2python之es单节点处理及处理一体机问题
- 2026-07-01 04:52:43
写在前面的话
提前预告。昨天,在图书馆,看到一个哥们吃着馒头,就着榨菜,可能是太噎了,喝了一口开水,哇哇呸了几口。这都什么年代了,还吃馒头咸菜。我是第三次见到他这样,我忍不住了,走上前去,说:哥们,减肥啊,这么将就。哥们说:叫我哥们,我是78年的,今年48啦。我问他中午怎么吃这么简单,他说现在没工作,又不想让家人担心,天天出来假装上班,能省就省点呗。我说那你会露馅的呀,到月底,家人见不到钱,你解释不了的。他说这些年偷偷存的有十几个,每个月拿出来一些当工资,后面不行,找朋友借点,能瞒一天是一天吧,家里人情绪不稳定,不想给他们制造焦虑。我在想:我要做个关爱大龄人士的活动,让他们来上号,推荐红包整大点,恩,就这样。
[190+100]-------->底部有张生活照片(头条号运营:大家想全托管上号的联系我哦,每天让你得个早餐钱,微信号: qhz_toutiao)
【关键词】python、ragflow、es单节点,一体机
一、es单节点处理(三级)
描述:需要在一个服务器上起两个容器,一个集群节点,一个es节点,这样一来,就可以一个供正式,一个供测试使用。
开工:
第一步:查资料(四级)
20250519周一时间段:23:11-01:00问下deepseek,修改了配置文件,如下:
docker-compose-base.yml如下:
es-test:image: docker.elastic.co/elasticsearch/elasticsearch:${STACK_VERSION}# build:# context: .# dockerfile: ./Dockerfiletest.elastic # 指定自定义路径# args:# ES_VERSION: ${STACK_VERSION}# network_mode: host # 所有节点统一配置healthcheck:test: ["CMD-SHELL", "curl -sf http://localhost:9200 || exit 1"]interval: 30stimeout: 30sretries: 3container_name: ragflow-es-testprofiles:- elasticsearchvolumes:- /home/admin/data/docker_esdata_single:/usr/share/elasticsearch/data- ./elasticsearch/elasticsearch_test.yml:/usr/share/elasticsearch/config/elasticsearch.yml- /etc/localtime:/etc/localtime:ro- /etc/timezone:/etc/timezone:roports:- "1201:9200" # 使用1200端口对外暴露# - "9300:9300" # 集群内部通信端口env_file:- .env- .${HOSTNAME}.envenvironment:- network.host=0.0.0.0- node.name=zero4-test # 直接指定节点名,避免依赖 ${HOSTNAME}- discovery.type=single-node- cluster.name=ragflow-test-cluster # 使用独立的集群名- network.bind_host=0.0.0.0- http.port=9200 # 明确指定HTTP端口- transport.port=9301 # 使用与集群不同的传输端口(避免冲突)- bootstrap.memory_lock=true- ES_JAVA_OPTS=-Xms8g -Xmx8g- ELASTIC_PASSWORD=${ELASTIC_PASSWORD}- xpack.security.enabled=false # 确保禁用安全功能networks:- ragflowulimits:memlock:soft: -1hard: -1restart: unless-stopped
elasticsearch_test.yml如下:
# # 线程池配置
thread_pool:
search:
size: 24 # 等于CPU核心数
queue_size: 1000 # 适当增加队列大小
write:
size: 12 # 写操作线程数(核心数一半)
get:
size: 12 # get操作线程数
#备份文件存放路径
# path.repo: ["es_backups0430"] # 新增配置项
# path.repo: ["/home/admin/data/es_backups0430"]
# 内存和缓存配置
bootstrap.memory_lock: true
indices.queries.cache.size: "30%"
script.max_size_in_bytes: 100000000
script.max_compilations_rate: 250000/5m
# 文件系统
index.store.type: "niofs" # 使用 NIO 文件系统(Linux 推荐)
cluster.name: ragflow-test-cluster
node.name: zero4-test
network.host: 0.0.0.0
discovery.type: single-node
xpack.security.enabled: false
第二步:测试
测试还可以
二、合并测试线上代码(三级)
描述:现在测试代码要和线上代码一样,做下合并。
开工:
第一步:合并代码(四级)
20250520周二时间段:10:28-12:00在云效上合并,截图如下:

图2b-1
注:还可以。
第二步:测试
测试还可以
三、处理一体机问题(三级)
描述:现在一体机搞了个分支,有一些问题需要处理。
开工:
第一步:看文档(四级)
20250520周二时间段:11:00-12:00需要先处理一个一体机搜索问题,截图如下:
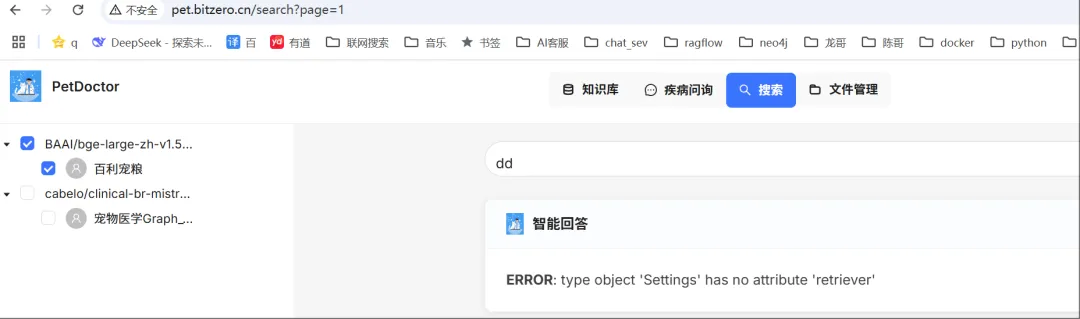
图2c-1
注:接下来,是本地复现这个问题。
第二步:本地复现问题(四级)
20250520周二时间段:15:12-16:00本地复现问题可以打断点,先在测试分支上复现一下。
排查到原因了,先看接口:
/v1/conversation/ask 错误日志:
{"retcode": 0, "retmsg": "", "data": {"answer": "\n**ERROR**: No API-key provided.", "reference": {}}}{"retcode": 500, "retmsg": "type object 'Settings' has no attribute 'retriever'", "data": {"answer": "**ERROR**: type object 'Settings' has no attribute 'retriever'", "reference": []}}注:说是却少api-key,另一个是没有这个属性。接下来,写个测试用例如下:
def test_conversation_ask(client):
log.info("test_conversation_ask")
'''
测试web页面搜索
'''
json_data = {
"kb_ids": [
"19227896305c11f0ae7b2ea444f1dac4",
"a8b097002d9a11f090bb0a8671151e3e"
],
"question": "55"
}
url = f"/v1/conversation/ask"
resp = client.post(
url,
json=json_data,
headers={
"Content-type": "application/json",
"Authorization": "Bearer ragflow-UxOGYzZjUwYjMwOTExZWZiODc0MDI0Mm"
}
)
if not 200 <= resp.status_code < 300:
raise Exception(f"GET {url} status_code {resp.status_code}.")
# received_data = []
for chunk in resp.iter_encoded():
answer = chunk.decode('utf-8').strip()
log.info(f"\n\n answer: {answer} \n\n")
四、科技文章(三级)
描述:看一篇文章,提高下。
开工:
第一步:标题(四级)
截图如下:
图2d-1
第二步:背景(四级)
在数字化时代,电商已成为全球商业最具活力的领域之一。Alluxio作为数据管理与存储领域的先锋,为电商行业的快速发展提供了重要支持,尤其在全球跨境电商的崛起中,成为企业高效运营和创新的关键力量。
跨境电商企业面临数据管理的多重挑战,包括多样化数据处理、跨境物流、多语言支持和本地化运营等复杂场景,涉及的数据可能分布在不同的云平台和本地数据中心。Alluxio凭借其分布式缓存技术和创新解决方案,帮助企业优化数据利用,提升运营效率,从而在全球市场保持竞争优势。
为了赋能更多全球电商企业,我们汇集多家全球跨境电商企业实战案例,推出
《Alluxio助力全球跨境电商构建高性能数据访问平台实战宝典》
从业务痛点剖析到Alluxio解决方案应用,再到企业价值收益,深入挖掘跨境电商企业实战经验,赋能更多电商领域负责AI和大数据的相关从业者,在自身业务中开展更多的创新应用。
第二步:内容摘要(四级)
【韩国本土电商巨头】Alluxio提升韩国本土电商平台AI训练效率:加速数据访问、GPU利用率、简化存储管理
【日本头部电商平台】借力Alluxio提升数据平台灵活性和扩展性
【东南亚领航电商平台】Shopee 在 Alluxio 加速 AI 训练的实践与探索
【快时尚跨境电商标杆平台】Alluxio助力快时尚跨境电商标杆平台大数据与AI场景提升性能和降低成本
【国内知名品牌特卖电商平台】加速优化唯品会亿级数据服务平台
第四步:读者收益(四级)
借鉴实战经验:学习全球知名电商平台如何通过Alluxio解决AI模型训练中的数据瓶颈,加速模型迭代和部署。
优化多云架构:掌握如何利用Alluxio实现跨云、跨数据中心的数据高效管理,提升数据平台的灵活性和扩展性,为AI模型训练提供更强大的基础设施支持。
提升AI模型训练效率:了解Alluxio如何通过分布式缓存加速数据读取,显著缩短AI模型训练时间,提升GPU利用率,助力企业更快地实现模型上线。
实现性能与成本双重优化:在提升数据处理速度的同时,大幅降低存储和流量成本,特别是在AI模型训练场景下,实现更高的性价比。
增强数据管理能力:通过Alluxio的智能缓存策略和数据分层管理,优化AI训练数据的生命周期,提高数据访问效率和资源利用率。
实践灵活性与扩展性:探索如何在业务快速发展中,灵活应对数据增长和业务需求变化,实现AI模型训练的可持续发展。
五、头条战果汇报
昨日数据来啦,昨日总收入:1111.5,昨日总播放:1148.6万,软件截图如下:
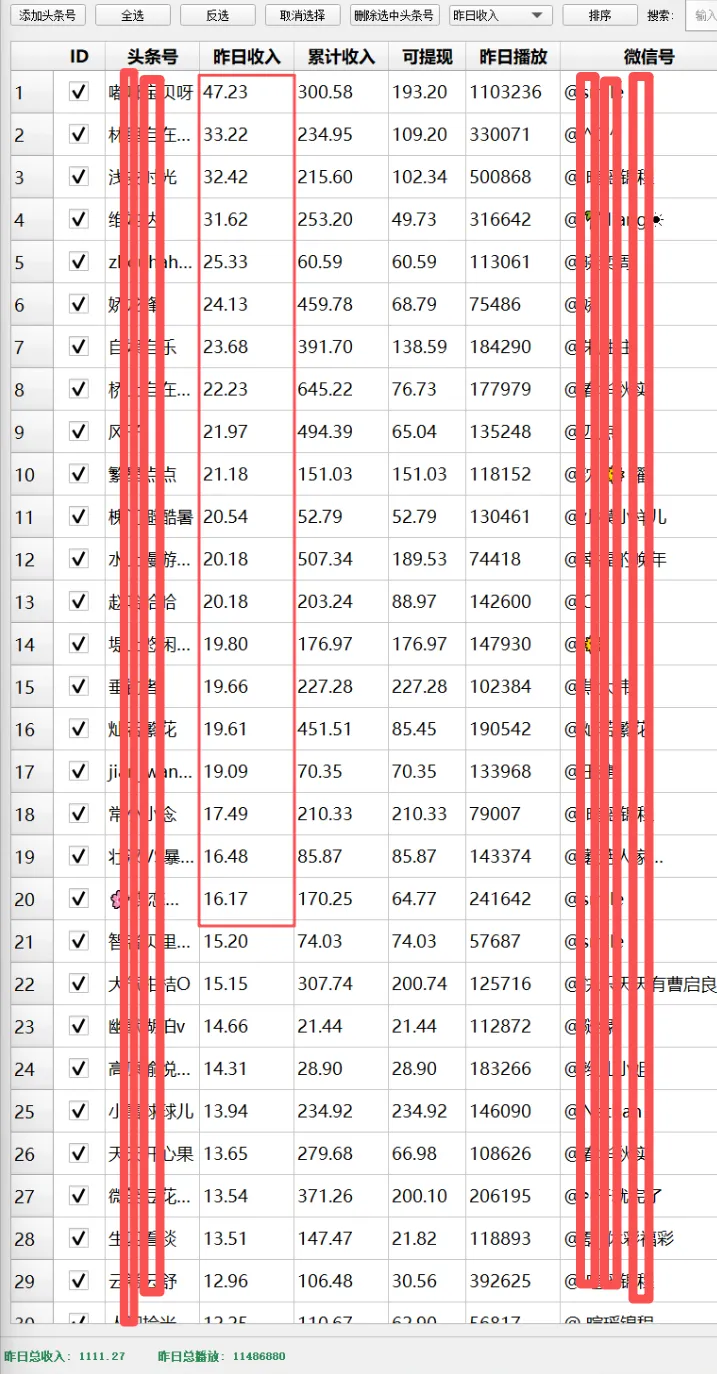
图2e-1
注:想要全脱管运营头条号的联系我,你出账号,我来运营,保你天天有钱花,咨询电话: 17701328814(微信同号),也可以加群先了解一下。

图2e-2
注:个人微信如下,欢迎骚扰。
图2e-3
六、生活照片
拍摄于2025年6月1日,13:13:17,带二宝在小区门口玩,当时二宝两岁八个月。我不是什么高尚的人,但如果在我挣钱的同时,能帮助一些像大哥这种大龄人士,也算是无心插柳吧,我准备从7月1号开始这么干,推荐红包改为12块,再加上挂号者年龄除以10,比如:一个上号者年龄60岁,那推荐人获得的红包是:12+60/10=18块。让他们主动去拉大龄人士上号,不愿意透露年龄的按18岁算,得红包:12+18/10=13.8块。其实,年龄越大,我这边上号越费劲,因为他们可能不会操作手机,年轻人来上号,十分钟搞定,大龄人士上号,可能1个小时都搞不定,但我愿意多花这个时间,也算是对社会的一点贡献吧。

图2f-1
《本文完》

