元加入到频率表中,图示如下
析:求哈夫曼编码需要先构建哈夫曼树,构建方法:①
从频率表中取出最小的两个元素,构建出新元素,②
将新元加入到频率表中,图示如下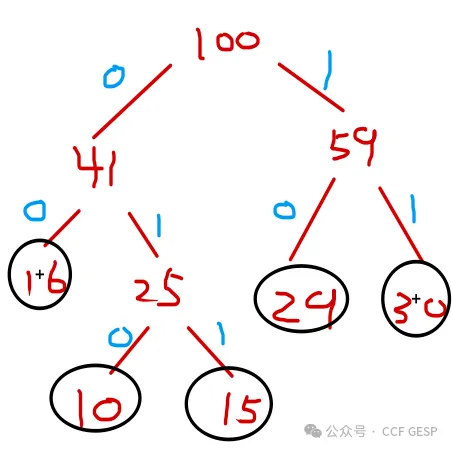
所以很明显abcdef分别对应的一组哈夫曼编码长度为3
3 2 2 2
7、以下Python代码实现n位的格雷码
,则横线上应填写( )。

inverted_gray_code
= [int(( '0 ' * n + bin(x)[2:])[-n:], 2)
inverted_gray_code
= [int(( '1 ' * n + bin(x)[2:])[-n:], 2)
inverted_gray_code
= [int(( '1 ' * n + bin(x)[1:])[-n:], 2)
D.
inverted_gray_code = [int(( '1 ' * n + bin(x)[2:])[n:], 2)
解析:题目要求实现一个函数generate_gray_code(n),该函数生成n位的格雷码。格雷码的特点是相邻两个数之间只有一个位不同。解析过程
1.基础情况
n
<= 0:如果 n 小于等于0,返回空列表。
n
== 1:如果 n 等于1,返回 [0,
1],这是1位格雷码。
2.递归调用
生成 n-1 位的格雷码:gray_code
= generate_gray_code(n - 1)。
3.构造 n 位格雷码
我们需要构造n位的格雷码,方法是:
生成 n-1 位格雷码的前缀为 0 的部分。
生成 n-1 位格雷码的前缀为 1 的部分。
具体做法是:
对于 n-1 位格雷码的每个元素 x,构造前缀为 1 的 n 位格雷码。
横线处的代码
我们需要构造前缀为1的n位格雷码。对于n-1位格雷码的每个元素x,构造前缀为1的n位格雷码:
inverted_gray_code
= [int(('1' * n + bin(x)[2:])[-n:], 2) for x in gray_code]
选项分析
A.
inverted_gray_code = [int(('0' * n + bin(x)[2:])[-n:], 2) for x in
gray_code]:
错误,前缀应该是 1,而不是 0。
B.
inverted_gray_code = [int(('1' * n + bin(x)[2:])[-n:], 2) for x in
gray_code]:
正确,构造前缀为 1 的 n 位格雷码。
C.
inverted_gray_code = [int(('1' * n + bin(x)[1:])[-n:], 2) for x in
gray_code]:
错误,bin(x)[1:] 应该是 bin(x)[2:]。
D.
inverted_gray_code = [int(('1' * n + bin(x)[2:])[n:], 2) for x in
gray_code]:
错误,切片 [n:] 导致截取错误的位置。
因此正确的答案是B
8、给定⼀棵⼆叉树
,其前序遍历结果为:ABDECFG,中序遍历结果为:DEBACFG,则这棵树的正确后序遍历
结果是( )。
A.
EDBGFCA
B.
EDGBFCA
C.
DEBGFCA
D.
DBEGFCA
解析:在前序遍历中找根,在中序遍历中找根的左右子树,建好树后进行后序遍历。
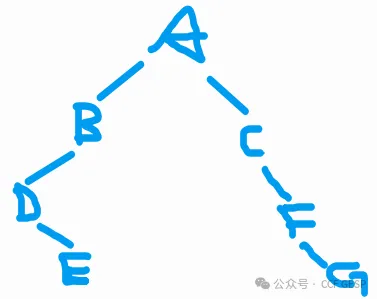
结果为EDBGFCA
9、⼀棵有n个结点的完全⼆叉树⽤数组进⾏存储与表⽰,
已知根结点存储在数组的第1个位置
。若存储在数组第 9个位置的结点存在兄弟结点和两个⼦结点
,则它的兄弟结点和右⼦结点的位置分别是( )。
A.
8, 18
B.
10, 18
C.
8, 19
D.
10, 19
解析:完全二叉树兄弟结点一般是左偶右奇,9号结点的兄弟结点只能是8号,而右子结点即9*2+1
= 19,选C
10、⼆叉树的深度定义为从根结点到叶结点的最长路径上的结点数
,则以下基于⼆叉树的深度优先搜索实现的
深度计算函数中横线上应填写( )。
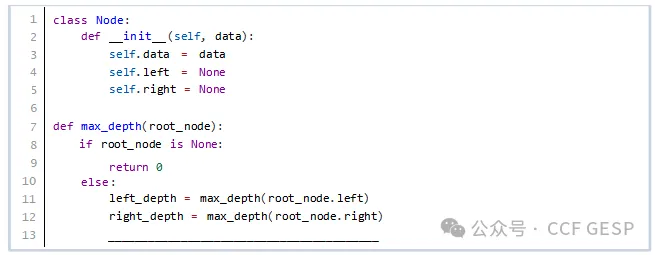
A.
return max(left_depth, right_depth)
B.
return min(left_depth, right_depth) + 1
C.
return max(left_depth, right_depth) + 1
D.
return max(left_depth, right_depth) - 1
解析:代码的思路是计算出当前根结点左子树的深度,右子树的深度,那么以根结点为子树的深度即max(左子树,右子树)+1,+1即将根结点的深度也计算在内,所以选C。
11、以下基于二叉树的搜索实现的深度计算函数中横线上应填写(
)。
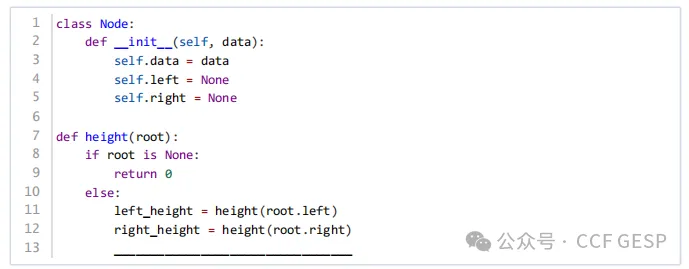
return
max(left_height, right_height) + 1
return
min(left_height, right_height) - 1
return
min(left_height, right_height) + 1
D.
return max(left_height, right_height) - 1
解析:我们需要计算二叉树的深度。二叉树的深度是指从根节点到最远叶子节点的最长路径上的边数。这里的深度计算逻辑是递归的。基本情况:如果根节点 root 为空,返回 0,表示空树的深度为 0。
递归情况:
计算左子树的深度 left_height。
计算右子树的深度 right_height。
返回左右子树中深度较大的那个加上 1(根节点的高度)。
根据上述逻辑,横线处应该填写:
return
max(left_height, right_height) + 1
这是因为我们要返回左右子树中深度较大的那个,并加上根节点的高度。
12、⼆叉搜索树中的每个结点
,其左子树的所有结点值都⼩于该结点值
,右⼦树的所有结点值都⼤于该结点值
。以下代码对给定的整数数组(假设数组中没有数值相等的元素) ,构造⼀个对应的⼆叉搜索树
,横线上应填写 (
)
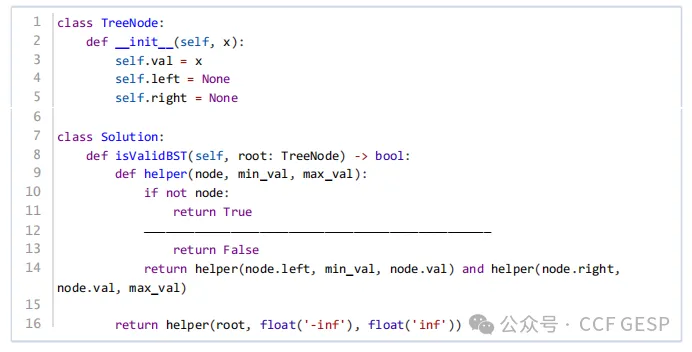
if
node.val <= min_val or node.val >= max_val:
if
node.val >= min_val or node.val >= max_val:
if
node.val <= min_val or node.val <= max_val:
D.
if node.val >= min_val or node.val <= max_val:
解析:题目描述了二叉搜索树(Binary
Search Tree,
BST)的性质,并给出了一个用于验证给定树是否为有效二叉搜索树的函数。我们需要填充横线上的代码,使其能够正确验证树的性质。
上述代码是一个用于验证二叉搜索树是否有效的函数isValidBST,并通过递归辅助函数helper来实现验证逻辑。
helper的作用是递归地验证当前节点node是否满足二叉搜索树的性质,即:
左子树的所有节点值小于当前节点值。
右子树的所有节点值大于当前节点值。
此外,函数还会传递当前节点值的有效范围min_val和max_val,确保节点值在指定范围内。
我们需要在横线上填充代码来检查当前节点的值是否在其有效范围内。具体来说:
如果当前节点值 node.val 小于等于 min_val 或者大于等于 max_val,则说明该节点不满足二叉搜索树的性质。
否则,继续递归检查左子树和右子树。
因此,正确的填充代码应该是:
if
node.val <= min_val or node.val >= max_val: return
False
因此选A
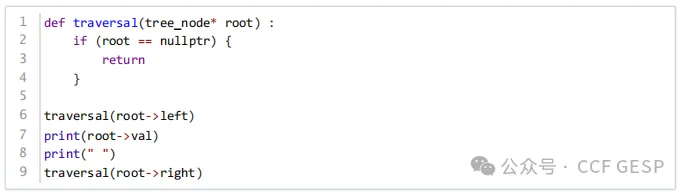
13、对上题中的⼆叉搜素树
,当输⼊数组为[5
, 3 , 7, 2 , 4, 6, 8]时
,构建⼆叉搜索树 ,并采用如下代码实现的遍历方式
,得到的输出是( )。
A.
5 3 7 2 4 6 8
B.
2 3 45 6 78
C.
2 43 6 8 7 5
D.
2 43 5 6 7 8
解析:根据输入数组建BST为
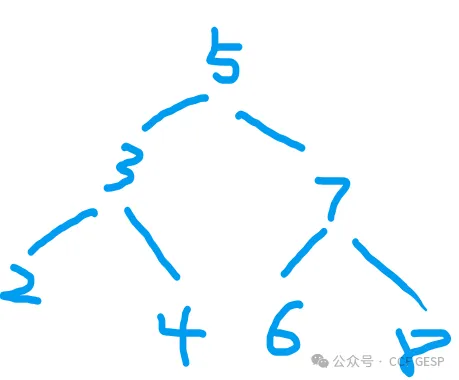
然后根据
“左根右”的遍历规则输出为:
2
3 4 5 6 7 8,选B
14、动态规划通常⽤于解决(
)。
A.⽆法分解的问题
B.可以分解成相互依赖的⼦问题的问题
C.可以通过贪⼼算法解决的问题
D.只能通过递归解决的问题
解析:一个问题是否能用DP来解决我们的考虑一般有两点:①
最优子结构,②无后效性最优子结构即
选项B,可分解成相互依赖的子问题的问题,因此选B。
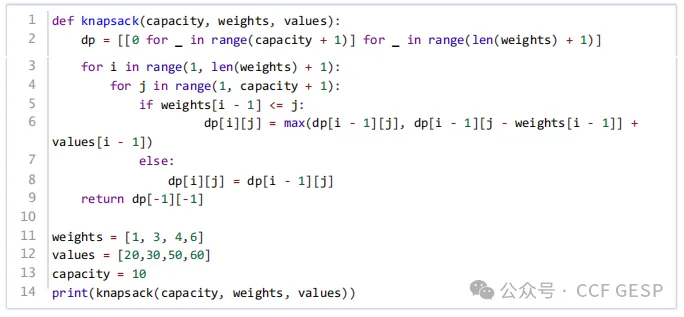
15、阅读以下⽤动态规划解决的0-1背包问题的函数
,假设背包的容量w是10kg ,假设输入4个物品的重量 wueights分别为1
, 3, 4, 6(单位为kg)
,每个物品对应的价值values分别为20,
30, 50, 60 ,则函数的输出为(
)。
A.
90
B.
100
C.
110
D.
140
解析:
01背包问题,dp[n][w]表示将前n个物品放入容量为w的背包中得到的最大价值,4个物品的重量为1
3 4 6,价值为20
30 50 60,背包容量为10,最大价值是1
3 6 对应的110。
二、判断题(每题2分,共20分)
|
题号
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
|
答案
|
√
|
×
|
√
|
√
|
×
|
√
|
√
|
×
|
√
|
√
|
1、C++、Python和JAVA等都是⾯向对象的编程语⾔
。解析:这些语言都支持面向对象编程的基本概念,如类、继承、封装和多态。
2、在python中
,类的静态成员变量只能被该类对象的成员函数访问。
解析:静态成员变量可以被类的所有实例共享,并且不仅限于成员函数访问,也可以在类外部访问。
3、栈和队列均可通过数组或链表来实现
,其中数组实现支持随机访问、 占⽤内存较少
,但插入和删除元素效率低 ;链表实现的元素插入与删除效率⾼
,但元素访问效率低、 占⽤内存较多。
解析:数组支持随机访问,插入和删除效率低;链表插入和删除效率高,但访问效率低,正确。
4、运行以下python代码
,屏幕将输出“derived
class”。
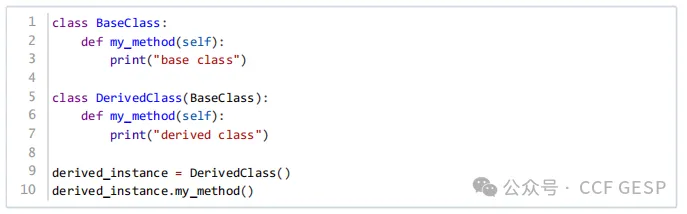
解析:代码分析
定义基类BaseClass:
基类 BaseClass 定义了一个方法 my_method,该方法打印字符串 "base
class"。
定义派生类DerivedClass:
派生类 DerivedClass 继承自 BaseClass。
派生类重写了基类中的 my_method 方法,该方法打印字符串 "derived
class"。
创建派生类实例并调用方法:
创建 DerivedClass 的一个实例 derived_instance。
调用实例方法 my_method。
运行结果
当创建DerivedClass的实例并调用其my_method方法时,由于DerivedClass重写了基类BaseClass中的my_method方法,因此会执行派生类中的方法,并打印字符串"derived
class"。
5、如下列代码所⽰的基类(base)及其派⽣类(derived)
,则⽣成⼀个派⽣类的对象时 ,只调⽤派⽣类的构造函数。

解析:创建一个派生类的对象时,会先调用基类的构造函数,再调用派生类的构造函数。因此,题目中的描述是不正确的。
正确的构造顺序是:
调用基类 base 的构造函数,输出"base
constructor"。
调用派生类 derived 的构造函数,输出"derived
constructor"。
因此,题目描述
“生成一个派生类的对象时,只调用派生类的构造函数”
是错误的。
6、哈夫曼编码本质上是⼀种贪⼼策略。
解析:哈夫曼编码通过每次选择局部最优解来达到全局最优解,符合贪心策略的定义。
7、如果根结点的深度记为1 ,则⼀棵恰有2024个叶结点的⼆叉树的深度最少是12 。 解析,考虑二叉树中第i层的叶结点数目最多为 2i-1,
,那 10
< i-1 < 11 , 11< i <12,因此
深度为 12是正确的。
8、在⾮递归实现的树的⼴度优先搜索中
,通常使⽤栈来辅助实现。
解析:广度优先搜索通常使用队列实现,而非栈。
9、状态转移⽅程是动态规划的核⼼
,可以通过递推⽅式表⽰问题状态的变化。
解析:状态转移方程是动态规划中表示状态变化的核心公式。
10、应用动态规划算法时
,识别并存储重叠⼦问题的解是必须的。
解析:动态规划算法通过存储重叠子问题的解来避免重复计算,提高效率。正确
三、编程题(每题25分,共50分)
1、小杨和整数拆分
题面描述
小杨有⼀个正整数n,小杨想将它拆分成若干完全平方数的和,
同时小杨希望拆分的数量越少越好。小杨请你编写程序计算出总和为n的完全平方数的最少数量。
输入格式
第⼀行包含⼀个正整数n,含义如题⾯所⽰
。
输出格式
输出⼀个整数
,代表总和为 n的完全平方数的最少数量。
样例1

18
= 9 + 9 = 16 + 1 + 1 ,其中最少需要2个完全平方数。

对于全部数据
,保证有 1
≤ n ≤ 105。
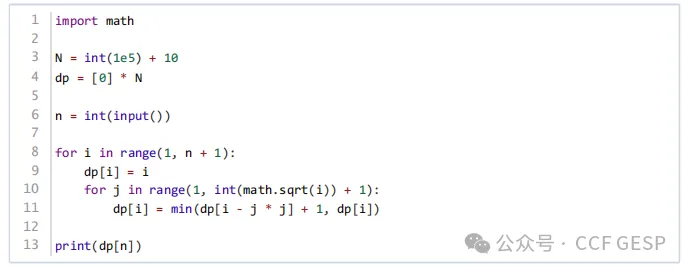
解析:
题目大意:给定一个正整数n,将其拆分成若干个完全平方数的和,要求拆分的数量越少越好。求最少需要多少个完全平方数才能构成n。
用DP进行求解
状态定义
设dp[i]表示构成整数i的最少完全平方数的数量。
状态转移方程
考虑如何通过已知的dp[j](其中j
< i)来推导出dp[i]。
对于任意一个整数i,我们可以考虑将它拆分成一个完全平方数j2加上剩余部分i
- j2 的和。因此,
dp[i] 可以通过dp[i
- j2] 来推导出来,即:
dp[i]
=min 1≤ k ≤ i (dp[ i−j 2 ]+1)
解释:
dp[i
- j2] 表示剩余部分 i
- j2 的最少完全平方数数量。+
1 表示当前添加了一个完全平方数 j2。
我们需要取所有可能的 j 的最小值,以确保 dp[i] 最小。
参考程序
2、算法学习
题面描述
小杨计划学习m种算法
,为此他找了 n道题⽬来帮助⾃⼰学习
,每道题⽬至多学习⼀次。
小杨对于m种算法的初始掌握程度均为0。第i道题⽬有对应的知识点ai,
即学习第 i道题⽬可以令⼩杨对第ai种
算法的掌握程度提⾼ bi。小杨的学习⽬标是对m种算法的掌握程度均⾄少为k。
小杨认为连续学习两道相同知识点的题⽬是不好的
,小杨想请你编写程序帮他计算出他最少需要学习多少道题⽬才
能使得他在完成学习⽬标的同时避免连续学习两道相同知识点的题⽬
。
输入格式
第⼀行三个正整数m,
n, k ,代表算法种类数
,题⽬数和目标掌握程度。
第⼆行n个正整数a1, a2 ,
a3 ,
... , an,代表每道题目的知识点。
第⼆行n个正整数b1, b2 ,
b3 ,
... , bn,代表每道题目提升的掌握程度。
输出格式
输出⼀个整数
,代表小杨最少需要学习题⽬的数量 ,如果不存在满足条件的方案
,输出 -1。
样例1

样例2

对于样例1,⼀种最优学习顺序为第⼀道题
,第三道题 ,第四道题 ,第⼆道题。
对于全部数据
,保证有 1
≤ m, n ≤ 105, 1 ≤ bi, k ≤ 105, 1 ≤ ai≤ m。
解析
1.数据准备
读入数据,并将每道题目按知识点分类,记录每种算法通过题目提升掌握程度的列表score。
2.计算每种算法所需的题目数量
对于每种算法,我们需要计算达到目标掌握程度k所需的题目数量。为了最大化利用高分题目,我们需要按分数降序排序。
3.确定最少题目数量
我们需要找到一种安排,使得小杨学习的题目数量最少,并且避免连续学习相同知识点的题目。为此,我们找出需要题目最多的算法,并尝试调整学习顺序。
4.调整学习顺序
如果最多需要的题目数量mx_need减去1之后仍然不超过总需要的题目数量减去mx_need,那么可以通过调整顺序来满足要求;否则,输出-1。
参考程序

技术支持:GESP技术委员会委员
赵晨泽
策划:GESP技术委员会副主席
刘晓庆












 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
