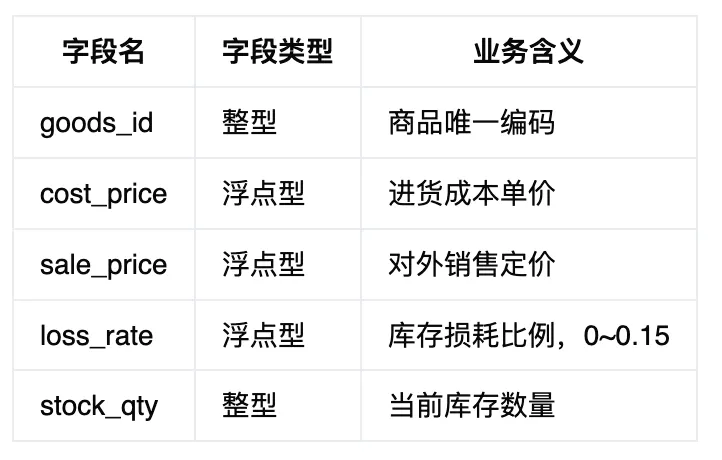
for循环逐行处理百万级数据运行极慢,向量化运算依托底层C实现批量计算,效率提升数十倍,是大数据量处理性能优化核心手段。场景:基于商品进货价、售价、损耗率批量计算毛利、毛利率、实际可售利润,对比循环与向量化两种写法的运行效率。核心知识点:列向量化四则运算、np.where向量化条件判断、避免逐行循环、性能基准对比。① 字段含义说明
② 生成测试数据
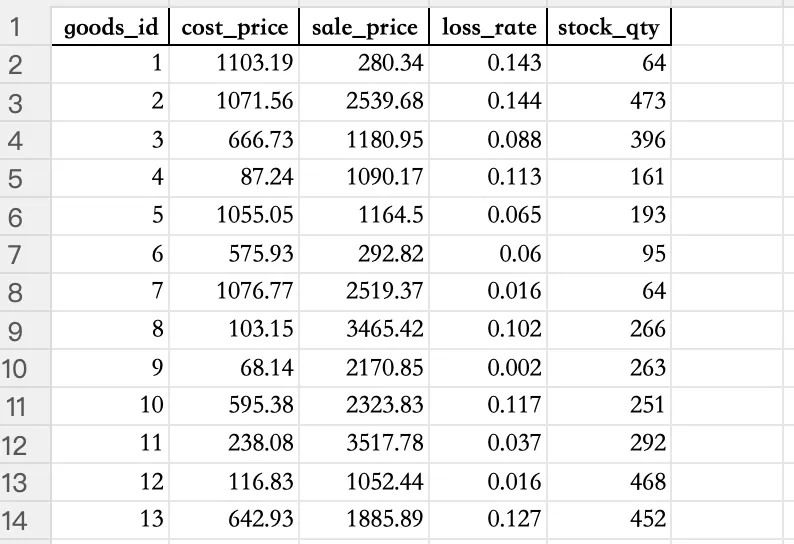
import pandas as pdimport numpy as np# 生成10万行超大测试数据集df = pd.DataFrame({ "goods_id": range(1, 100001), "cost_price": np.random.uniform(30, 1200, 100000).round(2), "sale_price": np.random.uniform(80, 3600, 100000).round(2), "loss_rate": np.random.uniform(0, 0.15, 100000).round(3), "stock_qty": np.random.randint(10, 500, 100000)})df.to_excel("vector_goods_data.xlsx", index=False)print("十万行库存商品测试数据生成完成")
③ 核心代码(循环写法 vs 向量化写法)
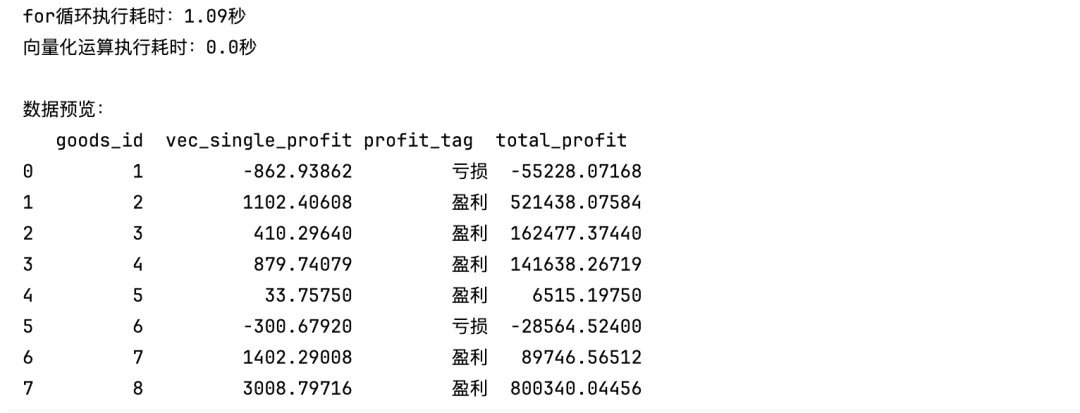
import pandas as pdimport numpy as npimport timedf = pd.read_excel("vector_goods_data.xlsx")# 方案1:传统for循环(低效,仅作对比)start_loop = time.time()profit_loop = []for idx, row in df.iterrows(): real_sale = row["sale_price"] * (1 - row["loss_rate"]) single_profit = real_sale - row["cost_price"] profit_loop.append(single_profit)df["loop_single_profit"] = profit_loopend_loop = time.time()# 方案2:向量化运算(高性能,生产推荐)start_vec = time.time()df["real_sale_unit"] = df["sale_price"] * (1 - df["loss_rate"])df["vec_single_profit"] = df["real_sale_unit"] - df["cost_price"]# 向量化多条件判定:区分盈利/亏损商品df["profit_tag"] = np.where(df["vec_single_profit"] > 0, "盈利", "亏损")df["total_profit"] = df["vec_single_profit"] * df["stock_qty"]end_vec = time.time()print(f"for循环执行耗时:{round(end_loop - start_loop, 2)}秒")print(f"向量化运算执行耗时:{round(end_vec - start_vec, 2)}秒")print("\n数据预览:")print(df[["goods_id","vec_single_profit","profit_tag","total_profit"]].head(8))
结果展示
总结
向量化运算直接操作完整数组,规避Python循环逐行解释开销,十万级数据速度差距可达百倍;条件判断优先使用np.where替代if循环,大数据预处理必须优先采用向量化改造思路。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
