按下电源键,CPU 从固定地址读取第一条指令。十五秒后,屏幕上出现登录界面。这十五秒里,Linux 把一堆硅片变成了一台能思考的机器。
硬件不懂"文件",不懂"进程",不懂"用户"。这些概念都是 Linux 用软件一层层"骗"出来的。理解这些抽象层,就读懂了操作系统的核心设计思想。
诞生:从硅片到进程
CPU 的工作极其简单:读取指令,执行指令,输出结果,然后重复。每条指令由一个时钟信号驱动,晶体管在纳秒级的时间内切换通断状态,完成一次逻辑运算。
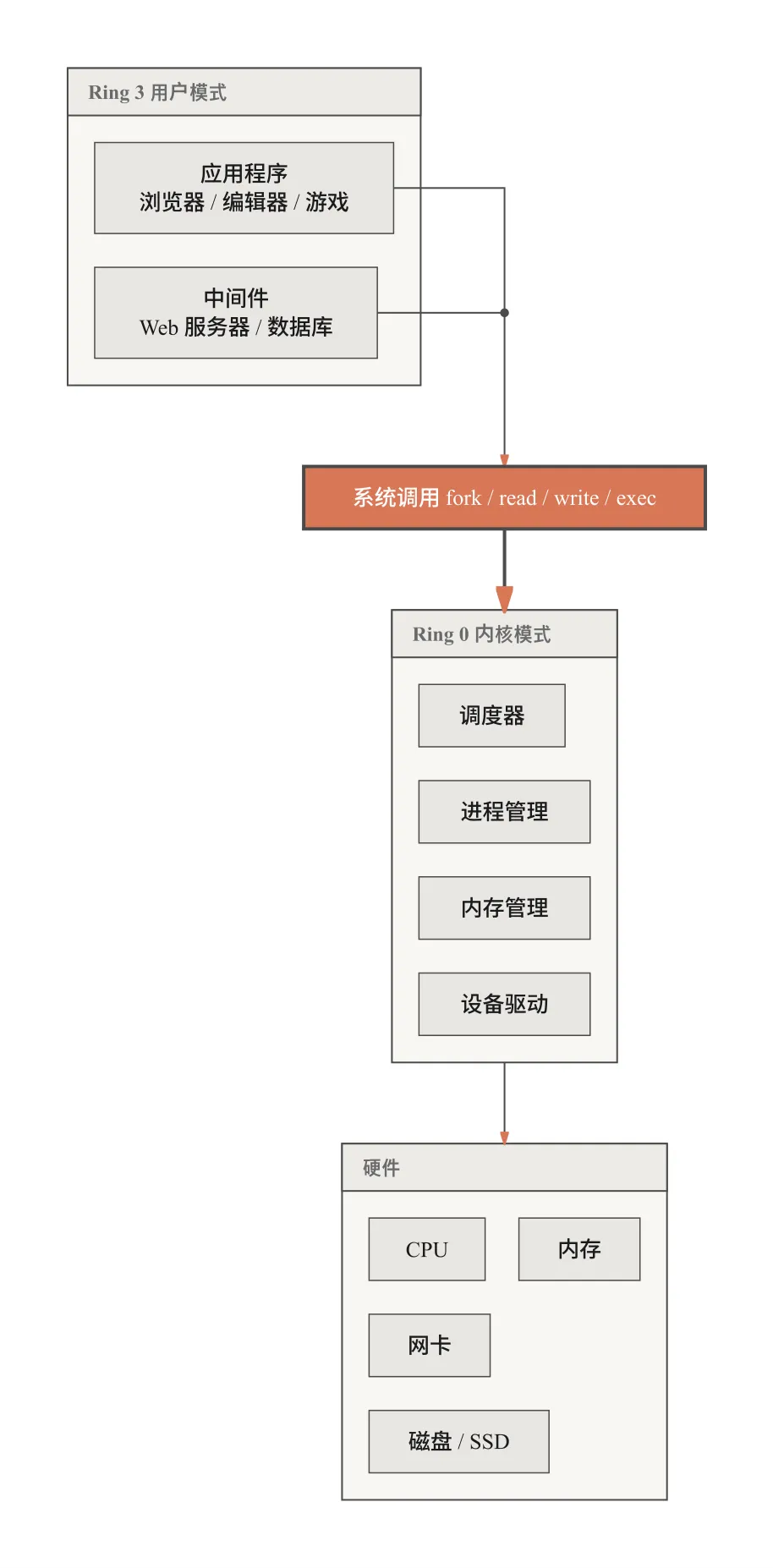
这些重复执行的步骤整合成对用户有意义的处理,就叫做程序。程序分三层——应用程序 直接面向用户需求(浏览器、编辑器、游戏),中间件(Web 服务器、数据库)为应用程序提供通用服务,操作系统直接控制硬件,为上面两层提供运行环境。没有操作系统,每个程序都要自己管理 CPU、内存和设备,开发成本不可想象。
程序在操作系统上以 进程 为单位运行。一个程序可以有多个进程——Chrome 浏览器通常为每个标签页分配独立的渲染进程。Linux 能同时运行成百上千个进程,每个进程都认为自己独占了整台计算机。这个幻觉的维持,靠的是 CPU 硬件提供的两种运行模式:内核模式(Ring 0)拥有最高权限,可以执行任何指令、访问任何内存和硬件;用户模式(Ring 3)权限受限,只能访问自己的内存空间,无法直接操作硬件。
把设备驱动、进程管理、内存管理、调度器等核心组件整合在一起的程序就是 内核。进程运行在用户模式,内核运行在内核模式。进程想使用内核功能(读文件、分配内存、创建子进程),必须通过系统调用向内核发出请求。进程能感知到的是:无限的内存、即时响应的设备、独立的 PID 空间——一个完美的虚拟世界。
桥梁:系统调用与中断
系统调用是进程与内核通信的唯一通道。每次调用都涉及 CPU 特权级切换——从 Ring 3 切到 Ring 0,内核接管后验证参数(指针是否合法、缓冲区是否可访问),执行操作,返回结果。发起调用的那个 CPU 核在此期间进入内核执行,这就是系统调用的真实成本。
以 cat file.txt 为例:shell 通过 fork() 创建子进程,子进程通过 exec() 加载 cat,然后 open() 打开文件,read() 读取内容,write() 输出到终端。一次简单的文件读取,至少五次模式切换。
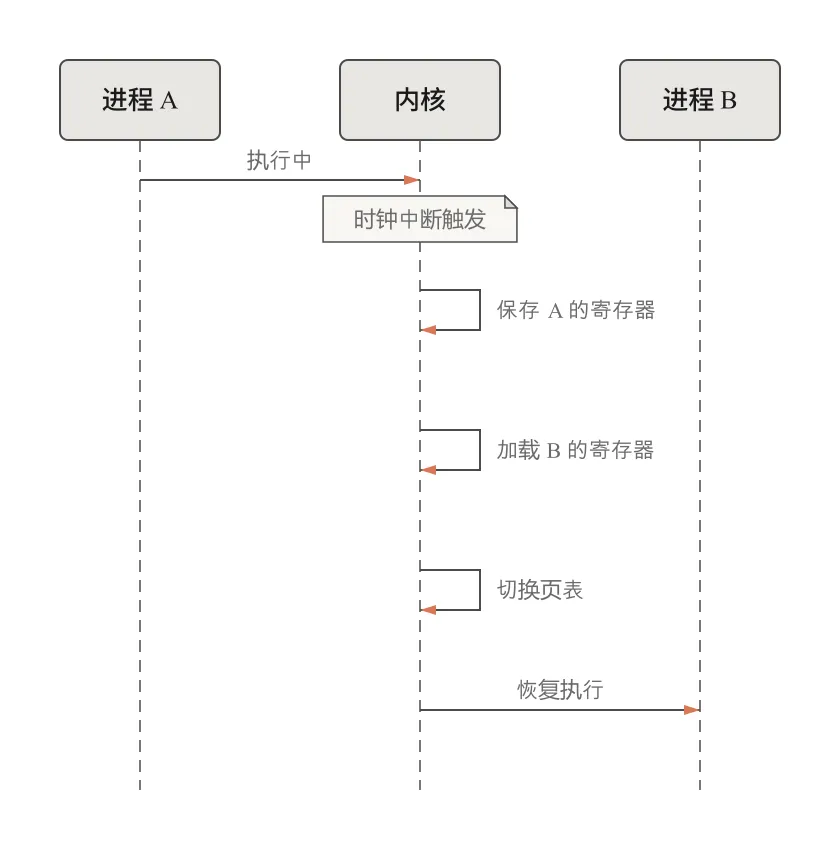
与系统调用的"主动请求"不同,中断 是硬件或内核向 CPU 发出的"被动通知"。硬件中断由外部设备触发:网卡收到数据包、磁盘完成读写、定时器到期。处理流程:设备通过中断控制器发送信号,CPU 暂停当前进程,保存寄存器状态,跳转到内核预设的中断处理函数,处理完毕后恢复进程继续执行。

进程等待 I/O 时不会浪费 CPU 时间。 进程调用 read() 但数据尚未到达时,内核将其标记为"等待"状态,切换到其他可运行的进程。数据到达后,磁盘发出硬件中断,内核在中断处理函数中将该进程重新标记为"可运行"。这就是中断驱动模型——CPU 不需要轮询设备状态,设备准备好时会主动通知。
当内核决定切换到另一个进程时,需要保存当前进程的所有状态(程序计数器、栈指针、通用寄存器、浮点寄存器),加载下一个进程的状态,更新页表基地址寄存器,然后跳转到新进程上次暂停的位置。整个过程只需几微秒,但这是进程并发运行的基础——每个进程都以为 CPU 一直在为自己服务。
面具:设备抽象与一切皆文件
Linux 把所有硬件差异封装在统一的文件接口后面。设备文件位于 /dev/ 目录,应用程序对设备文件执行 read()、write(),内核将请求路由到对应的驱动程序,驱动程序再与硬件交互。不管是三星的 SSD 还是西部数据的 SSD,进程用同样的方式操作。
设备分两类:字符设备 以字节流方式访问(终端 /dev/tty、串口),块设备 以固定大小的块为单位访问(硬盘 /dev/sda、SSD)。
在设备抽象之上,Linux 的分层架构再叠一层:虚拟文件系统(VFS)。VFS 在具体文件系统之上定义统一接口,应用程序不需要关心底层是 ext4、XFS 还是 NFS。VFS 定义了四种核心对象:超级块(代表一个挂载的文件系统)、索引节点(代表一个文件)、目录项(代表一个路径组件)、文件对象(代表一个打开的文件描述符)。
Linux 支持几十种文件系统格式——本地的 ext4、XFS,网络的 NFS、CIFS,甚至内存中的 tmpfs、procfs。/proc 和 /sys 是特殊的虚拟文件系统,内容由内核在内存中动态生成,不占用磁盘空间。读取 /proc/cpuinfo 时,内核实时收集 CPU 信息并格式化输出。读取 /proc/[pid]/status 时,内核返回指定进程的状态信息。这种"一切皆文件"的设计让系统管理变得简单而统一。
牢笼:命名空间与容器
当你用 Docker 启动一个容器时,里面的进程认为自己是 PID 1,拥有独立的文件系统、网络接口和主机名。但这些进程实际上都运行在宿主机的同一个内核上。Docker 并没有模拟出另一台计算机——它只是让进程"看到"了一个隔离的视图。
容器的核心是 Linux 内核提供的两个特性。命名空间 控制进程能"看到"什么:PID Namespace 让容器拥有独立的 PID 空间,Mount Namespace 让容器有独立的文件系统挂载点,Network Namespace 让容器有独立的 IP 地址,User Namespace 让容器内的 root 不等于宿主机的 root。cgroup 控制进程能"用多少"资源:CPU 使用率、内存上限、磁盘 I/O 带宽。超过内存限制时,内核触发 cgroup OOM Killer,通常只杀死容器内的进程。
容器和虚拟机的隔离机制完全不同。虚拟机通过 Hypervisor 模拟完整的硬件环境,每个虚拟机运行独立的内核——隔离性强,但资源开销大。容器共享宿主机内核,只隔离进程的视图和资源——启动速度快(毫秒级)、资源开销小,但隔离性弱于虚拟机。Linux 自身也可以充当虚拟机管理程序:KVM 是内核的一个模块,利用 CPU 的硬件虚拟化扩展(Intel VT-x 或 AMD-V)直接运行虚拟机,性能接近原生。
回到开头的问题:从按下电源键到屏幕亮起,Linux 做的事情本质上只有一件——用软件构建虚拟世界。
物理内存是有限的,但每个进程拥有 128TB 的虚拟地址空间。物理设备各不相同,但所有设备都通过统一的文件接口访问。硬件有中断和特权级,但进程只需要调用函数就能获得一切服务。容器没有独立的内核,但里面的进程以为自己运行在独立的机器上。
每一层抽象,都在向下屏蔽复杂性,向上提供简洁的接口。这就是操作系统的核心思想——也是 Linux 能运行在手机、服务器和超级计算机上的原因。
公众号回复「加群」,加入读者交流群
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
