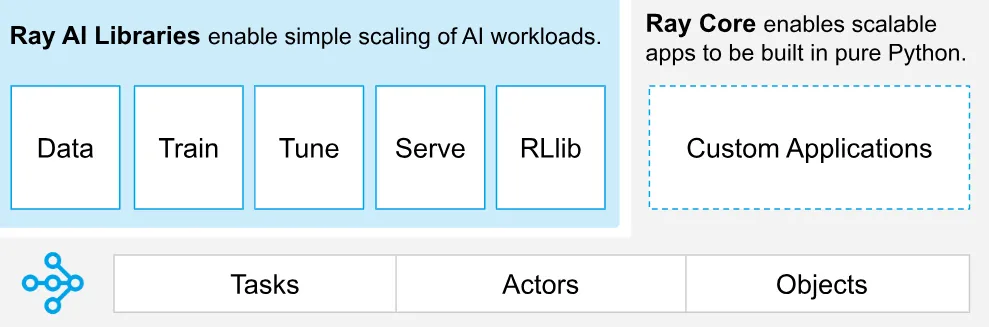
在大模型(LLM)与超大规模深度学习席卷全球的当下,数据量与模型参数量正以指数级速度增长。很多 Python 开发者都曾遭遇过这样的窘境:单机 CPU 核心吃满、显存频频 OOM(内存溢出)、使用 multiprocessing 遇到难以解决的序列化死锁……传统的单机计算早已无法满足现代 AI 任务的需求。
如何用最少的代码修改,把Python任务无缝扩展到多核CPU、多张GPU 甚至成百上千台机器组成的集群上?
答案就是Ray。本文将从零开始,系统性地带你彻底掌握这个为下一代 AI 时代而生的分布式计算框架。
01 为什么是Ray?
在深入代码之前,我们先来聊聊传统Python分布式工具的“痛点”,以及 Ray 究竟做对了什么。
1.1 传统分布式框架的困境
Multiprocessing(多进程模块): 只能局限于单机多核。一旦跨机器,你就必须自己写 Socket 通信、处理复杂的 IP 路由与心跳检测。同时,Python 的进程间通信(IPC)需要频繁进行数据的序列化与反序列化,面对大数据时内存很容易暴涨。
Spark / Flink: 它们是大数据时代的王者,非常擅长处理结构化的、大规模的数据批处理(MapReduce)。然而,在现代机器学习场景中,我们需要的是动态的控制流(如深度学习中的循环、强化学习中的复杂环境交互)、低延迟的任务调度以及对 GPU 资源的精准掌控。在这些 AI 专属的场景下,Spark 显得过于沉重和僵化。
1.2 Ray 的诞生与核心架构
Ray 由 UC Berkeley RISELab 发起,目标是提供一个统一的分布式运行时:用几乎与单机相同的 Python 代码,透明地调度到集群上的 CPU/GPU 资源。
截至 2026 年,Ray 在 GitHub 上已有 4 万+ Star,被 OpenAI、Uber、Shopify、Ant Group 等广泛用于训练、推理与数据处理。它不再只是「分布式任务队列」,而是一个完整的 AI Compute Engine。
Ray 的底层架构由几个关键的常驻进程组成:
Head Node(主节点): 集群的指挥中心。除了负责全局调度,它还运行着 GCS(Global Control Store,全局控制存储),负责记录整个集群的元数据(哪个对象在哪个节点、哪个机器有空闲资源等)。
Worker Node(工作节点): 负责具体计算的物理机器。
Raylet(集群管家): 运行在集群中每一个节点上的核心守护进程。它包含本地调度器(Scheduler)和对象存储(Object Store)。
核心黑科技:共享内存(Plasma)
Ray 的每个节点都内置了一个基于共享内存的对象存储组件。如果同一台机器上的多个进程需要读取同一个几十 GB 的超大矩阵,它们可以直接从共享内存中直接读取,实现零拷贝(Zero-copy)。这彻底解决了传统 Python 分布式库内存翻倍、序列化极慢的顽疾。
02 Ray的安装与集群搭建
Ray 的安装极其简单,它不仅支持本地单机模拟,也能轻松无缝扩展到真实的物理多机集群中。
2.1 基础安装
在你的 Python 虚拟环境(建议 Python 3.8+)中执行以下命令即可安装核心框架:
pip install "ray[default]"
[default] 选项会同时安装 Ray 的控制面板可视化仪表盘(Dashboard),方便你监控集群的 CPU、内存和任务状态。
2.2 多机部署与集群组建
假设你有两台处于同一内网的服务器,IP 分别为:
你只需要在命令行中执行以下两条命令,即可把两台物理机绑成一个强大的算力池:
步骤 1:在机器 A 上启动主节点
ray start --head --port=6379
执行后,控制台会打印出一条加入日志,提示你其他机器如何连接。
步骤 2:在机器 B 上加入集群
ray start --address='192.168.1.100:6379'
至此,分布式环境便搭建完毕。整个过程无需复杂的配置文件,更不需要手动在两台机器间拷贝业务代码。
03 Ray的无状态任务与有状态角色
Ray 的分布式编程模型非常优雅,它仅仅将复杂的分布式并发抽象为两个基础的 Python 概念:Tasks(无状态任务) 与 Actors(有状态角色)。
3.1 Tasks(分布式任务)—— 无状态的函数并行
当一个普通 Python 函数被加上了 @ray.remote 装饰器后,它就蜕变成了一个 Task。
3.2 Actors(分布式角色)—— 有状态的类常驻
当一个普通 Python 类(Class)被加上了 @ray.remote 装饰器后,它就变成了一个 Actor。
04 构建分布式高并发图片处理系统
为了让你彻底看清在分布式集群下,Tasks 和 Actors 是如何完美交响的,我们将动手编写一个完整的实战演练:构建一个分布式图像批处理与全局日志统计系统。
在这个系统中:
4.1 全流程 Python 代码实现
ray_studio.py代码:
import rayimport timeimport iofrom PIL import Image# =====================================================================# 步骤 1:连接集群# =====================================================================# 提示:如果是单机本地测试,直接写 ray.init() 即可,Ray 会在本地拉起虚拟集群。# 如果是在多机集群上运行,填入 "auto",Ray 会自动连接你在命令行启动的 6379 端口。ray.init(address="auto" if ray.is_initialized() else None)print("Ray 分布式集群连接成功!开始执行任务...")# =====================================================================# 步骤 2:定义【有状态的 Actor】 —— 全局计数器# =====================================================================@ray.remoteclass ClusterMetricsCounter: def __init__(self): self.total_processed = 0 self.node_breakdown = {} def log_success(self, node_ip: str): """记录处理成功事件,并累加当前节点的计数""" self.total_processed += 1 self.node_breakdown[node_ip] = self.node_breakdown.get(node_ip, 0) + 1 return self.total_processed def fetch_report(self): """返回当前的全局统计报表""" return { "total_images": self.total_processed, "distribution": self.node_breakdown }# =====================================================================# 步骤 3:定义【无状态的 Task】 —— 图像分布式转换# =====================================================================@ray.remotedef process_image_task(image_bytes: bytes, metrics_actor_handle) -> dict: """ 接收图片字节流,在远程节点将其转换为灰度图。 处理完成后,异步向集群中的有状态 Actor 汇报状态。 """ # 动态获取当前 Task 到底被分配到了哪台物理机器的 IP 上 current_node_ip = ray.get_runtime_context().worker.node_ip_address # 模拟图像处理逻辑 img = Image.open(io.BytesIO(image_bytes)) gray_img = img.convert("L") # 故意休眠 1 秒,模拟复杂的重度计算开销 time.sleep(1) # 【高能交互】:Task 跨网络远程调用 Actor 的方法,递增全局计数 # 注意:这里的 .remote() 是非阻塞的,Task 报完信会立刻往下走 metrics_actor_handle.log_success.remote(current_node_ip) return { "status": "success", "processed_by_ip": current_node_ip, "output_size": gray_img.size }# =====================================================================# 步骤 4:主控制流执行(Driver 进程)# =====================================================================if __name__ == "__main__": start_time = time.time() # A. 在集群某处实例化常驻的 Actor print("\n[1/4] 正在初始化远程有状态 Actor...") metrics_actor = ClusterMetricsCounter.remote() # B. 准备模拟数据(生成 6 张红色空白图片的二进制流) print("[2/4] 准备图片测试数据...") mock_img = Image.new("RGB", (800, 800), color="red") img_byte_arr = io.BytesIO() mock_img.save(img_byte_arr, format='JPEG') raw_bytes = img_byte_arr.getvalue() # C. 异步触发 6 个分布式任务 print("[3/4] 开始跨集群异步分发 6 个无状态图像处理任务...") # 我们把刚才创建的 metrics_actor 句柄像普通变量一样作为参数传进去 futures = [process_image_task.remote(raw_bytes, metrics_actor) for _ in range(6)] print("提示:.remote() 会立即返回 Future(对象引用),主线程完全没有被阻塞!") # D. 阻塞等待,回收全集群的计算结果 print("\n[4/4] 正在通过 ray.get() 同步阻塞等待所有远程节点计算返回...") task_results = ray.get(futures) # E. 打印任务明细与 Actor 收集的全局状态 print("\n" + "="*30 + " 集群物理执行明细 " + "="*30) for idx, res in enumerate(task_results): print(f"图片 {idx+1} 处理完毕 | 实际运行物理机器 IP: {res['processed_by_ip']} | 尺寸: {res['output_size']}") # 远程调用 Actor 获取它帮我们保管的内存状态 final_report = ray.get(metrics_actor.fetch_report.remote()) print("\n" + "="*30 + " 远程 Actor 全局账本报表 " + "="*30) print(f"整个集群累计处理图片总数: {final_report['total_images']}") print(f"各台服务器工作量负载打散详情: {final_report['distribution']}") print("="*75) print(f"整个流程总耗时: {time.time() - start_time:.2f} 秒。") print("(由于分布式并行,6个耗时1秒的任务在多核/多机上并发执行,总时间远小于 6 秒!)") # 关闭 Ray 连接 ray.shutdown()
4.2 这一全程中,Ray 在底层做了什么?
当你点击运行这个脚本,Ray 的分布式管弦乐队便开始在后台高能演奏:
动态代码网络广播(Code Spreading): 当运行到process_image_task.remote(...) 时,由于你的 Worker 节点(机器 B)上其实根本没有这个 .py 脚本文件,主节点的 Ray 引擎会自动将该函数的代码字节码序列化,通过网络广播发给机器 B 的 Raylet 管家,管家在本地实时把它拉起来运行。
无感知的网络远端过程调用(RPC): 在 process_image_task 函数内部,有一行 metrics_actor_handle.log_success.remote(...)。在以前,这意味着你要在 Task 里手动写网络套接字、处理高并发锁。而在 Ray 中,无论 Task 和 Actor 处于哪两台不同的物理机上,Ray 都会通过底层的轻量级 RPC 自动定位并将消息投递过去。
智能路由流转: 主节点连接的 GCS(全局控制存储)会充当全自动交警。当你需要读取结果执行 ray.get(futures) 时,它负责通知 Driver 去正确的机器下载处理完的数据。
通过本文的系统介绍与实战,我们不难发现,Ray 最具魅力的特点就在于对原生 Python 代码的极低侵入性。你不需要去刻意迎合复杂的分布式框架重写你所有的业务逻辑,只需要加上几个简单的 @ray.remote,无状态的函数和有状态的类就能在顷刻间化身为庞大集群中纵横飞驰的分布式算力。
如今,火爆全球的大模型框架如 OpenLLM、vLLM,以及超大规模参数微调库,其底层几乎无一例外地选择基于 Ray 构建。掌握了 Ray,你就拿到了通往分布式大规模 AI 计算时代的入场券。赶快在你的下一行 Python 代码中尝试一下ray.init() 吧!