由于借助 AI 工具学习编程已经变得非常容易了,因此之后的课程就不再默认进行视频讲解了,如果特别需要视频讲解也可以联系李老师预约讲解~讲义材料学习过程中遇到的问题也可以及时与李老师联系。
购买 RStata 名师讲堂会员即可参加该课程啦(之前的和未来的都可以参加)!
价格:2800/年 或者 4800/长期
购买会员可以从这里下单:https://rstata.duanshu.com/#/card/list/
名师讲堂会员权益:
- 参加平台上的其他 R 语言和 Stata 的课程;
- 以会员折扣价购买我们分享的数据资料(10 元/份);
* 如果发票可添加小编微信 r_stata2 (RStata 李老师)开具。如需数据资料,购买后可添加小编微信免费领取数据折扣卡。
更多关于 RStata 会员的更多信息可添加微信号 r_stata2 咨询:

课程主页(点击文末的阅读原文即可跳转):https://rstata.duanshu.com/#/brief/course/456cfe61dc584dceb07bc0c80be3ec45
由于存在坍缩问题,所以这个就不打算分享处理好的数据了,大家可以参考代码自行决定如何计算。
今天给大家讲解如何使用 Python 测算上市公司的数字技术复杂度指标。该指标来源于宋晴等(2026)发表在《数量经济技术经济研究》上的论文「数字技术复杂度与企业市场价值——基于策略性创新的视角」。附件中提供了该论文的 PDF 文件。
本文在 R 语言中通过 reticulate 包来调用 Python 代码。setup chunk 会创建并锁定 Python 虚拟环境 .venv,确保所有 {python} 代码块在正确的环境中执行。
数字技术复杂度指标的来源与计算方法
指标背景
数字技术复杂度(Digital Technology Complexity)是衡量企业在数字经济相关技术领域创新能力的综合性指标。与传统的专利数量指标不同,技术复杂度不仅考虑企业拥有的专利数量,还考虑了企业所涉及技术的稀缺性和复杂性——即企业是否集中在少数高门槛技术领域还是分散在普遍性技术领域。
该指标的计算基于 Hidalgo 和 Hausmann(2009)提出的反射法(Method of Reflections),最初用于测算国家出口产品的经济复杂度。宋晴等(2026)将其创新性地应用于企业层面的数字技术专利分析。
计算步骤
整个计算过程可以分为以下 6 个主要步骤:
- 数字经济专利识别:通过专利唯一标识
newipzlid 与数字经济专利库进行匹配,筛选出属于数字经济领域的专利; - 样本筛选:剔除建筑业、金融业、房地产业企业,剔除 ST、*ST、PT 股票(只要有一年出现即剔除该公司所有年份数据);
- 专利去重与 IPC 提取:对专利进行两轮去重(公开公告号去重 + 申请号去重),提取 IPC 主分类号四位码作为技术分类基本单位;
- RCA(显性比较优势)计算:对每个企业-技术组合计算 RCA 指标,判断企业在特定技术领域是否具有比较优势;
- 反射法迭代:基于 RCA 构建二元矩阵 M,通过迭代计算企业层面的数字技术复杂度;
- 标准化:将复杂度指标标准化至 [0,1] 区间,便于跨年比较和回归分析。
关于"忽增忽降"问题的重要说明
在使用反射法计算复杂度指标时,可能会遇到一个看似异常的现象:逐年标准化后的复杂度均值在某些年份突然出现大幅上升或下降(例如从 0.6 跳到 1.0,次年又跌回 0.4)。
这并不是计算错误,而是反射法在特定数据条件下的固有特征。本讲义将在后文("计算结果解读"一节)中详细解释其数学原理和数据层面的根本原因。
核心公式
直观理解:反射法是什么?
核心公式涉及较多数学符号,这里用一个通俗类比帮助理解反射法的本质。
问题意识:假设你要评价哪家企业的数字技术"厉害",最简单的办法是数专利数量——谁专利多谁厉害。但这样有问题:一个企业拥有 1000 件低端专利,未必比拥有 10 件尖端专利的企业更"复杂"。反射法的出发点正是剥离专利规模,只看技术结构。
一个类比:想象一个"谁有稀缺能力"的互评游戏:
- 企业说:我厉害,因为我掌握的技术别人都不会(技术越稀有,我就越厉害)
- 技术说:我厉害,因为会我的都是厉害企业(企业越厉害,我就越稀有)
这两句话互相"反射"——企业的得分取决于它掌握的技术有多稀有,而技术的稀有程度又取决于掌握它的企业有多厉害。信息在企业 ↔ 技术之间来回反射,经过多轮迭代后逐渐收敛到一个稳定值,这就是"反射法"(Method of Reflections)名字的由来。
具体迭代过程:
一句话总结:反射法 = 用"你拥有的东西有多稀缺"来定义"你有多厉害",并且让这个定义来回迭代直到收敛。它本质上是一种基于网络位置的排序算法,和 Google PageRank 的思想有异曲同工之处——一个企业"厉害",不仅取决于它自己,还取决于它关联的技术的"质量"。
使用 reticulate 创建与管理 Python 虚拟环境
在 R 中通过 reticulate 包来调用 Python,最好的实践是为项目创建一个专属的 Python 虚拟环境,将所需依赖隔离到独立空间。
重要说明(避免"已初始化"报错):reticulate 在 R 会话中只能绑定一次 Python——一旦某个 {python} 代码块运行,Python 解释器就被锁定。因此,虚拟环境的激活必须在所有 {python} 代码块之前完成。本文档的解决方案是在 setup chunk 中通过 Sys.setenv(RETICULATE_PYTHON = ...) 提前锁定 Python 路径,这是 reticulate 选取 Python 的最高优先级入口。
安装 reticulate(仅首次)
# 设置 CRAN 镜像(knit 时 R 处于非交互模式,不会自动选择镜像)options(repos = c(CRAN = "https://mirrors.tuna.tsinghua.edu.cn/CRAN/"))# 仅在尚未安装时才安装,避免每次 knit 都重装if (!requireNamespace("reticulate", quietly = TRUE)) { install.packages("reticulate") message("reticulate 安装完成!") message("reticulate 已安装,版本:", packageVersion("reticulate"))虚拟环境初始化原理(已在 setup chunk 中完成)
本文档的 setup chunk(隐藏运行)包含如下逻辑:
# 以下展示 setup chunk 中已执行的逻辑(eval=FALSE,仅供参考,不重复执行).venv_python <- virtualenv_python(.venv_name)if(!file.exists(.venv_python)){ virtualenv_create(.venv_name, packages =c("numpy","pandas","scipy","pyreadstat")) .venv_python <- virtualenv_python(.venv_name)# 通过环境变量抢先锁定 Python(优先级最高,早于任何 {python} chunk)Sys.setenv(RETICULATE_PYTHON = .venv_python)use_virtualenv(.venv_name, required =TRUE)检查 Python 包是否已就绪
py_pkgs <- c("numpy", "pandas", "scipy", "pyreadstat") installed <- py_list_packages(".venv")$package need_install <- setdiff(py_pkgs, installed)if (length(need_install) > 0) { message("以下包缺失,正在自动安装:", paste(need_install, collapse = ", ")) virtualenv_install(".venv", packages = need_install) message("所有 Python 包已就绪 (numpy, pandas, scipy, pyreadstat)") message("包检查跳过:", conditionMessage(e))验证激活状态
查看已安装的包
pkgs <- py_list_packages(".venv") key_pkgs <- c("numpy", "pandas", "scipy", "pyreadstat") pkgs[pkgs$package %in% key_pkgs, c("package", "version")] message("包列表查询跳过(Python 尚未初始化)")虚拟环境管理常用命令
# 以下命令仅供参考(eval=FALSE,不执行)# virtualenv_remove(".venv")# virtualenv_install(".venv", packages = "scipy", ignore_installed = TRUE)
数据准备
我们需要准备以下三组数据:
- 数字经济专利库:
基于主分类号筛选的数字经济专利newipzlid.dta,包含所有被判定为数字经济领域的专利 newipzlid; - 上市公司与专利数据:
1985~2024年上市公司与专利数据匹配结果.csv,包含每家上市公司每年申请的所有专利信息; - 上市公司行业信息:
2000~2024年国泰安上市公司行业信息.dta,包含每个公司的行业代码和股票简称,用于样本筛选。
1985~2024 年上市公司与专利数据匹配结果(版本3,含申请、授权信息):https://rstata.duanshu.com/#/brief/course/04100321f88b411f90429be934bff
1985~2024 年数字经济产业相关专利筛选结果:https://rstata.duanshu.com/#/brief/course/d5dfb9ca0858457ebc4f176fce9fee80
本讲义使用 2010~2016 年的子样本进行演示。附件中提供了提取好的样本数据 上市公司与专利样本数据.csv,其变量与完整数据相同:
| |
|---|
股票代码 | |
newipzlid | |
年份 | |
专利类型 | 专利类型(发明申请、发明授权、实用新型、外观设计) |
公开公告号 | |
申请号 | |
IPC主分类 | |
授权公告日 | |
首先来看一下样本数据的基本结构:
df_sample = pd.read_csv("上市公司与专利样本数据.csv", dtype={'股票代码': str})样本筛选说明
参照论文的做法,对样本进行以下筛选:
- 行业筛选:根据证监会 2012 版行业代码,剔除建筑业(代码首字母 E)、金融业(J)、房地产业(K)的企业。这些行业与数字技术创新关联较弱,且专利行为与制造业有本质差异;
- ST 筛选:剔除曾经被标记为 ST、*ST 或 PT 的公司。这些公司处于财务异常状态,其专利申请行为可能不代表正常的创新决策。只要该公司在任何一年被标记为 ST/*ST/PT,就剔除该公司所有年份的数据。
行业信息 DTA 的关键变量:
详细计算代码
下面我们逐步讲解完整的计算过程。Python 代码需要加载以下包:
from scipy.sparse import coo_matrixfrom datetime import datetimeStep 1:读取数字经济专利 DTA
首先从数字经济专利 DTA 文件中提取所有数字经济专利的 newipzlid 列表:
dta_path = "数字经济筛选标准/基于主分类号筛选的数字经济专利newipzlid.dta"csv_path = "上市公司与专利样本数据.csv"industry_dta = "2000~2024年国泰安上市公司行业信息.dta"collapse_thresh = 0.06# Kc range 小于此值视为迭代坍缩# E = 建筑业, J = 金融业, K = 房地产业exclude_industry_letters = ["E", "J", "K"]print(" 计算上市公司历年数字技术复杂度")print(f" 方法:反射法(Method of Reflections)")print(f" 年份范围:{min_year}-{max_year}")print(f" 迭代次数:k={n_iter_k}, t={n_iter_t}")print(f" 坍缩检测阈值:Kc range < {collapse_thresh}")print(f" 行业剔除:{','.join(exclude_industry_letters)}")# 使用 columns 参数等价于 R 的 read_dta(col_select = "newipzlid")dta_df = pd.read_stata(dta_path, columns=['newipzlid'])digital_patent_ids = dta_df['newipzlid'].dropna().unique()print(f" DTA 唯一 newipzlid 数量: {len(digital_patent_ids):,}")Step 2:读取行业信息,构建剔除名单
从行业信息 DTA 中识别需要剔除的公司:
上市公司行业信息来源于之前分享的这个数据:
2000~2024 年上市公司注册地址与办公地址(含经纬度及其所处的省市区县):https://rstata.duanshu.com/#/course/746d4f595eba41a2a116b5a6edc3ac0a
Step 3:读取 CSV 并筛选数据
读取上市公司与专利数据,依次进行年份筛选、公司筛选和数字经济专利匹配。
说明:论文使用上市公司申请的数字技术专利(不筛选授权状态),因此保留所有专利申请记录。
print("\n【Step 3】读取 CSV 并筛选数据...")cols_use = ["股票代码", "newipzlid", "年份", "专利类型","公开公告号", "申请号", "IPC主分类", "授权公告日"]# newipzlid 以字符串读取,避免 pandas 推断为 int64 导致与 DTA str 类型不匹配# 授权公告日以字符串读取,避免 pandas 自动推断日期类型df_raw = pd.read_csv(csv_path, usecols=cols_use, dtype={'newipzlid': str, '授权公告日': str, '股票代码': str})print(f" CSV 总行数: {len(df_raw):,}")# --- 3a: 筛选年份(2010-2016)---df_raw = df_raw[(df_raw['年份'] >= min_year) & (df_raw['年份'] <= max_year)]print(f" 年份筛选后: {len(df_raw):,}")# --- 3b: 剔除 ST/*ST/PT 和指定行业公司 ---n_before = df_raw['股票代码'].nunique()df_raw = df_raw[~df_raw['股票代码'].isin(exclude_stocks)]n_after = df_raw['股票代码'].nunique()print(f" 公司筛选(剔除 ST/PT + 建筑/金融/房地产):")print(f" 剔除前公司数: {n_before}")print(f" 剔除后公司数: {n_after}(剔除 {n_before - n_after} 家)")# --- 3c: 不筛选授权状态(论文使用申请专利,保留所有专利申请)---print(f" 保留所有专利申请(含未授权): {len(df_raw):,}")print(df_raw.groupby('专利类型').size().sort_values(ascending=False).to_string())# --- 3d: 通过 newipzlid 匹配数字经济专利 ---digital_set = set(digital_patent_ids)df_raw = df_raw[df_raw['newipzlid'].isin(digital_set)].copy()del digital_patent_ids, digital_setprint(f" newipzlid 匹配(数字经济专利)后: {len(df_raw):,}")Step 4:专利去重
由于专利数据中存在重复的情况,所以分两步进行去重:
Step 5:提取 IPC 四位码
以专利主分类号的 IPC 四位码作为技术分类的基本单位:
Step 6:逐年计算数字技术复杂度(反射法)
这是核心步骤。对每一年 ttt,执行以下操作:
- 从存量数据中筛选
年份 <= t 的专利(简化存量池:同一 newipzlid 不会跨年出现,直接用 df_raw[年份 <= t]) - 使用反射法迭代 20 次(企业)/ 19 次(技术)
- 坍缩检测:检查 Kc 的 range 是否小于阈值(默认 0.06)
★ 关于"迭代坍缩"的说明:当企业度分布 CV 接近 1.0 时,20 次迭代后所有企业的 Kc 值趋同(range < 0.06),导致逐年 Min-Max 标准化后均值出现异常跳跃。详见后文"忽增忽降问题的深入解读"章节。
Step 7:合并结果
将各年份的计算结果合并为完整的数据框:
print("\n【Step 7】合并结果...")results = pd.concat(results_list.values(), ignore_index=True)print(f" 总观测数: {len(results):,}")print(f" 年份范围: {results['年份'].min()}-{results['年份'].max()}")print(f" 唯一企业数: {results['股票代码'].nunique()}")Step 8:多种标准化方式对比
反射法得到的原始 Kc 值在不同年份之间的量纲差异较大,需要进行标准化。本节对比多种标准化方式,并重点解释逐年 Min-Max 标准化中"忽增忽降"现象的成因。
方式 1:逐年 Min-Max(论文使用方式)
此处内容需下载讲义材料查看~
方式 2:逐年百分位排名
此处内容需下载讲义材料查看~
方式 3:全局 Min-Max
此处内容需下载讲义材料查看~
方式 4:面板 z-score 缩放到 [0,1]
此处内容需下载讲义材料查看~
代码实现
Step 9:描述性统计
print("\n【Step 9】描述性统计...")print(f"\n── {min_year}~{max_year} 年 complexity 总体统计 ──")desc = results['complexity'].agg(['count', 'mean', 'min', 'median', 'max', 'std']).round(4)desc.index = ['样本量', '均值', '最小值', '中位数', '最大值', '标准差']yearly = results.groupby('年份').agg( 企业数 = ('complexity', 'count'), 均值 = ('complexity', lambda x: round(x.mean(), 4)), 中位数 = ('complexity', lambda x: round(x.median(), 4)), 标准差 = ('complexity', lambda x: round(x.std(), 4))print(yearly.to_string(index=False))"忽增忽降"问题的深入解读
现象描述
在使用逐年 Min-Max 标准化后,你可能会观察到复杂度指标的逐年均值出现大幅波动。例如:
这种"忽增忽降"并非计算错误,而是以下两个因素共同作用的必然结果。
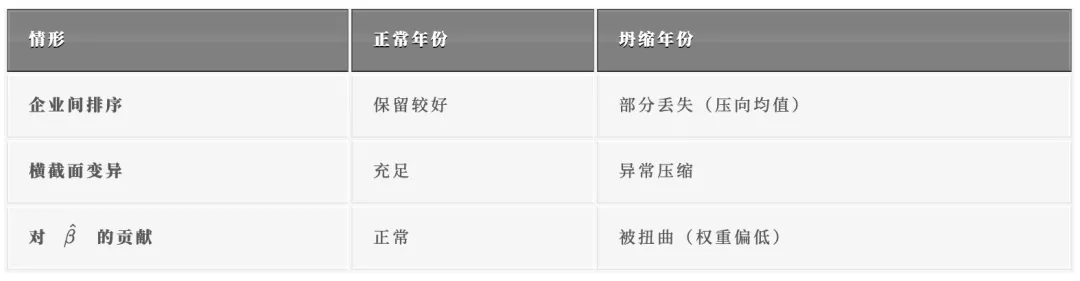
根本原因一:迭代坍缩(Iterative Collapse)
反射法的数学本质是让复杂度值在二分图(企业 ↔ IPC 技术)上不断扩散。当 M 矩阵中企业的度分布(即每个企业拥有的 RCA≥1 的 IPC 种类数)趋于均匀时,迭代会使所有企业的 Kc 值收敛到几乎相同的值。
我们用 2013 年(坍缩年)和 2012 年(正常年)的对比来说明:
企业度 CV(变异系数)= sd / mean,衡量企业间专利多样性的差异程度。当 CV 接近 1.0 时,所有企业的专利组合高度相似,反射法无法区分谁更复杂,迭代后 Kc 值全部挤在一起(range < 0.06),这就是迭代坍缩。
根本原因二:逐年标准化的独立尺度
逐年 Min-Max 每年独立地拉伸数据到 [0,1]。当某年发生迭代坍缩时,Kc 的 range 极小,几乎所有企业的 Kc 值相同,Min-Max 标准化后所有企业都被映射到相同或非常接近的值(通常是 0 或 1 附近),导致该年均值出现异常。
反之,当某年未发生坍缩、Kc 分布较宽时,Min-Max 后能保留较好的区分度,均值处于正常区间。
数据层面的深层原因
为什么企业度 CV 会在某些年份跌破 1.0(趋于均匀)?这反映了产业层面的真实结构变化:
- 企业数激增:2010 年 1,442 家 → 2015 年 3,284 家(翻倍),大量新进入企业初期的专利组合往往集中在少数热门 IPC 上(如 G06F、H04L);
- 技术数基本停滞:2010 年 118 种 → 2015 年 130 种(仅 +10%),但企业数翻倍 → 每项技术被更多企业同时持有,M 矩阵密度上升但结构变"平";
- 专利同质化涌入:2013 年前后数字经济政策密集出台,大量企业同时申请类似的数字技术专利,企业间差异缩小。
这不是数据错误,而是反射法算法对产业结构突变的敏感性表现。
解决方案
| | | |
|---|
| A. 减少迭代次数 | | | |
| B. 检测坍缩年并自动降级 | | | |
| C. 使用 log(Kc) + Min-Max | | | |
推荐做法:在回归分析中使用逐年 Min-Max 标准化 + 年份固定效应。年份固定效应会吸收所有年份层面的宏观因素(包括产业政策冲击),复杂度系数的识别完全来自"同年企业间的横截面差异",这是论文的基准做法。
对后续计量回归的影响
上述"忽增忽降"问题是否会污染回归结果,是实证研究中必须正视的问题。以下从计量经济学角度进行系统分析。
1. 测量误差与衰减偏误(Attenuation Bias)
2. 与年份固定效应的交互作用
逐年 Min-Max 标准化配合年份固定效应是论文的基准设定,但坍缩年份存在特殊问题:
年份固定效应吸收的是所有企业共同面对的年份冲击,复杂度系数的识别理论上完全来自"同年企业间的横截面差异"。但当某年横截面差异本身被算法扭曲时,该年份观测对整体估计的贡献是失真的。
3. 动态面板设定下的额外风险
此处内容需下载讲义材料查看~
4. 应对建议
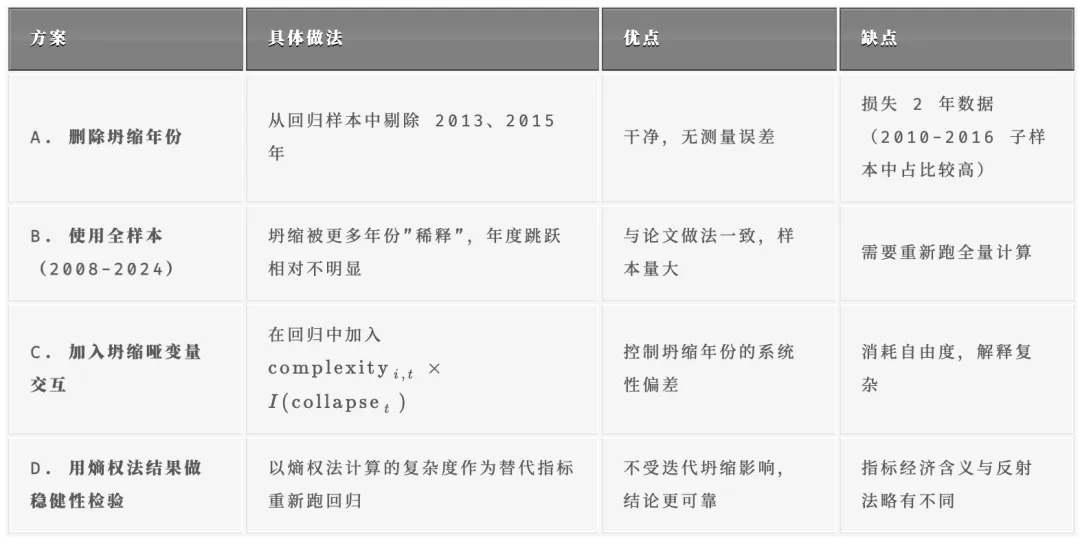
针对上述风险,提出以下四种处理思路:
推荐策略:
- 基准回归使用全样本(2008-2024)跑反射法复杂度 + 年份固定效应,此时坍缩的影响被 17 个年份大幅稀释,2013 和 2015 只是其中 2 年;
- 稳健性检验一:删除 2013 和 2015 年重新跑回归,将结果报告于 Robustness Table;
- 稳健性检验二:用熵权法计算的复杂度作为替代指标,验证核心结论是否依然成立;
- 若坚持使用 2010-2016 子样本:务必在回归中报告 Cluster-Robust SE,并在附录中披露坍缩年份的描述性统计。
小结:论文本身使用 2008-2024 全样本并成功发表,说明审稿人接受了这一测量方式。若你的研究聚焦于 2010-2016 子样本(如受某政策冲击的影响),则需要在论文中主动讨论坍缩问题,并用上述稳健性检验证明结论不受其干扰。
Step 10:保存结果
将股票代码统一转为 6 位字符串(不足前补 0),然后保存为 CSV 文件:
print("\n【Step 10】保存结果...")results['股票代码'] = results['股票代码'].astype(str).str.zfill(6)output_csv = f"{min_year}~{max_year}年上市公司数字技术复杂度_iter{n_iter_k}_py.csv"output_cols = ['股票代码', '年份', 'complexity','complexity_minmax', 'complexity_rank','complexity_global', 'complexity_panel', 'complexity_z']results[output_cols].to_csv(output_csv, index=False, encoding='utf-8-sig')print(f" CSV 已保存至: {output_csv}")print(" 数据处理:微信公众号 RStata")results[output_cols].head(20)关键注意事项
如何参加课程?
购买 RStata 名师讲堂会员即可参加该课程啦(之前的和未来的都可以参加)!
价格:2800/年 或者 4800/长期
购买会员可以从这里下单:https://rstata.duanshu.com/#/card/list/
名师讲堂会员权益:
- 参加平台上的其他 R 语言和 Stata 的课程;
- 以会员折扣价购买我们分享的数据资料(10 元/份);
* 如果发票可添加小编微信 r_stata2 (RStata 李老师)开具。如需数据资料,购买后可添加小编微信免费领取数据折扣卡。
更多关于 RStata 会员的更多信息可添加微信号 r_stata2 咨询:

课程主页(点击文末的阅读原文即可跳转):https://rstata.duanshu.com/#/brief/course/456cfe61dc584dceb07bc0c80be3ec45










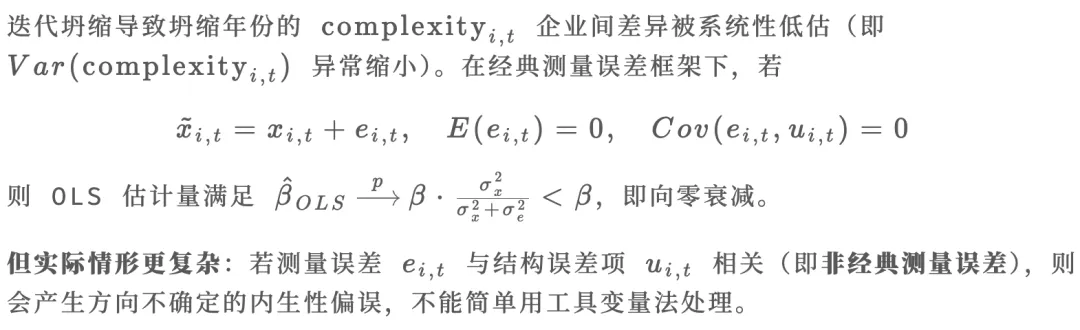

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
